Linux: PostgreSQL
- TAGS: Linux
本章内容
- PostgreSQL 介绍
- PostgreSQL 安装
- PostgreSQL 管理
- PostgreSQL 体系架构
- PostgreSQL 备份还原
- PostgreSQL 高可用
PostgreSQL 介绍和特性
PostgreSQL 介绍
PostgreSQL是当前功能最强大的开源的关系型数据库系统,支持跨平台的多种操作系统,基于C语言开发。通常简称为PG或PGSQL。
PostgreSQL宣称是世界上最先进的开源数据库。PostgreSQL的狂热者认为它的性能缺Oracle不分上下,而且没有高成本的负担。
PostgreSQL拥有看悠久的历史,可以追搠到1985年的加州大学伯克利分校的项目 POSTGRES,是1977年的由数据库科学家Michael Stonebraker领导的Ingres项目 的衍生品,为了专注于数据库理论的研究,在版本4.2时伯克利正式终止了 POSTGRES项目。
1994年,来自中国香港的两名伯克利的研究生Andrew Yu和 JollyChen向 POSTGRES中增加了现在SQL语言的解释器,将Postgres改名为Postgres95,并将其源代码发布到互联网上,成为一个开源的数据库管理系统。
1996年,Postgres95名称已经不合时宜,被更改为PostgreSQL,表示它支持查询语言标准,同时版本号也重新从6.0开始。自从版本6.0之后,出现了很多后续发行版本。
PostgreSQL是100%社区驱动的开源项自,由全球范围内千人以上的社区责献者共同维护。PostgreSQL提供了一个完整功能的瓶本,而不像MySQL那样提供多个不同的瓶本,如社区版、商业版及企业版。
PostgreSQL的开源协议采用自由的BSD,MTT类型,这种开源协议允许任何人在保留版权声明的情况下使用,戛制,修改或者分享代码。
可靠性是PostgreSQL最优先关注的特性。普遍认为PostgreSQL坚如磐石并且设计 精密,能够支持事务处理和关键任务应用。PostgreSQL提供一流的文档服务,包 括全面的免费在线手册,以及旧版本手册的存档。社区的支持非常出色,并且有独 立厂商提供商业支持。
数据一致性和完整性也是PostgeSQL的高度优先事项。PostgreSQL是完全符合 ACID原则(原子性、一致性、隔离性,持久性)的数据库:PostgreSQL对数据库访 问提供强大的安全控制,不仅能够利用企业安全工具,如: Kerberos和OpenSSL等, 还可以根据自己的业务规则自定义核对方法,以确保数据的质量。数据库管理员 最喜欢的功能是时间点恢复(point-in-time recovery简称PITR)期能,它具有灵 活性,高可用性特征,能够打造快速故障的热备份服务器,以及快照和恢复到特 定时间点等。但这还不是全部.该项目提供了很多方法来管理PostgreSQL,使 PostgreSQL具有高可用性、负载均衡和同步功能,因此可以利用这些功能来满足 特定需求
中文社区: http://www.postgres.cn
中文手册: http://www.postgres.cn/docs/12/index.html
参考网站:
- https://www.runoob.com/postgresql/postgresql-tutorial.html
- https://www.runoob.com/manual/PostgreSQL/index.html
PostgreSQL 开源许可( PostgreSQL Licence)
完全免费,二次开发无需担心会产生小课堂。
MySQL 开源许可(GPLv2 with exceptions and LGPLv2 and BSD)
MySQL's soure code is available under terms of the GNU General Public License, which also fits the Free Software and OpenSource definitions and conforms to the Debian Free Software Guidelines (but not to the Copyfree Standard). lt is also available under a proprietary license agreement, which is typically intended for use by those who wish to release software incorporatin:MySQL code without having to release the source code for the entire application. In practical terms, this means that MySQL can be distributed with or without source code, as can PostgreSQL, but to distribute without source code in the case of MySQL requires paying Oracle for a MySQL Commercial License.
数据库排名
PostgreSQL与MySQL对比
http://bbs.chinaunix.net/thread-1688208-1-1.html
| 特性 | MySQL | PostgreSQL |
|---|---|---|
| 实例 | 通过执行 MySQL 命令(mysqld)启动实例。一个实例可以管理一个或多个数据库。一台服务器可以运行多个 mysqld 实例。一个实例管理器可以监视 mysqld 的各个实 例。 | 通过执行 Postmaster 进程(pg_ctl)启动实例。一个实例可以管理一个或多个数据库,这些数据库组成一个集群。集群是磁盘上的一个区 域,这个区域在安装时初始化并由一个目录组成,所有数据都存储在这个目录中。使用 initdb创建第一个数据库。一台机器上可以启动多个实例。 |
| 数据库 | 数据库是命名的对象集合,是与实例中的其他数据库分离的实体。一个 MySQL 实例中的所有数据库共享同一个系统编目。 | 数据库是命名的对象集合,每个数据库是与其他数据库分离的实体。每个数据库有自己的系统编目,但是所有数据库共享 pg_databases。 |
| 数据缓冲区 | 通过 innodb_buffer_pool_size 配置参数设置数据缓冲区。这个参数是内存缓冲区的字节数,InnoDB 使用这个缓冲区来缓存表的数据和索引。在专用的数据库服务器上,这个参数最高可以设置为机器物理内存量的 80%。 | Shared_buffers 缓存。在默认情况下分配 64个缓冲区。默认的块大小是 8K。可以通过设置 postgresql.conf 文件中的 shared_buffers 参数来更新缓冲区缓存。 |
| 数据库连接 | 客户机使用 CONNECT 或 USE 语句连接数据库,这时要指定数据库名,还可以指定用户 id 和密码。使用角色管理数据库中的用户和用户组。 | 客户机使用 connect 语句连接数据库,这时要指定数据库名,还可以指定用户 id 和密码。使用角色管理数据库中的用户和用户组。 |
| 身份验证 | MySQL 在数据库级管理身份验证。基本只支持密码认证。 | PostgreSQL 支持丰富的认证方法:信任认证、口令认证、Kerberos 认证、基于 Ident 的认 证、LDAP 认证、PAM 认证 |
| 加密 | 可以在表级指定密码来对数据进行加密。还可以使用 AES_ENCRYPT和 AES_DECRYPT 函数对列数据进行加密和解密。可以通过 SSL 连接实现网络加密。 | 可以使用 pgcrypto 库中的函数对列进行加密/解密。可以通过 SSL 连接实现网络加密。 |
| 审计 | 可以对 querylog 执行 grep。 | 可以在表上使用 PL/pgSQL 触发器来进行审计。 |
| 查询解释 | 使用 EXPLAIN 命令查看查询的解释计划。 | 使用 EXPLAIN 命令查看查询的解释计划。 |
| 备 份、恢复和日志 | InnoDB 使用写前(write-ahead)日志记录。支持在线和离线完全备份以及崩溃和事务恢复。需要第三方软件才能支持热备份。 | 在数据目录的一个子目录中维护写前日志。支持在线和离线完全备份以及崩溃、时间点和事务恢复。 可以支持热备份。 |
| JDBC驱动程序 | 可以从 参考资料 下载 JDBC 驱动程序。 | 可以从 参考资料 下载 JDBC 驱动程序。 |
