C: C语言强化引导
- TAGS: C
强化引导
表达式有值
x = y = 0 ;
if (x > y) .. ..
等于
x = (y =0); /*将0赋给y, 但是表达式本身是有值的, 表达式的值是y被赋值后的新值*/ /*所以赋给x的值是,表达式y=0的值*/
编程速览
什么是编程
电信号可以代表能够被识别和执行的指令,可以代表指令在执行时用到的数据。
指令和数据存储的内存中,由处理器读取执行。
程序=指令+数据
编程是编写程序,安排一系列需要执行的步骤。
- 早期,通过纸带、开关和路线编程
- 现在,高级语言,接近自然语言,如C语言
程序内容放在源文件中,通过工具(翻译器)将源文件翻译为机器可执行的指令。
范例:编译翻写执行程序
D:\tmp\d>type test.c # include <windows.h> # define MSG0 "Playing...... \n" # define MSG1 "Finished. \n" int main (void) { WriteFile (GetStdHandle (STD_OUTPUT_HANDLE), MSG0, \ lstrlen (MSG0), (DWORD []) {0}, NULL); PlaySound ("zmtx.wav", NULL, SND_FILENAME |SND_SYNC); WriteFile (GetStdHandle (STD_OUTPUT_HANDLE), MSG1, \ lstrlen (MSG1), (DWORD []) {0}, NULL); } D:\tmp\d>gcc test.c -o test.exe -lwinmm #生成test.exe文件 D:\tmp\d>dir 2024-10-30 21:18 366 test.c 2024-10-30 21:21 118,372 test.exe 2024-02-09 11:11 2,430,331 zmtx.wav D:\tmp\d>test Playing...... Finished.
test.exe 包含了机器指令,可以直接执行。运行时,windows操作系统加载这个程序内容到内存中,由处理器来取指令执行指令
变量的声明
内存中的存储区
int obj;
上面内容在C语言中是一个声明,意思是程序运行时应当在内存中寻找一个空闲的存储区,obj就是存储区的名字,int是指定符号 obj所代表的存储区存储一个整数,;末尾的分号标志着一个声明的结束。
这里的int是类型指定符也是关键字。关键字是有固定拼写的单词,大小写敏感。
多数语言习惯使用变量这个术语,变量是内存里的一个存储位置,是一个存储区。
综上内容,声明一个符号obj,代表一个变量,变量要用int类型来读取和写入。
所以,这是声明了一个int类型的变量obj
标识符
int obj;
obj是一个标识符,标识符是自定义的,不以数字符号开头。
- 区分大小定
- 长度尽量控制在31个字符以内
- 不能与关键字相同
/*合法*/ int _Myid; int no123; int id_ab; int obj ; init obj ; /*非法*/ int 12aa; int pg dn; int go-to; int ~tm; int cc*w;
标准整数类型
标准整数类型
- 标准有符号整数类型
- 标准无符号整数类型
标准有符号整数类型
- signed char 可以表示的最小数据范围是-127…+127
- signed short int 短整型,可简写为signed short, short int或者short. 范围 -32767到+32767
- signed int 可简写为int或者signed。 范围-32767到+32767
- signed long int 可简写为signed long, long int或者long。范围-2147483647到+2147483647
- signed long long int 可简写为signed long long, long long int或者long long。范围-9223372036854775807到+9223372036854775807
标准无符号整数类型
- unsigned char 可以表示的最小数据范围是0…255
- unsigned short int 短整型,可简写为unsigned short. 范围 0到65535
- unsigned int 可简写为unsigned。 范围0到65535
- unsigned long int 可简写为unsigned long。范围0到4294967295
- unsigned long long int 可简写为unsigned long long。范围0到18446744073709551615
- _Bool 布尔类型,只能用来表示数字0和1
int x; int y; int sum; int x, y, sum;
如果要一次性声明多个标识符,类型指定符出现一次即可,但各个标识符之间必须用逗号“,”分开。
表达式和语句
int x, y, sum; x = 799; y = 321;
声明三个变量x, y, sum. 把799写入变量x,把321写入变量y.
语句是由表达式和末尾的分号组成。
范例:语句
表达式;
表达式是由运算符和操作数所组成的序列
范例:表达式
x = 799
操作数x, 运算符=, 操作数799
在C语言中,这里的等于号称为赋值运算符,将右边操作数的值赋给左边操作数
即,把右操作数的值写入左操作数所代表的变量中
这种表达式称为赋值表达式
子表达式:组成大表达式的小表达式称为子表达式
范例:子表达式
x = 799 #x和799即是赋值运算表达式的操作数,又是子表达式 #显然很多表达式并不包含运算符
左值:代表变量的表达式称为左值
范例:左值
x = 799 #赋值运算的左操作数必须代表一个变量
左值的必要性
范例:左值的必要性
* (m == 1 ? p : q) = 10086
上面子表达式是一个左值,代表一个变量。把10086写入左边所代表的变量里即左值。
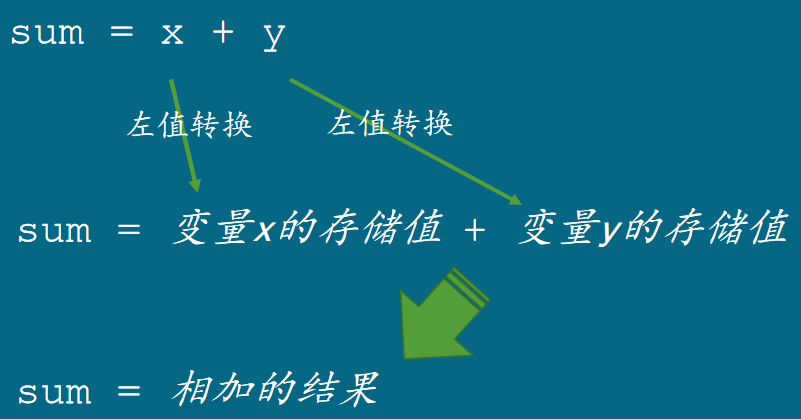
表达式的值
int x, y, sum; x = 799; y = 321; sum = x + y;
把变量x和变量y的内容相加,相加的结果写入变量sum。
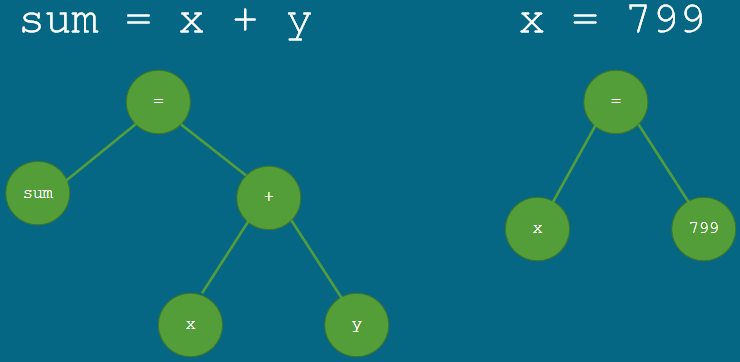
运算符的优先级
sum = x + y #x是运算符+的左操作数,而不是运算=的右操作数。 #因为运算符有各自的优先级,级别高的运算符优先与旁边的操作数组合
表达式的值被视为运算符的结果
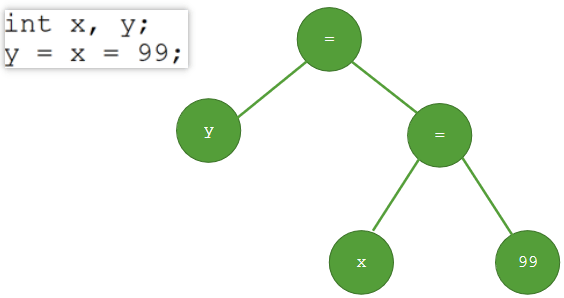
范例:运算符的结合性
int x, y; y = x = 99;
如果运算符的优先级相同,还要看运算的结合性。2种,从左向右结合以及从右向左结合。 而赋值运算符是从右向左结合的。
上例意思是,将99赋给x,x=99表达式的值赋给y,或者说将右边子表达式的结果赋给y
源文件和函数
*.c 为扩展名
它的创造者坚持认为语句不能是源文件的直接组成部分,而只能出现在函数体内.
int main (void) { int x, y, sum; x = 799; y = 321; sum = x + y; }
这里的缩进不是必须的并不影响程序的功能,而是为了美观。
在这个函数里,标识符main就是函数的名字,用于指示(代表)那个代码块。
main函数的另一个特殊之处在于,它是由操作系统调用的,当你运行翻译后的程序时,操作系统加载你的程序,然后调用这个main函数。
括号里是函数接收的参数。如果函数不接受任何参数,则括号中的内容应当为关键字void
每个函数只能有一个返回值。返回值是有类型的,这个类型需要在函数名字的左侧指定。
函数体由花括号"{"和"}",以及位于花括号里的声明和语句组成。
因此,一个完整的函数包括函数名、参数声明、返回类型声明和函数体。类似在程序中声明一个变量,在程序中编写一个函数实际上也是声明了一个函数,称为函数声明。
函数在执行完毕后可以返回到它的调用者那里,这个返回动作可以用return语句来完成。
int main (void) { int x, y, sum; x = 799; y = 321; sum = x + y; return 0; }
当main函数返回时,程序将终止运行,关闭并返回到操作系统,这个return语句用于执行这个返回操作,并将数值0返回到操作系统。
程序的翻译
C语言的本质是一套语法规则,而一个C程序则是按照这些语法规则而编写的文本符号的集合(从而形成源文件)。
一套翻译软件实际上包含了很多程序,这一套完整的工具集,可以视为C语言本身的一个实现,一个现实的化身,简称C实现。
编译只是C实现中的一个阶段。
C实现:
- GNU GCC
- LLVM CLANG
虚拟机和Linux安装
windows上安装虚拟机软件:
- VMware Workstaion Player 免费
Linux发行版
- Ubuntu LTS版 ISO文件
在Linux上安装GCC
sudo apt install gcc
# include <stdio.h> int main (void) { int x, y, z; x = 799; y = 321; z = x + y; printf ("%d\n", z); return 0; }
gcc test.c -o test.out #运行 ./test.out
在Windows上安装GCC
安装 mysys2
2.安装 C/C++ 必要的软件工具
#安装c++必要软件 gcc gdb make clang clang-tool pacman -Syu pacman -S mingw-w64-x86_64-gcc mingw-w64-x86_64-gdb make mingw-w64-x86_64-clang mingw-w64-x86_64-clang-tools-extra
程序的调试
调试器:控制程序的执行,如单步执行。代表GDB
gcc test.c -g #-g 向翻译后的可执行程序添加包括源代码、符号表等信息,有助于gdb调试
使用 gdb 调试
格式
gdb [options] [executable-file [core-file or process-id]]
gdb [options] --args executable-file [inferior-arguments ...]
#常用选项
-silent #去掉免责条款,干净一些
- 使用 gdb ./test.o -silent
- 常用调试命令
| name | function |
| list | 显示源代码 |
| break | 新增断点, break main, break 12(行号) |
| info | 查看断点或者局部变量信息 info breakpoints, info locals |
| run | 开始调试 |
| next | 类似 step over |
| step | 跳转到函数内部 |
| continue | 继续运行到下一个断点 |
| quit | 退出调试 |
| watch | 内存断点 |
| display | 类似 IDE 里面的 watch 功能 |
| break 11 if xxx | 条件断点 |
范例1:
$ gdb ./a.exe -silent Reading symbols from ./a.exe... #列出源代码 (gdb) list 1 # include <stdio.h> 2 3 int main (void) 4 { 5 int x, y, z; 6 7 x = 799; 8 y = 321; 9 10 z = x + y; #第3行打断点 (gdb) b 3 Breakpoint 1 at 0x14000143d: file test.c, line 7. #打印断点信息 (gdb) i b Num Type Disp Enb Address What 1 breakpoint keep y 0x000000014000143d in main at test.c:7 #开始调试,会在第一个断点处停下来 (gdb) r Starting program: D:\tmp\d\a.exe [New Thread 3824.0x21c8] Thread 1 hit Breakpoint 1, main () at test.c:7 7 x = 799; #表示下一个将被执行的语句,是第7行 #打印变量x的值 (gdb) p x $1 = 0 #保存在临时存储区,从$1开始。 #执行下一条语句 (gdb) n 8 y = 321; (gdb) print x $2 = 799 (gdb) next 10 z = x + y; (gdb) print y $3 = 321 (gdb) n 12 printf ("%d\n", z); (gdb) print z $4 = 1120 #一次打印多个变量的值 (gdb) p {x,y,z} $5 = {799, 321, 1120} #运行到下一个断点,没有则运行到程序结尾 (gdb) c Continuing. 1120 [Thread 3824.0x21c8 exited with code 0] [Inferior 1 (process 3824) exited normally] #即出 (gdb) q
范例2:
- list 显示源代码
- break 11 在第11行打断点
- break 12 在第12行打断点.
- 如果有函数名add,也可以给函数下断点 b add;
- 条件断点 b 20 if i == 2500 在第20行i等于时加断点
- info breakpoints 查看断点信息
- run 调试,程序停在第一个断点位置
- print myVec的值。 保存在临时存储区,从$1开始。
- next下一个
- print myVec的值,发生变化
- continue 运行到下一个断点
(gdb) list
1 #include<iostream>
2 #include<iterator>
3 #include<vector>
4
5 using namespace std;
6
7 int main()
8 {
9 vector<int> myVec;
10 myVec.push_back(2);
(gdb)
11 myVec.push_back(3);
12 cout << "Hello World"<<endl;
13
14 cout <<"vect size: "<<myVec.size() <<endl;
15 return 0;
16 }
(gdb) break 11
Breakpoint 1 at 0x140001483: file test.cpp, line 11.
(gdb) break 12
Breakpoint 2 at 0x14000149a: file test.cpp, line 12.
(gdb) info breakpoints
Num Type Disp Enb Address What
1 breakpoint keep y 0x0000000140001483 in main() at test.cpp:11
2 breakpoint keep y 0x000000014000149a in main() at test.cpp:12
(gdb) run
Starting program: d:\tmp\emacs\test.o
[New Thread 7812.0x4d34]
[New Thread 7812.0x4864]
[New Thread 7812.0x3bdc]
Thread 1 hit Breakpoint 1, main () at test.cpp:11
11 myVec.push_back(3);
(gdb) print myVec
$1 = std::vector of length 1, capacity 1 = {2}
(gdb) next
Thread 1 hit Breakpoint 2, main () at test.cpp:12
12 cout << "Hello World"<<endl;
(gdb) print myVec
$2 = std::vector of length 2, capacity 2 = {2, 3}
(gdb) continue
Continuing.
