C++: 基础算法
- TAGS: C++
基础概念
时间复杂度
前言
很多人觉得算法难,是因为被困在了时间和空间这两个维度上。如果不考虑时间和空间的因素,其实我们可以把所有问题都通过「穷举法」来解决,也就是你告诉计算机你要做什么,然后通过它强大的算力帮你计算。
那么,说到了时间,今天我就和大家来聊一下「算法时间复杂度」。
穷举法
单层循环
所谓穷举法,就是我们通常所说的枚举,就是把所有情况都遍历了(跑到)的意思。举个最简单的例子:
- 【例题1】给定n(n<=1000)个元素ai,求其中奇数有多少个。
判断一个数是偶数还是奇数,只需要求它除上2的余数是0还是是1,那么我们把所有数都判断一遍,并且对符合条件的情况进行计数,最后返回这个计数器就是答案,这里需要遍历所有的数,这就是穷举。如图所示:

C/C++代码实现如下:
int countOdd(int n, int a[]) { int cnt = 0; for (int i = 0; i < n; ++i) { if (a[i] & 1) { ++cnt; } } return cnt; }
Python代码实现如下:
def countOdd(n, a): cnt = 0 for i in range(n): if a[i] & 1: cnt += 1 return cnt
其中 a & 1等价于 a % 2,代表a模2的余数。
双层循环
经过上面的例子,相信你对穷举法已经有一定的理解,那么我我们来看看稍微复杂一点的情况。
- 【例题2】给定n(n<=1000)个元素ai,求有多少个二元组(i,j),满足ai+aj是奇数(i<j)。
- 我们还是秉承穷举法的思想,这里需要两个变量i和j,所以可以收举ai和aj,再对ai+aj进行奇偶性断,所以很快设计出一个利用穷举的算法。如图二-2-1所示:

C/C++代码实现如下:
int countOddPair(int n, int a[]) { int cnt = 0; for (int i = 0; i < n; ++i) { for (int j = i + 1; j < n; ++j) { if (a[i] + a[j] & 1) ++cnt; } } return cnt; }
Python代码实现如下:
def countOddPair(n, a): cnt = 0 for i in range(n): for j in range(i+1, n): if a[i] + a[j] & 1: cnt += 1 return cnt
三层循环
经过这两个例子,是不是对穷举已经有点感觉了?那么,我们继读来看下一个例子。
【例题3】给定n(n<=1000)个元素ai,求有多少个三元组(i,j,k),满制足ai+aj+ak 是奇数(i<j<k)
相信聪明的你也已经猜到了,直接给出代码:
c/c++代码实现如下:
int countOddTriple(int n, int a[]) { int cnt = 0; for (int i = 0; i < n; ++i) { for (int j = i + 1; j < n; ++j) { for (int k = j + 1; k < n; ++k) { if (a[i] + a[j] + a[k] & 1) ++cnt; } } } return cnt; }
Python代码实现如下:
def countOddTriple(n, a): cnt = 0 for i in range(n): for j in range(i+1, n): for k in range(j+1, n): if a[i] + a[j] + a[k] & 1: cnt += 1 return cnt
这时间,相信你已经意识到一个问题:时间
是的,随着循环嵌套的增多,时间消耗会越来越多,并且是是三个循环是乘法的关系,也就是遍历次数随着n的增加,呈立方式的增长。
递归枚举
【例题4】给定n(n<=1000)个元素ai和一个整数k(k<=n),求有多少个有序k元组,满足它们的和是偶数。
- 一层循环,两层循环,三层循环,k层循环?
- 我们需要根据k的不同,决定写几层循环,k的最大值为1000,也就意味着我们要写1000的if else语句。
- 显然,这样是无法接受,比较暴力的做法是采用到递归;
c/c++代码实现如下:
- 代码可以先不看,当学到树的数据结构后比较好理解
int dfs(int n, int a[], int start, int k, int sum) { if (k = 0) return (sum & 1) ? 0 : 1; // (1) int s = 0; for (int i = start; i < n; ++i) s += dfs(n, a, i + 1, k - 1, sum + a[i]); // (2) return s; }
Python代码实现如下:
def dfs(n, a, start, k, sum_): if k == 0: return 0 if sum_ & 1 else 1 #(1) s = 0 for i in range(start, n): s += dfs(n, a, i+1, k-1, sum_ + a[i]) # (2) return s
这是一个经典的深度优先遍历的过程,对于初学者来说可能比较难理解,这个过程比较复杂。
- (1)dfs(int n, inta[], int start, int k, int k, int sum)这个函数的含义是:给定n元素的数组a[],从下标start开始,选择k个元素,得到的和为sum的情况下的方案数,当k=0时代表的是递归的出口;
- (2)当前第 i元素选择以后,剩下就是从i+1个元素开始选择k-1个的情况,递归求解。
- 我们简单分析一下,n个元素选择k个,根据排列组合,方案数为:C(n,k),当n=1000,k=500时已经是天文数字,这段代码是完全出不了解的。
- 当然,对于初学者来说,这段代码如果不理解,问题也不大,只是为了说明穷举这个思想。
时间复杂度
时间复杂度的表示法
在进行算法分析时,语句总的执行次数T(n)是关于问题规模n的函数,进而分析T(n)随着n的变化情况而确定T(n)的数量级。
算法的时间复杂度,就是算法的时间度量,记作: T(n)=O(f(n)) 用大写的O来体现算法时间复杂度的记法,我们称之为大O记法。
- 时间函数
时间复杂度往往会联系到一个函数,自变量表示规模,应变量表示执行时间。
这里所说的执行时间,是指广义的时间,也就是单位并不是"秒"、"毫秒"这些时间单位,它代表的是一个"执行次数"的概念。我们用f(n)来表示这个时间函数。
- 经典函数举例
在【例题1】中,我们接触到了单层循环,这里的n是一个变量,随着n的增大,执行次数增大,执行时间就会增加,所以就有了时间函数的表示法如下:f(n)=n
这个就是最经典的线性时间函数
在【例题2】中,我们接触到了双层循环,它的时间函数表示法如下:f(n) = n(n-1)/2。也就是随着n的增大,消耗的时间越多些。

这是一个平方级别的时间函数
在【例3】中,我们接触到了三层循环,它的时间函数表示法如下:f(n) = n(n-1)(n-2)/6
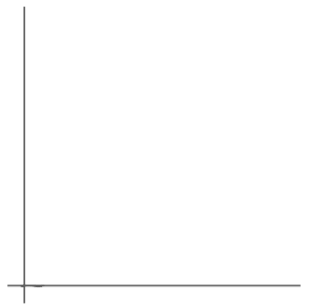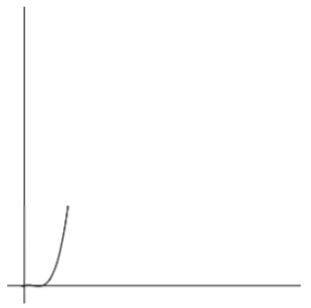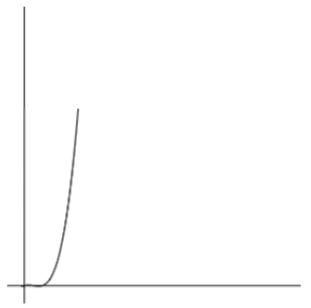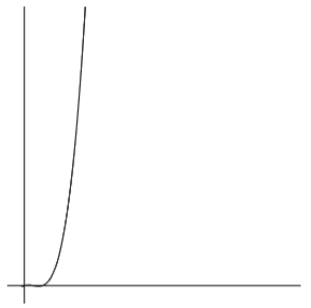
这是一个立方级别的时间函数。
时间复杂度
一个算法中的语句执行次数称为语句频度或时间频度。记为T(n)。
并且我们有一个更加优雅的表示法,即:T(n)=O(f(n))
其中O念成大O;
- 当f(n)=n,我们称这个算法拥有线性时间复杂度,记作O(n);
- 当f(n)=n(n-1)/2,我们称这个算法拥有平方级时间复杂度,记作O(n^2);
- 当f(n)=n(n-1)(n-2)/6,我们称这个算法拥有立方级的时间复杂度,记作O(n^3);
这时候我们发现,f的函数可能很复杂,但是O表示的函数往往比较简单,它舍弃了一些"细节",这是为什么呢?
接下来我们来谈下数学上一个非常有名的概念"高阶无穷小"。
高阶无穷小
有这么一个定义:如果lim(B/a)=0,则称"β是比a较高阶的无穷小"。
如果对极限没有什么概念,我会用更加通俗的语言来解释一下。
我们来看上面提到的一个函数:
f(n) = n(n-1) / 2
总共两部分组成:一部分是n^2的部分,另一部分是n的部分,直观感受,那个更大呢?
显而易见,一定是n^2,相对于n^2来说,n就是"小巫见大巫"!
所以随着n的增长,线性的部分增长已经跟不上平方部分,这样,线性部分的时间消耗相对于平方不分来说已经"微不足道",所以我们就索性不提它了,于是就有时间复杂度表示如下
\(T(n) = O(f(n))\)
\(=O(\frac{1}{2} n^2 - \frac{1}{2}n)\)
\(=O(\frac{1}{2} n^2)\)
\(=O(n^2)\)
所以它的时间复杂度就是 O(n^2)了。
简化系数
我们发现上述的公式推导的过程中,将n^2前面的系数1/2给去掉了,这是由于时间复杂度描述的更多的是一个数量级,所以尽量减少干扰项。对于两个不同的问题,可能执行时间不同,但是我们可以说他们的 时间复杂度 是一样的。
接下来让我们来看下一些常见的时间复杂度。
常见的时间复杂度
常数阶
const int MAXN = 1024; int getMAXN() { return MAXN; }
这个比较好理解,一共就一句话,没有循环,是常数时间,表示为O(1)。
对数阶
【例题4】给定n(n<=10000000)个元素的有序数组 ai 和整数v,才v在数组中的下标,不存在输出-1。
这个问题就是一个常见的查询问题,我们可以用O(n)的算法遍历整个数组,然后去找v的值。
当然,也有更快的办法,注意到题目中的条件,数组ai是是有序的,所以我们可以利用二分查找来实现。
C/C++代码实现如下:
int bin(int n, int a[], int v) { int l = 0, r = n - 1; while (l <= r) { int mid = (l + r) >> 1; // 右移一位相当于对原来的这个数除上2 if (a[mid] == v) return mid; else if (a[mid] < v) r = mid + 1; else l = mid + 1; } return -1; }
python代码实现如下:
def bin(n, a, v): l = 0 r = n -1 while l <= r: mid = (l + r) // 2 if a[mid] == v: return mid elif a[mid] < v: r = mid + 1 else: l = mid + 1 return -1
这是一个二分查找的实现,时间复杂度为O(logn)。
每次相当于把n切半,即:
\(n \rightarrow \frac{n}{2} \rightarrow \frac{n}{4} \rightarrow \dots \rightarrow \frac{n}{2^k} \rightarrow \dots \rightarrow 0\)
这条路径长度也就是执行次数,也就是要求 \(2^k \leq n\) 中的 k 的最大值,两边取以2为底的对数,得到:
\(k \leq log_{2^n}\)
所以 T(n) = O(f(n)) = O(k) = O(logn)。
根号阶
【例题5】给定一个数n(n<=10^9),问n是否是一个素数(素数的既念,就是除了1和它本身,没有其它因子)。
基于素数的概念,我们可以枚举所有i属于[2,n),看能否整除n,一旦能整除,代表找到了一个因子,则不是素数;当所有数枚举完还没找到,它就是素数。
但是这样做,显然效率太低,所以我们需要进行一些思考,最后得到以下算法:
C/C++代码实现如下:
bool isPrime(int n) { int i; if (n == 1) { return false; } int sqrtn = sqrt(n + 0.0); for (int i = 2; i <= sqrtn; ++i) { if (n % i == 0) { return false; } } return true; }
Python代码实现如下:
import math def isPrime(n): if n == 1: return False sqrtn = int(math.sqrt(n)) for i in range(2, sqrtn + 1): if n % i == 0: return False return True
这个算法的时间复杂度为O(根号n)。
为什么只需要枚举根号n内的数呢?