| 表类型 | 取决于存储引擎。例如,NDB 存储引擎支持分区表,内存引擎支持内存表。 | 支持临时表、常规表以及范围和列表类型的分区表。不支持哈希分区表。 由于PostgreSQL的表分区是通过表继承和规则系统完成了,所以可以实现更复杂的分区方式。 |
| 索引类型 | 取决于存储引擎。MyISAM: BTREE,InnoDB:BTREE。 | 支持 B-树、哈希、R-树和 Gist 索引。 |
| 约束 | 支持主键、外键、惟一和非空约 束。对检查约束进行解析,但是不强制实施。 | 支持主键、外键、惟一、非空和检查约束。 |
| 存储过程和用户定义函数 | 支持 CREATE PROCEDURE 和 CREATE FUNCTION 语句。存储过程可以用 SQL 和 C++ 编写。用户定义函数可以用 SQL、C 和 C++ 编写。 | 没有单独的存储过程,都是通过函数实现的。用户定义函数可以用 PL/pgSQL(专用的过程语言)、PL/Tcl、PL/Perl、PL/Python 、SQL 和 C 编写 |
| 触发器 | 支持行前触发器、行后触发器和语句触发器,触发器语句用过程语言复合语句编写。 | 支持行前触发器、行后触发器和语句触发器,触发器过程用 C 编写。 |
| 系统配置文件 | my.conf | Postgresql.conf |
| 数据库配置 | my.conf | Postgresql.conf |
| 客户机连接文件 | my.conf | pg_hba.conf |
| XML 支持 | 有限的 XML 支持。 | 有限的 XML 支持。 |
| 数据访问和管理服务器 | OPTIMIZE TABLE -–— 回收未使用的空间并消除数据文件的碎片 myisamchk -analyze -–— 更新查询优化器所使用的统计数据 . (MyISAM 存储引擎) mysql -–— 命令行工具 MySQL Administrator -–— 客户机 GUI工具 | Vacuum -–— 回收未使用的空间 Analyze -–—更新查询优化器所使用的统计数据 psql -–— 命令行工具 pgAdmin -–— 客户机 GUI 工具 |
| 并发控制 | 支持表级和行级锁。InnoDB 存储引擎支持 READ_COMMITTED、 READ_UNCOMMITTED、 REPEATABLE_READ 和 SERIALIZABLE。使用 SET TRANSACTION ISOLATION LEVEL语句在事务级设置隔离级别。 | 支持表级和行级锁。支持的 ANSI 隔离级别是 Read Committed(默认 -–— 能看到查询启动时数据库的快照)和 Serialization(与 Repeatable Read 相似 -–— 只能看到在事务启动之前提交的结果)。使用 SET TRANSACTION语句在事务级设置隔离级别。使用 SET SESSION在会话级进行设置。 |
MySQL相对于PostgreSQL的劣势
| MySQL | PostgreSQL |
|---|---|
| 最重要的引擎InnoDB很早就由Oracle公司控制。目前整个MySQL数据库都由Oracle控 制。 | BSD协议,没有被大公司垄断。 |
| 对复杂查询的处理较弱,查询优化器不够成熟 | 很强大的查询优化器,支持很复杂的查询处理。 |
| 只有一种表连接类型:嵌套循环连接(nested- loop),不支持排序-合并连接(sort-merge join)与散列连接(hash join)。 | 都支持 |
| 性能优化工具与度量信息不足 | 提供了一些性能视图,可以方便的看到发生在一个表和索引上的select、delete、update、 insert统计信息,也可以看到cache命中率。网上有一个开源的pgstatspack工具。 |
| InnoDB的表和索引都是按相同的方式存储。也就是说表都是索引组织表。这一般要求主键不能太长而且插入时的主键最好是按顺序递 增,否则对性能有很大影响。 | 不存在这个问题。 |
| 大部分查询只能使用表上的单一索引;在某些情况下,会存在使用多个索引的查询,但是查询优化器通常会低估其成本,它们常常比表扫描还要慢。 | 不存在这个问题 |
| 表增加列,基本上是重建表和索引,会花很长时间。 | 表增加列,只是在数据字典中增加表定义,不会重建表 |
| 存储过程与触发器的功能有限。可用来编写存储过程、触发器、计划事件以及存储函数的语言功能较弱 | 除支持pl/pgsql写存储过程,还支持perl、 python、Tcl类型的存储过程:pl/perl, pl/python,pl/tcl。 也支持用C语言写存储过程。 |
| 不支持Sequence。 | 支持 |
| 不支持函数索引,只能在创建基于具体列的索引。 不支持物化视图。 | 支持函数索引,同时还支持部分数据索引,通过规则系统可以实现物化视图的功能。 |
| 执行计划并不是全局共享的, 仅仅在连接内部是共享的。 | 执行计划共享 |
| MySQL支持的SQL语法(ANSI SQL标准)的很小一部分。不支持递归查询、通用表表达式 (Oracle的with 语句)或者窗口函数(分析函数)。 | 都 支持 |
| 不支持用户自定义类型或域(domain) | 支持 |
| 对于时间、日期、间隔等时间类型没有秒以下级别的存储类型 | 可以精确到秒以下。 |
| 身份验证功能是完全内置的,不支持操作系统认证、PAM认证,不支持LDAP以及其它类似的外部身份验证功能。 | 支持OS认证、 Kerberos 认证 、 Ident 的认证、 LDAP 认证、PAM认证 |
| 不支持database link。有一种叫做Federated的存储引擎可以作为一个中转将查询语句传递到远程服务器的一个表上,不过,它功能很粗糙并且漏洞很多 | 有dblink,同时还有一个dbi-link的东西,可以连接到 oracle和mysql上。 |
| Mysql Cluster可能与你的想象有较大差异。开源的cluster软件较少。 复制(Replication)功能是异步的,并且有很大的局限性.例如,它是单线程的 (single-threaded),因此一个处理能力更强的Slave的恢复速度也很难跟上处理能力相对较慢的Master. | 有丰富的开源 cluster软件支持。 |
| explain看执行计划的结果简单。 | explain返回丰富的信息。 |
| 类似于ALTER TABLE或CREATE TABLE一类的操作都是非事务性的.它们会提交未提交的事务,并且不能回滚也不能做灾难恢复 | DDL也是有事务的。 |
PostgreSQL主要优势:
1. PostgreSQL完全免费,而且是BSD协议,如果你把PostgreSQL改一改,然后再 拿去卖钱,也没有人管你,这一点很重要,这表明了PostgreSQL数据库不会 被其它公司控制。oracle数据库不用说了,是商业数据库,不开放。而MySQL 数据库虽然是开源的,但现在随着SUN被oracle公司收购,现在基本上被 oracle公司控制,其实在SUN被收购之前,MySQL中最重要的InnoDB引擎也是 被oracle公司控制的,而在MySQL中很多重要的数据都是放在InnoDB引擎中的, 反正我们公司都是这样的。所以如果MySQL的市场范围与oracle数据库的市场 范围冲突时,oracle公司必定会牺牲MySQL,这是毫无疑问的。 2. 与PostgreSQl配合的开源软件很多,有很多分布式集群软件,如pgpool、 pgcluster、slony、plploxy等等,很容易做读写分离、负载均衡、数据水平 拆分等方案,而这在MySQL下则比较困难。 3. PostgreSQL源代码写的很清晰,易读性比MySQL强太多了,怀疑MySQL的源代 码被混淆过。所以很多公司都是基本PostgreSQL做二次开发的。 4. PostgreSQL在很多方面都比MySQL强,如复杂SQL的执行、存储过程、触发器、 索引。同时PostgreSQL是多进程的,而MySQL是线程的,虽然并发不高时, MySQL处理速度快,但当并发高的时候,对于现在多核的单台机器上,MySQL 的总体处理性能不如PostgreSQL,原因是MySQL的线程无法充分利用CPU的能 力。
新闻评价
https://www.theregister.com/2021/12/06/mysql_a_pretty_poor_database/
With the caveat that his reasons for leaving were complex, he went on to say: "MySQL is a pretty poor database, and you should strongly consider using Postgres instead.