Hello World
vect size: 2
[Thread 7812.0x4d34 exited with code 0]
[Thread 7812.0x4864 exited with code 0]
[Thread 7812.0x3bdc exited with code 0]
[Inferior 1 (process 7812) exited normally]
(gdb)
集成开发环境
集成开发环境(IDE)
集成开发环境是一个软件工具,允许我们在同一个界面下完成源文件的创建和编辑、程序的翻译、执行和调试功能。
- code::blocks https://www.codeblocks.org/
windows下载 codeblocks-20.03-setup-nonadmin.exe
配置
- Sttings –>Compair–>Selected compiler–>GNU GCC Compiler
- GCC安装目录 Sttings –>Compair–>Toolchain excutables
- 调试器 Sttings –>Debugger–>Default–>Executeable path 找到gdb.exe路径,如D:\msys64\mingw64\bin\gdb.exe–>OK
创建工程
- File–>New–>Project–>可选控制台应用程序Consle application
函数
函数的调试
long long add (long long a, long long b) { return a + b; } int main(void) { long long x, y; x = add (100, 200); y = add (799, 321); return 0; }
函数和函数调用
add (100, 200) 函数调用表达式。 ( ) 函数调用运算符 (long long a, long long b) 形参,形式上的参数 (100,200) 实参,实际提供的参数
加性和乘性运算符
long long add (long long a, long long b) { return a + b; } long long sub (long long a, long long b) { return a - b; } long long mul (long long a, long long b) { return a * b; } long long div (long long a, long long b) { return a / b; } long long mod (long long a, long long b) { return a % b; } int main(void) { long long m; m = add (15, 6); m = sub (15, 6); m = mul (15, 6); m = div (15, 6); m = mod (15, 6); return 0; }
指针
变量的初始化
int main (void) { int a = 10086, b = 10010; int tmp = a; a = b; b = tmp; return 0; }
初始化器: int a = 10086, b = 10010;
注意,声明、表达式和语句是不同的东西,等于号出现在表达式里,它是一个运 算符,是赋值运算符。但这里是声明,不是表达式,所以,这个等于号不是赋值 运算符,而是标点符号,是连接符,意思是“来自于”或者“来源于”,用于在 标识符后面连接一个表达式,也就是初始化器。
变量值的互换问题
void swap (int x, int y) { int tmp = x; x = y; y = tmp; } int main (void) { int a = 10086, b = 10010; swap (a, b); return 0; }
swap(a, b) 传递的是a, b的值。实现交换需要使用指针才能完成。
取地址和间接运算符
变量是内存中的存储区。处理器内部有临时存放数据的寄存器。
在计算机中组成内存的基本单元是字节,也就是说可以将内存看成由大量的字节堆叠而成。
组成内存的字节都有一个编号,叫做地址。而且每个字节都有一个唯一无二的地址。
字节是排顺序编号的,所以地址是递增的。第一个字节的地址是0,第二字节的地址是1,第3个字节的地址是2,以此类推。
变量可能对应着一个字节单元或者连续的多个字节单元,因为单个字节存储不了多大的数字。

int main (void) { int x; x = 10086; * & x = 10010; return 0; }
x = 10086 把10086写入变量x
* & x = 10010;
如果需要,C语言也允许我们通过变量的地址来访问它。在第二条语句里,对变 量x的访问就是通过地址进行的。在这里,&是一个运算符,它用于取得变量x的 地址。这里的*也是运算符,它作用于地址,并重新得到变量x本身。
在c语言里,运算符 & 用于取得一个变量或者函数的地址,所以叫 取地址运算符 。这是个一元运算符,因为它只需要一个右操作数。
星号 运算符用于根据一个地址来得到那个变量或者函数本身。这是一种还原操作,要通过地址来间接进行,所以叫 间接运算符 。
星号不是乘法运算符么?是的,同一个符号具有不同的功能,这在C语言里很常 见,区分它们的方法是看它们的操作数和具体的用法。乘法运算符需要一左一右 两个操作数,是二元运算符,而间接运算符只需要一个右操作数,是一元运算符。
括住的表达式
取地址运算符,用于取一个变量或函数的地址。
间接运算符,根据地址直接还原那个变量或者函数。
int retd (int a, int b, int c) { return (a + b) * c; } int main (void) { int x, y; x = retd (20, 30, 50); y = (* & retd) (20, 30, 50); return 0; }
注意,这里使用了括号,这是什么意思呢?
在这里,赋值运算符的优先级最低,所以,它右侧的子表达式有没有括号对它没 有任何影响。但是,在这个子表达式里,函数调用运算符的优先级高于取地址和 间接运算符。如果没有括号,这个子表达式将是非法的,不能通过翻译。
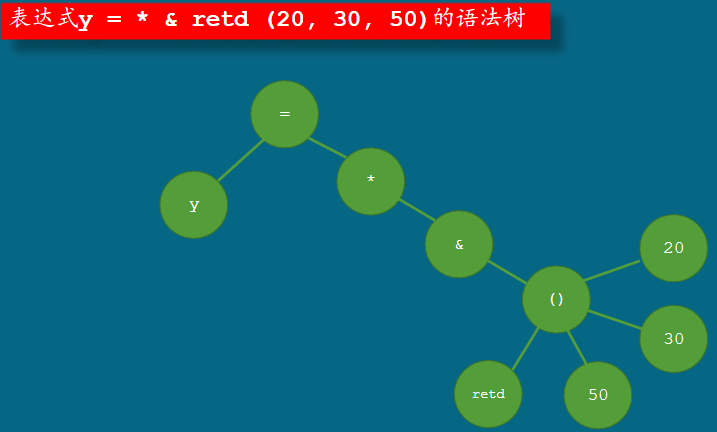
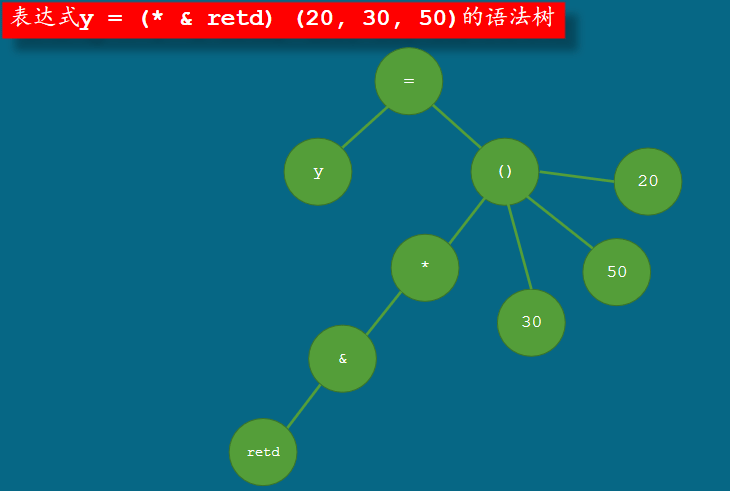
在C语言里,用圆括号括住的表达式,连同这对括号一起,称为括住的表达式。 括住的表达式等同于那个被括住的表达式,括住的表达式独立计算,它的值是被 括住的那个表达式的值。
什么是指针
通过地址,你无法知道在这个地址上到底是一个变量,还是一个函数。如果取地 址运算符的结果仅仅是一个地址,那么,当间接运算符拿到这个地址时,它无法 知道这个地址上到底是变量还是函数。
取地址运算符的结果并不单纯是一个地址,而是一个带有类型信息的地址。当间 接运算符作用于它时,也将还原出它的原始类型信息。
- 指针是带有类型信息的地址
- 指针是一种数据类型。 如表达式
& m的值是一个指针
区分指向不类型的指针
整数类型是一个统称,可细分为signed char、int、unsigned long int,等等。
指针类型也是统称,可细分为不同的指针类型,比如指向signed char的指针、指向int的指针、指向signed long int的指针,等等。
如果操作数的类型是 T ,则取地址运算符的结果是指向 T 的指针。给定以下的声明:
int x; long long y;
则表达式 & x 的值是指向int的指针,指向变量x;表达式 & y 的值是指向long long的指针,指向变量
取地址和间接运算符的总结
一元&运算符的操作数必须是左值或者函数指示符,& 250是错误的; 一元*运算符的操作数必须是指针; 一元*运算符用来还原指针所指向的变量或者函数; 如果操作数是指向某变量的指针,则一元 * 运算符的结果是个左值,代表那个变量; 如果操作数是指向某函数的指针,则一元 * 运算符的结果是个函数指示符,代表那个函数。
间接运算符的说明
一元*运算符的操作数必须是指针; 一元*运算符用来还原指针所指向的变量或者函数; 如果操作数是指向某变量的指针,则一元 * 运算符的结果是个左值,代表那个变量; 如果操作数是指向某函数的指针,则一元 * 运算符的结果是个函数指示符,代表那个函数。
函数指示符-指针转换
int retd (int a, int b, int c) { return (a + b) * c; } int main (void) { int x; x = retd (20, 30, 50); return 0; }
上面程序里是否有指针?有。
虽然说你已经熟悉函数调用运算符和函数调用表达式,但是你可能并不是真的了 解它。因为,函数调用运算符的左操作数必须是一个指向函数的指针。
但是这里的(retd)并不是指针啊。
函数指示符–指针转换
C语言规定,除非是做为取地址运算符(&)的操作数,函数指示符将自动转换为指向函数的指针,这称为函数指示符-指针转换。
x = retd (20, 30, 50); # redtd 自动将函数指示符转换成指向函数的指针 (& retd) (20, 30, 50), 函数指示符retd本身不会转化为指针 x = (& retd) (20, 30, 50) #合法
间接运算符的还原操作
- 如果操作数是指向某变量的指针,则一元 * 运算符的结果是个左值,代表那个变量;
- 如果操作数是指向某函数的指针,则一元 * 运算符的结果是个函数指示符,代表那个函数。
范例:
x = retd (20, 30, 50); x = (* & retd) (20, 30, 50) #合法 #因为* & retd这个表达式的值是函数指示符,它可以做取地址运算符的操作数(& * & retd) #这将显示地得到一个指向函数的指针 x = (& * & retd) (20, 30, 50) #合法 #表达式(& * & retd)是一个指向函数的指针,它完全可以做为间接运算符的操作数(* & * & retd),如下 x = (* & * & retd) (20, 30, 50) #这将重新得到一个函数指示符,而且因为它不是取地址操作符的运算符,将自动转换为指向函数 #的指针(& * & * & retd)
上例,这一系列的修改都不过是在转圈圈,但它们很好地说明了函数指示符和指针之间是如何互相转换的
指针类型的变量
我们说过,指针是一种数据类型。既然是一种数据类型,那么就可以声明这种类型的变量。
另一方面,我们知道,取地址运算符的结果是一个指针,指针类型的值也应该可以保存到变量里,就象我们可以把一个整数保存到变量里面一样。
int main (void) { int a, b; a = 3; /*合法,两侧类型相同*/ b = & a; /*不合法, C语言是强类型语言*/ return 0; }
在第二条语句里,变量b的类型是整数,意味着它只能用来读写整数类型的值。 但是在赋值运算符的右侧,(这个子表达式)的值是一个指针。C语言是强类型 的语言,赋值运算符两侧的类型不同,这是不合法的。
如果想要保存一个指针到变量,变量的类型也必须是指针,
int main (void) { int a; int * p; return 0; }
指针的声明
int a; #a的类型是int int * p; #p的类型是指针int, 或者说p是一个指向int类型的指针 #这里的星号不是运算符,而是表示指针的符号。只有在表达式里才是运算符。
范例
int main (void) { int a; int * p; p = & a; return 0; }
上例,赋值运算符的左侧是一个左值,其类型为指向int的指针;在赋值运算符 的右侧,因为a的类型是int,所以(这个子表达式)的值是指向int的指针。两 侧类型一致,这个表达式没有问题,将把右侧的指针写入变量p。于是,我们现 在可以说,变量p的内容是一个指针,或者说变量p的值是一个指针。
变量p的值是指针,这个值指向另一个变量,也就是变量a。既然如此,我们应该 可以通过变量p来间接访问变量a。这当然是可以的,例如:
int main (void) { int a; int * p; p = & a; * p = 10086; return 0; }
间接运算符(*)的优先级高于赋值运算符,所以,p是间接运算符的操作数,赋值 运算符的子表达式是*P和10086。 左值p执行左值转换,转换为变量p的值。这个 值是指针,指向变量a。我们知道,如果操作数的类型是指向变量的指针,则间 接运算符的结果是一个左值,代表那个变量。所以,(这个子表达式)的结果是 一个左值,代表变量p的值所指向的变量,也就是变量a。
显然,这实际上是把10086写入(这个左值)所代表的变量,也就是写入变量a。
可以在 * p = 10086; 设置断点调试看看。
类型的派生
int a, * p;
指针类型是派生类型
在C语言中,指针类型是派生类型,是从已有的类型中派生出来的。指向int的指针是从int中派生的。
范例
int * a, p; /*a的类型是指向int的指针*/ int * p, * q; /*声明2个指针*/
范例
int main (void) { int a, * p = & a; /*指针初始化*/ * & * p = 10086; /*合法*/ * & * & * & * p = 65535; /*合法*/ return 0; }
指针的传递
void swap (int x, int y) { int tmp = x; x = y; y = tmp; } int main (void) { int a = 10086, b = 10010; swap (a, b); return 0; }
还记得这个程序吗,我们打算通过函数swap来交换变量a和变量b的值,但是没有 成功。这是因为,在函数调用时,只能传递值,而不可能传递变量本身。
但是,当我们学习了指针后,这个问题就迎刃而解了。因为我们可以传递指向变 量a和变量b的指针,在函数swap里,通过指针来找到变量a和变量b并交换它们的 值。
void swap (int * p, int * q) { int tmp = * p; * p = * q; * q = tmp; } int main (void) { int a = 10086, b = 10010; swap(& a, & b); return 0; }
- 函数swap的参数类型是指向int的指针,当函数调用时,参数p和q将创建为指针类型的变量,并接受传递给它们的指针。