因为一旦有一个因子s,必然有另一个因子n/s,它们之间必然有个大小关系,无论是s<=n/s还是n/s <= s,都能通过两边乘上s得出:
\(s \leq \sqrt{n}\)
线性阶
【例题1】中我们接触到的单层循环,这里的n是一个变量,随着着n的增大,执行次数增大,执行时间就会增加,所以就有了时间函数的表示法如下:
f(n) = n
这个就是最经典的线性时间,即O(n)。
线性对数阶
【例题6】给定n(n<=10000000)个元素ai,求满足ai+aj=1024的有序二元组(i,j)有多少对。
首先,还是先思考最朴素的算法,当然是两层枚举了,参考【例题2】,时间复杂度O(n^2)。
但是,这个问题n的范围较大。
我们来看下这个问题,如果你对【例题4】已经理解了,那那么这个问题也就不难了。
我们可以先对所有元素ai按照递增排序,然后枚举ai,并且在[i-+1, n)范围内找是否存在aj=1024
多项式阶
多项式的含义是函数f(n)可以表示成如下形式:
\(f(n) = an^k + bn^{k-1} + \dots + C\)
所以O(n^5)、O(n^4)、O(n^3)(立方阶)、O(n^2)(平方阶)、O(n)(线性阶)都是多项式时间。
指数阶
【例题7】给出n(n<=15)个点,以及每两个点之间的关系(连通还是不连通),求一个最大的集合,使得在这个集合中都连通。
这是求子集的问题,由于最多只有15个点,我们就可以枚举每个点选或者不选,总共2^n种情况,然后再判断是否满足题目中的连通性,这个算法时间复杂度为O(n^2 * 2^n);
当然有更加优秀的算法,但不是本文讨论的重点,所以就交给优秀的你自己去探索啦!
阶乘阶
【例题8】给定n(n<=12)个点,并且给出任意两点间的距离,求从S点开始经过所有点回到S的距离的最小值。
这个问题就是典型的暴力枚举所有情况求解,可以把这些点当成是一个排列,所以排列方案数为 n! 。
暴力枚举的时间复杂度为O(n!)。
当然,一般这类问题,暴力搜索没有实际意义,我们可以通过动态规划来进行优化。
如何判断时间复杂度
接下来我们来讨论下,如何通过一个问题的规模来判断这个个问题应该能够承受的时间复杂度。
标准
首先,我们需要一个标准,也就是总执行次数多少合适。
这个标准是我经过多年做题经验得出,我们把它定义为S = 10^6。一个数据如果跑 10^6 以上,那么时间复杂度就是偏高了。
问题规模
有了标准以后,我们还需要知道问题规模,也就是O(n)中的n。
套公式
然后就是凭感觉套公式了。
- 当n<12时,可能是需要用到阶乘级别的算法,即 \(O(n!)\);
- 当n<16时,可能是需要状态压缩的算法,比如 \(O(2^n) 、 O(n2^n) 、 O(n^22^n)\);
- 当n<30时,可能是需要 \(O(n^4)\) 的算法,因为 \(30^4\) 差不多接近 \(10^6\);
- 当n<100时,可能是需要 \(O(n^3)\) 的算法,因为 \(100^3 = 10^6\);
- 当n<1000时,可能是需要 \(O(n^2)\) 的算法,因为 \(1000^2 = 10^6\);
- 当n<100000时,可能是需要 \(O(nlog_{2^n}) 、 O(n(log_{2^n})^2)\) 的算法;
- 当n<1000000时,可能是需要 \(O(\sqrt{n}) 、 O(n)\) 的算法;
细心的读者可能会发现,我在描述的时候都是用了可能的话语气,那是因为以上数据量都是我通过做题总结出来的,有时候还需要结合题目本身的时间限制、出题人的阴险程度来决定,所以不能一概而论。
空间复杂度
前言
很多人觉得算法难,是因为被困在了时间和空间这两个维度上。如果不考虑时间和空间的因素,其实我们可以把所有问题都通过「穷举法」来解决,也就是你告诉计算机你要做什么,然后通过它强大的算力帮你计算。
那么。今天我就和大家来聊一下「算法空间复杂度」。
概念
空间复杂度是指算法在执行过程中所需的额外存储空间。这包括算法在运行时使用的变量、数组、链表等数据结构所占用的内存空间。它和算法的时间复杂度一起,是衡量算法性能的重要指标之一。
- 额外存储空间:比如给写一个n个元素的数组要你怎么样怎么样。如果你不用其它额外的空间,空间复杂度就是O(1),也就是说这个给你的数组不能算在空间复杂度里。
在算法设计中,我们通常希望尽可能地降低空间复杂度,以减少内存的使用,提高算法的效率。然而,在某些情况下,为了实现算法的功能,可能需要使用更多的存储空间。
常见数据结构的空间复杂度
- 顺序表:0(n),其中n是顺序表的长度。
- 链表:O(n),其中n是链表的长度。
- 栈:O(n),其中n是栈的最大深度。
- 队列:O(n),其中n是队列的最大长度。
- 哈希表:O(n),其中n是哈希表中元素的数量。
- 树:O(n),其中n是树的结点数量。
- 图:O(n+m),其中n是图中顶点的数量,其中m是图中边的数量。
当然具体情况还需要具体分析。
空间换时间
通常使用额外空间的目的,就是为了换取时间上的效率,也就是我们常说的空间换时间。最经典的空间换时间就是动态规划,例如求一个斐波那契数列的第n项的值,如如果不做任何优化,就是利用循环进行计算,时间复杂度O(n),但是如果引入了数组,将计算结果预先存储在数组中,那么每次询问只需要0(1)的时间复杂度就可以得到第n项的值,而这时,由于引入了数组,所以空间复杂度就变成了O(n)。
总结
对于空间复杂度,不需要太过纠结于概念,学习动态规划以后,会对它有非常深刻的理解。
环境介绍
- 在线编译 https://www.jyshare.com/compile/12/
- 杭电在线评测系统 HDOJ https://acm.hdu.edu.cn/ (相对简单)
- Problem Archive 第11页是中文题目
- 北大在线评测系统 POJ http://poj.org/ (相对难些)
- Register 注册账号。在 Problems 找到题目。
- 力扣核心代码模式 https://leetcode.cn/problemset/ (面向求职的,相对简单)
语言其实也不重要,最重要的还是数据结构和算法的思想 。
线性枚举
线性枚举(概念篇)
线性枚举特点
- 暴力算法
- 简单有效
- 用于开拓思路
- 没有数据结构基础也可以学
问题描述
4 3 5 6 2 7 1
- 求上述数组中的最大值
- 求上述数组中的元素和
算法描述
求最大值
- 初始化max=-1000
- 遍历数组,大于max就更新max
元素求和
- sum = 0
- 遍历数组,累加
代码分析
求最大值
int getMax(int n, vector<int> a) { int max = -100000; for (int i = 0; i <=n-1; ++i) { if (a[i] > max) { max = a[i]; } } return max; }
求和
int getSum(int n, vector<int> a) { int sum = 0; for (int i = 0; i <=n-1; ++i) { sum += a[i]; } return sum; }
细节分析
第一点、时间复杂度
线性枚举的时间复杂度为0(nm),其中n是线性表的长度。m是每次操作的量级,对于求最大值和求和来说,因为操作比较简单,所以m为1,则整体的时间复杂度是O(n)的。这是因为线性枚举需要遍历列表中的每个元素。在处理大规模数据时,可能需要使用更高效的算法来提高搜索速度。
第二点、优化算法
对于线性枚举,有很多优化算法,具体我们会在后续章节中一一解密,目前先做一个简单介绍。
- 二分查找: 如果线性表已经排序,可以使用二分搜索来提高搜索效率
- 哈希表: 可以使用哈希表来存储已经搜索过的元素,避免重复搜索
- 前缀和: 可以存储前i个元素的和,避免重复计算。
- 双指针: 可以从两头开始搜索,提升搜索效率。
线性枚举(实战篇)
存在连续三个奇数的数组
https://leetcode.cn/problems/three-consecutive-odds/
给你一个整数数组 arr,请你判断数组中是否存在连续三个元素都是奇数的情况:如果存在,请返回 true ;否则,返回 false 。 示例 1: 输入:arr = [2,6,4,1] 输出:false 解释:不存在连续三个元素都是奇数的情况。 示例 2: 输入:arr = [1,2,34,3,4,5,7,23,12] 输出:true 解释:存在连续三个元素都是奇数的情况,即 [5,7,23] 。 提示: 1 <= arr.length <= 1000 1 <= arr[i] <= 1000
class Solution { public: bool threeConsecutiveOdds(vector<int>& arr) { for(int i = 0; i+2 < arr.size(); ++i) { int a = arr[i]; int b = arr[i+1]; int c = arr[i+2]; //if(a & 1 && b & 1 && c &1) { if(a % 2 && b % 2 && c % 2) { return true; } } return false; } };
最大连续 1 的个数
https://leetcode.cn/problems/max-consecutive-ones/
给定一个二进制数组 nums , 计算其中最大连续 1 的个数。 示例 1: 输入:nums = [1,1,0,1,1,1] 输出:3 解释:开头的两位和最后的三位都是连续 1 ,所以最大连续 1 的个数是 3. 示例 2: 输入:nums = [1,0,1,1,0,1] 输出:2 提示: 1 <= nums.length <= 105 nums[i] 不是 0 就是 1.