https://blog.csdn.net/dqcfkyqdxym3f8rb0/article/details/121804125
各种数据库性能比较
| 数据库 | 硬件 | TPS |
|---|---|---|
| Oracle | DELL R910 CPU : Intel(R) Xeon(R) CPU E7530 @ 1.87GHz 四路48线程 MEM : 32* 4G 128G 存储 : FusionIO 640G MLC | 稳定值2000,峰值2600 |
| MySQL Percona 5.1.60-13.1 修改版 | DELL R910 CPU : Intel(R) Xeon(R) CPU E7530 @ 1.87GHz 四路 48线程 MEM : 32* 4G 128G 存储 : FusionIO 640G MLC | 峰值 1200*4,谷值0, 均值950*4 |
| PostgreSQL 9.3.1 | IBM x3850 X5 CPU : Intel(R) Xeon(R) CPU X7560 @ 2.27GHz 四路32线程 内存 : 8 * 8GB 64G 存储:OCZ RevoDrive3X2 480GB | 稳定值 24487 |
| PostgreSQL 9.3.1 | DELL R610 CPU : Intel(R) Xeon(R) CPU E5504 @ 2.00GHz 2路 8线程 (电源功率不够降频到1.6GHZ) 内存 : 12 * 8GB 96G 存储:OCZ RevoDrive3 240GB | 稳定值 15151 |
PostgreSQL各版本的特性矩阵
PostgreSQL的优势
- PostgreSQL数据库是目前功能最强大的开源数据库,它是最接近工业标准SQL92的查询语言,并且正在实现新的功能以兼容最新的SQL标准SQL2003。
- 稳定可靠: PostgreSQL是唯一能做到数据零丢失的开源数据库。有报道称国外的部分银行也在使用PostgreSQL数据库。
- 开源免费: PostgreSQL数据库是开源的、免费的,而且是BSD协议,在使用和二次开发上基本没有限制。
- 支持广泛:PostgreSQL数据库支持大量的主流开发语言,包括C、C++、Perl、Python、Java、Tcl,PHP等。
- PostgreSQL社区活跃:PostgreSQL基本上每三个月推出一个补丁版本,这意味着已知的BUG很快会被修复,有应用场景的需求也会及时得到响应。
PostgreSQL 安装
安装方法分为两种:
二进制安装包进行安装
各个Linux的发行版本中,很多都内置了PostgreSQL的二进制安装包,但内置 的版本可能较旧。对于二进制包安装的方法是通过不同发行版本的Linux下的 包管理器进行的,如在RHEL系统相关版本下用yum 命令,在Debian或Ubuntu下 使用 apt 命令
源码编译安装
使用源码编译安装相对更灵活,用户可以有更多的选择,可以选择较新的版本、 配置不同的编译选项,编译出用户需要的功能。
二进制包安装
PostgreSQL 支持各种操作系统,并提供相关二进制包包的安装方法
RHEL/CentOS/Rocky安装 PostgreSQL
范例: Rocky9 利用官方源安装 PostgreSQL-17
sudo dnf install -y https://download.postgresql.org/pub/repos/yum/reporpms/EL-9-x86_64/pgdg-redhat-repo-latest.noarch.rpm #禁用内置的postgresql sudo dnf -qy module disable postgresql sudo dnf install -y postgresql17-server #初始化数据库 sudo /usr/pgsql-17/bin/postgresql-17-setup initdb #启动服务 systemctl enable --now postgresql-17 #验证成功 [root@rocky9 ~]#sudo -u postgres psql -c "SELECT version();" PostgreSQL 17.0 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 11.4.1 20231218 (Red Hat 11.4.1-3), 64-bit [root@rocky9 ~]#su - postgres [postgres@rocky9~]$ psql psql (17.1) Type "help" for help. postgres=# help \copyright for distribution terms \h for help with SQL commands \? for help with psql commands \g or terminate with semicolon to execute query \q to quit
范例: Rocky8 利用系统源安装 PostgreSQL-10
[root@rocky8 ~]#yum -y install postgresql-server #默认无法启动 [root@rocky8 ~]#systemctl start postgresql.service #查看日志提示做初始化 [root@rocky8 ~]#tail /var/log/messages Dec 23 12:01:41 rocky8 [root@rocky8 ~]#ls /var/lib/pgsql/data #初始化数据库 [root@rocky8 ~]#/usr/bin/postgresql-setup --initdb [root@rocky8 ~]#ls /var/lib/pgsql/data [root@rocky8 ~]#systemctl enable --now postgresql.service [root@rocky8 ~]#su - postgres [postgres@rocky8 ~]$ psql psql (10.17) postgres=#
Ubuntu 安装 PostgreSQL
范例: Ubuntu利用官方源安装 PostgreSQL-17
#导入存储库签名密钥 sudo apt install curl ca-certificates sudo install -d /usr/share/postgresql-common/pgdg sudo curl -o /usr/share/postgresql-common/pgdg/apt.postgresql.org.asc --fail https://www.postgresql.org/media/keys/ACCC4CF8.asc #创建存储库配置文件 sudo sh -c 'echo "deb [signed-by=/usr/share/postgresql-common/pgdg/apt.postgresql.org.asc] https://apt.postgresql.org/pub/repos/apt $(lsb_release -cs)-pgdg main" > /etc/apt/sources.list.d/pgdg.list' #更新存储并安装最新版本, 可以指定版本,如postgresql-16代替postgresql sudo apt update sudo apt -y install postgresql #验证版本, 5432端口 root@debian:~/.jasper# sudo -u postgres psql -c "SELECT version();" version --------------------------------------------------------------------------------------------------------------------- PostgreSQL 17.0 (Debian 17.0-1.pgdg120+1) on x86_64-pc-linux-gnu, compiled by gcc (Debian 12.2.0-14) 12.2.0, 64-bit (1 row) root@debian:~/.jasper# su - postgres postgres@debian:~$ psql psql (17.0 (Debian 17.0-1.pgdg120+1)) Type "help" for help. postgres=# #安装12版本时,ubuntu需要初始化才能启动 #初始化并启动 #方法1 [root@ubuntu2004 ~]#pg_createcluster 12 main --start #方法2 [root@ubuntu2004 ~]#su - postgres #数据库初始化 postgres@ubuntu2004:~$/usr/lib/postgresql/12/bin/initdb -D /var/lib/postgresql/data #启动服务 postgres@ubuntu2004:~$ /usr/lib/postgresql/12/bin/pg_ctl -D /var/lib/postgresql/data -l logfile start #修改配置 postgres@ubuntu2004:~$ vim /var/lib/postgresql/data/postgresql.conf listen_addresses = '*' postgres@ubuntu2004:~$ vim /var/lib/postgresql/data/pg_hba.conf # IPv4 local connections: host all all 127.0.0.1/32 trust host all all 0.0.0.0/0 md5 #重启服务 postgres@ubuntu2004:~$ /usr/lib/postgresql/12/bin/pg_ctl -D /var/lib/postgresql/data -l logfile restart postgres@ubuntu2004:~$ psql #修改密码 postgres=# ALTER USER postgres WITH ENCRYPTED PASSWORD '123456'; ALTER ROLE #远程登录 [root@rocky8 ~]#psql -U postgres -h 10.0.0.200 Type "help" for help.
范例: Ubuntu20.04利用系统源安装 PostgreSQL-12
[root@ubuntu2004 ~]#apt update
[root@ubuntu2004 ~]#apt -y install postgresql
[root@ubuntu2004 ~]#su -postgres
postgres@ubuntu2004:~$ /usr/lib/postgresql/12/bin/pg_ctl init -D /var/lib/postgresql/12/main
Success. You can now start the database server using:
/usr/lib/postgresql/12/bin/pg_ctl -D /var/lib/postgresql/12/main -l logfile start
postgres@ubuntu2004:~$ /usr/lib/postgresql/12/bin/pg_ctl -D /var/lib/postgresql/12/main -l logfile start
postgres@ubuntu2004:~$ psql
postgres=# exit
范例: Ubuntu18.04 利用系统源安装 PostgreSQL-10
[root@ubuntu1804 ~]#apt update
[root@ubuntu1804 ~]#apt -y install postgresql
[root@ubuntu1804 ~]#su - postgres
postgres@ubuntu1804:~$ psql
postgres=# help
源码编译安装
编译安装过程说明
官方帮助
第一步:下载源代码 https://www.postgresql.org/ftp/source/
第二步:编译安装。过程与Linux下其他软件的编译安装过程相同
./configure make make install
第三步:编译安装完成后执行如下步骤
- 使用initdb命令初使用化数据库
- 启动数据库实例
系统初始化和优化配置
#关闭防火墙和SELinux等 #内核参数优化 # vi /etc/sysctl.conf kernel.shmmax = 68719476736 (CentOS6以前版本默认值,CentOS7默认为18446744073692774399) kernel.shmall = 4294967296 (CentOS6以前版本默认值,CentOS7默认为18446744073692774399) kernel.shmmni = 4096 kernel.sem = 50100 64128000 50100 1280 fs.file-max = 7672460 net.ipv4.ip_local_port_range = 9000 65000 net.core.rmem_default = 1048576 net.core.rmem_max = 4194304 net.core.wmem_default = 262144 net.core.wmem_max = 1048576 # sysctl -p # vi /etc/security/limits.conf * - nofile 100000 * - nproc 100000 * - memlock 60000
安装依赖包