- main函数,在调用函数swap时,我们传递的是这两个表达式的值。在这里,取 地址运算符分别取得变量a和变量b的地址。或者说,这两个表达式分别生成了 指向变量a和变量b的指针。然后,将这两个指针传递给函数swap的形参。
- 回到函数swap,形参p和q是两个变量,它们接受传递过来的实参,所以它们的值分别指向变量a和变量b。
void swap (int * p, int * q)
{
int tmp = * p;
#我们声明了变量tmp并用(这个表达式*p)的值初始化它。
#在这里,左值p执行左值转换,转换为变量p的值。这是一个指针,指向变量a。
#间接运算符*作用于这个指针,得到一个左值,代表变量a。当然,你可以认为我们
#得到了变量a。(这个左值* p)执行左值转换,转换为变量a的值,然后用于初始化变量tmp。
#此时,变量tmp的值等于变量a的值。换句话说,我们这一步是把变量a的值复制到变量tmp。
* p = * q;
#在赋值运算符的右侧* q,左值q执行左值转换,转换为变量q的值,这是一个指针,指向变量b。
#间接运算符*作用于这个指针,得到一个左值,代表变量b。(这个左值* q)执行左值转换,转换为变量b的值。
#在赋值运算符的左侧* p,左值p执行左值转换,转换为变量p的值,这是一个指针,指向变量a。
#间接运算符作用于这个指针,得到一个左值,代表变量a。(这个左值*p)是赋值运算符的左操作数,不执行左值转换,而是接受赋值。
#因此,这条语句实际上是把变量b的值写入变量a。
* q = tmp;
#在赋值运算符的左侧* q,左值q执行左值转换,转换为变量q的值,这是一个指针,指向变量b。
#间接运算符作用于这个指针,得到一个左值,代表变量b。(这个左值)是赋值运算符的左操作数,不执行左值转换,而是接受赋值。
#在赋值运算符的右侧,左值tmp执行左值转换,转换为变量tmp的值。因此,这条语句实际上是把变量tmp的值写入变量b。
}
#至此,变量a和变量b的值交换完毕。
数组
编程是为了解决生产、生活的问题。
数组和数组的声明
数组
int a [300];
在这里,a是变量的名字,它是一个大变量,包含了300个小的子变量,所有子变 量的类型都是int。显然,这是一种好办法,允许我们一次性声明300个变量,但 遗憾的是,这300个变量只有一个统一的名字a。
数组,一组数据或者成组的数据,是数据的集合体。数组的子变量称为元素。这里数组a有300个元素。
数组声明
解析一个声明要从标识符开始,向左或者向右读。如果标识符右边是中括号 [ 或者 ( 圆括号,则必须先向右读。
如果是中括号就意味着这是一个数组。
这里,a右边是中括号,所以向右读,读作a的类型是数组。元素的数据在方括号内部,300。继续向右直至遇到向右的中括号。 右中括号右边如果没有东西就转而向左读,左边是类型指定符int,这是数组的元素类型,所以我们读作元素类型是int。最后 整个过程合并在一起,读为,a是一个数组,该数组有300个元素,元素的类型是int。
数组变量的初始化
int a [300] = {33, 55, 66, 77, 88};
a [0] 33 [1] 55 [2] 66 [3] 77 [4] 88 [5] 0 <repeats 295 times>
在C语言里,凡是带有子变量的变量,它的初始化器都应当以花括号作为开始和结束。
如果带有初始化器,则数组声明时的中括号内可以不指定元素数量,就象这样
int a [] = {33, 55, 66, 77, 88};
此时,数组的大小取决于初始化器。在这里,我们提供了5个数字,所以这个数组的大小是5。
实数浮点数类型
浮点类型
- 实数浮点数类型(简称实浮点类型)
- 复数类型
实浮点类型
- float 至少精确到小数点后6位数字;可表示的最大值起码为 \(3.4 \times 10^38\)
- double 至少精确到小数点后10位数字;可表示的最大值起码是 \(1.79 \times 10^308\)
- long double 至少精确到小数点后19位数字;可表示的最大值起码是 \(1.1 \times 10^4392\)
float a [300] = {500.0, 521.5, 551.0, 522.0, 530.9};
数组-指针转换
一旦错过了初始化阶段,你再也无法为它整体赋值。
int main (void) { int a [5]; a = {1, 2, 3, 4, 5}; /*非法*/ return 0; }
这样写是非法的。原因在于:
- 第一,赋值运算符的右操作数必须是一个表达式并得到这个表达式的值,但这这里的{…}并不是表达式,它只能在数组的声明里用做初始化器。
- 第二,在C语言里,数组类型的左值是一个不可修改的左值。也就是说,一个数组类型的左值不能是赋值运算符的左操作数。再说得直白点,在这里,a不能出现在赋值运算符的左边。
因为C语言的发明者有另外的想法。它想让数组和指针之间建立一种特殊的关系,为编程提供便利。
数组-指针转换
- 除非是做为一元 & 或者 sizeof 运算符的操作数,或者是一个用作初始化器 的字面串,否则,一个元素类型为 T 的数组会被自动转换为指向T的指针,并 指向该数组的首元素。
范例:
int main (void) { int a [3] = {10, 20, 30}, b, * p; * a = 15; b = * a; p = a; b = * p + * a; return 0; }
在第一条语句里,a是数组,自动转换为指针且指向该数组的第一个元素。因为a 的元素类型是int,所以转换后的类型是指向int的指针。间接运算符的优先级高 于赋值运算符,所以,a是间接运算符的操作数。当它转换为指针后,间接运算 符作用于这个指针,得到一个左值,代表数组的第一个元素,因为它是赋值运算 符的左操作数,不执行左值转换而是接受赋值。所以,这条语句是把15写入数组 a的第一个元素。
在第二条语句里,a是数组,自动转换为指针且指向该数组的第一个元素。因为a 的元素类型是int,所以转换后的类型是指向int的指针。间接运算符的优先级高 于赋值运算符,所以,a是间接运算符的操作数。当它转换为指针后,间接运算 符作用于这个指针,得到一个左值,代表数组的第一个元素,在这里,它将执行 左值转换,转换为数组第一个元素的值。所以,这条语句是把数组第一个元素的 值15读出并写入变量b。
在第三条语句里,a是数组,自动转换为指针且指向该数组的第一个元素。因为a 的元素类型是int,所以转换后的类型是指向int的指针。接着,这个指针被写入 同类型的指针变量p。
在第四条语句里,间接运算符的优先级最高,加法运算符次之,赋值运算符最低。所以,(这个间接运算符*)的操作数是p;(这个间接运算符*)的操作数是a;加法运算符的操作数是(这个子表达式* p和这个子表达式 * a的值)。
左值p执行左值转换,转换为变量p的值,这是一个指针,指向数组a的第一个元素。间接运算符作用于这个指针,得到一个左值,代表数组的第一个元素,并执行左值转换,得到数组第一个元素的值15。
左值a的类型是数组,按照数组到指针的转换规则,转换为指针,指向数组的第一个元素。间接运算符作用于这个指针,得到一个左值,代表数组的第一个元素,并执行左值转换,得到数组第一个元素的值15。
加法运算符将上述两个数值相加,得到的结果是30,并将这个结果赋给左值b,或者说写入变量b。此时,变量b的值是30。
数组并不是在所有情况下都会转换为指针
- 当数组是取地址运算符的操作数时,不转换为指针。
- 如果数组是运算符sizeof的操作数,则不执行数组到指针的转换。
范例:数组不转换为指针的2种情况
int main (void) { int a [3] = {10, 20, 30}, b, * p; /*当数组是取地址运算符的操作数时,不转换为指针*/ b = * * & a; /* 如果数组是运算符sizeof的操作数,则不执行数组到指针的转换*/ unsigned u; u = sizeof a; u = sizeof p; char s [] = "hello"; return 0; }
在第一条语句里,数组a是取地址运算符(&)的操作数。此时,数组a并不转换为指针。如果转换为指针,则意思是取指针的地址,这就荒谬了。
如果操作数的类型是任意类型T,则取地址运算符的结果是得到一个指向T的指针。在这里,a的类型是数组,所以这个子表达式 (& a) 的值是指向数组的指针。
如果操作数的类型是指向任意类型T的指针,则间接运算符的结果是类型T。在这
里,这个子表达式 (& a) 的值是指向数组的指针,所以,这个子表达式 (*
& a) 的结果是数组。等于是一个还原操作, 从指向数组的指针还原为数组。
因为这个子表达式 (* & a) 的类型是数组,所以执行数组到指针的转换,自动转换为指针,并指向数组a的第一个元素。
因为这个子表达式 (* & a) 的结果是指针,最左边的间接运算符作用于它,
得到一个左值,代表数组a的第一个元素。紧接着,它执行左值转换,转换为数
组a第一个元素的值,并赋给b。非常关键的是,变量b的类型是int,而数组第一
个元素的值也是int,所以能够赋值。
在某此方面,C语言是很古怪的。很多运算符都是标点符号,但这个运算符 (sizeof) 却是一个单词,很象函数。但它并不是函数。
sizeof运算符可以得到变量的大小,以它所占用的字节数计算。
在这条语句里 (u = sizeof a;) ,sizeof运算符得到变量a,也就是数组a的
大小,并写入变量u。sizeof运算符的结果是一个无符号整数,所以我们声明了
一个unsigned 类型的变量u来接受它的值。我们发现,数组a的大小是12,这是
怎么算的呢?它是用元素的数量乘以元素的大小。在我的机器上,int类型的变
量占用4个字节,数组a有3个元素,所以数组a的总大小是12。
在这条语句里 (u = sizeof p;) ,sizeof运算符得到指针变量p的大小。变量p的大小是8
在最后一条语句里 (char s [] = "hello") ,(这个东西 "hello" )叫做
字面串,它是一个数组。这个字面串充当了数组s的初始化器。在这种情况下,
这个奇特的数组并不会转换为指针。执行这一行,来看,当数组s创建并初始化
之后,它的内容是 "hello"
指针的运算
通过指针访问数组元素
既然数组可以自动转换为指向数组首元素的指针,那么我们可以很容易想到,数 组元素大小相同而且是连续的,只要移动这个指针令它依次指向数组的其他元素 不就可以访问数组的其他元素了吗?C语言就是这样访问数组元素的。
指针的加减运算
- 可以把指针和整数放在一起做加减运算;
- 将指针加上或者减去一个整数,其结果仍然是一个指针;
- 如果一个指针指向数组的第 i 个元素,在数组足够大的情况下,将这个指针 加上或者减去整数 n,则相加或者相减的结果是指向数组第 i+n 或者 i-n 个 元素的指针。
范例:指针的加减运算
int main (void) { int a [3]; * a = 10; * (a +1) = 20; * (a + 2) = * (a + 1) + 10; return 0; }
我们声明了一个数组变量a,它有3个int类型的元素。
在第一条语句里 (* a = 10;) ,a的类型是数组,自动转换为指针并指向数组
的第一个元素。紧接着,间接运算符 (*) 作用于这个指针,得到一个左值,
代表数组a的第一个元素,并接受赋值,也就是把10写入数组a的第一个元素。
在第二条语句里 (* (a + 1) = 20;) ,间接运算符 (*) 的优先级最高,加
法运算符 (+) 次之,赋值运算符 (=) 的优先级最低。如果没有括号的话,
a是间接运算符的操作数,但我们的本意并非如此,所以要把a加1用括号括起来,
组成一个括住的表达式。
在括号内部,a的类型是数组,自动转换为指针并指向数组的第一个元素。将它加1后,得到一个新的指针,指向数组的下一个元素,也就是第二个元素。
括住的表达式的值等于被括号括住的那个表达式的值。所以(这个表达式 (a+1) 的值)等于这个表达式 ((a + 1)) 的值。
因为这个表达式 ((a + 1)) 的值是一个指针,指向数组的第二个元素,间接
运算符 (*) 作用于这个指针,得到一个左值,代表数组的第二个元素,并接
受赋值。执行这条语句,数组的第二个元素已经变量20。
在第三条语句里,因为运算符优先级的关系,这个复杂的表达式等价于
(* (a + 2)) = ((* (a + 1)) + 10);
显然,在赋值运算符的左侧,这个表达式 ((a+2)) 是一个指针,指向数组的
第三个元素,这个表达式 ((* (a + 2))) 是一个左值,代表数组的第三个元
素,并接受赋值。在赋值运算符的右侧,这个表达式 ((a+1)) 是一个指针,
指向数组的第二个元素,这个表达式 ((* (a+1))) 是一个左值,代表数组的
第二个元素,并执行左值转换,转换为数组第二个元素的值,也就是20;这个表
达式 (((* (a + 1)) + 10)) 将20和10相加,得到一个结果30。
也就是说,这条语句是把数组第二个元素的值和10相加,得到30,并写入数组的第三个元素。
指针运算的特殊性
指针 + 1 = ?
指针加减法的意义在于,如果指针指向一个数组元素,那么将它和一个整数相加减是要指向数组的其他元素。
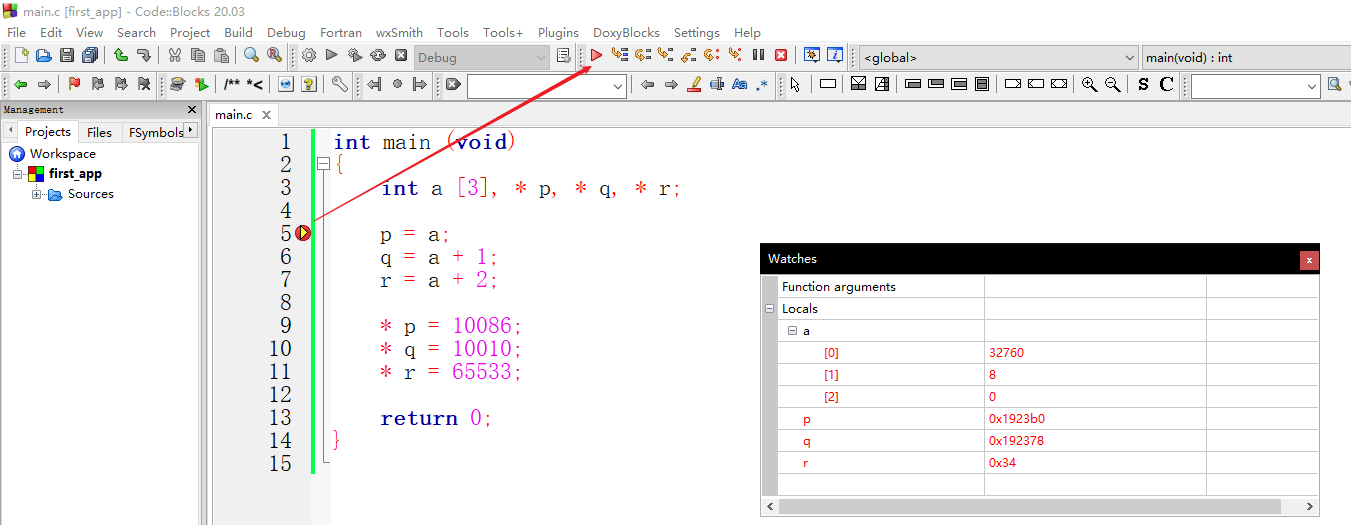
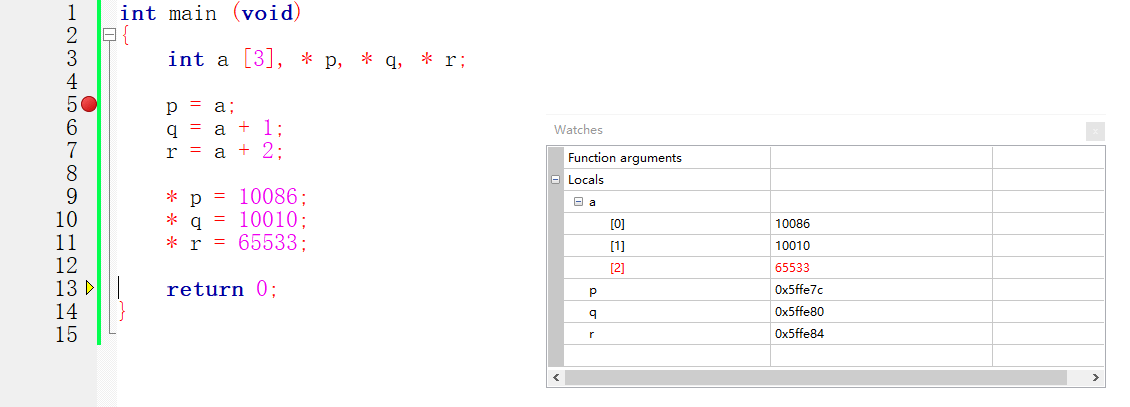
int main (void) { int a [3], * p, * q, * r; p = a; q = a + 1; r = a + 2; * p = 10086; * q = 10010; * r = 65533; return 0; }
我们声明了数组a和指针变量p、q、r。需要再次提醒的是,在声明里,星号是指针的意思,如果要一次性声明多个指针变量,则它们各自需要使用一个星号。
在第一条语句里 (p = a;) ,a是数组,自动转换为指针并指向数组的第一个元素,我们将这个指针写入变量p。此时,变量p的内容是数组第一个元素的地址,我们启动调试器,来看一下这个地址是多少 0x5ffe7c
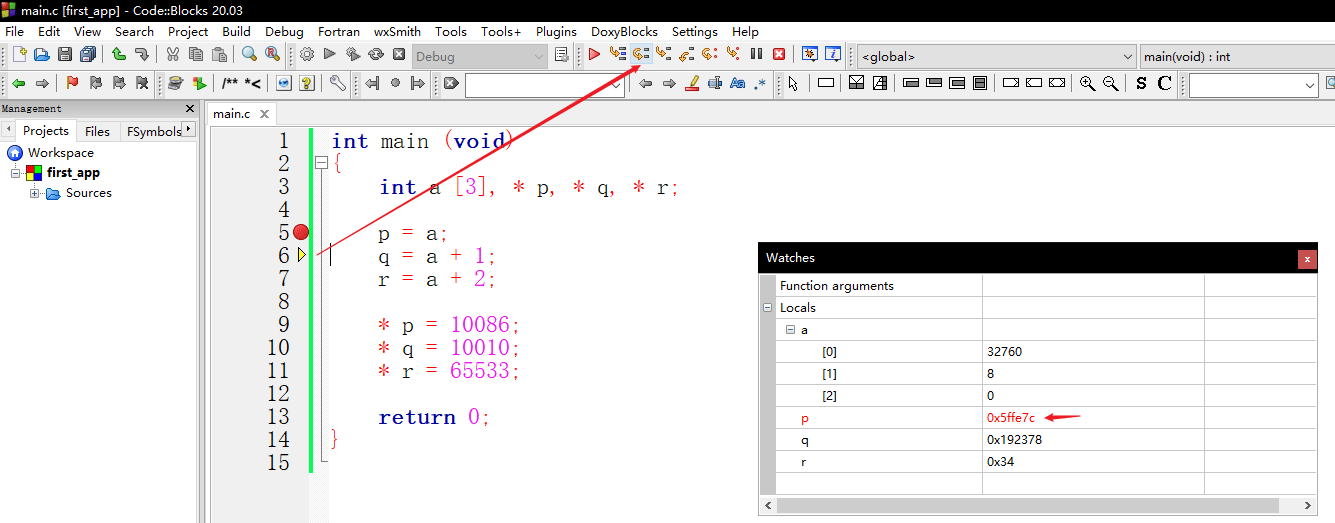
第二条语句 (q = a + 1) 是把指向数组第二个元素的指针写入变量q,或者通俗地说,是把数组第二个元素的地址写入变量q。我们来看一下,当这条语句执行后,变量q的内容是多少 0x5ffe80
0x5ffe80 比 0x5ffe7c 大了4。
在数学上,变量p和q的内容应该相差为1。但是显然,将指针加1后,实际得到的数值并不是在原来的基础上多1,而是多了4。这是为什么呢?