class Solution { public: int findMaxConsecutiveOnes(vector<int>& nums) { int pre = 0; // 前面有多少个连续的1 int max = 0; // 到当前这个数截至以后最大连续1的个数 // 枚举数组 for(int i = 0; i < nums.size(); ++i) { if(nums[i] == 1) { pre = pre + 1; if (pre > max) { max = pre; } } else if(nums[i] == 0) { pre = 0; } } return max; } };
有序数组中的单一元素
https://leetcode.cn/problems/single-element-in-a-sorted-array/
给你一个仅由整数组成的有序数组,其中每个元素都会出现两次,唯有一个数只会出现一次。 请你找出并返回只出现一次的那个数。 你设计的解决方案必须满足 O(log n) 时间复杂度和 O(1) 空间复杂度。 示例 1: 输入: nums = [1,1,2,3,3,4,4,8,8] 输出: 2 示例 2: 输入: nums = [3,3,7,7,10,11,11] 输出: 10 提示: 1 <= nums.length <= 105 0 <= nums[i] <= 105
class Solution { public: int singleNonDuplicate(vector<int>& nums) { // 因为是有序数组,那么相同的数一定是相邻的。 // 只出现一次的数只要比较和它左边的数是否相等、和右边的数是否相等 // 第1个元素到倒数第2个元素 for (int i = 1; i < nums.size() -1; ++i) { if(nums[i] != nums[i-1] && nums[i] != nums[i+1]) { return nums[i]; } } // 只有1个元素 if(nums.size() == 1) { return nums[0]; } // 第1和第2个元素 if(nums[0] != nums[1]) { return nums[0]; } return nums.back(); // 都不相等返回最后一个元素 } };
课后习题
模板题集
课内题集
课后题集
- 2025
- 三元组中心问题
- 企业组织结构优化
- 单词分析
- 园艺
- 成绩统计
- 数位倍数
- 桥接字符
- 消失的蓝宝
- 逛商场
- 门牌制作
- A Mathematical Curiosity
- Ignatius and the Princess IV
- Financial Management
- 猜数字
- 数组中两元素的最大乘积
- 寻找旋转排序数组中的最小值
- 寻找旋转排序数组中的最小值 II
- 第三大的数
- 三个数的乘积
- 使数组变成交替数组的最小操作数
- K 个元素的最大和
- 拿硬币
- 值相等的最小索引
- 删除有序数组中的重复项
- 将找到的值乘以 2
- 检查是否所有 A 都在 B 之前
- 银行中的激光束数量
- 移除元素
- 写字符串需要的行数
- 按符号重排数组
- 数组元素和与数字和的绝对差
- 数组能形成多少数对
- 两个数组的交集
- 两个数组间的距离值
- 最大交换
- 至少在两个数组中出现的值
- 统计上升四元组
模拟
模拟(概念篇)
模拟算法其实就是根据题目做,题目要求什么,就做什么。一些复杂的模拟题其实还是把一些简单的操作组合了一下,所以模拟题是最锻炼耐心的,也是训练编码能力的最好的暴力算法。
数据结构
对于模拟题而言,最关键的其实是数据结构,看到一个问题,选择合适的数据结构,然后根据问题来实现对应的功能。模拟题的常见数据结构主要就是:数组、字符串、矩阵、链表、二叉树 等等。
1、基于数组 利用数组的数据结构,根据题目要求,去实现算法,如:
2、基于字符串 利用字符串的数据结构,根据题目要求,去实现算法,如:
3、基于链表 利用链表的数据结构,根据题目要求,去实现算法,如:
4、基于矩阵
利用矩阵的数据结构,根据题目要求,去实现算法,如:
5、基于栈 利用栈的数据结构,如:1441.用栈操作构建数组 6、基于队列 利用队列的数据结构,如:1700.无法吃午餐的学生数量
算法技巧
模拟时一般会用到一些算法技巧,或者说混合算法,比如 排序、递归、迭代 等等。
1、排序 排序后,干一件事情,如:950.按递增顺序显示卡牌 2、递归
需要借助递归来实现,如:1688.比赛中的配对次数 、2169.得到 0 的操作数、258.各位相加 3、迭代
不断迭代求解,其实就是利用 while 循环来实现功能,如:1860.增长的内存泄露、258.各位相加
模拟(实战篇)
互换数字
https://leetcode.cn/problems/swap-numbers-lcci/
编写一个函数,不用临时变量,直接交换numbers = [a, b]中a与b的值。 示例: 输入: numbers = [1,2] 输出: [2,1] 提示: numbers.length == 2 -2147483647 <= numbers[i] <= 2147483647
class Solution { public: vector<int> swapNumbers(vector<int>& a) { a[0] = a[0] ^ a[1]; a[1] = a[0] ^ a[1]; // (a[0] ^ a[1] ^ a[1]) == a[0] ^ 0 == a[0] a[0] = a[0] ^ a[1]; // a[0] == 原先的a[0] ^ a[1] ; a[1] = a[0];所以 a[0] ^ a[1] ^ a[0] == a[1] return a; } };
位 1 的个数
https://leetcode.cn/problems/er-jin-zhi-zhong-1de-ge-shu-lcof/
编写一个函数,输入是一个无符号整数(以二进制串的形式), 返回其二进制表达式中数字位数为 '1' 的个数(也被称为 汉明重量).)。 提示: 请注意,在某些语言(如 Java)中,没有无符号整数类型。在这种情况下, 输入和输出都将被指定为有符号整数类型,并且不应影响您的实现, 因为无论整数是有符号的还是无符号的,其内部的二进制表示形式都是相同的。 在 Java 中,编译器使用 二进制补码 记法来表示有符号整数。 因此,在上面的 示例 3 中,输入表示有符号整数 -3。 示例 1: 输入:n = 11 (控制台输入 00000000000000000000000000001011) 输出:3 解释:输入的二进制串 00000000000000000000000000001011 中,共有三位为 '1'。 示例 2: 输入:n = 128 (控制台输入 00000000000000000000000010000000) 输出:1 解释:输入的二进制串 00000000000000000000000010000000 中,共有一位为 '1'。 示例 3: 输入:n = 4294967293 (控制台输入 11111111111111111111111111111101,部分语言中 n = -3) 输出:31 解释:输入的二进制串 11111111111111111111111111111101 中,共有 31 位为 '1'。 提示: 输入必须是长度为 32 的 二进制串 。
class Solution { public: int hammingWeight(uint32_t n) { int sum = 0; // 表示多个1 // 当n不等于0时,看n的最低位是多少 while(n) { // sum += n % 2; // n /= 2; // 优化 sum += n & 1; n = (n >> 1); // 右移1位,就是不断除2 } return sum; } }; // 00000000000000000000000000001011 // 00000000000000000000000000000001
找到数组的中间位置
https://leetcode.cn/problems/find-the-middle-index-in-array/
给你一个下标从 0 开始的整数数组 nums , 请你找到 最左边 的中间位置 middleIndex (也就是所有可能中间位置下标最小的一个)。 中间位置 middleIndex 是满足 nums[0] + nums[1] + ... + nums[middleIndex-1] == nums[middleIndex+1] + nums[middleIndex+2] + ... + nums[nums.length-1] 的数组下标。 如果 middleIndex == 0 ,左边部分的和定义为 0 。类似的, 如果 middleIndex == nums.length - 1 ,右边部分的和定义为 0 。 请你返回满足上述条件 最左边 的 middleIndex ,如果不存在这样的中间位置,请你返回 -1 。 示例 1: 输入:nums = [2,3,-1,8,4] 输出:3 解释: 下标 3 之前的数字和为:2 + 3 + -1 = 4 下标 3 之后的数字和为:4 = 4 示例 2: 输入:nums = [1,-1,4] 输出:2 解释: 下标 2 之前的数字和为:1 + -1 = 0 下标 2 之后的数字和为:0 示例 3: 输入:nums = [2,5] 输出:-1 解释: 不存在符合要求的 middleIndex 。 示例 4: 输入:nums = [1] 输出:0 解释: 下标 0 之前的数字和为:0 下标 0 之后的数字和为:0 提示: 1 <= nums.length <= 100 -1000 <= nums[i] <= 1000
class Solution { public: int findMiddleIndex(vector<int>& nums) { // 时间复杂度 O(n^2),因为数组长度只有100, 100^2 = 10000 // 更好的办法是前缀和了,这次用最简单的模拟的方法来做 for (int i = 0; i < nums.size(); ++i) { int l = 0, r = 0; // 左边和l;右边和r for (int j = 0; j < i; ++j) { l += nums[j]; } for (int j = i + 1; j < nums.size(); ++j) { r += nums[j]; } if (l == r) { return i; } } return -1; } };
递推
递推(概念篇)
递推是动态规划的基础。
递推最通俗的理解就是数列,递推和数列的关系就好比 算法 和 数据结构 的关系,数列有点像数据结构中的线性表(可以是顺序表,也可以是链表,一般情况下是顺序表),而递推就是一个循环或者迭代的枚举过程。
递推本质上是数学问题,所以有同学问算法是不是需要数学非常好,也并不是,你会发现,这些数学只不过是初中高中我们学烂的东西,高考都经历了,这些东西又何足为惧!?
斐波那契数列
斐波那契数(通常用F(n) 表示)形成的序列称为 斐波那契数列 。该数列由0 和 1 开始,后面的每一项数字都是前面两项数字的和。也就是:
F(0) = 0,F(1)= 1 F(n) = F(n - 1) + F(n - 2),其中 n > 1,给定n(0 ≤ n ≤ 30) ,请计算 F(n) 。
拿到这个题目,我们首先来看题目范围,最多不超过 30,那是因为斐波那契数的增长速度很快,是指数级别的。所以如果n 很大,就会超过 c语言 中32位整型的范围。这是一个最基础的递推题,递推公式都已经告诉你了,我们要做的就是利用一个循环来实现这个递推。
我们只需要用一个 F[31] 数组,初始化好 F[0] 和 F[1],然后按照给定的公式循环计算就可以了。写成伪代码像这样:
int fib(int n) { int i; // (1) int F[31] = {0, 1}; // (2) for(i = 2; i <= n; ++i) { // (3) F[i] = F[i-1] + F[i-2]; // (4) } return F[n]; // (5) }
- 首先定义一个循环变量;
- 再定义一个数组记录斐波那契数列的第 n 项,并且初始化第0项 和 第1项。
- 然后一个 for 循环,从第 2 项开始;
- 利用递推公式逐步计算每一项的值;
- 最后返回第n项即可。
泰波那契数列
泰波那契序列Tn定义如下:
T(0) = 0, T(1) = 1, T(2) = 1
且在 n > 2的条件下 T(n) = T(n-1) + T(n-2) + T(n-3),给你整数n,请返回第 n 个泰波那契数T(n) 的值。
如果已经理解斐波那契数列,那么这个问题也不难,只不过初始化的时候,需要初始化前三个数,并且在循环迭代计算的时候,当前数的值需要前三个数的值累加和。像这样:
int tribonacci(int n){ int T[100]; T[0] = 0; T[1] = 1; T[2] = 1; for(int i = 3; i <= n; ++i) { T[i] = T[i-1] + T[i-2] + T[i-3]; } return T[n]; }
斐波那契数列变形
给定一个n(1 ≤ n ≤ 45)代表总共有n阶楼梯,一开始在第0阶,每次可以爬1或者2个台阶,问总共有多少种不同的方法可以爬到楼顶。
我们定义一个数组f[46],其中f[i] 表示从第0 阶爬到第 i阶的方案数。由于每次可以爬1或者2个台阶,所以对于第i阶楼梯来说,所以要么是从第i-1阶爬过来的,要么是从 i-2阶爬过来的,如图所示: 于是得出一个递推公式:f[i] = f[i-1] + f[i-2]。
我们发现这个就是斐波那契数列,你可以叫它递推公式,也可以叫它状态转移方程。这里的 f[i]就是状态的概念,从一个状态到另一个状态就叫状态转移。状态转移是在动态规划中非常重要的概念。
当然我们还要考虑初始状态,f[0]代表从第0阶到第0阶的方案数,当然就是1啦,f[1]代表从第0阶到第1阶的方案数,由于只能走1阶,所以方案数也是1。
代码就不再累述了。
二维递推问题
像斐波那契数列这种问题,是一个一维的数组来解决的,有些时候,一维解决不了的时候,我们就需要升高一个维度来看问题了。
长度为n(1≤n<40)的只由'A'、'C'、'M'三种字符组成的字符串(可以只有其中一种或两种字符,但绝对不能有其他字符)且禁止出现 M 相邻的情况,问这样的串有多少种?
考虑长度为n,且以 'A' 结尾的串有f[n][0]种、以 'C' 结尾的串有f[n][1]种、以 'M' 结尾的串有f[n][2]种,那么我们要求的答案就是:
\begin{equation*} \sum_{i=0}^2 \ f[n][i] \end{equation*}想一下怎么进行递推???