#RHEL系统 yum install -y gcc make readline-devel zlib-devel #Ubuntu apt update apt install -y gcc make libreadline-dev zlib1g-dev apt install -y libicu-dev pkg-config bison flex apt install -y build-essential zlib1g-dev libssl-dev libreadline-dev libpam0g-dev libdb-dev
源码编译安装
#下载解压缩 wget https://ftp.postgresql.org/pub/source/v12.9/postgresql-12.9.tar.gz tar xf postgresql-12.9.tar.gz cd postgresql-12.9 wget https://ftp.postgresql.org/pub/source/v17.0/postgresql-17.0.tar.gz tar xf postgresql-17.0.tar.gz cd postgresql-17.0 #查看安装说明 cat postgresql-12.9/INSTALL ./configure make su make install adduser postgres mkdir /usr/local/pgsql/data chown postgres /usr/local/pgsql/data su - postgres /usr/local/pgsql/bin/initdb -D /usr/local/pgsql/data /usr/local/pgsql/bin/pg_ctl -D /usr/local/pgsql/data -l logfile start /usr/local/pgsql/bin/createdb test /usr/local/pgsql/bin/psql test #查看编译选项(可选) pg_config --configure #开始编译三步曲,默认安装在/usr/local/pgsql mkdir buid_dir cd buid_dir ../configure --prefix=/apps/pgsql --with-pgport=5432 make -j 2 world #默认 make 不包括文档和其它模块,2表示当产主机的CPU核心数 make install-world #默认 make install 不包括安装文档
创建数据库用户和组
PostgreSQL默认不支持 以root身份启动服务,虽然也可修改源码实现root启动,但基于安全考虑不建议,因此必须创建一个用于启动PostgrepSQL的普通用户
root@debian:~/postgresql-17.0/buid_dir# useradd test root@debian:~/postgresql-17.0/buid_dir# getent passwd test test:x:1001:1001::/home/test:/bin/sh #创建数据库用户和组,注意此用户需要可以交互登录 useradd -s /bin/bash -m -d /home/postgres postgres #修改postgres密码 echo -e '123456\n123456' | passwd postgres echo postgres:123456|chpasswd
创建数据目录并授权
mkdir -pv /pgsql/data/ chown postgres.postgres /pgsql/data/
设置环境变量
vim /etc/profile.d/pgsql.sh export PGHOME=/apps/pgsql export PATH=$PGHOME/bin/:$PATH export PGDATA=/pgsql/data export PGUSER=postgres export MANPATH=/apps/pgsql/share/man:$MANPATH su - postgres #验证 psql --version
初始化数据库
su - postgres #初始化 initdb initdb -D $PGDATA #如果没有指定选项 -D <datadir> ,按环境变量$PGDATA指定的路径进行初始化 #生产建议初始化方式 initdb -A md5 -D $PGDATA -E utf8 --locale=C -U postgres -W #选项 -A #指定local connections默认的身份验证方法 -D #指定数据目录 -E #指定字符集 --locale=C #指定语言环境 -U #指定数据库superuser用户名 -W #指定数据库superuser的用户密码
启动和关闭服务
#启动 pg_ctl -D /pgsql/data -l logfile start postgres -D /pgsql/data & #停止数据库的命令如下: pg_ctl stop -D $PGDATA [-m SHUTDOWN-MODE] 其中-m是指定数据库的停止方法,有以下三种: smart: 等所有的连接中止后,关闭数据库。如果客户端连接不终止,则无法关闭数据库。 fast: 快速关闭数据库,断开客户端的连接,让已有的事务回滚,然后正常关闭数据库。相当于Oracle数据库关闭时的immediate模式。此为默认值,建议使用 immediate: 立即关闭数据库,相当于数据库进程立即停止,直接退出,下次启动数据库需要进行恢复。相当于Oracle数据库关闭时的 abort模式 #smart关闭 pg_ctl stop -D /pgsql/data/ -ms #fast关闭,推荐使用,也是默认模式 pg_ctl stop -D /pgsql/data/ -mf #immediate 相当于kill -9 pg_ctl stop -D /pgsql/data/ -mi #或者发送信号,直接向数据库主进程发送的signal 信号有以下三种。 SIGTERM: 发送此信号为Smart Shutdown关机模式。 SIGINT: 发送此信号为Fast Shutdown关机模式。 SIGQUIT: 发送此信号为Immediate Shutdown关机模式。 #重启 pg_ctl restart -mf #源码目录中内置PostgreSQL的启动脚本 postgresql-12.9/contrib/start-scripts/linux
范例:Ubuntu 启动脚本实现开机自动PostgreSQL
[root@ubuntu2004 ~]#cat /etc/rc.local #!/bin/bash su - postgres -c "/apps/pgsql/bin/pg_ctl -l logfile start" #/etc/init.d/postgresql start
范例: CentOS创建PosgreSQL启动脚本
[root@rocky8 ~]#cp postgresql-12.9/contrib/start-scripts/linux /etc/init.d/postgresql [root@rocky8 ~]#chmod +x /etc/init.d/postgresql [root@rocky8 ~]#chkconfig --add postgresql [root@rocky8 ~]#vim /etc/init.d/postgresql #修改下面两行 prefix=/apps/pgsql PGDATA="/pgsql/data" [root@rocky8 ~]#service postgresql start
范例: 创建 service 文件
#创建新的service文件 [root@ubuntu2004 ~]#cat > /lib/systemd/system/postgresql.service <<EOF [Unit] Description=PostgreSQL database server After=network.target [Service] User=postgres Group=postgres ExecStart=/apps/pgsql/bin/postgres -D /pgsql/data ExecReload=/bin/kill -HUP [Install] WantedBy=multi-user.target EOF [root@ubuntu2004 ~]#systemctl daemon-reload #确认文件内容, 并开机启动 systemctl cat postgresql.service systemctl enable --now postgresql
查看编译和相关信息
[postgres@postgresql ~]$pg_config BINDIR = /apps/pgsql/bin DOCDIR = /apps/pgsql/share/doc HTMLDIR = /apps/pgsql/share/doc INCLUDEDIR = /apps/pgsql/include PKGINCLUDEDIR = /apps/pgsql/include INCLUDEDIR-SERVER = /apps/pgsql/include/server LIBDIR = /apps/pgsql/lib PKGLIBDIR = /apps/pgsql/lib LOCALEDIR = /apps/pgsql/share/locale MANDIR = /apps/pgsql/share/man SHAREDIR = /apps/pgsql/share SYSCONFDIR = /apps/pgsql/etc PGXS = /apps/pgsql/lib/pgxs/src/makefiles/pgxs.mk CONFIGURE = '--prefix=/apps/pgsql' CC = gcc CPPFLAGS = -D_GNU_SOURCE CFLAGS = -Wall -Wmissing-prototypes -Wpointer-arith -Wdeclaration-after- statement -Werror=vla -Wendif-labels -Wmissing-format-attribute -Wformat- security -fno-strict-aliasing -fwrapv -fexcess-precision=standard -Wno-format- truncation -Wno-stringop-truncation -O2 CFLAGS_SL = -fPIC LDFLAGS = -Wl,--as-needed -Wl,-rpath,'/apps/pgsql/lib',--enable-new-dtags LDFLAGS_EX = LDFLAGS_SL = LIBS = -lpgcommon -lpgport -lpthread -lz -lreadline -lrt -lcrypt -ldl -lm VERSION = PostgreSQL 12.9
pg_ctl 命令管理PostgreSQL
pg_ctl 是一个实用的命令行工具,有以下常见功能:
- 初始化 PostgreSQL 数据库实例
- 启动、终止或重启 PostgreSQL 数据库服务。
- 查看 PostgreSQL数据库服务的状态
- 让数据库实例重新读取配置文件。允许给一个指定的PostgreSQL进程发送信号
- 控制 standby 服务器为可读写
- 在Windows平台下允许为数据库实例注册或取消一个系统服务
pc_ctl 命令格式
postgres@debian:~$ pg_ctl --help
pg_ctl is a utility to initialize, start, stop, or control a PostgreSQL server.
Usage:
pg_ctl init[db] [-D DATADIR] [-s] [-o OPTIONS]
pg_ctl start [-D DATADIR] [-l FILENAME] [-W] [-t SECS] [-s]
[-o OPTIONS] [-p PATH] [-c]
pg_ctl stop [-D DATADIR] [-m SHUTDOWN-MODE] [-W] [-t SECS] [-s]
pg_ctl restart [-D DATADIR] [-m SHUTDOWN-MODE] [-W] [-t SECS] [-s]
[-o OPTIONS] [-c]
pg_ctl reload [-D DATADIR] [-s]
pg_ctl status [-D DATADIR]
pg_ctl promote [-D DATADIR] [-W] [-t SECS] [-s]
pg_ctl logrotate [-D DATADIR] [-s]
pg_ctl kill SIGNALNAME PID
Common options:
-D, --pgdata=DATADIR location of the database storage area
-s, --silent only print errors, no informational messages
-t, --timeout=SECS seconds to wait when using -w option
-V, --version output version information, then exit
-w, --wait wait until operation completes (default)
-W, --no-wait do not wait until operation completes
-?, --help show this help, then exit
If the -D option is omitted, the environment variable PGDATA is used.