我们知道,内存的基本组成是字节单元,每个字节单元都有一个地址,相邻字节 单元的地址是连续的,在数值上相差1。数组是由元素组成,元素的大小取决于 它的类型,可能占用一个字节,也可能占用好几个字节。
在我的机器上,int类型的变量占用4个字节。因此,数组a的每个元素都占用4个 字节,相邻元素的地址之差为4。将指针加一,其意义在于使它指向下一个数组 元素,而不是指向内存里的下一个字节单元。所以,相加后的指针,在数值上自 然比原来大4了。
同样地,第三条语句是把指向数组第三个元素的指针写入变量r。写入后,变量r的内容在数值上比变量q的内容大4。
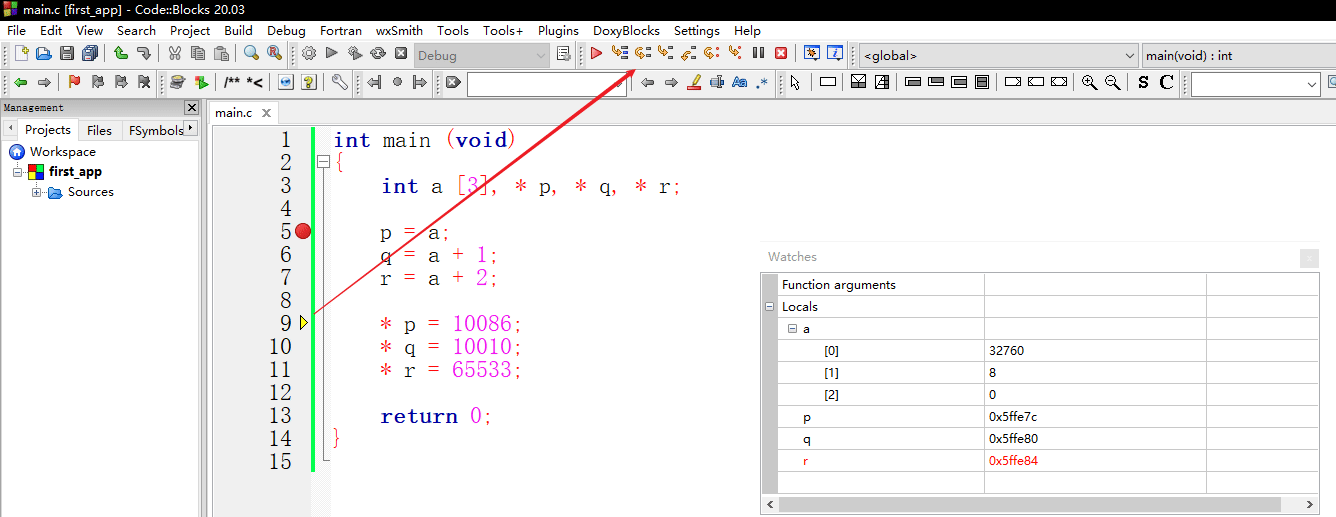
* p = 10086; * q = 10010; * r = 65533;
后面的三条语句是为数组的元素赋值。
在这条语句里 (* p = 10086) ,左值p执行左值转换,转换为变量p的存储值。这个值是指针,指向数组a的第一个元素。间接运算符 (*) 作用于它,得到一个左值,代表数组a的第一个元素,接受10086的赋值。换句话说,这条语句是把10086写入数组a的第一个元素里。
下标运算符
int main (void) { int a [3]; * a = 10086; * (a + 1) = 10010; * (a + 2) = 65533; return 0; }
我们已经尝试用指向数组首元素的指针来访问数组的每一个元素。来看这个程序 ,这里使用的方法我们已经不再陌生,
- 第一条语句是将10086写入数组a的第一个元素;
- 第二条语句是把10010写入数组a的第二个元素;
- 第三条语句是把65535写入数组a的第三个元素。
这里使用的方法就是C语言使用的方法,但是写起来很麻烦。为此,C语言提供了一个新的运算符,称为下标运算符,允许我们通过下标来直观地指定数组的元素。
数组下标运算符
- 数组下标运算符:[] - 数组下标运算符简称下标运算符,它需要两个操作数,一个在方括号左边,另一个在方括号里面; - 在这两个操作数中,一个是指针,我们把它所指向的变量看成是数组的第一个元素;另一个是整数,指定数组元素的下标。 - 下标运算符的结果是一个左值,代表那个具有指定下标的数组元素。
上面的程序可以修改为
int main (void) { int a [3]; a [0] = 10086; a [1] = 10010; a [2] = 65533; return 0; }
第一条语句 (a [0] = 10086;) ,这一对方括号是下标运算符,中间的整数0
是元素的下标,左边的a是数组,自动转为指向数组a首元素的指针。按照规定,
(这个子表达式 (a [0]) )的结果是一个左值,代表数组a的第一个元素,也
就是下标为0的元素,并接受赋值。所以,这条语句是把10086写入数组a的第一
个元素,也就是下标为0的元素。
第二条语句 (a [1] = 10010;) ,这一对方括号是下标运算符,中间的整数1
是元素的下标,左边的a是数组,自动转为指向数组a首元素的指针。按照规定,
(这个子表达式)的结果是一个左值,代表数组a的第二个元素,也就是下标为1
的元素,并接受赋值。所以,这条语句是把10010写入数组a的第二个元素,也就
是下标为1的元素。
下标运算的本质
- 本质上,表达式 a [n] 等价于 * (a + n)。 - 值得一提的是,C语言并未规定 a [n] 中 a 和 n 哪一个是指针,哪一个是整数,所以 a [n] 和 n [a] 都是合法的,而且是等价的。
范例:C语言并未规定 a [n] 中 a 和 n 哪一个是指针,哪一个是整数,所以 a [n] 和 n [a] 都是合法的,而且是等价的
int main (void) { int a [3]; 0 [a] = 10086; 1 [a] = 10010; 2 [a] = 65533; return 0; }
另一方面,因为下标运算符要求的操作数是指针,而不是数组,所以,这些代码还可以改成这样:
int main (void) { int a [3], *p; p = a; p [0] = 10086; p [1] = 10010; p [2] = 65533; return 0; }
在这里,我们声明了一个指向int的指针变量p,然后,在这一条语句里,数组a 自动转换为指向其首元素的指针,并写入变量p。现在,变量p的值是指向数组a 首元素的指针。
(在这条语句里),左值p执行左值转换,转换为变量p的值。这个值是一个指向 数组a首元素的指针,而这个子表达式代表数组a的第一个元素,也就是下标为0 的元素,并接受赋值。执行这条语句后,10086被写入数组a的第一个元素,也就 是下标为0的元素。
文本的输出
计算机中的文本
在计算机内部一切皆数字,数字含义取决它是如何生成的又准备做什么用。例如机器指令是一堆有特殊含义的数字代表了让处理器执行的动作;例如从话筒录音时声音转换为电流,计算机将电流转换为数字,这些数字存储在 计算机内部或者磁盘、U盘中,在播放时,计算机内转换器再次将数字转换为不同的电流驱动喇叭发声;
在计算机里存储文字并不是存储它的形状,我们通过键盘输入的文字也被转换为数字,这些数字代表了不同的字符;当这些数字需要打印或者显示的时候,打印机或者显示器将这些数字还原为他们的形状。
[root@proxy .jasper]# cat hello.txt hello world. [root@proxy .jasper]# hexdump -C hello.txt 00000000 68 65 6c 6c 6f 20 77 6f 72 6c 64 2e 20 0a |hello world. .| 0000000e
文字是以数字形式存储的,这些数字叫做文字的编码。换句话说,这些数字是文字的代码,每个数字代表一个字符。68代表h,65代表e, 6c代表l
你可能会问,既然在计算机内部,一切皆为数字,计算机如何知道这些数字到底代表什么呢?
答案是,它并不知道。一切都在于恰到好处的配合。当处理器工作时,我们提供的恰好是一个正确的程序,包含了机器指令。如果你把一个图片的内容当成机器指令让处理器执行,计算机将发生严重错误。
字符集和编码的历史
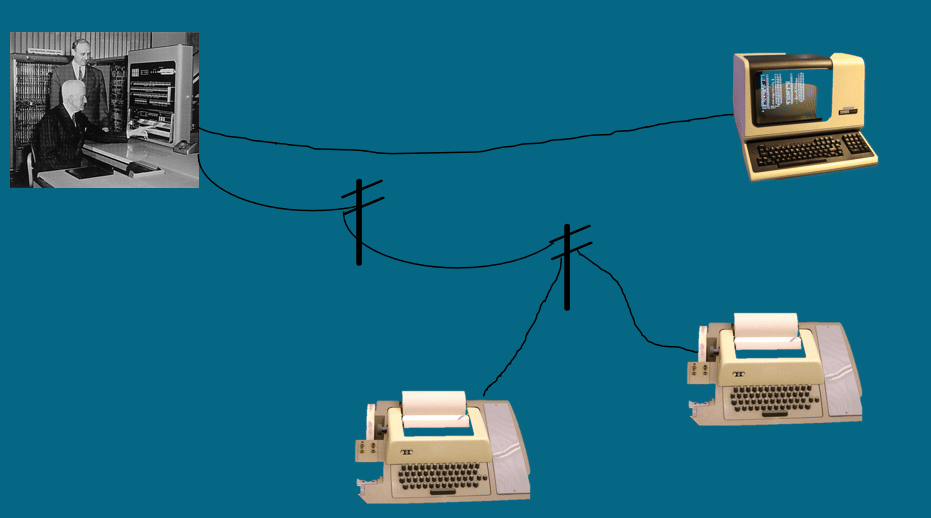
我们知道文字的信息是以数字的形式存储在计算机里。那么用哪个数字代表哪个字符呢? 必须要制定一个全球都认可的编码方案和编码标准,否则设备之间的文字交流将无法实现。 必须完成字符的收集和整理工作,使之形成一个字符的清单或者成为字符集。计算机 发展的早期字符是的制定是小范围的事,那时大型机是主流。为了使用大型机,需要 使用终端通过电缆和电话线与主机相连。 那个时候的终端都是电传打字机,少数带有显示器,电传打字机带有键盘可以向主机 发送命令,主机将处理结果送回终端。为了在主机和终端之间通信,有个双方都能理解 的码表,这就是早期的字符集和编码方式。 这个字符集用于在主机和终端之间传送控制命令和文字信息。最著名的是IBM公司的码表, 1967年 ASCII码.
ASCII字符集,共128个字符。 控制字符用来控制电传打字机的动作,如确认、响铃、查询、同步、回车、换行等。
ASCII字符集用代码点得到字符编码的实例
33 ! 34 " 35 # 36 $ 37 % 38 & 39 ' 40 (
41 ) 42 * 43 + 44 , 45 - 46 . 47 / 48 0
49 1 50 2 51 3 52 4 53 5 54 6 55 7 56 8
57 9 58 : 59 ; 60 < 61 = 62 > 63 ? 64 @
65 A 66 B 67 C 68 D 69 E 70 F 71 G 72 H
73 I 74 J 75 K 76 L 77 M 78 N 79 O 80 P
81 Q 82 R 83 S 84 T 85 U 86 V 87 W 88 X
89 Y 90 Z 91 [ 92 \ 93 ] 94 ^ 95 _ 96 `
97 a 98 b 99 c 100 d 101 e 102 f 103 g 104 h
105 i 106 j 107 k 108 l 109 m 110 n 111 o 112 p
113 q 114 r 115 s 116 t 117 u 118 v 119 w 120 x
121 y 122 z 123 { 124 | 125 } 126 ~
现今绝大数字符集都兼容ASCII字符集。
字符数组
我们已了解到文字信息是以数字编码的方式存储在计算机中,都是一些数字。那么,可以用数组来存储这些数字,相当于存储了文本。
我们知道数组的元素是连续的,元素的类型也都相同,文字的编码都是一些整数,所以,在声明一个用来保存文本的数组时,应当 将它的元素类型指定为整数类型。
- 文本的存储可以使用元素类型为整数的数组。
- 英语系国家和地区的字符编码:使用 signed char 和 unsigned char ?