如果第n个结尾的字符是 'A' 或者 'C',那么显然, 第n−1个字符可以是任意字符;而如果第n个结尾的字符是 'M',那么第n−1个字符只能是是 'A' 或者 'C'。所以可以得到递推公式如下:
\begin{equation*} f[n][0] \ = \ f[n-1][0] + f[n-1][1] + f[n-1][2] \end{equation*} \begin{equation*} f[n][1] \ = \ f[n-1][0] + f[n-1][1] + f[n-1][2] \end{equation*} \begin{equation*} f[n][2] \ = \ f[n-1][0] + f[n-1][1] \end{equation*}到这一步,我们就可以利用程序求解了(二维数组,枚举后再求和),但是,还可以化解,由于
i是从0到2
\begin{equation*} \sum_{i=0}^2 \ f[n][i] \ = \ f[n][0] + f[n][1] + f[n][2] \end{equation*}于是,可以得出:
\begin{equation*} f[n][0] \ = \ \sum_{i=0}^2 \ f[n-1][i] \end{equation*} \begin{equation*} f[n][1] \ = \ \sum_{i=0}^2 \ f[n-1][i] \end{equation*} \begin{equation*} f[n][2] \ = \ \sum_{i=0}^2 \ f[n-2][i] + \sum_{i=0}^2 \ f[n-2][i] \end{equation*}从而得到:
\begin{equation*} \sum_{i=0}^2 \ f[n][i] \ = \ 2* ( \sum_{i=0}^2 \ f[n-1][i] + \sum_{i=0}^2 \ f[n-2][i] ) \end{equation*} \begin{equation*} g[n] \ = \ \sum_{i=0}^2 \ f[n][i] \end{equation*}原式可以化解为如下递推式(升维再降维):
\begin{equation*} g[n] \ = \ 2 * (g[n-1] + g[n-2]) \end{equation*}然后我们手动算出长度为 1 和 长度为 2 的串的方案数分别是3和8,递推的伪代码如下:
long long getACM(int n) { long long g[40]; g[1] = 3, g[2] = 8; for(i = 3; i <= n; i++) { g[i] = 2 * (g[i-1] + g[i-2]); } return g[n]; }
递推(实战篇)
斐波那契数
https://leetcode.cn/problems/fibonacci-number/
斐波那契数 (通常用 F(n) 表示)形成的序列称为 斐波那契数列 。 该数列由 0 和 1 开始,后面的每一项数字都是前面两项数字的和。也就是: F(0) = 0,F(1) = 1 F(n) = F(n - 1) + F(n - 2),其中 n > 1 给定 n ,请计算 F(n) 。 示例 1: 输入:n = 2 输出:1 解释:F(2) = F(1) + F(0) = 1 + 0 = 1 示例 2: 输入:n = 3 输出:2 解释:F(3) = F(2) + F(1) = 1 + 1 = 2 示例 3: 输入:n = 4 输出:3 解释:F(4) = F(3) + F(2) = 2 + 1 = 3 提示: 0 <= n <= 30
class Solution { public: int fib(int n) { // n是 0 到30就是31个数 int f[31]; f[0] = 0; f[1] = 1; for(int i = 2; i <= n; i++) { f[i] = f[i -1] + f[i-2]; } return f[n]; } };
爬楼梯
https://leetcode.cn/problems/climbing-stairs/
假设你正在爬楼梯。需要 n 阶你才能到达楼顶。 每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢? 示例 1: 输入:n = 2 输出:2 解释:有两种方法可以爬到楼顶。 1. 1 阶 + 1 阶 2. 2 阶 示例 2: 输入:n = 3 输出:3 解释:有三种方法可以爬到楼顶。 1. 1 阶 + 1 阶 + 1 阶 2. 1 阶 + 2 阶 3. 2 阶 + 1 阶 提示: 1 <= n <= 45
class Solution { public: int climbStairs(int n) { // 1 <= n <= 45 int f[46]; f[0] = 1; f[1] = 1; for(int i = 2; i <= n ; ++i) { f[i] = f[i-1] + f[i-2]; } return f[n]; } }; // 0 1 2 3 4 5 6 // 1 1 2 3 5 8 13 // 爬2阶时,可以爬1阶或者2阶,方法数是2 // 爬3阶时,可以在爬第2阶时再爬1阶,2阶的方案数是2,也可以在1阶时爬2阶,方案数是1,1+2=3 // 爬4阶时,可以在爬第2阶时再爬2阶,2阶的方案数是2,也可以3阶时爬1阶,3阶的方案数是3,2+3=5 // 发现规律:任何一数都等于前俩项之和
杨辉三角 II
https://leetcode.cn/problems/pascals-triangle-ii/
给定一个非负索引 rowIndex,返回「杨辉三角」的第 rowIndex 行。 在「杨辉三角」中,每个数是它左上方和右上方的数的和。 示例 1: 输入: rowIndex = 3 输出: [1,3,3,1] 示例 2: 输入: rowIndex = 0 输出: [1] 示例 3: 输入: rowIndex = 1 输出: [1,1] 提示: 0 <= rowIndex <= 33
class Solution { public: vector<int> getRow(int rowIndex) { // 0 <= rowIndex <= 33 int f[34][34]; for(int i = 0; i <= rowIndex; ++i ) { for(int j = 0; j <= i; ++j) { if(j == 0 || j == i) { f[i][j] = 1; } else // 其他元素的值等于上一行同位置元素值加上上一行前一个位置值的和 { f[i][j] = f[i-1][j] + f[i-1][j-1]; } } } vector<int> ret; for(int j = 0; j <= rowIndex; ++j) { ret.push_back( f[rowIndex][j] ); } return ret; } }; /* 用二维数组来存储 1 0 0 0 0 第0行 1 1 0 0 0 第1行 1 2 1 0 0 1 3 3 1 0 1 4 6 4 1 发现第1列元素值都为1, 对角线元素值为1, 其他元素的值等于上一行同位置元素值加上上一行前一个位置值的和 */
杨辉三角 II(空间优化)
进阶: 你可以优化你的算法到 O(rowIndex) 空间复杂度吗?
class Solution { public: vector<int> getRow(int rowIndex) { // 因为每一行的值都等于上一行的值,可以用滚动数组解决。使用2维就可以了 int f[2][34]; int now = 1; int pre = 0; f[pre][0] = 1; for(int i = 1; i <= rowIndex; ++i ) { for(int j = 0; j <= i; ++j) { if(j == 0 || j == i) { f[now][j] = 1; } else // 其他元素的值等于上一行同位置元素值加上上一行前一个位置值的和 { f[now][j] = f[pre][j] + f[pre][j-1]; } } // 计算完后,pre就没用了。pre和now交换 //pre = 1 - pre; // pre 和 now 有一个是0有一个是1 //now = 1 - now; pre ^= 1; now ^= 1; } vector<int> ret; for(int j = 0; j <= rowIndex; ++j) { ret.push_back( f[pre][j] ); } return ret; } }; /* 用二维数组来存储 1 0 0 0 0 第0行 1 1 0 0 0 第1行 1 2 1 0 0 1 3 3 1 0 1 4 6 4 1 发现第1列元素值都为1, 对角线元素值为1, 其他元素的值等于上一行同位置元素值加上上一行前一个位置值的和 */
选择排序
选择排序(概念篇)
选择排序(Selection Sort)是一种简单直观的排序算法。它首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
算法思想
第一步、在未排序序列中找到最小(大)元素,存放到排序序列的起始位置。
第二步、再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。
重复第二步,直到所有元素均排序完毕。
算法分析
1、时间复杂度
- 选择排序中有两个嵌套循环。当有 n 个元素时,外循环正好运行n−1次迭代。 但内部循环运行变得越来越短:
- 当i=0,内层循环n−1次「比较」操作。
- 当i=1,内层循环n−2次「比较」操作。
- 当i=2,内层循环n−3次「比较」操作。
- ……
- 当i=n−3,内层循环2次「比较」操作。
- 当i=n−2,内层循环1次「比较」操作。
因此,总「比较」次数如下:(n−1)+…+2+1=n(n−1)/2,总的时间复杂度为:O(n^2)。
2、空间复杂度
选择排序的空间复杂度为 O(1)。它只使用了固定的额外空间来存储交换操作,并不依赖于输入数组的大小。
算法的优点
- 简单易懂:选择排序是一种简单直观的排序算法,容易理解和实现。
- 原地排序:选择排序不需要额外的存储空间,只使用原始数组进行排序。
- 适用于小型数组:对于小型数组(元素个数小于1000),选择排序的性能表现较好。
算法的缺点
- 时间复杂度高:在处理大规模数据时效率较低。
- 不稳定:选择排序在排序过程中可能会改变相同元素的相对顺序,因此它是一种不稳定的排序算法。
优化方案
「 选择排序 」在众多排序算法中效率较低,时间复杂度为O(n^2)。
想象一下,当有n=100000个数字。 即使我们的计算机速度超快,并且可以在 1 秒内计算10^8次操作,但选择排序仍需要大约一百秒才能完成。
考虑一下,每一个内层循环是从一个区间中找到一个最小值,并且更新这个最小值。是一个「 动态区间最值 」问题,所以这一步,我们是可以通过「 线段树 」来优化的。这样就能将内层循环的时间复杂度优化成O(log2n)了,总的时间复杂度就变成了O(nlog2n)。
当然,常见的选择排序优化是采用堆排序来进行优化的,后续我们会学到。
选择排序(实战篇)
颜色分类
https://leetcode.cn/problems/sort-colors/
给定一个包含红色、白色和蓝色、共 n 个元素的数组 nums , 原地 对它们进行排序,使得相同颜色的元素相邻,并按照红色、白色、蓝色顺序排列。 我们使用整数 0、 1 和 2 分别表示红色、白色和蓝色。 必须在不使用库内置的 sort 函数的情况下解决这个问题。 示例 1: 输入:nums = [2,0,2,1,1,0] 输出:[0,0,1,1,2,2] 示例 2: 输入:nums = [2,0,1] 输出:[0,1,2] 提示: n == nums.length 1 <= n <= 300 nums[i] 为 0、1 或 2
class Solution { void selectSort(vector<int>& a) { int n = a.size(); for (int i = 0; i < n; ++i) { int min = i; for(int j = i + 1; j < n; ++j) { if(a[j] < a[min]) { min = j; } } int tmp = a[min]; a[min] = a[i]; a[i] = tmp; } } public: void sortColors(vector<int>& nums) { selectSort(nums); } };
寻找两个正序数组的中位数
https://leetcode.cn/problems/median-of-two-sorted-arrays/
给定两个大小分别为 m 和 n 的正序(从小到大)数组 nums1 和 nums2。 请你找出并返回这两个正序数组的 中位数 。 算法的时间复杂度应该为 O(log (m+n)) 。 示例 1: 输入:nums1 = [1,3], nums2 = [2] 输出:2.00000 解释:合并数组 = [1,2,3] ,中位数 2 示例 2: 输入:nums1 = [1,2], nums2 = [3,4] 输出:2.50000 解释:合并数组 = [1,2,3,4] ,中位数 (2 + 3) / 2 = 2.5 提示: nums1.length == m nums2.length == n 0 <= m <= 1000 0 <= n <= 1000 1 <= m + n <= 2000 -106 <= nums1[i], nums2[i] <= 106
class Solution { void selectSort(vector<int>& a) { int n = a.size(); for (int i = 0; i < n; ++i) { int min = i; for(int j = i + 1; j < n; ++j) { if(a[j] < a[min]) { min = j; } } int tmp = a[min]; a[min] = a[i]; a[i] = tmp; } } public: double findMedianSortedArrays(vector<int>& nums1, vector<int>& nums2) { for(int i = 0; i < nums2.size(); ++i) { int x = nums2[i]; nums1.push_back(x); } selectSort(nums1); int n = nums1.size(); if ( n % 2) { return nums1[n/2]; } return (nums1[n/2 -1] + nums1[n/2]) / 2.0; } };
至少是其他数字两倍的最大数
https://leetcode.cn/problems/largest-number-at-least-twice-of-others/