Options for start or restart:
-c, --core-files allow postgres to produce core files
-l, --log=FILENAME write (or append) server log to FILENAME
-o, --options=OPTIONS command line options to pass to postgres
(PostgreSQL server executable) or initdb
-p PATH-TO-POSTGRES normally not necessary
Options for stop or restart:
-m, --mode=MODE MODE can be "smart", "fast", or "immediate"
Shutdown modes are:
smart quit after all clients have disconnected
fast quit directly, with proper shutdown (default)
immediate quit without complete shutdown; will lead to recovery on restart
Allowed signal names for kill:
ABRT HUP INT KILL QUIT TERM USR1 USR2
Report bugs to <[email protected]>.
PostgreSQL home page: <https://www.postgresql.org/>
范例:别名
cat <<\EOF>> ~/.bash_profile alias ll='ls -alF' alias gprestart='pg_ctl -D /pgsql/data restart' alias gprestatus='pg_ctl -D /pgsql/data status' alias gpstart='pg_ctl -D /pgsql/data start' alias gpstop='pg_ctl -D /pgsql/data stop' EOF
初始化实例
初始化PostgreSQL数据库实例的命令如下:
#先切换用户 su - postgres #初始化数据库 initdb [DATADIR] pg_ctl init[db] [-s] [-D DATADIR] [-o options] #pg_ctl命令调用initdb命令创建了一个新的PostgreSQL数据库实例,参数说明如下。 -s #只打印错误和警告信息,不打印提示性信息。 -D DATADIR #指定数据库实例的数据目录。如果没有指定DATADIR,使用环境变量PGDATA指定的路径 -o options #为直接传递给initdb命令的参数
范例: 创建新的数据库实例数据
chown postgres: /pgsql/
su - postgres
postgres@debian:~$ pg_ctl init -D /pgsql/data2
Success. You can now start the database server using:
/apps/pgsql/bin/pg_ctl -D /pgsql/data2 -l logfile start
postgres@debian:~$ ls /pgsql/data2
#修改端口,启动实例
postgres@debian:~$ grep 5432 /pgsql/data2/postgresql.conf
#port = 5432 # (change requires restart)
postgres@debian:~$ echo port = 5433 >> /pgsql/data2/postgresql.conf
postgres@debian:~$ /apps/pgsql/bin/pg_ctl -D /pgsql/data2 -l logfile start
pg_ctl -D /pgsql/data2 stop
服务管理
查看服务状态
查询数据库实例状态的命令如下:
pg_ctl status [-D datadir]
范例:
postgres@ubuntu2004:~$ pg_ctl status -D /pgsql/data2 pg_ctl: server is running (PID: 23320) /apps/pgsql/bin/postgres "-D" "/pgsql/data2"
启动服务
启动PostgreSQL服务的命令:
pg_ctl start [-w] [-t seconds] [-s] [-D datadir] [-l filename] [-o options] [-p path] [-c] #参数说明如下。 start #启动数据库实例 -w #等待启动完成 -t #等待启动完成的等待秒数,默认为60秒 -s #只打印错误和警告信息,不打印提示性信息 -D datadir #指定数据库实例的数据目录 -l #服务器日志输出附加在“filename”文件上,如果该文件不存在则创建它 -o options #声明要直接传递给postgres 的选项,具体可见postgres命令的帮助 -p path #指定postgres可执行文件的位置。默认情况下postgres可执行文件来自和pg_ctl相同的目录, #不必使用该选项。除非要进行一些不同寻常的操作,或者产生了postgres执行文件找不到的错误 -c #提高服务器的软限制(ulimit -c),尝试允许数据库实例在有异常时产生一个coredump文件,以便于问题定位和故障分析
范例:
postgres@ubuntu2004:~$ pg_ctl start -D /pgsql/data2 postgres@ubuntu2004:~$ pg_ctl status -D /pgsql/data2 pg_ctl: server is running (PID: 23027) /apps/pgsql/bin/postgres "-D" "/pgsql/data2"
停止服务
停止PostgreSQL 数据库的命令如下:
pg_ctl stop [-w] [-t seconds] [-s] [-D datadir] [-m s[mart] l f[ast] | i [mmediate] ] #参数说明如下。 -W #不等待数据库停下来,命令就返回。 -m #指定停止的模式。前面已叙述过停止的几种模式了。 #其它未说明的参数,其含义与启动数据库命令中的参数相同。
范例:
postgres@ubuntu2004:~$ pg_ctl stop -D /pgsql/data2 server stopped postgres@ubuntu2004:~$ pg_ctl status -D /pgsql/data2 pg_ctl: no server running
重启服务
重启PostgreSQL 数据库的命令如下:
pg_ctl restart [-w] [-t seconds][-s] [-D datadir] [-c] [-m s[mart] | f[ast] | i[mmediate] ] [-o "options ] #此命令中的参数与启动或停止命令中的参数含义相同
加载配置
在配置文件中改变参数后,需要使用上面这条命令使参数生效
#修改配置文件 postgresql.conf后,让修改生效的方法有两种 #方法一:在操作系统使用下面命令 pg_ctl reload [-s] [-D datadir] #方法二:在 psql 中使用如下命令 postgres=# select pg_reload_conf(); #注意:加载配置操作只针对一些配置的修改生效,有些配置需要重新启动服务才能生效
范例:
postgres@ubuntu2004:~$ pg_ctl reload -D /pgsql/data2 #注意:修改端口不支持reload,只能restart postgres@ubuntu2004:~$ vim /pgsql/data2/postgresql.conf listen_addresses = '*' postgres@ubuntu2004:~$ pg_ctl reload -D /pgsql/data2 postgres@ubuntu2004:~$ pg_ctl restart -D /pgsql/data2 postgres@ubuntu2004:~$ ss -ntl|grep 5432
promote 模式
在流复制架构中,在standby主机执行promote提升操作,恢复正常的读写操作
pg_ctl promote [-D DATADIR] [-W] [-t SECS] [-s]
备用服务器在指定数据目录中运行提升模式命令,结束备用模式并开始读写操作
PostgreSQL 管理
配置文件介绍
PostgreSQL使用环境变量PGDATA指向的目录做为数据存放的目录。这个目录是在 安装时指定的,所以在安装时需要指定一个合适的目录作为数据目录的根目录, 而且,每一个PG数据库实例都需要有这样的一个目录。此数据目录的初始化是使 用命令initdb来完成的。
初始化完成后,PGDATA数据目录下就会生成三个配置文件。
postgresql.conf #数据库实例的主配置文件,基本上所有的配置参数都在此文件中。 pg_hba.conf #认证配置文件,配置了允许哪些IP的主机访问数据库,认证的方法是什么等信息。 pg_ident.conf #认证方式ident的用户映射文件。
数据库相关概念
数据库的结构组织
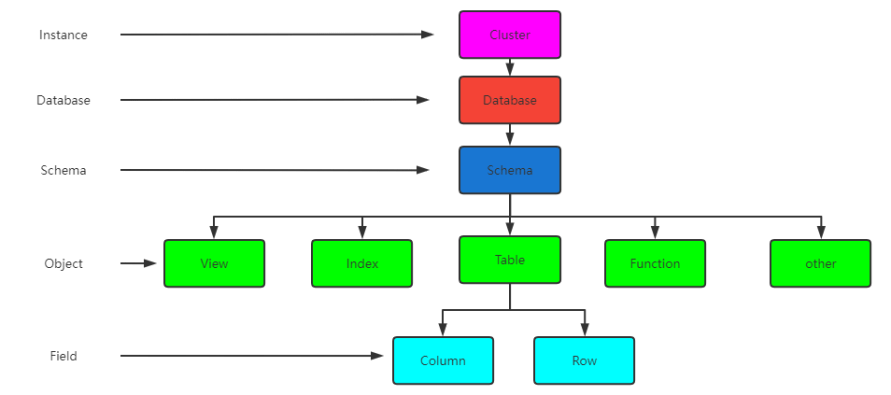
在一个PostgreSQL 数据库系统中,数据的组织结构可以分为以下五层:
- 实例: 一个PostgreSQL对应一个安装的数据目录$PGDATA,即一个instance实例
数据库:一个PostgreSQL数据库服务下可以管理多个数据库,当应用连接到一个数据库时,一般只能访问这个数据库中的数据,而不能访问其他数据库中的内容
默认情况下初始实例只有三个数据库: postgres、template0、template1
- 模式: 一个数据库可以创建多个不同的名称空间即Schema,用于分隔不同的业务数据
- 表和索引:一个数据库可以有多个表和索引。在PostgreSQL中表的术语称为Relation,而在其他数据库中通常叫Table
- 行和列:每张表中有很多列和行数据。在PostgreSQL 中行的术语一般为“Tuple”,而在其他数据库中则叫“Row”。
PostgreSQL中的术语
PostgreSQL有一些术语与其他数据库中不一样,了解了这些术语的意思,就能更好地看懂PostgreSQL中的文档。
与其他数据库不同的术语如下。