- char 等价于 signed char 或者 unsigned char
- 在C语言里,char、signed char 和 unsigned char 合称为字符类型,因为在历史上,它们用来保存字符的编码。但实际上,它们也是整数类型。

int main (void) { char txt [6]; txt [0] = 104; txt [1] = 101; txt [2] = 108; txt [3] = 108; txt [4] = 111; txt [5] = 46; return 0; }
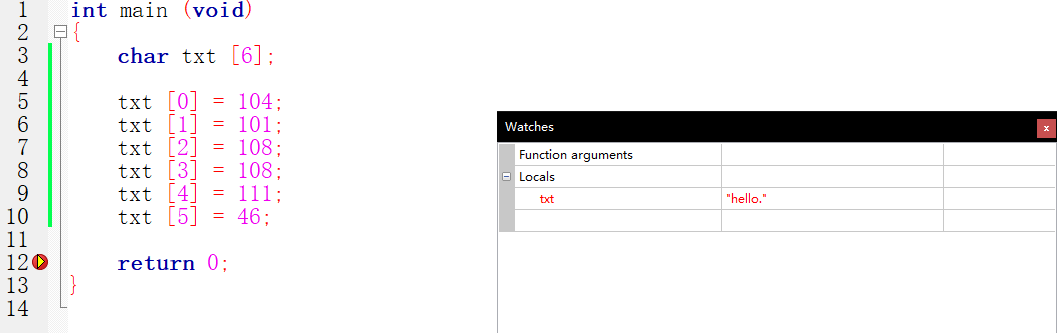
调试器对char类型的变量特殊对待,它认为你保存的是文字,所以文本的内容显示为一串而不是显示单个的元素。
实际上,我们也可以在声明时用初始化器指定字符的编码, 如下
int main (void)
{
char txt [6] = {104, 101, 108, 108, 111, 46};
return 0;
}
字符常量
我们不可能总是记得字符的编码值是多少。同一个字符编码对于不同的字符集所代表的字符可能有所不同。
C语言为我们准备另一样东西:字符常量。
int main (void) { char txt [6] = {'h', 'e', 'l', 'l', 'o', '.'}; return 0; }
字符常量是由一对单引号,以及由单引号括住的字符序列组成。在程序翻译期间,字符常量被转换为当前所用字符集的字符编码。因此,字符常量虽然不象数字,但它的类型是整数。
我们也可以先声明字符数组,然后再用独立的语句给数组的每个元素赋值, 如下
int main (void) { char txt [6]; txt [0] = 'h'; txt [1] = 'e'; txt [2] = 'l'; txt [3] = 'l'; txt [4] = 'o'; txt [5] = '.'; return 0; }
C语言的原则之一是类型必须匹配。我们说过,字符常量的类型是整数,所以能赋给同样是整数类型的数组元素。
如何输出文本
C语言可以胜任各种算术和逻辑运算,并控制程序的执行过程,但并不具备输入和输出的能力。
但操作系统可以支持。
操作系统会提供很多接口让应用程序通过这些接口调用它的功能。这些操作系统接口类似于一个个的函数,让应用程序调用一些功能,所以又称为系统调用。
通过系统调用来显示文本。
Linux系统调用
C语言连使用系统调用的能力都没有。要解决这个问题,要使用汇编语言或者机器语言。汇编语言和机器语言是一一对应的等效的,但汇编语言要方便很多。
C语言和汇编语言是两码事是不同的语言。写C程序不能使用汇编语言,但不要忘了还有C实现,C实现两边语言都通精通两边语言的翻译。可以把汇编代码嵌入到C程序中,用来做C语言做不了的事。
只要C实现愿意并认可这种做法,那么它就可以生成一个可以做系统调用的程序了。
[root@proxy tmp]# cat main.c
int main (void)
{
char ws [] = {'h', 'e', 'l', 'l', 'o', '.'};
__asm__ (
"mov rax, 1 \n\t"
"mov rdi, 1 \n\t"
"syscall \n\t"
:
: "S" (ws), "d" (6)
);
return 0;
}
[root@proxy tmp]# gcc main.c -masm=intel #-masm用于指定汇编语言的格式
[root@proxy tmp]# ls
a.out main.c
[root@proxy tmp]# ./a.out
hello.
我们首先声明了数组ws并初始化为一串文本hello。然后,下面是嵌入的汇编语
言代码。汇编指令是提供给C实现的,为了与普通的C语言代码分开,需要一个标
志,这个标志就是(这一部分 __asm__ ) 。如果没有这个标志,C实现就会把这些
汇编语言指令当成C语言来翻译。后面圆括号里的内容就是用汇编语言写的代码。
在汇编指令中
- (这一部分
mov xxxxx)用来传递参数,传入两个1是告诉操作系统我们要在屏幕上输出文本; - (这一部分
"S" (ws))是用来传入数组首元素的地址。因为数组的元素是连续的,只需要传入首元素的地址即可,操作系统自会找到后续的字符。在这里,数组ws自动转换为指向其首元素的指针; - (这一部分
"d" (6))是传入数组的长度,也就是字符的个数。hello连同一个句点共是6个字符,所以我们传入的是6。 - 这条syscall指令用于发起系统调用并转入操作系统内部执行。
脱转序列
'h' 'e' 'l' 'l' 'o' '.'
像这些都是字符常量,但有些不能用字符常量表示,如回车、换行字符。C语言提供了脱转序列或者按照流行的说法转义序列。
脱转序列的作用是将一个字符序列从原来的文本中脱离出来,转换和替代为一个新的字符。
脱转序列是以“\”引导的字符序列。以下是常用的脱转序列:
\a 警示。以声音或者图形发出警示信息 \b 退格。光标或者字车回退到当前行的上一个打印位置 \n 换行。光标或者字车移动到下一行的行首 \r 回车。光标或者字车移动到当前行的行首 \t 水平制表符。对应于键盘上TAB键的字符编码
[root@proxy tmp]# cat main.c
int main (void)
{
char ws [] = {'h', 'e', 'l', 'l', 'o', '.', '\n'};
__asm__ (
"mov rax, 1 \n\t"
"mov rdi, 1 \n\t"
"syscall \n\t"
:
: "S" (ws), "d" (7)
);
return 0;
}
[root@proxy tmp]# gcc main.c -masm=intel
[root@proxy tmp]# ./a.out
hello.
[root@proxy tmp]#
除了前面那些常用的脱转序列,我们也可以在反斜杠的后面直接使用字符的编码,但必须使用八进制或者十六进制数字。
- 八进制数字,它可以直接写在反斜杠后面。例如字符h的编码是十进制数字104,转换为八进制后,是150,所以它的脱转序列是\150;
- 十六进制,则反斜杠后面要先写一个小写字母x,然后才是字符编码。字符e的编码是十进制数字101,转换为十六进制后是65,所以采用十六进制的脱转序列是\x65。
对于单引号,使用\',对于斜杠,使用\\
[root@proxy tmp]# cat main.c
int main (void)
{
char ws [] = {'\150', '\x65', 'l', 'l', 'o', '.', '\'', '\\', '\n'};
__asm__ (
"mov rax, 1 \n\t"
"mov rdi, 1 \n\t"
"syscall \n\t"
:
: "S" (ws), "d" (9)
);
return 0;
}
[root@proxy tmp]# gcc main.c -masm=intel
[root@proxy tmp]# ./a.out
hello.'\
[root@proxy tmp]#
编译和链接
如果别人想使用这些代码,只需要把这些代码封装成一个函数,并放到一个独立的文件中,再把这个文件发给你的朋友,他就可以使用了。
假定这个文件是print.c,而且你的朋友已经得到了这个文件,我们来看它的内容。这是一个普通的源文件,只有一个函数myprint。这个函数不返回任何值,所以它的返回类型是void;
这个函数接受两个参数,第一个参数s是指向char类型的指针,它应该指向字符数组的第一个元素;第二个参数n是unsigned类型,它是unsigned int的简写,这个参数用于指定要输出多少个字符。
在函数内部,这两个参数被传递给系统调用。左值s执行左值转换,转换为形参变量s的值,并传递给系统调用。我们知道,这个值是指向数组首元素的指针;左值n执行左值转换,转换为形参变量n的值,并传递给系统调用,这个值是输入的字符个数。
为了使用这个函数,你的朋友需要创建一个自己的源文件,假定他已经创建了这个源文件,名字叫main.c,它的内容如下。
[root@proxy tmp]# ls
main.c print.c
[root@proxy tmp]# cat print.c
void myprint (char * s, unsigned n)
{
__asm__ (
"mov rax, 1 \n\t"
"mov rdi, 1 \n\t"
"syscall \n\t"
:
: "S" (s), "d" (n)
);
}
[root@proxy tmp]# cat main.c
void myprint (char *, unsigned);
int main (void)
{
char ws [] = {'\150', '\x65', 'l', 'l', 'o', '.', '\n'};
myprint (ws, 7);
return 0;
}
#直接编译报错
#因为程序在翻译和运行时,必须能够找到函数的定义,也就是带有函数体的函数声明。
[root@proxy tmp]# gcc main.c
/tmp/ccWsi3Lk.o: In function `main':
main.c:(.text+0x31): undefined reference to `myprint'
collect2: error: ld returned 1 exit status
[root@proxy tmp]# gcc -c main.c #生成一个目标文件main.o
[root@proxy tmp]# gcc -c print.c -masm=intel #需要指定汇编格式,生成print.o
[root@proxy tmp]# ls
main.c main.o print.c print.o
#将目标文件链接在一起
[root@proxy tmp]# gcc main.o print.o #生成a.out
[root@proxy tmp]# ./a.out
hello.
#合并翻译过程
[root@proxy tmp]# gcc main.c print.c -masm=intel
[root@proxy tmp]# ./a.out
hello.
在这个main.c文件里,他声明了一个字符数组并初始化为文本hello、句点和换行字符。接着,他使用下面的语句来调用你的函数myprint。
函数在调用之前必须声明。这个函数在另一个源文件里,你只需要在调用之前做一个不带函数体的声明即可。这个声明放在哪里都行,只要它位于调用之前。一般来说,我们会将它放在源文件的开头 。
void myprint (char *, unsigned);
在不带函数体的函数声明中,参数的名字是不必要的,可以省略,但是参数的类型必须保留,因为函数调用时,将对照函数的声明做参数类型检查。 在这里,第一个参数的名字省略了,只有类型,是指向char的指针;第二个参数的名字也省略了,但它有类型保留,是unsigned。
如果仅仅使用 gcc main.c 这将出错,并出现一堆错误信息,告诉我们找不到
函数myprint的定义。这是很显然的,在源文件main.c里,函数myprint只是做了
不带函数体的声明就直接调用,但程序在翻译和运行时,必须能够找到函数的定
义,也就是带有函数体的函数声明。否则的话,没有函数体,怎么可能调用并执
行函数呢?
没在关系,我们有这个函数的定义,只不过它位于另一个源文件里,只要想办法让它找到这个定义即可。
在C语言里,一个C程序可以由多个源文件组成。在翻译时,C实现将分别翻译这些源文件,并把它们链接到一起生成可执行程序。C实现对源文件的翻译分为两个大的阶段。
- 第一个阶段是编译,对C语言源文件的内容进行语法分析,进而生成对应的机 器指令。但是,对有些实体(比如函数)的解析是无法完成的,因为它们可能 并不是在当前源文件内定义的。在这种情况下,C实现将记下这些名字,以及 它们的属性(比如函数的参数类型和返回类型)。因此,这个阶段的成果并不 是最终的可执行文件,而是目标文件。目标文件是包含了可执行代码的文件, 但是,它缺少必要的信息,不能独立执行,只能作为模块使用。
- 第二个阶段是链接,是将前面生成的目标文件链接起来,得到最终的可执行文 件。在这个阶段,将要处理那些未决的符号,找到它们的定义。除此之外,还 要链接一些与操作系统有关的代码,这些代码对于能否让生成的可执行程序在 操作系统上运行至关重要。
为此,我们可以先独立地生成以上两个源文件的目标文件,这需要在翻译时使用 -c选项:
gcc -c main.c #生成一个目标文件main.o gcc -c print.c -masm=intel #需要指定汇编格式,生成print.o
最后,我们将以上两个目标文件链接在一起:
#将目标文件链接在一起 gcc main.o print.o #生成a.out
实际上,以上独立的翻译过程可以合并为一个过程,只需要指定所有源文件的名字,以及必要的选项即可,就象这样:
#合并翻译过程 gcc main.c print.c -masm=intel
库
源文件可以分发给别人,这样他们就能使用现成的代码来提高编程速度和效率, 但是,出于一些特殊的原因,比如一些函数包含了特殊的算法和秘密,你不想让 使用它的人知道它是如何编写的,则可以将它编译成库。
库是一个特殊的文件,包含了编译过的可执行代码。
我们原来是通过源文件print.c来共享函数myprint,现在,我们要创建一个库并共享库的代码。为此,我们需要先将源文件print.c翻译成目标文件
[root@proxy tmp]# gcc -c print.c -masm=intel #翻译成目标文件print.o [root@proxy tmp]# ls main.c print.c print.o
然后创建一个库并加入翻译之后的目标文件:
[root@proxy tmp]# ar r libprint.a print.o ar: creating libprint.a [root@proxy tmp]# ls libprint.a main.c print.c print.o
原则上,库文件的名字应该以lib打头。
ar命令创建库
ar [emulation options] [-]{dmpqrstx}[abcDfilMNoPsSTuvV] [--plugin <name>] [member-name] [count] archive-file file...
ar -M [<mri-script]
#选项
r #如果在库中有同名函数,则覆盖它
现在,你可以把这个库(libprint.a)分发给同事或者朋友们,让他们使用。
使用
gcc main.c libprint.a #或者 gcc main.c -lprint -L. #-l表示添加库文件,可以省略lib前缀和.a后缀. 但是这个选项并不在当前目录下搜索库文件。 #问题在于我们要使用的库是在当前目录下,为此需要使用大写的-L选项把当前目录添加到搜索过程中。 #句点表示当前目录。
范例:
[root@proxy tmp]# cat main.c
void myprint (char *, unsigned);
int main (void)
{
char ws [] = {'\150', '\x65', 'l', 'l', 'o', '.', '\n'};
myprint (ws, 7);
return 0;
}
#使用库,方式1
[root@proxy tmp]# gcc main.c libprint.a
[root@proxy tmp]# ./a.out
hello.
#使用库,方式2
[root@proxy tmp]# gcc main.c -lprint -L.
[root@proxy tmp]# ls
a.out libprint.a main.c print.c print.o
[root@proxy tmp]# ./a.out
hello.
头文件和预处理
使用库可以为程序开发者带来方便,问题在于,库不象源文件,库的内容不是人工可读的.