给你一个整数数组 nums ,其中总是存在 唯一的 一个最大整数 。 请你找出数组中的最大元素并检查它是否 至少是数组中每个其他数字的两倍 。 如果是,则返回 最大元素的下标 ,否则返回 -1 。 示例 1: 输入:nums = [3,6,1,0] 输出:1 解释:6 是最大的整数,对于数组中的其他整数,6 至少是数组中其他元素的两倍。6 的下标是 1 ,所以返回 1 。 示例 2: 输入:nums = [1,2,3,4] 输出:-1 解释:4 没有超过 3 的两倍大,所以返回 -1 。 提示: 2 <= nums.length <= 50 0 <= nums[i] <= 100 nums 中的最大元素是唯一的
class Solution { void selectSort(vector<int>& a) { int n = a.size(); for (int i = 0; i < n; ++i) { int min = i; for(int j = i + 1; j < n; ++j) { if(a[j] < a[min]) { min = j; } } int tmp = a[min]; a[min] = a[i]; a[i] = tmp; } } public: int dominantIndex(vector<int>& nums) { int max = 0; for(int i = 0; i < nums.size(); ++i) { if(nums[i] > nums[max]){ max = i; } } selectSort(nums); int n = nums.size(); if(nums[n-1] >= 2*nums[n-2]) { return max; } return -1; } };
冒泡排序
冒泡排序(概念篇)
冒泡排序(Bubble Sort)是一种简单的排序算法,通过多次比较和交换相邻的元素,将数组中的元素按升序或降序排列。
算法思想
冒泡排序的基本思想是:每次遍历数组,比较相邻的两个元素,如果它们的顺序错误,就将它们交换,直到数组中的所有元素都被遍历过。
具体的算法步骤如下:
- 第一步、遍历数组的第一个元素到最后一个元素。
- 第二步、对每一个元素,与其后一个元素进行比较。
- 第三步、如果顺序错误,就将它们交换。
- 重复上述步骤,直到数组中的所有元素都被遍历过至少一次。
算法分析
1、时间复杂度
我们假设「比较」和「交换」的时间复杂度为O(1)(为什么这里说假设,因为有可能要「比较」的两个元素本身是数组,并且是不定长的,所以只有当系统内置类型,我们才能说这两个操作是O(1)的)。
「 冒泡排序 」中有两个嵌套循环。 外循环正好运行n−1次迭代。 但内部循环运行变得越来越短:
- 当i=0,内层循环n−1次「比较」操作。
- 当i=1,内层循环n−2次「比较」操作。
- 当i=2,内层循环n−3次「比较」操作。
- ……
- 当i=n−2,内层循环1次「比较」操作。
- 当i=n−1,内层循环0次「比较」操作。
因此,总「比较」次数如下:(n−1)+(n−2)+…+1+0=n(n−1)/2,总的时间复杂度为:O(n^2)。
2、空间复杂度
由于算法在执行过程中,只有「交换」变量时候采用了临时变量的方式,而其它没有采用任何的额外空间,所以空间复杂度为O(1)。
算法的优点
- 简单易懂:冒泡排序的算法思想非常简单,容易理解和实现。
- 稳定排序:冒泡排序是一种稳定的排序算法,即在排序过程中不会改变相同元素的相对顺序。
算法的缺点
- 效率较低:由于需要进行多次比较和交换,冒泡排序在处理大规模数据时效率较低。
- 排序速度慢:对于大型数组,冒泡排序的时间复杂度较高,导致排序速度较慢。
优化方案
「 冒泡排序 」在众多排序算法中效率较低,时间复杂度为O(n^2)。
想象一下,当有n=100000个数字。 即使我们的计算机速度超快,并且可以在 1 秒内计算10^8次操作,但冒泡排序仍需要大约一百秒才能完成。
但是,它的外层循环是可以提前终止的,例如,假设一开始所有数字都是升序的,那么在首轮「比较」的时候没有发生任何的「交换」,那么后面也就不需要继续进行「比较」了,直接跳出外层循环,算法提前终止。
「改进思路」如果我们通过内部循环完全不交换,这意味着数组已经排好序,我们可以在这个点上停止算法。
冒泡排序(实战篇)
合并两个有序数组
https://leetcode.cn/problems/merge-sorted-array/
给你两个按 非递减顺序 排列的整数数组 nums1 和 nums2, 另有两个整数 m 和 n ,分别表示 nums1 和 nums2 中的元素数目。 请你 合并 nums2 到 nums1 中,使合并后的数组同样按 非递减顺序 排列。 注意:最终,合并后数组不应由函数返回,而是存储在数组 nums1 中。 为了应对这种情况,nums1 的初始长度为 m + n,其中前 m 个元素表示应合并的元素, 后 n 个元素为 0 ,应忽略。nums2 的长度为 n 。 示例 1: 输入:nums1 = [1,2,3,0,0,0], m = 3, nums2 = [2,5,6], n = 3 输出:[1,2,2,3,5,6] 解释:需要合并 [1,2,3] 和 [2,5,6] 。 合并结果是 [1,2,2,3,5,6] ,其中斜体加粗标注的为 nums1 中的元素。 示例 2: 输入:nums1 = [1], m = 1, nums2 = [], n = 0 输出:[1] 解释:需要合并 [1] 和 [] 。 合并结果是 [1] 。 示例 3: 输入:nums1 = [0], m = 0, nums2 = [1], n = 1 输出:[1] 解释:需要合并的数组是 [] 和 [1] 。 合并结果是 [1] 。 注意,因为 m = 0 ,所以 nums1 中没有元素。nums1 中仅存的 0 仅仅是为了确保合并结果可以顺利存放到 nums1 中。 提示: nums1.length == m + n nums2.length == n 0 <= m, n <= 200 1 <= m + n <= 200 -109 <= nums1[i], nums2[j] <= 109
class Solution { // 冒泡排序 void bubbleSort(vector<int>& a) { int n = a.size(); for(int i = n -1; i >= 0; --i) { for(int j = 0; j < i; ++j) { if(a[j] > a[j+1]) { int tmp = a[j]; a[j] = a[j+1]; a[j+1] = tmp; } } } } public: void merge(vector<int>& nums1, int m, vector<int>& nums2, int n) { // 0 <= m, n <= 200 1 <= m + n <= 200 数据量很小。可以用任意一种O(n^2)排序算法解决 for(int i = 0; i < nums2.size(); ++i) { nums1[m+i] = nums2[i]; } bubbleSort(nums1); } };
元素计数
https://leetcode.cn/problems/count-elements-with-strictly-smaller-and-greater-elements
给你一个整数数组 nums ,统计并返回在 nums 中同时至少具有一个严格较小元素和一个严格较大元素的元素数目。 示例 1: 输入:nums = [11,7,2,15] 输出:2 解释:元素 7 :严格较小元素是元素 2 ,严格较大元素是元素 11 。 元素 11 :严格较小元素是元素 7 ,严格较大元素是元素 15 。 总计有 2 个元素都满足在 nums 中同时存在一个严格较小元素和一个严格较大元素。 示例 2: 输入:nums = [-3,3,3,90] 输出:2 解释:元素 3 :严格较小元素是元素 -3 ,严格较大元素是元素 90 。 由于有两个元素的值为 3 ,总计有 2 个元素都满足在 nums 中同时存在一个严格较小元素和一个严格较大元素。 提示: 1 <= nums.length <= 100 -105 <= nums[i] <= 105
class Solution { // 冒泡排序 void bubbleSort(vector<int>& a) { int n = a.size(); for(int i = n -1; i >= 0; --i) { for(int j = 0; j < i; ++j) { if(a[j] > a[j+1]) { int tmp = a[j]; a[j] = a[j+1]; a[j+1] = tmp; } } } } public: int countElements(vector<int>& nums) { // 排序后枚举中间的每个数 bubbleSort(nums); int cnt = 0; for (int i = 1; i < nums.size() - 1; ++i) { if(nums[i] != nums[0] && nums[i] != nums.back()) { ++cnt; } } return cnt; } };
最后一块石头的重量
https://leetcode.cn/problems/last-stone-weight/
有一堆石头,每块石头的重量都是正整数。
每一回合,从中选出两块 最重的 石头,然后将它们一起粉碎。假设石头的重量分别为 x 和 y,且 x <= y。那么粉碎的可能结果如下:
如果 x == y,那么两块石头都会被完全粉碎;
如果 x != y,那么重量为 x 的石头将会完全粉碎,而重量为 y 的石头新重量为 y-x。
最后,最多只会剩下一块石头。返回此石头的重量。如果没有石头剩下,就返回 0。
示例:
输入:[2,7,4,1,8,1]
输出:1
解释:
先选出 7 和 8,得到 1,所以数组转换为 [2,4,1,1,1],
再选出 2 和 4,得到 2,所以数组转换为 [2,1,1,1],
接着是 2 和 1,得到 1,所以数组转换为 [1,1,1],
最后选出 1 和 1,得到 0,最终数组转换为 [1],这就是最后剩下那块石头的重量。
提示:
1 <= stones.length <= 30
1 <= stones[i] <= 1000
class Solution { // 冒泡排序 void bubbleSort(vector<int>& a) { int n = a.size(); for(int i = n -1; i >= 0; --i) { for(int j = 0; j < i; ++j) { if(a[j] > a[j+1]) { int tmp = a[j]; a[j] = a[j+1]; a[j+1] = tmp; } } } } public: int lastStoneWeight(vector<int>& stones) { while( stones.size() > 1) { bubbleSort(stones); int n = stones.size(); int v = stones[n-1] - stones[n-2]; stones.pop_back(); stones.pop_back(); // 塞回去 if(v || stones.size() == 0) { stones.push_back(v); } } return stones[0]; } };
插入排序
插入排序(概念篇)
插入排序(Insertion Sort)是一种简单直观的排序算法。它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入,直到整个数组有序。
算法思想
- 第一步:从第一个元素开始,将其视为已排序部分。
- 第二步:取出下一个元素,与已排序部分的元素进行比较。
- 第三步:如果该元素小于已排序部分的最后一个元素,则将其插入到已排序部分的适当位置。
- 重复步骤 二 和 三,直到整个数组都被排序。
算法分析
1、时间复杂度
我们假设 「比较」 和 「移动」 的时间复杂度为 O(1) 的。
「 插入排序 」 中有两个嵌套循环。
外循环正好运行 n−1 次迭代。 但内部循环运行变得越来越短:
- 当 i = 1,内层循环 1 次「比较」操作。
- 当 i = 2,内层循环 2 次「比较」操作。
- 当 i = 3,内层循环 3 次「比较」操作。
- ……
- 当 i = n − 2,内层循环 n − 2 次「比较」操作。
- 当 i = n − 1,内层循环 n − 1 次「比较」操作。
因此,总「比较」次数如下:1 + 2 + . . . + ( n − 1 ) = n(n-1)/2。总的时间复杂度为:O (n^2)。
2、空间复杂度
由于算法在执行过程中,只有「移动」变量时候,需要事先将变量存入临时变量x,而其它没有采用任何的额外空间,所以空间复杂度为 O(1)。
算法的优点
- 简单易懂,易于实现。
- 适用于小型数组或基本有序的数组。
- 稳定性好,不会改变相等元素的相对顺序。
算法的缺点
- 对于大型无序数组,效率较低。
- 不适合大规模数据排序。
优化方案
「 插入排序 」在众多排序算法中效率较低,时间复杂度为 O(n^2)。
考虑,在进行插入操作之前,我们找位置的过程是在有序数组中找的,所以可以利用「二分查找」 来找到对应的位置。然而,执行 「 插入 」 的过程还是 O (n),所以优化的也只是常数时间,最坏时间复杂度是不变的。
「改进思路」执行插入操作之前利用 「 二分查找 」 来找到需要插入的位置。
插入排序(实战篇)
去掉最低工资和最高工资后的工资平均值
https://leetcode.cn/problems/average-salary-excluding-the-minimum-and-maximum-salary/
给你一个整数数组 salary ,数组里每个数都是 唯一 的,其中 salary[i] 是第 i 个员工的工资。 请你返回去掉最低工资和最高工资以后,剩下员工工资的平均值。 示例 1: 输入:salary = [4000,3000,1000,2000] 输出:2500.00000 解释:最低工资和最高工资分别是 1000 和 4000 。 去掉最低工资和最高工资以后的平均工资是 (2000+3000)/2= 2500 示例 2: 输入:salary = [1000,2000,3000] 输出:2000.00000 解释:最低工资和最高工资分别是 1000 和 3000 。 去掉最低工资和最高工资以后的平均工资是 (2000)/1= 2000 示例 3: 输入:salary = [6000,5000,4000,3000,2000,1000] 输出:3500.00000 示例 4: 输入:salary = [8000,9000,2000,3000,6000,1000] 输出:4750.00000 提示: 3 <= salary.length <= 100 10^3 <= salary[i] <= 10^6 salary[i] 是唯一的。 与真实值误差在 10^-5 以内的结果都将视为正确答案。