- Relation:表示表table或索引index,具体表示的是Table还是Index需要看具体情况
- Tuple:表示表中的行,在其他数据库中使用Row来表示
- Segment:每个表和索引都单独对应一个文件,,即为segment,如果文件大小超过1GB,会创建多个相同名称但后缀不同的文件
- Page:表示在磁盘中的数据块。在文件中以块为单位存放数据, 默认值为8KB,最大可以为32KB
- Buffer:表示在内存中的数据块。
范例: 编译时可以指定segment大小
[root@ubuntu2004 postgresql-12.9]#./configure --help |grep segment
--with-segsize=SEGSIZE set table segment size in GB [1]
模版数据库template0 和template1
template1和template0是PostgreSQL的模板数据库。所谓模板数据库就是创建新database时,PostgreSQL会基于模板数据库制作一份副本,其中会包含所有的数据库设置和数据文件。
PostgreSQL安装好以后会默认附带两个模板数据库: 默认模板库为template1和template1。
默认模板库为 template1,也可以指定template0
比如:create database db1 template template0
不要对template0模板数据库进行任何修改,因为这是原始的干净模板如果其它模板数据库被搞坏了,基于这个数据库做一个副本就可以了。
如果希望定制自己的模板数据库,那么请基于template1进行修改,或者自己另外创建一个模板数据库再修改。
template1和template0的区别主要有两点:
- template1 可以连接,template0 不可以连接。
- 使用 template1 模板库建库时不可指定新的encoding 和locale,而template0可以。
注意:template0和template1都不能被删除。
模式 schema
模式schema是数据库中的一个概念,可以将其理解为一个命名空间。不同的模式 下可以有相同名称的表、函数等对象且互相不冲突。提出模式的概念是为了便于 管理,只要有权限,每个模式(schema)的对象可以互相调用。
在 PostgreSQL中,一个数据库包含一个或多个模式,一个模式中又包含了表、函数及操作符等数据库对象。
在PostgreSQL中,不能同时访问不同数据库中的对象,当要访问另一个数据库中 的表或其他对象时,需要重新连接到这个新的数据库,而模式没有此限制。一个 用户在连接到一个数据库后,就可以同时访问这个数据库中多个模式的对象。
通常情况下,创建和访问表的时候都不用指定模式,实际上这时访问的都是 public模式。每当我们创建一个新的数据库时,PostgreSQL都会自动创建一个名 为public的模式。当登录到该数据库时,如果没有特殊的指定,都是以该模式 public操作各种数据对象的。
我们需要使用模式有以下几个主要原因:
- 允许多个用户在使用同一个数据库时彼此互不干扰。
- 把数据库对象放在不同的模式下,然后组织成逻辑组,让它们更便于管理。
- 第三方的应用可以放在不同的模式中,这样就不会和其他对象的名字冲突了。
#创建模式 create schema schema_name; #删除模式 drop schema schema_name; #查看模式 \dn
要访问指定模式中的对象,需要先指定一个包含模式名及表名的名字,模式和表之间用一个“点”分开,如下:
schema_name.table_name
psql 工具介绍和基本用法
psql是PostgreSQL中的一个命令行交互式客户端工具,类似MySQL的mysql和 Oracle中的命令行工具sqlplus,它允许你交互地输入SQL或命令,然后把它们发 出给PostgreSQL服务器,再显示SQL或命令的结果。而且,输入的内容还可以来 自于一个文件。此外,它还提供了一些命令和多种类似shell的特性来实现书写 脚本,从而实现对大量任务的自动化工作。
虽然也可以使用PostgreSQL中图形化的客户端工具(如pgadmin)来实现上述功能。 但如果掌握了psql的使用方法,将会体会到它的方便之处。因为psql是一个字符 界面的工具,没有图形化工具使用上的一些限制。psql与 pgAdminIII之间的关 系类似于vi与某些图形化工具的关系。
psql 的历史命令与补全的功能
- 可以使用上下键把以前使用过的命令或SQL语句调出来
- 连续按两个tab键表示把命令补全或给出提示输入
psql 命令格式
psql -h <hostname or ip> -p<端口> [数据库名称] -U [用户名称] -h #指定要连接的数据库主机名或IP地址,默认local socket登录(由配置项unix_socket_directories指定) -p #指定连接的数据库端口 #最后两个参数是数据库名和用户名 #这些连接参数也可以用环境变量指定,比如: export PGDATABASE=testdb export PGHOST=10.0.0.200 export PGPORT=5432 export PGUSER=postgres #然后运行psql即可,其效果与运行psql -h 10.0.0.200 -p 5432 testdb postgres相同。 #可通过下面命令查看详细帮助:man /apps/pgsql/share/man/man1/psql.1
范例:psql 本地登录PGSQL
#方法1 [root@rocky8 ~]#psql -d postgres -U postgres #方法2 [root@rocky8 ~]#su - postgres [postgres@rocky8 ~]$psql
范例:远程登录
#注意:默认PostgreSQL不支持远程登录,需要修改配置和授权才可以 #如果不指定hellodb数据库,默认连接和用户名同名的数据库 [root@rocky8 ~]#psql -h 10.0.0.200 -p 5432 hellodb postgres Password for user postgres: psql (12.9) Type "help" for help. hellodb=#
范例:psql 命令中直接执行 SQL
[root@rocky8 ~]#psql -U postgres -h 10.0.0.200 -p 5432 -d postgres -c "select current_time"
Password for user postgres: current_time
04:43:48.508999+00
(1 row)
范例:psql 命令中执行文件中的 SQL
[root@rocky8 ~]#cat test.sql select current_time \du #方法1 [root@rocky8 ~]#psql -U postgres -h 10.0.0.200 -p 5432 -d postgres -f test.sql #方法2 \i <文件名> #执行存储在外部文件中的sql语句或命令 [postgres@rocky8 ~]$psql postgres=# \i hellodb.sql
postgres=# create database db1; CREATE DATABASE postgres=# \c db1 You are now connected to database "db1" as user "postgres". db1=# create table t1(id int); CREATE TABLE db1=# \dt public | t1 | table | postgres postgres@debian:~$ cat test.sql \c db1 create table t2(id int); select * from t2; postgres@debian:~$ psql -f test.sql You are now connected to database "db1" as user "postgres". CREATE TABLE id ---- (0 rows)
范例:psql客户端命令
\c #显示当前连接的数据库 \c 库名 #连接数据库 \dn #显示schema \l #显示数据库 \du #显示权限
连接管理
访问控制配置文件介绍
在PostgreSQL中,带有一个网络防火墙的功能的文件pg_hba.conf,可以控制允许设置哪些IP的机器访问数据库服务器。
HBA的意思是host-based authentication,也就是基于主机的认证,即实现PostgreSQL 防火墙功能
initdb初始化数据目录时,会生成一个默认的pg_hba.conf文件。
pg_hba.conf文件的格式由很多记录组成,每条记录占一行。
以#开头的行为注释及空白行会被忽略。
一条记录由若干个空格或由制表符分隔的字段组成,如果字段用引号包围,那么它可以包含空白。
每条记录声明一种连接类型、一个客户端IP地址范围(如果和连接类型相关)、一个数据库名、一个用户名字,以及对匹配这些参数的连接所使用的认证方法。
第一条匹配连接类型、客户端地址、连接请求的数据库名和用户名的记录将用于 执行认证。如果选择了一条记录而且认证失败,那么将不再考虑后面的记录;如 果没有匹配的记录,访问将被拒绝。即从上向下匹配,一旦匹配则不会再向下检查
每条记录可以是下面七种格式之一:
1) local <dbname> <user> <auth-method>[auth-options] 2) host <dbname> <user> <ip/masklen> <auth-method>auth-options] 3) hostssl <dbname><user> <ip/masklen> <auth-method>[auth-options] 4) hostnossl <dbname> <user> <ip/masklen> <auth-method>[auth-options] 5) host <dbname> <user> <ip><mask> <auth-method> [auth-options] 6) hostssl <dbname> <user> <ip> <mask> <auth-method>[ auth-options] 7) hostnossl <dbname><user><ip><mask> <auth-method>[auth-options]
pg_hba.conf文件为pg实例的防火墙配置文件。配置文件格式分为5部分:
TYPE DATABASE USER ADDRESS METHOD
- 第1个字段只能是下面的取值.