会显示一堆乱码 ,因为它的内容不是文本,而是可执行代码。
[root@proxy tmp]# ls a.out libprint.a main.c print.c print.o [root@proxy tmp]# cat libprint.a !<arch> / 1730769368 0 0 0 16 ` Tmyprintprint.o/ 1730769071 0 0 100644 1264 ` ELF>0@@ UH䈉}EňȀHȇ]CC: (GNU) 4.8.5 20150623 (Red Hat 4.8.5-44)zRx b C 'print.cmyprint .symtab.str
使用库中的函数myprint,要在main.c文件的开头做了一个不带函数体的声明。
即使知道库里有一个函数,他也可能无法确切地知道函数的名字、参数的数量和类型。
对于一个来自于商业途径的库来说,里面的函数不止一个,可能有几十个几百个之多。在使用之前,重复声明这些函数实在是太困难,太麻烦了。
为了解决这个问题,需要在发行库文件的时候,同时发行一个文本文件。习惯上,这个文本文件以.h为扩展名,叫做头文件。可以在头文件里声明库中的函数。
因为我们已经有了一个库文件libprint.a,所以,还应当有一个头文件,比如print.h
[root@proxy tmp]# cat print.h void myprint (char *, unsigned);
使用时,不再需要自己手工声明库里的函数,只需要把你给他的头文件包含到自己的源文件里即可。因此,他需要这样修改他的源文件main.c
[root@proxy tmp]# cat main.c # include "print.h" int main (void) { char ws [] = {'\150', '\x65', 'l', 'l', 'o', '.', '\n'}; myprint (ws, 7); return 0; }
这是一条预处理指令( # include "print.h" )。所谓预处理,顾名思义,是在程序正式翻译前,预先进行某些处理。那么,做什么样的预先处理工作呢?这需要不同的指令加以指示,称为预处理指令。
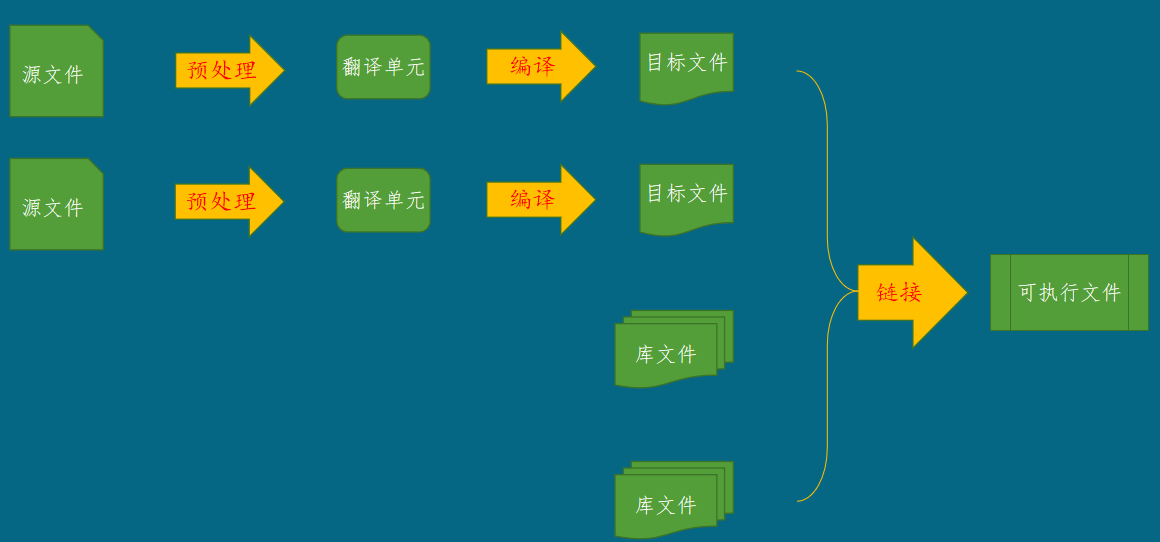
程序的翻译过程
- 一个程序可以由很多源文件组成。
- 预处理阶段:翻译时,每个源文件都各自进行预处理。预处理后的结果是得到翻译单元,翻译单元不再包含预处理指令
- 编译阶段:各个翻译单元都独立地进行编译,编译之后将得到各自的目标文件。
- 链接阶段:所有目标文件和所有库文件集中到一起,由链接器连接为一个可执行文件。
预处理阶段
- 所有预处理指令都是以 # 井号打头;
- include是源文件包含指令,后跟一个文件名
回到程序中,当这条预处理指令( # include "print.h" )执行后,它会被删除。并且,头文件print.h的内容会被加进来,从这条指令所在的位置开始插入。
预处理之后的结果是得到翻译单元。翻译单元的内容不再包含任何预处理指令。
gcc
#预处理选项 -E 在预处理之后停止翻译过程, 即仅预处理; -P用于禁止输出一些多余的信息。 -o 用于指定翻译单元的文件名
范例:
[root@proxy tmp]# cat main.c # include "print.h" int main (void) { char ws [] = {'\150', '\x65', 'l', 'l', 'o', '.', '\n'}; myprint (ws, 7); return 0; } #预处理,生成翻译单元。预处理指令会被删除,在指令所在位置插入头文件内容 [root@proxy tmp]# gcc -E -P main.c -o main.p #查看翻译单元内容 [root@proxy tmp]# cat main.p void myprint (char *, unsigned); int main (void) { char ws [] = {'\150', '\x65', 'l', 'l', 'o', '.', '\n'}; myprint (ws, 7); return 0; }
现在,我们正式翻译源文件main.c并链接生成最终的可执行文件:
#翻译并链接生成可执行文件 [root@proxy tmp]# gcc main.c -lprint -L. [root@proxy tmp]# ls a.out libprint.a main.c main.p print.c print.h print.o [root@proxy tmp]# ./a.out hello.
库的分类
库是C语言功能的延伸。
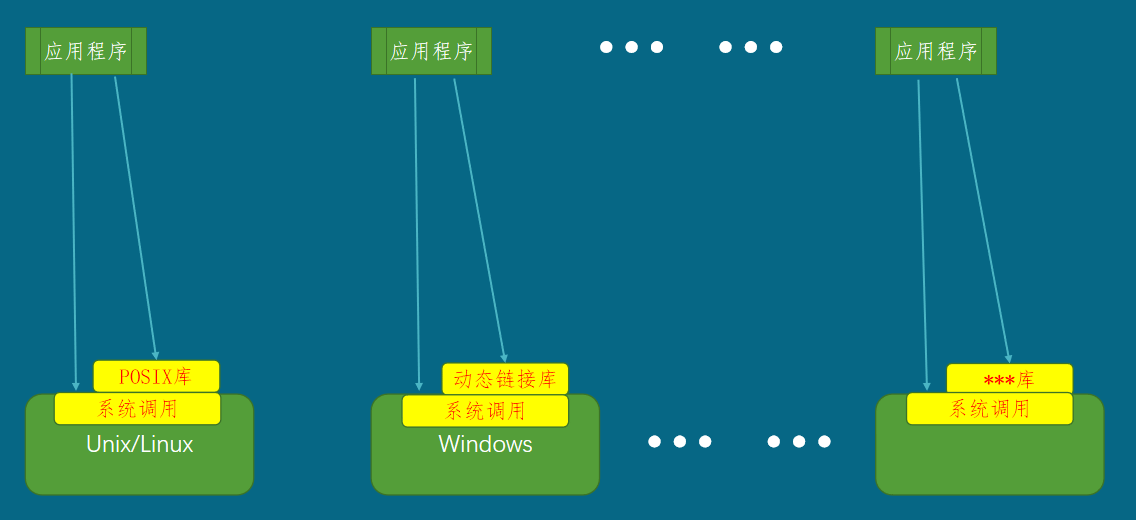
对于依赖操作系统才能运行的程序来说,为了获得操作系统提供的服务需要使用系统调用。不同的操作系统都提供各自不同的系统调用。
为方便己见,系统调用都会被封装为库,这样每个操作系统都会有各种不同的库及各自不同的库。应用程序通过库来使用操作系统提供的服务,就像调用普通函数一样方便。
- 在Unix/Gun Linux系统上,主流的库是Unix函数库,后来标准化为POSIX库。
- 在Windows上,主流的库是动态链接库
- 其他系统,有各自不同的库
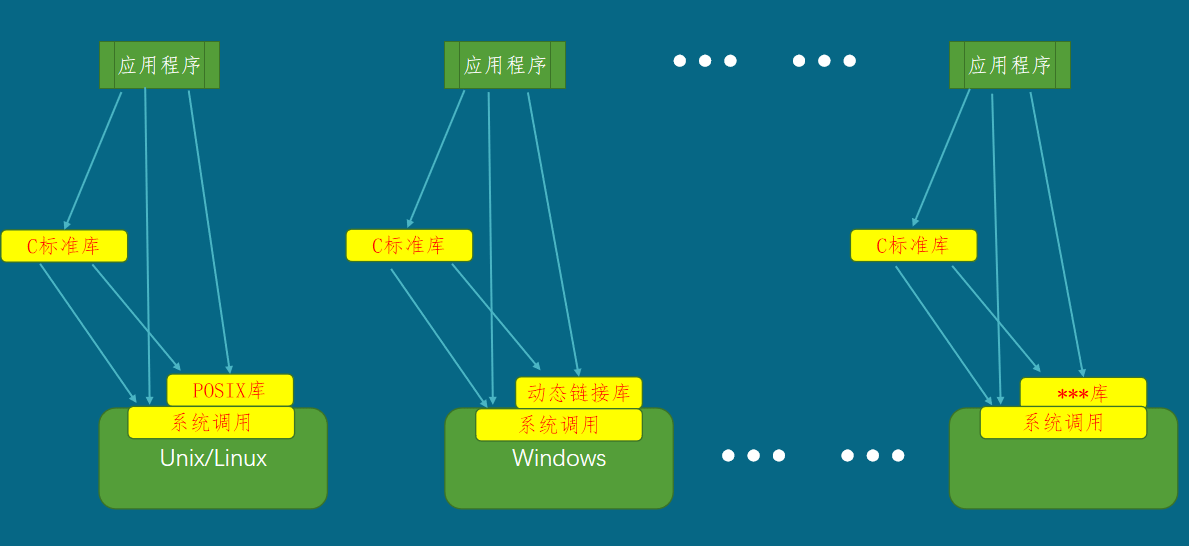
如果你想编写一个在不同操作系统上工作的程序,这通常是一个不可能完成的任 务,因为不同操作系统在各方面都不一样。外观不同、体系结构不同、系统调用 不同、库不同、对可执行文件的格式要求不同。所以唯一的办法是为不同的操作 系统编写不同的程序,尽量它们是完成相同的功能。
为了能够实现一次编写处处运行,C语言提供了自己的库称为C标准库。
使用C标准库函数编写的程序不用修改就可在不同操作系统上翻译并执行。因为, 不管理程序运行在哪个操作系统平台,程序员都可以使用相同的库函数,但这些 库函数在这些不同操作系统平台上有不同的实现。
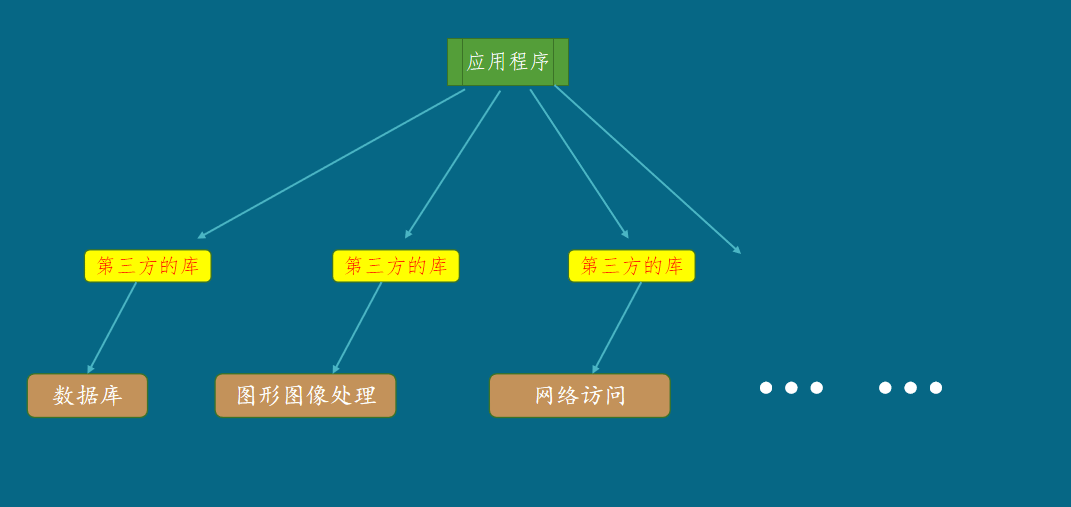
除此之外,应用程序还可以使用第三方开发的库,这些库用来访问数据库、处理图形、网络访问等。
UNIX和LINUX上输出文本的例子
POSIX标准库
对函数库的开发做标准化的规定,形成一个标准叫POSIX(可移植性操作系统接口)。POSIX对Unix各个分支加以规范和认证,其中就包含C语言的函数库。 统一后的UNIX编程接口按照功能进行归类并以头文件的形式发布。
Linux和Unix有近亲关系,可以被认为是Unix的一个分支,只不过出现的较晚。Linux也遵循POSIX规范。
POSIX标准的库函数按照他们的功能归类被划分为很多头文件。
<assert.h> #验证程序断言 <cpio.h> #cpio归档值 <dirent.h> #目录项 <errno.h> #出错码 <fcntl.h> #文件控制 <float.h> #浮点常数 <ftw.h> #文件树漫游 <grp.h> #组文件 <langinfo.h> #语言信息常数 <limits.h> #实施常数 <locale.h> #本地类别 <math.h> #数学常数 <nl_types.h> #消息类别 <pwd.h> #口令文件 <regex.h> #正则表达式 <search.h> #搜索表 <setjmp.h> #非局部goto <signal.h> #信号 <stdarg.h> #可变参数表 <stddef.h> #标准定义 <stdio.h> #标准I/O库 <stdlib.h> #公用函数 <string.h> #字符串操作 <tar.h> #tar归档值 <termios.h> #终端I/O <time.h> #时间和日期 <ulimit.h> #用户限制 <unistd.h> #符号常数 <utime.h> #文件时间 <sys/ipc.h> #IPC <sys/msg.h> #消息队列 <sys/sem.h> #信号量 <sys/shm.h> #共享存储 <sys/stat.h> #文件状态 <sys/times.h> #进程时间 <sys/types.h> #原系统数据类型 <sys/utsname.h> #系统名 <sys/wait.h> #进程控制
范例:
[root@proxy tmp]# cat main.c # include <unistd.h> int main (void) { char a [] = {'h', 'e', 'l', 'l', 'o', ' ', 'w', 'o', 'r', 'l', 'd', '.', '\n'}; write (1, a, 13); return 0; }
在这个程序中,我们调用POSIX库函数write向标准输出设备写入一串文本“hello world.”。所谓的标准输出设备是一个历史术语,现在通常是指显示器。文本的内容是通过一个数组a来提供的,数组a在声明时初始化为字符常量,这些字符常量组成了要打印的文本内容。
库函数write需要三个参数,第一个参数是整数类型,如果你传进去的是整数1,则表示向标准输出设备写入。
第二个参数 (a) 是指针,指向要写入的内容。在这里,数组a自动转换为指向char的指针,并指向它的第一个元素。由于这个数组的内容是一串文本,所以,函数write可以顺藤摸瓜,通过移动这个指针来找到后面的字符,并输出它们。
最后一个参数 (13) 是整数类型,要求提供写入的长度,以字节计。对于数组a来说,它的元素类型是char,而char类型的变量在任何计算机上都恰好占用一个字节。所以,我们只需要传入数组a的元素个数即可。数组a的元素数量是13,我们就传入13。
我们知道,函数在调用前必须先声明。函数write是在POSIX的头文件unistd.h里声明的。为了引入函数write的声明,我们在源文件的开头用include预处理指令包含了这个头文件。
你可能已经注意到,在先前的预处理指令中,头文件是用双引号围起来的,而这里用的是尖括号,这有什么区别吗?
当然是有的。我们知道,库分为好多种,有我们自己生成的库,也有别的公司或者个人生成的库,还有行业组织为各种操作系统定义的库。每个C实现在安装的时候,都会提供那些由行业组织定义的标准库,并存放在特定的目录下。
- 如果include预处理指令引用的头文件是用尖括号围起来的,在程序翻译时,预处理器会到那个特定的目录下去寻找它们;
- 如果是用双引号围起来的,预处理器先在当前目录下寻找。如果找不到,就把它当成由尖括号围起来的文件名处理。
#翻译并执行程序。 POSIX标准库在程序翻译时自动添加不需要手工给出库文件 [root@proxy tmp]# gcc main.c [root@proxy tmp]# ./a.out hello world.
现在,我们翻译并执行这个程序。。。你可能觉得奇怪,我们使用了POSIX的库函数write,但是为什么在翻译时不用给出它所在的库文件呢?事实上,POSIX标准库是在程序翻译时自动添加的,不需要我们手工给出。
宏定义的宏替换
一个好记的名字很重要,最好能望文生义。好在C语言支持我们这样做,C语言提供了一个预处理指令,称为宏定义,可以把一些文本定义成好记的名字。
在这个程序中,我们可以用这条预处理指令把数字1定义为标识符STD_OUTPUT
宏定义格式
# define 宏名称 替换列表
范例
[root@proxy tmp]# cat main.c # include <unistd.h> # define STD_OUTPUT 1 # define MAIN int main (void) MAIN { char a [] = {'h', 'e', 'l', 'l', 'o', ' ', 'w', 'o', 'r', 'l', 'd', '.', '\n'}; write (STD_OUTPUT, a, 13); return 0; } #仅预处理,生成一个翻译单元 [root@proxy tmp]# gcc -E -P main.c -o main.p [root@proxy tmp]# ls main.c main.p #查看翻译单元 [root@proxy tmp]# cat main.p ... unistd.h内容 int main (void) { char a [] = {'h', 'e', 'l', 'l', 'o', ' ', 'w', 'o', 'r', 'l', 'd', '.', '\n'}; write (1, a, 13); return 0; } #正式地翻译并执行 [root@proxy tmp]# gcc main.c [root@proxy tmp]# ./a.out hello world.