class Solution { // 0 1 2 3 4 5 6 x // 1 2 3 4 6 7 8 5 void insertionSort(vector<int>& a) { // 从第2个元素开始,从后向前遍历 for(int i = 1; i <a.size(); ++i) { int x = a[i]; int j; for(j = i -1; j >= 0; --j) { if(x < a[j]) { a[j+1] = a[j]; } else { break; } } a[j+1] = x; } } public: double average(vector<int>& salary) { insertionSort(salary); int n = salary.size(); double sum = 0; for(int i = 1; i < n-1; ++i) { sum += salary[i]; } return sum/ (n-2); } };
删除某些元素后的数组均值
https://leetcode.cn/problems/mean-of-array-after-removing-some-elements/
给你一个整数数组 arr ,请你删除最小 5% 的数字和最大 5% 的数字后,剩余数字的平均值。 与 标准答案 误差在 10-5 的结果都被视为正确结果。 示例 1: 输入:arr = [1,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,3] 输出:2.00000 解释:删除数组中最大和最小的元素后,所有元素都等于 2,所以平均值为 2 。 示例 2: 输入:arr = [6,2,7,5,1,2,0,3,10,2,5,0,5,5,0,8,7,6,8,0] 输出:4.00000 示例 3: 输入:arr = [6,0,7,0,7,5,7,8,3,4,0,7,8,1,6,8,1,1,2,4,8,1,9,5,4,3,8,5,10,8,6,6,1,0,6,10,8,2,3,4] 输出:4.77778 示例 4: 输入:arr = [9,7,8,7,7,8,4,4,6,8,8,7,6,8,8,9,2,6,0,0,1,10,8,6,3,3,5,1,10,9,0,7,10,0,10,4,1,10,6,9,3,6,0,0,2,7,0,6,7,2,9,7,7,3,0,1,6,1,10,3] 输出:5.27778 示例 5: 输入:arr = [4,8,4,10,0,7,1,3,7,8,8,3,4,1,6,2,1,1,8,0,9,8,0,3,9,10,3,10,1,10,7,3,2,1,4,9,10,7,6,4,0,8,5,1,2,1,6,2,5,0,7,10,9,10,3,7,10,5,8,5,7,6,7,6,10,9,5,10,5,5,7,2,10,7,7,8,2,0,1,1] 输出:5.29167 提示: 20 <= arr.length <= 1000 arr.length 是 20 的 倍数 0 <= arr[i] <= 105
class Solution { void insertionSort(vector<int>& a) { // 从第2个元素开始,从后向前遍历 for(int i = 1; i <a.size(); ++i) { int x = a[i]; int j; for(j = i -1; j >= 0; --j) { if(x < a[j]) { a[j+1] = a[j]; } else { break; } } a[j+1] = x; } } public: double trimMean(vector<int>& arr) { insertionSort(arr); int n = arr.size(); double sum = 0; int cnt = 0; for(int i = n/20; i < n - n/20; ++i) { sum += arr[i]; ++cnt; } return sum / cnt; } };
学生分数的最小差值
https://leetcode.cn/problems/minimum-difference-between-highest-and-lowest-of-k-scores/
给你一个 下标从 0 开始 的整数数组 nums ,其中 nums[i] 表示第 i 名学生的分数。另给你一个整数 k 。 从数组中选出任意 k 名学生的分数,使这 k 个分数间 最高分 和 最低分 的 差值 达到 最小化 。 返回可能的 最小差值 。 示例 1: 输入:nums = [90], k = 1 输出:0 解释:选出 1 名学生的分数,仅有 1 种方法: - [90] 最高分和最低分之间的差值是 90 - 90 = 0 可能的最小差值是 0 示例 2: 输入:nums = [9,4,1,7], k = 2 输出:2 解释:选出 2 名学生的分数,有 6 种方法: - [9,4,1,7] 最高分和最低分之间的差值是 9 - 4 = 5 - [9,4,1,7] 最高分和最低分之间的差值是 9 - 1 = 8 - [9,4,1,7] 最高分和最低分之间的差值是 9 - 7 = 2 - [9,4,1,7] 最高分和最低分之间的差值是 4 - 1 = 3 - [9,4,1,7] 最高分和最低分之间的差值是 7 - 4 = 3 - [9,4,1,7] 最高分和最低分之间的差值是 7 - 1 = 6 可能的最小差值是 2 提示: 1 <= k <= nums.length <= 1000 0 <= nums[i] <= 105
class Solution { void insertionSort(vector<int>& a) { // 从第2个元素开始,从后向前遍历 for(int i = 1; i <a.size(); ++i) { int x = a[i]; int j; for(j = i -1; j >= 0; --j) { if(x < a[j]) { a[j+1] = a[j]; } else { break; } } a[j+1] = x; } } public: int minimumDifference(vector<int>& nums, int k) { insertionSort(nums); int ret = 1000000000; // 保证 r - l + 1 = k for(int i = 0; i + k -1 < nums.size(); ++i) { int l = i; int r = i + k -1; ret = min(ret, nums[r] - nums[l]); } return ret; } };
计数排序
计数排序(概念篇)
计数排序(Counting Sort)是一种基于哈希的排序算法。它的基本思想是通过统计每个元素的出现次数,然后根据统计结果将元素依次放入排序后的序列中。这种排序算法适用于整数的排序并且元素范围较小的情况,例如整数范围在 0 到 k 之间。
算法思想
计数排序的核心是创建一个计数数组,用于记录每个元素出现的次数。然后,根据计数数组对原始数组进行排序。具体步骤如下:
- 第一步、初始化一个长度为最大元素值加 1 的计数数组,所有元素初始化为 0。
- 第二步、遍历原始数组,将每个元素的值作为索引,在计数数组中对应位置加 1。
- 第三步、将原数组清空。
- 第四步、遍历计数器数组,按照数组中元素个数放回到原数组中。
算法分析
1、时间复杂度
我们假设一次「 哈希 」和「 计数 」的时间复杂度均为O(1)。并且总共n个数,数字范围为1→k。
除了输入输出以外,「 计数排序 」中总共有四个循环。
- 第一个循环,用于初始化「 计数器数组 」,时间复杂度O(k);
- 第二个循环,枚举所有数字,执行「 哈希 」和「 计数 」操作,时间复杂度O(n);
- 第三个循环,枚举所有范围内的数字,时间复杂度O(k);
- 第四个循环,是嵌套在第三个循环内的,最多走O(n),虽然是嵌套,但是它可第三个循环是相加的关系,而并非相乘的关系。
所以,总的时间复杂度为:O(n+k)
2、空间复杂度
假设最大的数字为k,则空间复杂度为O(k)。
算法的优点
- 简单易懂:计数排序的原理非常简单,容易理解和实现。
- 时间复杂度低:对于范围较小的元素,计数排序的时间复杂度非常优秀。
- 适用于特定场景:当元素的范围已知且较小时,计数排序可以高效地完成排序。大于10^6次就比较吃力了。
算法的缺点
- 空间开销:计数排序需要额外的空间来存储计数数组,当元素范围较大时,可能会消耗较多的内存。
- 局限性:计数排序只适用于元素范围较小的情况,对于大规模数据或元素范围不确定的情况并不适用。
优化方案
「 计数排序 」在众多排序算法中效率最高,时间复杂度为O(n+k)。
但是,它的缺陷就是非常依赖它的数据范围。必须为整数,且限定在[1,k]范围内,所以由于内存限制,k就不能过大,优化点都是常数优化了,主要有两个:
- 初始化「 计数器数组 」可以采用系统函数(例如C/C++中的memset,纯内存操作,优于循环);
- 上文提到的第三个循环,当排序元素达到n个时,可以提前结束,跳出循环。
计数排序(实战篇)
颜色分类
https://leetcode.cn/problems/sort-colors/
给定一个包含红色、白色和蓝色、共 n 个元素的数组 nums ,原地 对它们进行排序,使得相同颜色的元素相邻,并按照红色、白色、蓝色顺序排列。 我们使用整数 0、 1 和 2 分别表示红色、白色和蓝色。 必须在不使用库内置的 sort 函数的情况下解决这个问题。 示例 1: 输入:nums = [2,0,2,1,1,0] 输出:[0,0,1,1,2,2] 示例 2: 输入:nums = [2,0,1] 输出:[0,1,2] 提示: n == nums.length 1 <= n <= 300 nums[i] 为 0、1 或 2
class Solution { void countingSort(vector<int>& a, int m) { // [0, 1, 2, ... m] int n = a.size(); int *count = new int[m+1]; memset(count, 0, sizeof(int) * (m + 1)); for(int i =0; i < n; ++i) { count[ a[i] ]++; } int idx = 0; for(int i = 0; i <= m; ++i) { while(count[i] > 0) { a[idx++] = i; count[i]--; } } // indx == n delete[] count; } public: void sortColors(vector<int>& nums) { countingSort(nums, 2); } };
最后一块石头的重量
https://leetcode.cn/problems/last-stone-weight/
class Solution { void countingSort(vector<int>& a, int m) { // [0, 1, 2, ... m] int n = a.size(); int *count = new int[m+1]; memset(count, 0, sizeof(int) * (m + 1)); for(int i =0; i < n; ++i) { count[ a[i] ]++; } int idx = 0; for(int i = 0; i <= m; ++i) { while(count[i] > 0) { a[idx++] = i; count[i]--; } } // indx == n delete[] count; } public: int lastStoneWeight(vector<int>& stones) { while( stones.size() > 1) { countingSort(stones, 1000); // 值域 1-1000 int n = stones.size(); int v = stones[n-1] - stones[n-2]; stones.pop_back(); stones.pop_back(); // 塞回去 if(v || stones.size() == 0) { stones.push_back(v); } } return stones[0]; } };
学生分数的最小差值
https://leetcode.cn/problems/minimum-difference-between-highest-and-lowest-of-k-scores/
class Solution { void countingSort(vector<int>& a, int m) { // [0, 1, 2, ... m] int n = a.size(); int *count = new int[m+1]; memset(count, 0, sizeof(int) * (m + 1)); for(int i =0; i < n; ++i) { count[ a[i] ]++; } int idx = 0; for(int i = 0; i <= m; ++i) { while(count[i] > 0) { a[idx++] = i; count[i]--; } } // indx == n delete[] count; } public: int minimumDifference(vector<int>& nums, int k) { countingSort(nums, 100000); int ret = 1000000000; // 保证 r - l + 1 = k for(int i = 0; i + k -1 < nums.size(); ++i) { int l = i; int r = i + k -1; ret = min(ret, nums[r] - nums[l]); } return ret; } };
归并排序
归并排序(概念篇)
归并是一种常见的算法思想,在许多领域都有广泛的应用。归并排序的主要目的是将两个已排序的序列合并成一个有序的序列。
算法思想
当然,对于一个非有序的序列,可以拆成两个非有序的序列,然后分别调用归并排序,然后对两个有序的序列再执行合并的过程。所以这里的“归”其实是递归,“并”就是合并。
整个算法的执行过程用mergeSort(a[], l, r) 描述,代表 当前待排序数组a,左区间下标l,右区间下标r,分以下几步:
- 第一步、计算中点mid=(l+r)/2;
- 第二步、递归调用mergeSort(a[], l, mid)和mergeSort(a[], mid+1, r);
- 第三步、第二步中两个有序数组进行有序合并,再存储到 a[l:r];
- 调用时,调用mergeSort(a[], 0, n-1)就能得到整个数组的排序结果了。
算法分析
1、时间复杂度
我们假设「比较」和「赋值」的时间复杂度为O(1)。
我们首先讨论「 归并排序 」算法的最重要的子程序:O(n)的合并,然后解析这个归并排序算法。
给定两个大小为n1和n2的排序数组A和B,我们可以在O(n)时间内将它们有效地归并成一个大小为n=n1+n2的组合排序数组。可以通过简单地比较两个数组的前面的元素,并始终取两个中较小的一个来实现的。
问题是这个归并过程被调用了多少次?