- local: 这条记录匹配通过UNIX域套接字的连接认证。没有这种类型的记录, 就不允许有UNIX域套接字的连接。当psql后面不指定主机名或IP地址时,即 用UNIX域套接字的方式连接数据库。
- host:这条记录匹配通过TCP/IP进行的连接。包括了SSL和非SS的连接。
- hostssl:这条记录匹配使用TCP/IP的SSL连接。必须是使用SSL加密的连接,且要使用这个选项,编译服务器时必须打开SSL支持,启动服务器时必须打开SSL配置选项。
- hostnossl: 这条记录与hostssI相反,它只匹配那些在TCP/IP上不使用SSL 的连接请求。
- 第2个字段用于设置一个数据库名称,如果设置为all,表示可以匹配任何数据 库,注意:如果设置为replication时比较特殊,表示允许流复制连接,而不是允 许连接到一个名为“replication”的数据库上。
- 第3个字段用于设置一个用户的名称,如果设置为all,表示可以匹配任何用户。
- 第4个字段<ip/masklen>表示允许哪些IP地址来访问此服务器,如 192.168.1.10/32表示只允许192.168.1.10这台主机访问数据 库,192.168.1.0/24表示IP地址前缀为192.168.1.X的主机都允许访问数据库服 务器。
- 第5个字段表示验证方法,PostgreSQL支持的认证配置方式很多,最常用的认证方法是trust、reject、md5和 ident方法。
#METHOD有如下值可选 md5:执行SCRAM-SHA-256或MD5身份验证加密密码来验证,是推荐使用的安全验证的方法 peer:从操作系统获取客户端的操作系统用户名,并检查它是否与请求的数据库用户名匹配。这仅适用于本地socket连接。 trust:允许无条件连接,允许任何PostgreSQL用户身份登录,而无需密码或任何其他身份验证。 reject:拒绝任何条件连接,这对于从组中“过滤掉”某些主机非常有用。 scram-sha-256:执行SCRAM-SHA-256身份验证以验证用户的密码。 password:要提供未加密的密码以进行身份验证。由于密码是通过网络以明文形式发送的,因此不建议使用 gss:使用GSSAPI对用户进行身份验证,这仅适用于TCP / IP连接。 sspi:使用SSPI对用户进行身份验证,这仅适用于Windows。 ident:允许客户端上的特定操作系统用户连接到数据库。这种认证方式的使用 场景是,客户端是主机上的某个操作系统用户,已经通过了操作系统的身份认证, 是数据库服务器可以信任的用户,不需要在数据库层面再次检测身份。比如,如 果配置了这种认证方式(配置中允许的用户名为dba)、这时在操作系统用户dba下, 就能以数据库用户dba的身份连接到数据库。服务器为了确定接收到的连接请求 确实是客户端机器上的dba用户发起的,而不是这台机器上其他用户发起的假冒 请求,会向客户端机器上的ident服务发起请求,让ident服务查看此TCP连接是 否是dba用户发起的,如果不是,说明是假冒,则认证失败。如果客户端通过本 地连接到服务器,因为客户端与服务器在一台机器上,数据库服务器可以直接检 查客户端用户的操作系统用户身份,就不需要向ident服务发送请求进行判断了。 ldap:使用LDAP服务器进行身份验证。 radius:使用RADIUS服务器进行身份验证。 cert:使用SSL客户端证书进行身份验证。 pam:使用操作系统提供的可插入身份验证模块(PAM)服务进行身份验证。 bsd:使用操作系统提供的BSD身份验证服务进行身份验证。
范例:
#如果一台机器只给数据库使用,而没有其他用途,则可以在pg_hba.conf中加上下面一行配置: local all all trust #该配置表示在这台机器上,任何操作系统的用户都可以使用任何数据库用户(包括数据库超级用户) #连接到数据库而不需要任何密码。因为这台主机只供数据库使用,可以把不用的操作系统用户都禁止掉,以保证安全性。 #如果数据库中有一个用户“dba”,操作系统中也有一个用户“dba” #在操作系统"dba”用户下连接数据库不需要密码验证的设置方法: local all dba ident #如果想在数据库主机上使用密码验证,可以使用下面的配置项: local all all md5 #如果想让其他主机的连接都使用md5密码验证,则使用如下配置: host all all 0.0.0.0/0 md5 #允许用户通过10.0.0.0/24的远程主机进行md5验证登录 #TYPE DATABASE USER ADDRESS METHOD host all all 10.0.0.0/24 md5 #允许用户wang通过任意远程主机进行md5验证登录test数据库 #TYPE DATABASE USER ADDRESS METHOD host test wang 0.0.0.0/0 md5
打开远程连接
默认安装完的PG只监听1ocal。如果要远程连接,需要监听对外提供服务的IP地址。
范例: 实现远程连接
#修改用户postgres密码 [root@rocky8 ~]#psql postgres=# ALTER USER postgres with password '123456'; ALTER ROLE #查看监听地址和端口,默认为127.0.0.1:5432 [root@rocky8 ~]#ss -ntl [root@rocky8 ~]#vim /pgsql/data/postgresql.conf listen_addresses = '*' #修改此行中的localhost为 * #listen_addresses = '0.0.0.0' #或者修改为0.0.0.0 [root@rocky8 ~]#vim /pgsql/data/pg_hba.conf host all all ::1/128 trust #上面行的后面加一行 host all all 0.0.0.0/0 md5 #重启服务生效 [postgres@rocky8 ~]$pg_ctl restart -mf #查看监听地址和端口 [root@rocky8 ~]#ss -ntl #psql Usage: psql [OPTION]... [DBNAME [USERNAME]] #测试远程登录 [root@rocky8 ~]#psql -d postgres -h PostgreSQL主机IP -p 5432 -U postgres $ psql -h 10.0.0.131 db1 postgres Password for user postgres: psql (17.0) Type "help" for help. db1=#
范例: 利用.pgpass文件实现免密码连接远程posgresql
[root@rocky8 ~]#vim .pgpass #hostname:port:database:username:password 10.0.0.200:5432:testdb:postgres:123456 [root@rocky8 ~]#chmod 600 .pgpass [root@rocky8 ~]#ll .pgpass -rw------- 1 root root 81 Dec 30 10:04 .pgpass #psql默认连接本机,需要指定和.pgpass文件内容相匹配信息才可以使用.pgpass文件连接 [root@rocky8 ~]#psql -U postgres -h 10.0.0.200 -d testdb -w testdb=# \c You are now connected to database "testdb" as user "postgres". testdb=#
常用操作
查看psql帮助
#列出psql帮助用法 help #列出以\开头的命令,即psql的命令 \? #列出所有SQL命令的帮助,注意:SQL语句必须以 ; 结束 \h #查看指定SQL的帮助 \h create database \help create user
范例:
设置显示信息的格式
#后续查询将坚着显示,类似于MySQL中的\G \x #开启命令执行时长提示 \timing on #显示详细的信息,可以打印出报出问题的源代码位置 \set VERBOSITY verbose
范例: 竖着显示
postgres=# \x #开启竖着显示 Expanded display is on postgres=# \l #列出数据库信息。可以看到是竖着显示的 db1=# \l List of databases -[ RECORD 1 ]-----+---------------------- Name | db1 Owner | postgres Encoding | UTF8 Locale Provider | libc Collate | en_US.UTF-8 Ctype | en_US.UTF-8 Locale | ICU Rules | Access privileges | postgres=# select pg_sleep(3); pg_sleep (1 row)
范例:开启执行时长显示
testdb=# \timing on Timing is on. testdb=# select pg_sleep(3); Time: 3003.928 ms (00:03.004) testdb=# \timing off Timing is off. testdb=# select pg_sleep(3); testdb=#
范例: 查看出错对应的源代码位置
[root@ubuntu2004 ~]#su - postgres postgres@ubuntu2004:~$ psql postgres=# \set VERBOSITY verbose postgres=# select wang; ERROR: 42703: column "wang" does not exist LINE 1: select wang; LOCATION: errorMissingColumn, parse_relation.c:3349 #说明:错误对应的是parse_relation.c文件中的3349行中errorMissingColumn函数 [root@ubuntu2004 ~]#find -name parse_relation.c ./postgresql-12.9/src/backend/parser/parse_relation.c [root@ubuntu2004 ~]#vim +3349 `find -name parse_relation.c` errorMissingColumn(ParseState *pstate, const char *relname, const char *colname, int location) { FuzzyAttrMatchState *state; char *closestfirst = NULL; state = searchRangeTableForCol(pstate, relname, colname, location); if (state->rfirst && AttributeNumberIsValid(state->first)) closestfirst = strVal(list_nth(state->rfirst->eref->colnames, state->first - 1)); if (!state->rsecond)