回到程序中,实际上,我们定义STD_OUTPUT是多余的,因为POSIX标准库已经在头文件unistd.h里定义了它,宏的名字叫STDOUT_FILENO。因为这个程序已经包含了这个头文件,所以这个宏也可以直接在程序中使用
[root@proxy tmp]# cat main.c # include <unistd.h> # define MAIN int main (void) MAIN { char a [] = {'h', 'e', 'l', 'l', 'o', ' ', 'w', 'o', 'r', 'l', 'd', '.', '\n'}; write (STDOUT_FILENO, a, 13); return 0; } [root@proxy tmp]# gcc main.c [root@proxy tmp]# ./a.out hello world.
WINDOWS上播放音乐的例子
动态链接库和音乐播放
Windows动态链接库是调用windows系统服务的接口文件,由程序运行时动态加载并使用其中的功能。最开始windows是用汇编语言和C语言开发的,所以windows动态链接库中的函数用C语言调用应该是最方便的。
windows动态链接库是对外提供服务的接口文件,这不是一个文件而是很多文件,这此文件各自提供不同的系统服务。这些文件大多以 .dll 为扩展名,是windows系统的一部分,在安装windows时它们也会被安装在特定的目录下。
有个核心的动态链接库
C:\Windows\System32 user32.dll #提供windows图形界面的功能,如,创建和管理窗口 kernel32.dll #提供windows系统核心的管理功能,如,内存管理、输入输出 gdi32.dll #提供图形和图像的功能。如,绘制图形、输出文件
在Windows里,可以用以下两个函数输出文本:
- WriteConsole函数:位于Kernel32.dll中,并在头文件Wincon.h中声明
- WriteFile函数:位于Kernel32.dll中,并在Fileapi.h中声明
范例:播放音乐main.c
# include <windows.h> int main (void) { char fname [] = {'z', 'm', 't', 'x', '.', 'w', 'a', 'v', '\0'}; PlaySound (fname, 0, SND_FILENAME | SND_SYNC); return 0; }
播放音乐,可以使用库函数PlaySound。这个函数只能播放wav格式的音频,这是微软公司自己制定的音频格式。为了使用这个函数,我们需要通过包含头文件windows.h来引入它的声明。
在这个程序中,我们是要播放一个音乐文件,文件的名字叫zmtx.wav。提交准备好这个文件
D:\tmp\d>gcc main.c D:/msys64/mingw64/bin/../lib/gcc/x86_64-w64-mingw32/14.2.0/../../../../x86_64-w64-mingw32/bin/ld.exe: C:\Users\jasper\AppData\Local\Temp\ccBsheh7.o:main.c:(.text+0x34): undefined reference to `__imp_PlaySoundA' collect2.exe: error: ld returned 1 exit status #报错,因为没有在翻译时提供动态链接库文件。对于windows程序来说,因为库太多了,有些不太常用的库可能不会自动添加,需要我们手工添加。 D:\tmp\d>gcc main.c c:\windows\system32\winmm.dll #执行程序 D:\tmp\d>a
字面串和字符串
# include <windows.h> int main (void) { char fname [] = {'z', 'm', 't', 'x', '.', 'w', 'a', 'v', '\0'}; PlaySound (fname, 0, SND_FILENAME | SND_SYNC); return 0; }
函数playsound用于播放声音。它需要好几个参数,第一个参数是指向字符的指针,用来指定声音的名字。
在这里,数组fname自动转换为指向char的指针,并指向它的第一个元素。由于这个数组的内容是一串文本,所以,函数playsound可以顺藤摸瓜,通过移动这个指针来找到后面的字符,把这些字符的序列当成是声音名字。
问题在于,函数playsound并不要求你给出数组的长度,所以问题来了,它怎么知道文本在哪里结束呢?
来看数组fname的声明,数组fname的初始化器和以前不一样。初始化器的最后一个字符常量是用单引号围着的反斜杠和0。这是一个特殊的字符常量,代表一个编码值为0的字符,称为空字符。所以,这个字符常量也叫做空字符常量。
对于函数playsound来说,它通过移动传递给它的指针来搜集字符,当遇到一个空字符时,停止搜集,因为空字符是一个结束标志。
在使用C语言编程时,我们会大量地用到这种以空字符结尾的文本串。为方便起见,我们称之为字符串。字符串是一个字符的序列,以遇到的第一个空字符结束。末尾的空字符也是字符串的一部分,而且是它的最后一个字符。
字符串用得太频繁了。C语言是实用主义的语言,为了方便,它引入了一个新的东西来生成字符串,这就是字面串。
字面串是一对用双引号围起来的字符 "zmtx.wav"。
- 在程序翻译阶段,字面串用于创建一个隐藏的、元素类型为char的数组,数组元素的内容来自于双引号里的字符,并且会自动在末尾添加一个空字符。因此,由字面串"zmtx.wav"所创建的数组里有9个字符,而不是8个。
- 因为以上原因,你可以把字面串看成是一个不需要声明就能直接使用的字符数组。事实上,字面串是一个数组类型的表达式,代表着它背后那个隐藏的数组。
字符串是字符数组的内容,字符数组是字符串的载体和容器。一个字符串可以是字符数组的全部或者部分内容。
例如,字面串"hello\0world\0"所创建和代表的隐藏数组里有3个字符串。
里面有2个空字符常量 (
\0) , 字符常量也可以用在字面串里。在这个字符串里,\0用于生成编码值为0的空字符。
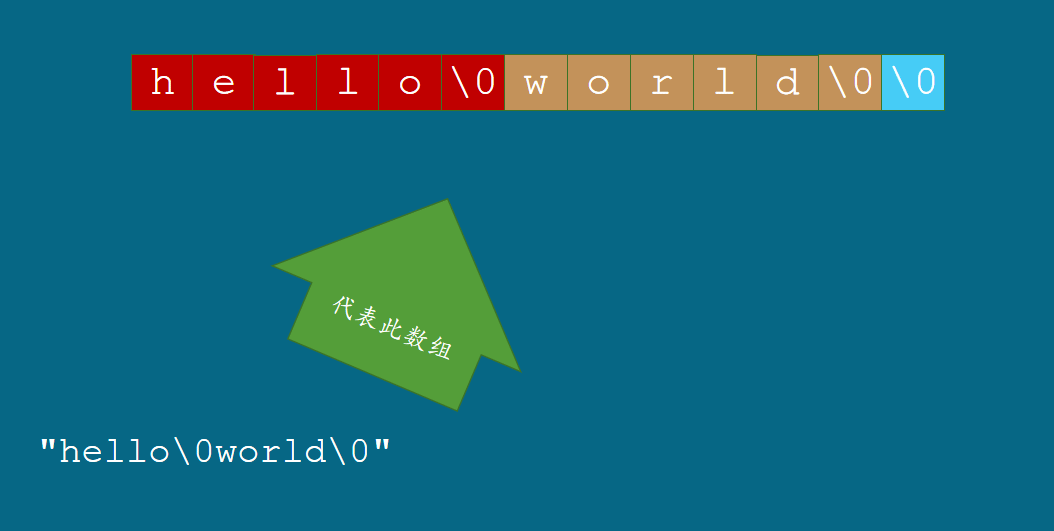
字面串"hello\0world\0"代表一个由它自己创建的隐藏数组。这个数组里面,字符序列hello后面有一个空字符,所以这形成了一个字符串;同样字符序列world后面有一个空字符,这形成了一个字符串。最后用一个字面串所创建 的数组里会自动添加一个空字符,所以这个空字符也形成了一个字符串,这个字符串里仅有一个空字符,即空串。
字面串是因为从字面意义上等同于字符串。
回到程序中,既然引入了字面串,那我们就不需要声明一个数组来存放文件名,而是直接使用字面串,就象这样:
# include <windows.h> int main (void) { PlaySound ("zmtx.wav", 0, SND_FILENAME | SND_SYNC); return 0; }
在这里,这个字面串将创建一个不可见的隐藏数组,数组的内容是一个字符串,而这个字面串代表这个隐藏的数组。
由这个字面串代表一个字符类型的数组,所以会执行数组到指针的转换,转换为指针,指向它所代表的那个数组的第一个元素。随后,这个指针被传递给playsound函数。
逐位或运算符
继续来看这个程序,函数playsound的第三个参数 (SND_FILENAME | SND_SYNC) 有点古怪,但实际上,这是一个表达式,用来计算一个整数。这是因为,函数PlaySound的第三个参数要求是一个整数。
函数playsound要求我们用第三个参数来指定如何播放声音,而且这个参数必须是一个整数。我们先不管这个表达式是如何得到一个整数的,现在的问题是,整数如何能够表达意图呢?这好奇怪。
声音播放标志
因为数字在计算机内部是2进制形式的,函数PlaySound可以通过观察第三个参数的特定比特来分析你想如何播放声音。
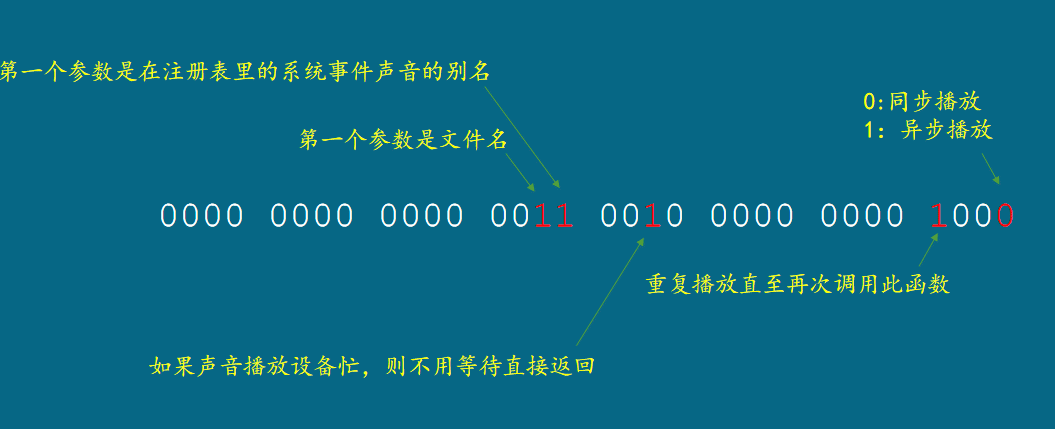
在程序中,我们是要播放一个音乐文件而且采用同步播放,所以只需要将右边第一个比特设置为0表示同步播放,右边第18个比特设置为1表示第一个参数是文件,其他比特一律为0。这样就组成了一个数字等于10进制131072
这样的搞法需要程序员确定各个比特是0还是1,然后组成一个数字。这样做肯定会把程序员逼疯。需要包装一下。
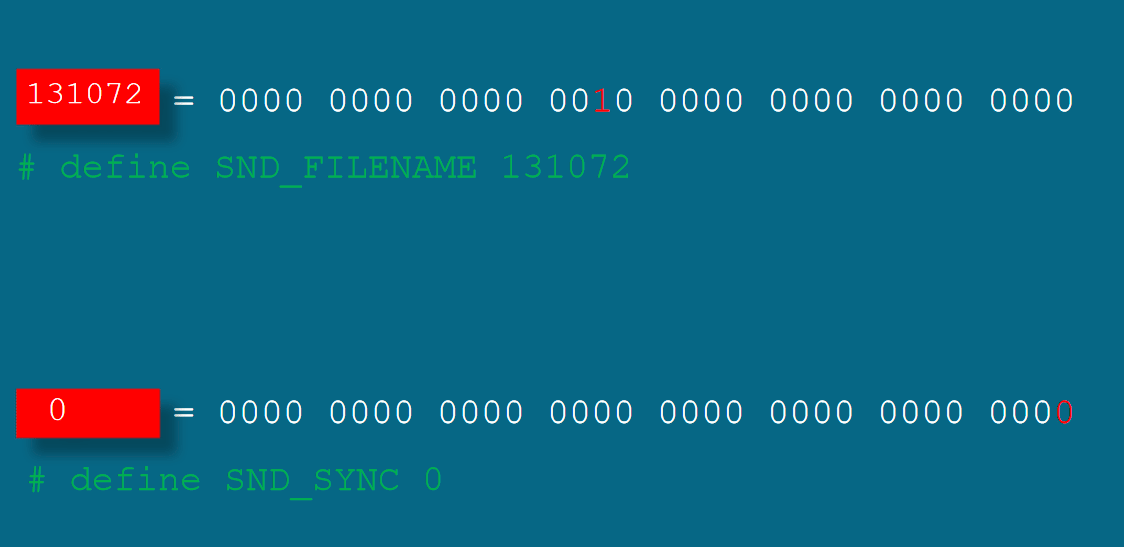
改进的第一步是将各个标志位分享出来变成独立的数字。如,131072表示播放的是声音文件,这是因为这个数字的二进制形式中只有右边第18位为1其余为0。如,0表示同步播放。 第二步将数字和有意义的名字联合起来,这就需要使用宏定义。
回到程序中,在这里,SND_FILENAME和SND_SYNC是两个宏,不需要我们自己定义,它们已经定义好了,并通过头文件windows.h引入到当前这个程序里。在程序翻译的预处理阶段,它们会被替换为数字。因此,这一部分实际上等价于
131072 | 0
这里的竖线是C语言里的运算符,叫做逐位或运算符。它需要左右两个操作数,并对它们做或运算。
逐位或运算
逐位或运算是在2个操作数的2进制层面上进行操作。
- 如果2上操作数上相对应的比特是0,则结果对应的比特是0;
- 如果2上操作数上相对应的比特至少有一个是1或者都是1,则结果对应的比特是1;
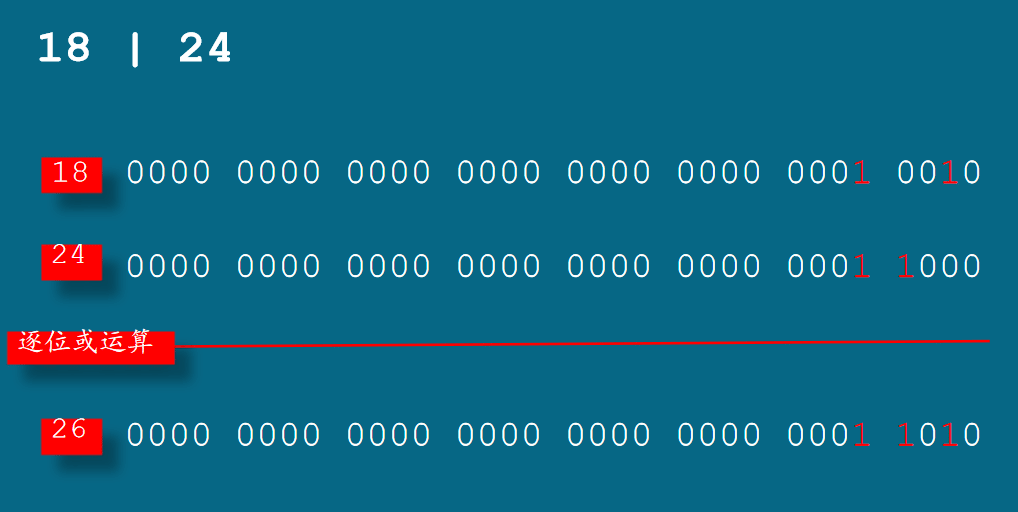
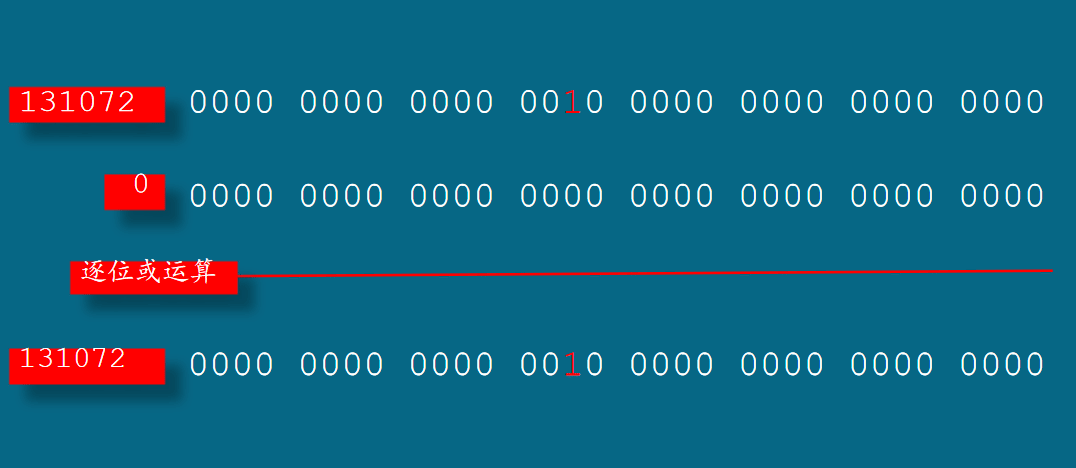
# include <windows.h> int main (void) { PlaySound ("zmtx.wav", 0, 131072 | 0); return 0; }
再次回到程序中,我们现在知道,这是一个表达式,竖线是逐位或运算符,它对操作数131072和0做逐位或运算,并得到一个整数做为结果,然后把它传递给playsound。
现在,我们把这个表达式恢复到原来的样子。这次再来审视它,你会发现,使用宏和逐位或运算符,不但很和谐很优美,而且确实也方便了程序的编写工作。
最后来看函数playsound的第二个参数,如果我们在第三个参数中指定SND_FILENAME,则这个参数应当是0。
使用C标准库输出文本的例子
C标准库和文本输出
C标准库和C实现一起发行,是最具有可移植性的库。一共有30多个头文件。
范例:输入文
[root@proxy tmp]# cat main.c # include <stdio.h> int main (void) { putchar (48); putchar (':'); putchar ('\n'); printf ("hellow world.\n"); return 0; } [root@proxy tmp]# gcc main.c [root@proxy tmp]# ./a.out 0: hellow world.