由于每次都是对半切,所以整个归并过程类似于一颗二叉树的构建过程,次数就是二叉树的高度,即log2n,所以归并排序的时间复杂度为O(nlog2n)。
2、空间复杂度
由于归并排序在归并过程中需要额外的一个「 辅助数组 」,并且最大长度为原数组长度,所以「 归并排序 」的空间复杂度为O(n)。
算法的优点
- 稳定性:归并算法是一种稳定的排序算法,这意味着在排序过程中,相同元素的相对顺序保持不变。
- 可扩展性:归并算法可以很容易地扩展到并行计算环境中,通过并行归并来提高排序效率。
算法的缺点
额外空间:归并算法需要使用额外的辅助空间来存储合并后的结果,这对于内存受限的情况可能是一个问题。
复杂性:归并算法的实现相对复杂,相比于其它一些简单的排序。
优化方案
「 归并排序 」在众多排序算法中效率较高,时间复杂度为O(nlog2n)。
但是,由于归并排序在归并过程中需要额外的一个「 辅助数组 」,所以申请「 辅助数组 」内存空间带来的时间消耗会比较大,比较好的做法是,实现用一个和给定元素个数一样大的数组,作为函数传参传进去,所有的「 辅助数组 」干的事情,都可以在这个传参进去的数组上进行操作,这样就免去了内存的频繁申请和释放。
归并排序(实战篇)
排序数组
https://leetcode.cn/problems/sort-an-array/
给你一个整数数组 nums,请你将该数组升序排列。 你必须在 不使用任何内置函数 的情况下解决问题,时间复杂度为 O(nlog(n)),并且空间复杂度尽可能小。 示例 1: 输入:nums = [5,2,3,1] 输出:[1,2,3,5] 解释:数组排序后,某些数字的位置没有改变(例如,2 和 3),而其他数字的位置发生了改变(例如,1 和 5)。 示例 2: 输入:nums = [5,1,1,2,0,0] 输出:[0,0,1,1,2,5] 解释:请注意,nums 的值不一定唯一。 提示: 1 <= nums.length <= 5 * 104 -5 * 104 <= nums[i] <= 5 * 104
class Solution { void merge(vector<int>& a, int l, int m, int r) { // l 到 m 元素个数 int n1 = m - l + 1; // m 到 r 元素个数 int n2 = r - m; int temp[n1 + n2]; // 合并左右部分 for(int i = 0; i < n1; ++i) { temp[i] = a[l+i]; } for(int i = 0; i < n2; ++i) { temp[n1+i] = a[m+1+i]; } int i = 0, j = n1, k = l; while(i < n1 && j < n1+n2) { if(temp[i] <= temp[j]) { a[k++] = temp[i++]; }else { a[k++] = temp[j++]; } } while(i < n1) { a[k++] = temp[i++]; } while(j < n1 + n2) { a[k++] = temp[j++]; } } void mergeSort(vector<int>& a, int l, int r) { if(l >= r) return; // 定义中点下标 int m = (l + r) /2; // 对左边、右边内容排序 mergeSort(a, l, m); mergeSort(a, m+1, r); // 合并 merge(a, l, m, r); } public: vector<int> sortArray(vector<int>& nums) { mergeSort(nums, 0, nums.size()-1); return nums; } };
排序链表
https://leetcode.cn/problems/sort-list/
给你链表的头结点 head ,请将其按 升序 排列并返回 排序后的链表 。 示例 1: 输入:head = [4,2,1,3] 输出:[1,2,3,4] 示例 2: 输入:head = [-1,5,3,4,0] 输出:[-1,0,3,4,5] 示例 3: 输入:head = [] 输出:[] 提示: 链表中节点的数目在范围 [0, 5 * 104] 内 -105 <= Node.val <= 105
/** * Definition for singly-linked list. * struct ListNode { * int val; * ListNode *next; * ListNode() : val(0), next(nullptr) {} * ListNode(int x) : val(x), next(nullptr) {} * ListNode(int x, ListNode *next) : val(x), next(next) {} * }; */ class Solution { ListNode* mergeSort(ListNode* a, ListNode* b) { a = sortList(a); b = sortList(b); ListNode* head = new ListNode(); // 虚拟头节点 ListNode* tail = head; // 游标节点 while(a || b) { if(a == NULL) { tail->next = b; break; } else if ( b == NULL) { tail->next = a; break; }else if (a->val < b->val) { tail->next = a; a = a->next; }else { tail->next = b; b = b->next; } tail = tail->next; tail->next = NULL; // 链尾的next 一定是空 } return head->next; } public: ListNode* sortList(ListNode* head) { // 如何把一个链表变成2个链表 if(head == NULL) { return NULL; }else if(head->next == NULL) { return head; } ListNode* fast = head; // 快节点 ListNode* slow = head; // 慢节点 ListNode* prev = NULL; // 前驱节点 while(fast){ prev = slow; slow = slow->next; fast = fast->next; if(fast) { fast = fast->next; } } // head-> ... ->prev -> slow -> ... -> ... -> fast prev->next = NULL; // prev的next设置为空,就可以拆成2条链表了 return mergeSort(head, slow); } };
快速排序
快速排序(概念篇)
快速排序(Quick Sort)是一种分而治之的排序算法。它通过选择一个基准元素,将数组分为两部分,一部分的元素都比基准小,另一部分的元素都比基准大,然后对这两部分再进行快速排序,最终得到有序的数组。
二、算法思想
- 第一步、选择基准元素:从数组中选择一个元素作为基准。
- 第二步、分割数组:将比基准小的元素放在基准的左边,比基准大的元素放在基准的右边。
- 第三步、递归排序:对基准左边和右边的子数组分别进行快速排序。
- 重复步骤 一 至 三,直到子数组的长度为 1 或 0。
三、算法分析
1、时间复杂度
- 最优情况:当每次选择的基准元素正好将数组分成两等分时,快速排序的时间复杂度是 O(nlogn)。
- 最坏情况:当每次选择的基准元素是最大或最小元素时,快速排序的时间复杂度是 O(n^2)。
- 平均情况:在平均情况下,快速排序的时间复杂度也是 O(nlogn)。所以在选的时候用随机的方式。
2、空间复杂度
快速排序的空间复杂度是 O(logn),因为在递归调用中需要使用栈来存储中间结果。这意味着在排序过程中,最多需要 O(logn) 的额外空间来保存递归调用的栈帧。
四、算法的优点
- 高效性:快速排序在大多数情况下具有较高的排序效率。
- 适应性:适用于各种数据类型的排序。
- 原地排序:不需要额外的存储空间。
五、算法的缺点
- 最坏情况性能:在最坏情况下,快速排序的时间复杂度可能退化为 O(n^2)。
- 不稳定性:快速排序可能会破坏排序的稳定性,即相同元素的相对顺序可能会改变。
六、优化方案
- 选择合适的基准:选择合适的基准元素可以提高算法的性能。
- 三数取中:通过选择中间元素作为基准,可以避免最坏情况的出现。
- 分区的改进:可以使用双指针或其他方法来改进分区的过程,提高算法的效率。
- 小数组使用插入排序:对于小数组,可以直接使用插入排序,避免不必要的递归。
快速排序(实战篇)
存在重复元素
https://leetcode.cn/problems/contains-duplicate/
给你一个整数数组 nums 。如果任一值在数组中出现 至少两次 ,返回 true ;如果数组中每个元素互不相同,返回 false 。 示例 1: 输入:nums = [1,2,3,1] 输出:true 解释: 元素 1 在下标 0 和 3 出现。 示例 2: 输入:nums = [1,2,3,4] 输出:false 解释: 所有元素都不同。 示例 3: 输入:nums = [1,1,1,3,3,4,3,2,4,2] 输出:true 提示: 1 <= nums.length <= 105 -109 <= nums[i] <= 109
class Solution { // l r // 4 5 2 3 6 1 7 // i j // x = 4 int Partition(vector<int>&a, int l, int r) { // 随机一个下标 int idx = l + rand() % (r - l + 1); // 交换。 两边的数不断向中间靠拢 swap(a[l], a[idx]); int i = l, j = r; int x = a[i]; while(i < j) { // 处理大于x的部分 while(i < j && a[j] > x) j--; if(i < j) { swap(a[i], a[j]), ++i; } // 处理小于x的部分 while(i < j && a[i] < x) i++; if(i < j) swap(a[i], a[j]), --j; } // i == j时 return i; } void QuickSort(vector<int>& a, int l, int r) { // 排a[l] 到a[r]之间的元素 if(l > r) return; // 计算一个锚点,使得左边的数小于它,右边的数大于它 int pivox = Partition(a, l, r); // 递归调用 QuickSort(a, l, pivox-1); QuickSort(a, pivox+1, r); } public: bool containsDuplicate(vector<int>& nums) { int n = nums.size(); QuickSort(nums, 0, n -1); for(int i = 1; i < n; ++i) { if(nums[i] == nums[i-1]) { return true; } } return false; } };
多数元素
https://leetcode.cn/problems/majority-element/
给定一个大小为 n 的数组 nums ,返回其中的多数元素。多数元素是指在数组中出现次数 大于 ⌊ n/2 ⌋ 的元素。 你可以假设数组是非空的,并且给定的数组总是存在多数元素。 示例 1: 输入:nums = [3,2,3] 输出:3 示例 2: 输入:nums = [2,2,1,1,1,2,2] 输出:2 提示: n == nums.length 1 <= n <= 5 * 104 -109 <= nums[i] <= 109 输入保证数组中一定有一个多数元素。
class Solution { // l r // 4 5 2 3 6 1 7 // i j // x = 4 int Partition(vector<int>&a, int l, int r) { // 随机一个下标 int idx = l + rand() % (r - l + 1); // 交换。 两边的数不断向中间靠拢 swap(a[l], a[idx]); int i = l, j = r; int x = a[i]; while(i < j) { // 处理大于x的部分 while(i < j && a[j] > x) j--; if(i < j) swap(a[i], a[j]), ++i; // 处理小于x的部分 while(i < j && a[i] < x) i++; if(i < j) swap(a[i], a[j]), --j; } // i == j时 return i; } void QuickSort(vector<int>& a, int l, int r) { // 排a[l] 到a[r]之间的元素 if(l > r) return; // 计算一个锚点,使得左边的数小于它,右边的数大于它 int pivox = Partition(a, l, r); // 递归调用 QuickSort(a, l, pivox-1); QuickSort(a, pivox+1, r); } public: int majorityElement(vector<int>& nums) { // 可以认为只要排好序,多数元素一定在列表的中间 // 因为nums数组元素是10^4,所以必须用nlogn的排序算法,这里用快速排序 int n = nums.size(); QuickSort(nums, 0, n-1); return nums[n/2]; } };
桶排序
桶排序(概念篇)
一、引言
桶排序(Bucket Sort)是一种基于计数的排序算法,工作原理是将数据分到有限数量的桶子里,然后每个桶再分别排序(有可能再使用别的排序算法或是以递回方式继续使用桶排序进行排序)。
二、算法思想
- 第一步、设置固定数量的空桶。
- 第二步、把数据放到对应的桶中。
- 第三步、对每个不为空的桶中数据进行排序。
- 第四步、拼接不为空的桶中数据,得到结果。
三、算法分析
1、时间复杂度
桶排序属于一种组合排序,因为分入桶中的元素,可以采用任意一种排序,所以时间复杂度还是取决于每个桶中的元素,采用什么排序。
2、空间复杂度
由于由于采用了额外的桶空间,并且每个元素都需要放入桶中,最多存储的个数就是元素个数,所以空间复杂度为 O(n)。
四、算法的优点
适用于一定范围内的整数或浮点数排序,不需要比较元素之间的大小,因此排序速度较快。
桶排序是一种稳定的排序算法。
五、算法的缺点
当数据范围较大时,需要的桶数量较多,会消耗较多的内存空间。
桶排序是一种线性排序,不适合大规模数据排序。