函数putchar的功能是向标准输出设备写入一个字符,它需要一个整数类型的参数,并假定这个整数代表某个字符的编码值。
- 在ASCII字符集里,编码值为48的字符是数字字符0,所以这条语句实际上是打印数字字符0。
- 第二条语句中,我们打印的是字符常量。字符常量的类型是整数,是代表编码值的整数。
- 第三条语句中,我们是打印一个换行字符
调用C标准库函数printf打印一串文本。函数printf的最简单的用法是打印一串文本。如果仅仅是打印一串文本,则可以传递一下指向char的指针。但是,函数printf要求指针所指向的文本是以空字符结束,否则它不知道文本在哪里终止。
为此,我们传递了字面串。用这个字面串所生成的隐藏数组里,最后一个字符是空字符。字面串的类型是数组,它自动转换为指向数组首元素的指针,并传递给函数printf。
字面串的特殊之处
字面串是数组类型的表达式,可以当数组来用。在下面的程序中,我们先声明了一个数组a并初始化为字符常量,初始化之后,数组a的内容是一个字符串,因为它的最后一个元素是空字符。
[root@proxy tmp]# cat main.c # include <stdio.h> int main (void) { char a [] = {'s', 'm', 'i', 't', 'h', '\n', '\0'}; putchar (a [2]); putchar ('\n'); putchar ("smith\n" [3]); putchar ('\n'); printf (a); printf ("smith\n"); return 0; }
我们可以用下标运算符访问数组的元素。下标运算符要求一个指针类型的操作数和一个整数类型的操作数。在(这一条 a [2] )语句里,数组a自动转换为指针,指向它的首元素。然后下标运算符得到一个左值,代表数组下标为2的元素,并执行左值转换,转换为这个元素的值,也就是字符i的代码。
同理,在(这一条 "smith\n" [3] )语句里,字面串等价于数组,自动转换为指向数组首元素的指针。然后,下标运算符得到一个左值,代表数组下标为3的元素,并执行左值转换,转换为这个元素的值,也就是字符t的代码。
再比如,函数printf要求它的第一个参数是指向char的指针,这个指针应当指向字符串的第一个字符。为方便起见,我们简单地称之为指向字符串的指针。
在(这一条 printf (a); )语句里,数组a自动转换为指向其首元素的指针。数组a的内容是一个字符串,所以这将打印字符串。
在(这一条 printf ("smith\n"); )语句里,字面串将创建一个包含了字符串的隐藏数组,而且字面串也是数组类型的表达式,将自动转换为指向隐藏的数组的首元素的指针。所以这一句也将打印字符串。
[root@proxy tmp]# gcc main.c [root@proxy tmp]# ./a.out i t smith smith
不过,相比之下,字面串还有一个特殊之处。即,它可以用于作为初始化器,初始化一个字符数组。
范例:初始化字符数组
[root@proxy tmp]# cat main.c # include <stdio.h> int main (void) { char a [] = {'s', 'm', 'i', 't', 'h', '\n', '\0'}; /* char b [] = a; */ char c [] = "jerry\n"; printf (a); printf (c); return 0; }
来看这个程序,我们声明了数组a并初始化为字符常量。接着,我们声明了数组b,并企图用数组a来初始化。但是这错误的,非法的。因为我们知道,数组a将自动转换为指针,你不能用一个指针来初始化数组。
再来看数组c的声明,在数组c的声明中也有初始化器,这个初始化器也是一个数组,但不是普通的数组,是一个字面串。这是允许的。因为我们在介绍数组-指针转换的时候说过。
除非是做为一元 & 或者 sizeof 运算符的操作数,或者是一个用作初始化器 的字面串,否则,一个元素类型为 T 的数组会被自动转换为指向T的指针,并 指向该数组的首元素。
所以,在这里,字面串将保持数组的本色不变,并且用它的内容初始化数组c,这是一个复制过程。数组c在声明时没有指定大小,它的大小由初始化器决定。初始化完成后,数组c的内容完全来自于字面串,包括末尾的空字符。也就是说,数组c的大小是7,各个元素的内容分别是j, e, r, r, y, 换行符和空字符。
接着往下看,我们用函数printf打印数组a里的字符串和数组c里的字符串。我们来运行这个程序,并观察打印的内容。
[root@proxy tmp]# gcc main.c [root@proxy tmp]# ./a.out smith jerry
范例:
[root@proxy tmp]# cat main.c # include <stdio.h> int main (void) { char a [] = "jerry"; char b [3] = "jerry"; char c [10] = "jerry"; return 0; }
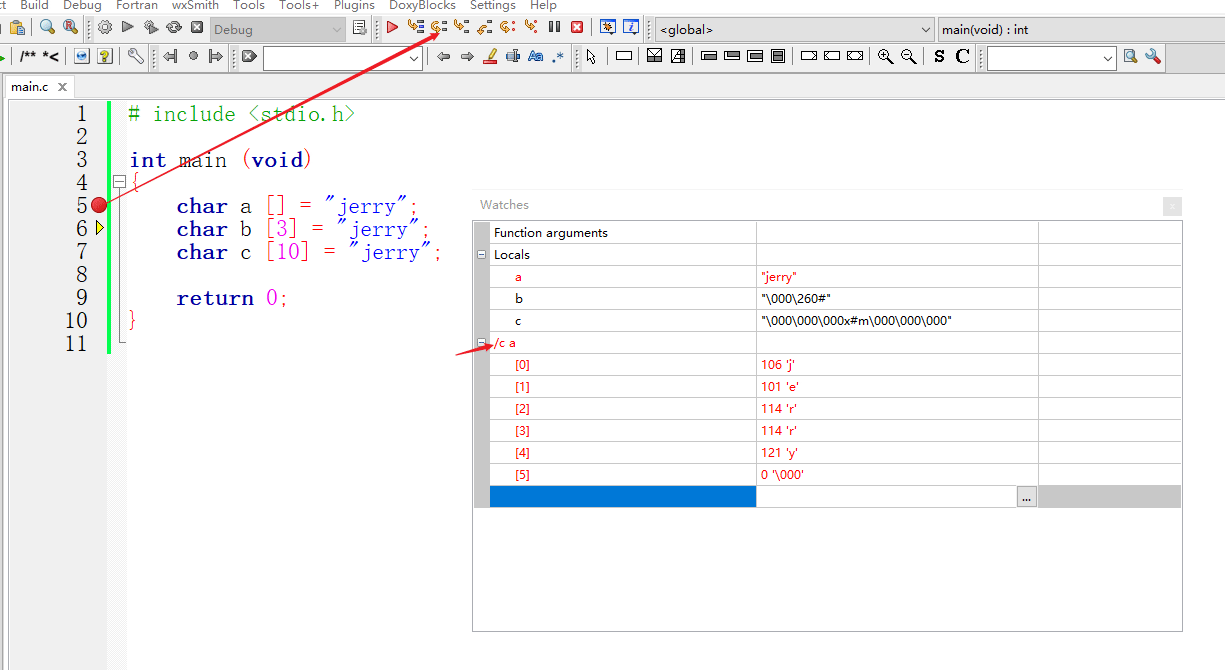
再来看这个程序,在用一个字面串初始化数组时,如果数组没有指定大小,则创建一个恰好能够容纳字面串内容的数组。因此,数组a具有6个元素,包括末尾的空字符。我们最好是边调试边说明。在第一个声明这里设置断点,启动调试器。
先单击下一行来处理第一个声明。来看,watches窗口对char类型的数组作了特殊处理,看不到各个元素的内容,我们用/c选项来显示数组的每个元素。。。
来看,数组a共有6个元素,分别是…,最后一个元素是空字符。
单击下一行。
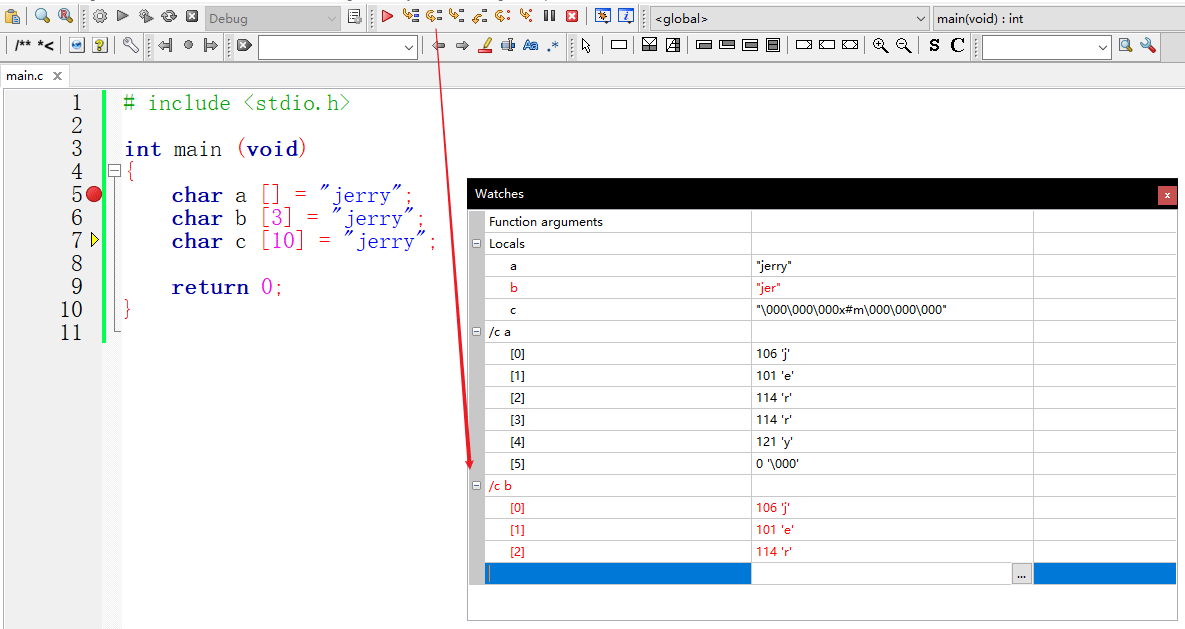
再来看,如果数组的大小不足以容纳字面串的内容,包括末尾的空字符,则只有字面串前面的内容被复制。因此,数组b的内容是字符j,e和r。
单击下一行。
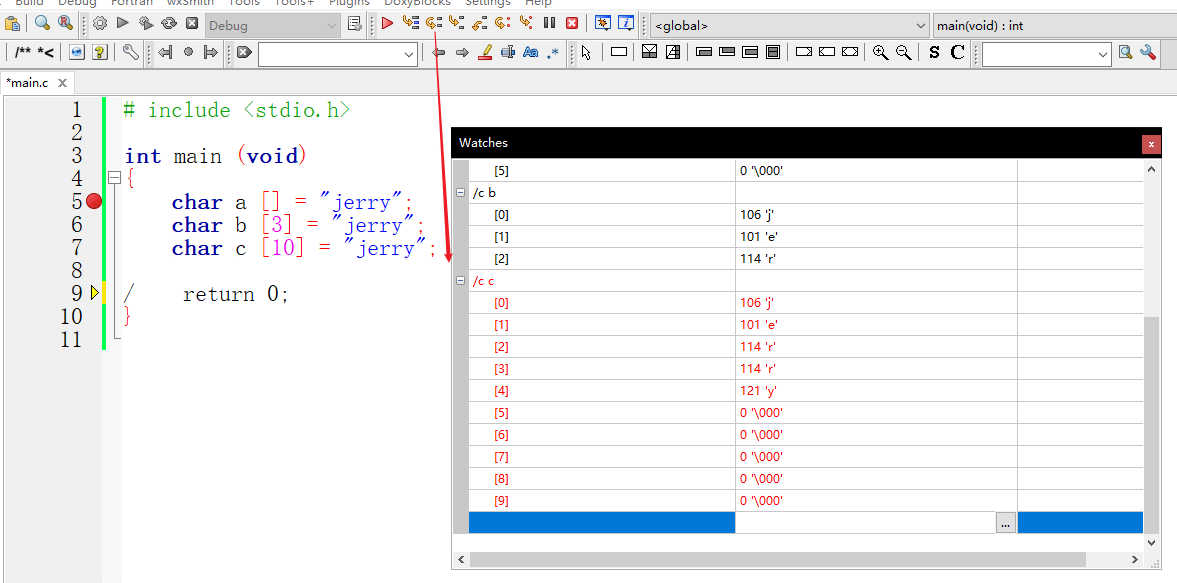
最后来看数组c,它有大小为10,比字面串的内容还多。在这种情况下,除了复制字面串的内容外,多余的元素都被初始化为0,你可以认为它们都是空字符。