六、优化方案
- 选择合适的桶大小:根据数据的分布情况,选择合适的桶大小,尽量减少桶的数量。
- 使用其他排序算法:对每个桶中的数据,可以使用其他排序算法进行排序,例如插入排序、快速排序等。
- 合并桶中的数据:在桶排序的最后一步,可以使用归并排序或堆排序等算法,对桶中的数据进行合并,以提高排序的效率。
桶排序(实战篇)
根据字符出现频率排序
https://leetcode.cn/problems/sort-characters-by-frequency
给定一个字符串 s ,根据字符出现的 频率 对其进行 降序排序 。一个字符出现的 频率 是它出现在字符串中的次数。 返回 已排序的字符串 。如果有多个答案,返回其中任何一个。 示例 1: 输入: s = "tree" 输出: "eert" 解释: 'e'出现两次,'r'和't'都只出现一次。 因此'e'必须出现在'r'和't'之前。此外,"eetr"也是一个有效的答案。 示例 2: 输入: s = "cccaaa" 输出: "cccaaa" 解释: 'c'和'a'都出现三次。此外,"aaaccc"也是有效的答案。 注意"cacaca"是不正确的,因为相同的字母必须放在一起。 示例 3: 输入: s = "Aabb" 输出: "bbAa" 解释: 此外,"bbaA"也是一个有效的答案,但"Aabb"是不正确的。 注意'A'和'a'被认为是两种不同的字符。 提示: 1 <= s.length <= 5 * 105 s 由大小写英文字母和数字组成
class Solution { #define ArrayType char vector<vector<ArrayType>> bucket; vector<int> count; void bucketSort(ArrayType* a, int n, int max) { // a 待排序列表、n表示a数组长度、max表示a中每个元素的最大值 255 bucket.clear(); // 清空 count.resize(max); // count数组置为0。这样所有字符出现次数初始化为0 for(int i = 0; i < max; ++i) { count[i] = 0; } // 遍历 a 数组,并对count计数 for(int i = 0; i < n ; ++i) { count[ a[i] ]++; } // 计数可能是 n 次,所以最多新建 n 个桶。0次是不用的。每个桶是一个列表 for(int i = 0; i <= n; ++i) { bucket.push_back( {} ); } // 遍历每一个字符,对于第 i 个字符次数映射到桶中,把字符存下来 for(int i = 0; i < max; ++i) { int cnt = count[i]; bucket[cnt].push_back(i); } // 桶排序。遍历所有桶执行排序 for(int i = 0; i <= n; ++i) { sort(bucket[i].begin(), bucket[i].end()); } } public: string frequencySort(string s) { // 字符范围0-255,可以把它映射到数组中再进行计数,之后对计数的数字 // 映射到桶中,然后对桶中元素逆序输出 int n = s.size(); string ret = ""; // s 取到字符数组并转换成char* bucketSort((char *)s.c_str(), n, 256); // 得到一个 0 到 n 的桶 // 降序排列 for(int i = n; i > 0; --i) { // 遍历每个桶 for(int j = 0; j < bucket[i].size(); ++j) { for(int k = 0; k < i; ++k) { ret += bucket[i][j]; } } } return ret; } };
基数排序
基数排序(概念篇)
一、引言
基数排序(Radix Sort)是一种非比较型排序算法,它根据数字的每一位来进行排序。通常用于整数排序,基数排序的基本思想是通过对所有元素进行若干次“分配”和“收集”操作来实现排序。”基“就是进制转换中的进制。
二、算法思想
基数排序的算法思想可以概括为以下步骤:
- 第一步、获取待排序元素的最大值,并确定其位数。
- 第二步、从最低位(个位)开始,依次对所有元素进行“分配”和“收集”操作。
- 第三步、在每一位上,根据该位上数字的值将元素分配到相应的桶中。
- 第四步、对每个桶中的元素进行顺序收集,得到排序后的部分结果。可以认为每个桶是一个队列
- 重复上述步骤,直到对所有位都进行了排序。
三、算法分析
1、时间复杂度
它的时间复杂度为 O(d(n+r)), 其中 d 是数字的位数,n 是待排序元素的数量,r 是基数(radix)。
基数排序的时间复杂度主要取决于数字的位数和待排序元素的数量。对于位数较少的情况,基数排序的效率较高,因为它不需要进行元素间的比较。然而,当数字的位数较多时,可能需要较多的“分配”和“收集”操作,导致时间复杂度增加。
2、空间复杂度
在空间复杂度方面,基数排序需要额外的存储空间来存储桶。特殊的桶排序。具体的空间复杂度取决于使用的桶的数量和存储桶的方式。
四、算法的优点
- 基数排序不需要进行元素间的比较,因此对于一些特殊情况(如排序范围有限、元素具有特定的顺序等),它可能比比较型排序算法更有效。
- 基数排序可以很容易地用于排序具有固定宽度的数字序列,如电话号码、身份证号码等。
五、算法的缺点
- 基数排序需要额外的空间来存储桶,对于大型数据集可能会消耗较多的内存。
- 对于复杂的数据类型或非整数类型,可能需要进行额外的处理来实现基数排序。
六、优化方案
- 对于数字位数较多的情况,可以考虑使用其他排序算法,如快速排序、归并排序等。
- 在实际应用中,可以根据数据的特点和排序要求,选择合适的排序算法组合,以达到更好的排序效果。
基数排序(实战篇)
排序数组
https://leetcode.cn/problems/sort-an-array/
给你一个整数数组 nums,请你将该数组升序排列。 你必须在 不使用任何内置函数 的情况下解决问题,时间复杂度为 O(nlog(n)),并且空间复杂度尽可能小。 示例 1: 输入:nums = [5,2,3,1] 输出:[1,2,3,5] 解释:数组排序后,某些数字的位置没有改变(例如,2 和 3),而其他数字的位置发生了改变(例如,1 和 5)。 示例 2: 输入:nums = [5,1,1,2,0,0] 输出:[0,0,1,1,2,5] 解释:请注意,nums 的值不一定唯一。 提示: 1 <= nums.length <= 5 * 104 -5 * 104 <= nums[i] <= 5 * 104
先用C语言实现出来
/** * Note: The returned array must be malloced, assume caller calls free(). */ const int MAXN = 50005; // 多少元素5*10^4 const int MAXT = 7; // 最多的位数 const int BASE = 10; // 基数排序的基数。这里10进制 void RadixSort(int* a, int n) { // 首地址是 a, n 个元素 int PowOfBase[MAXT]; // 10的i次 PowOfBase[0] = 1; // 任何数的0次都是1 for(int i = 1; i < MAXT; ++i) { PowOfBase[i] = PowOfBase[i-1] * BASE; } int RadixBucket[BASE][MAXN]; // 每个桶最多有MAXN个元素 int RadixBucketTop[BASE]; // 每个桶的元素个数 // 负数情况 for(int i = 0; i < n; ++i) { a[i] += PowOfBase[MAXT-1]; } // 计数排序 int pos = 0; while (pos < MAXT) { // 初始化,每个桶里都没有元素 memset(RadixBucketTop, 0, sizeof(RadixBucketTop)); // 先排个位,放进对应桶中 for(int i = 0; i < n; ++i) { int rdx = a[i] / PowOfBase[pos] % BASE; RadixBucket[rdx][ RadixBucketTop[rdx]++ ] = a[i]; } int top = 0; for(int i = 0; i < BASE; ++i) { // 枚举桶中每个元素 for(int j = 0; j < RadixBucketTop[i]; ++j) { a[top++] = RadixBucket[i][j]; } } // 按十位排 pos++; } // 加完再减回来 for(int i = 0; i < n; ++i) { a[i] -= PowOfBase[MAXT-1]; } } int* sortArray(int* nums, int numsSize, int* returnSize) { RadixSort(nums, numsSize); *returnSize = numsSize; // 给外部调用的 return nums; }
C++实现
class Solution { const int MAXN = 50005; // 多少元素5*10^4 const int MAXT = 7; // 最多的位数 const int BASE = 10; // 基数排序的基数。这里10进制 void RadixSort(vector<int>& a) { int n = a.size(); // 首地址是 a, n 个元素 int PowOfBase[MAXT]; // 10的i次 PowOfBase[0] = 1; // 任何数的0次都是1 for(int i = 1; i < MAXT; ++i) { PowOfBase[i] = PowOfBase[i-1] * BASE; } int RadixBucket[BASE][MAXN]; // 每个桶最多有MAXN个元素 int RadixBucketTop[BASE]; // 每个桶的元素个数 // 负数情况 for(int i = 0; i < n; ++i) { a[i] += PowOfBase[MAXT-1]; } // 计数排序 int pos = 0; while (pos < MAXT) { // 初始化,每个桶里都没有元素 memset(RadixBucketTop, 0, sizeof(RadixBucketTop)); // 先排个位,放进对应桶中 for(int i = 0; i < n; ++i) { int rdx = a[i] / PowOfBase[pos] % BASE; RadixBucket[rdx][ RadixBucketTop[rdx]++ ] = a[i]; } int top = 0; for(int i = 0; i < BASE; ++i) { // 枚举桶中每个元素 for(int j = 0; j < RadixBucketTop[i]; ++j) { a[top++] = RadixBucket[i][j]; } } // 按十位排 pos++; } // 加完再减回来 for(int i = 0; i < n; ++i) { a[i] -= PowOfBase[MAXT-1]; } } public: vector<int> sortArray(vector<int>& nums) { RadixSort(nums); return nums; } };
堆排序
堆排序(概念篇)
问题描述
给定一个无序数组,将它原地进行递增排序
算法描述
1、先把数组利用 "下沉" 操作构建成一个大顶堆
2、把数组第0个元素(也就是大顶堆中最大的元素)和数组最后一个元素交换,并且把堆的大小减一,然后执行 "下沉" 操作
3、把数组第0个元素(也就是大顶堆中最大的元素)和数组倒数第二个元素交换,并且把堆的大小减一,然后执行 "下沉" 操作
4、反复执行,最后堆没了,数组的元素,从后往前,从大到小,逐个有序。
细节剖析
整个过程实际上是这样的:
- 找到数组[0, n-1] 的最大值,和第 n-1 的位置上的数交换
- 找到数组[0, n-2] 的最大值,和第 n-2 的位置上的数交换
- 找到数组[0, i] 的最大值,和第 i 的位置上的数交换
- 最终,从 n-1 到 0 的数,从大到小有序。
哈希算法
贪心算法
前缀和
双指针
课后习题
1、模板题集
2、课内题集
3、课后题集
3.1-数组追赶
3.2-数组逼近
3.3-快慢指针
滑动窗口
二分查找
课后习题(入门)
1、模板题集
2、课内题集
3、课后题集
括号内的整数代表完整代码行数。
3.1-模板题
3.2-实数的二分
3.3-线性枚举 + 二分
3.4-线性枚举 + 二分 + 前缀和
课后习题(进阶)
1、模板题集
2、课内题集
3、课后题集
括号内的整数代表完整代码行数。
3.1-公式判定
3.2-统计判定
最短路(Dijkstra)
课后习题
1、模板题集
2、课内题集
3、课后题集
- 一个人的旅行
- HDU Today
- Shortest Path
- Shortest Path Problem
- Idiomatic Phrases Game
- Here We Go(relians) Again
- find the safest road
- Saving James Bond
- A strange lift
- Bus Pass
- zz’s Mysterious Present
- Another Brick in the Wall
- 湫湫系列故事——过年回家
- Entropy
- Eddy’s picture
- Pearls
- Galactic Import
- Bus System
- The diameter of graph
- Free DIY Tour(路径还原)
- Minimum Transport Cost(路径还原)
- A Walk Through the Forest(路径数)
- Choose the best route(预处理)
- find the mincost route(枚举删边)
- find the longest of the shortest(枚举删边)
- Cycling(二分枚举)
最小生成树(Prim)
深度优先搜索
广度优先搜索
课后习题
1、模板题集
2、课内题集
3、课后题集
最短路(Bellman-Ford)
课后习题
1、模板题集
2、课内题集
3、课后题集
最短路(Floyd)
最短路(Dijkstra + Heap)
最短路(SPFA)
线性DP
拓扑排序
记忆化搜索
0/1背包
0/1背包(空间优化)
课后习题
1、模板题集
2、课内题集
3、课后题集
完全背包
完全背包(时间优化)
完全背包(空间优化)
课后习题
1、模板题集
2、课内题集
3、课后题集