数据库的创建和删除
创建数据库可以使用SQL语句create database 实现,也可以利用createdb命令创建数据库
createdb 是一个 SQL 命令 CREATE DATABASE 的封装。
createdb 命令语法格式如下:
createdb [option...] [dbname [description]] #参数说明: options:参数可选项,可以是以下值: -D tablespace指定数据库默认表空间。 -e 将createdb 生成的命令发送到服务端。 -E encoding指定数据库的编码。 -l locale指定数据库的语言环境。 -T template指定创建此数据库的模板。 --help显示 createdb 命令的帮助信息。 -h host指定服务器的主机名。 -p port指定服务器监听的端口,或者 socket 文件。 -U username连接数据库的用户名。 -w忽略输入密码。 -W连接时强制要求输入密码 dbname:要创建的数据库名。 description:关于新创建的数据库相关的说明。
删除数据库可以使用SQL语句drop database实现
范例: 创建数据库
#方法1 [root@ubuntu2004 ~]#createdb -h 10.0.0.200 -p 5432 -U postgres testdb Password: #方法2 postgres@ubuntu2004:~$ psql postgres=# create database testdb;
范例: 删除数据库
postgres@ubuntu2004:~$ psql postgres=# drop database testdb; #连着这个库时无法删除,先切到别的库再删除
范例: 查看数据库存放目录的路径
postgres=# select oid,datname from pg_database;
oid | datname
-------+-----------
5 | postgres
24580 | db1
1 | template1
4 | template0
24587 | db2
(5 rows)
postgres@debian:~$ ls /pgsql/data/base/
1 24580 24587 4 5
管理和查看模式
一个数据库包含一个或多个已命名的模式,模式又包含表。模式还可以包含其它 对象,包括数据类型、函数、操作符等。同一个对象名可以在不同的模式里使用 而不会导致冲突;比如,schema1和schema2都可以包含一个名为test的表
#创建模式 create schema schema_name; #删除模式 drop schema schema_name; #列出所有schema postgres=# \dn
范例
postgres=# \c db1 You are now connected to database "db1" as user "postgres". db1=# create schema m48_sch; CREATE SCHEMA db1=# create schema m47_sch; CREATE SCHEMA db1=# \dn m47_sch | postgres m48_sch | postgres public | pg_database_owner db1=# create table m48_sch.t1(id int); CREATE TABLE db1=# create table m47_sch.t1(id int); CREATE TABLE db1=# \dt public | t1 | table | postgres public | t2 | table | postgres #查看 db1=# \dt m48_sch.t1 m48_sch | t1 | table | postgres db1=# \dt m48_sch.* m48_sch | t1 | table | postgres db1=# \dt m47_sch.* m47_sch | t1 | table | postgres
查看和连接数据库
#列出所有数据库名,相当于MySQL中的show databases; postgres=# \l #显示数据库详细信息,比如大小 testdb-# \l+ #查看当前连接信息 postgres=# \c You are now connected to database "postgres" as user "postgres". #查看当前连接详细信息 postgres=# \conninfo You are connected to database "postgres" as user "postgres" via socket in "/tmp" at port "5432". #连接数据库,相当于use postgres=# \c hellodb You are now connected to database "hellodb" as user "postgres". hellodb=#
管理表
PostgreSQL 支持多种数据类型实现表结构的创建范例: 查看支持数据类型
postgres=# select typname from pg_type;
typname
--------------
bool
bytea
char
name
int8
int2
int2vector
int4
regproc
text
oid
tid
xid
cid
oidvector
pg_type
pg_attribute
pg_proc
pg_class
json
xml
范例: 管理表
postgres=# \c testdb testdb=# create table tb1 (id serial primary key,name text); CREATE TABLE #生成9次随机数插入到name中 testdb=# insert into tb1 (name) select (md5(random()::text)) from generate_series (2,10); INSERT 0 9 Time: 0.816 ms testdb=# select * from tb1; id | name ----+---------------------------------- 1 | b57de43d05a691dac86ae85b9191583e 2 | 2543f7146cfa18cfb3d5842dcd6a4304 3 | da0ea56dc318ce616f00b8750210cdec 4 | 7185258c81c16cca69591c7aaae11df4 5 | e49acadbce73bf718da4f037c45aee3b 6 | 3ffeac879d5e22202806b3c3354fb47c 7 | d8f1526f8f7bb636e2339729764af096 8 | cd2a34be663b47b0751d467df0f3128d 9 | b85b403e135688aca61b5f770e3c0562 #PostgreSQL中插入100万条记录只需要花2s testdb=# \timing on testdb=# insert into tb1 (name) select (md5(random()::text)) from generate_series (1,1000000); INSERT 0 1000000 Time: 2111.662 ms (00:02.112) testdb=# select count(*) from tb1; count --------- 1000000 (1 row) #复制表结构,不复制数据 testdb=# create table tb2 ( like tb1 ); CREATE TABLE testdb=# \d tb2 testdb=# select * from tb2; testdb=# drop table tb2;
查看表和表信息
#列出所有表,视图,序列 \d #列出public的schema中所有的表名,相当于show tables; \dt #查看t1的表信息 \dt t1 #支持通配符*和?,以下显示所有t开头的表 \dt t* #列出myschema模式的表结构 \dt myschema.* #查看t1的表结构,相当于desc \d t1 #列出所有表信息,包括大小 hellodb-# \dt+ #列出表信息 hellodb=# \dt students #列出表信息的大小信息 hellodb=# \dt+ students #查看所有表 postgres=# select * from pg_tables; #列出系统表 db1=# \dt pg_catalog.* #查看表大小 testdb=# select pg_total_relation_size('tb1'); testdb=# select pg_total_relation_size('tb1')/1024/1024||'MB';
范例: 查看表对应的文件径
db1=# select oid,datname from pg_database where datname = 'db1'; 16385 db1=# select relid from pg_stat_all_tables where relname='tb2'; 16413 [root@ubuntu2004 ~]#ll /pgsql/data/base/16385/16413 -rw------- 1 postgres postgres 0 Feb 14 07:21 /pgsql/data/base/16385/16413
范例: 查看当前库中的所有表的统计信息
postgres=# select * from pg_stat_all_tables; postgres=# \c testdb #查看指定表t1的信息 testdb=# select * from pg_stat_all_tables where relname='t1';
系统表(system catalogs)
官方文档
系统表的定义
系统表也称为系统目录(system catalogs),是关系型数据库存放模式元数据的地 方,比如表和列的信息,以及内部统计信息等。PostgreSQL的系统表也就是普通 表。虽然可以删除并重建这些表、增加列、插入和更新数值,但会导致系统损坏。 通常情况下,不应该手工修改系统目录,通过相关SQL命令去实现。例如:当执行 CREATE DATABASE 时会向系统表pg_database中插入一行记录,并且实际上在磁盘 上创建该数据库。
系统表包括存放系统信息的普通表或者视图,系统视图建立在系统表之上
系统表的创建
pg的每一个数据库中都有一套自己的系统表,其中大多数系统表都是在数据库创建时从模板数据库中拷贝过来的
系统表的维护
系统表中的信息由相的SQL命令关联至系统表自动维护
系统表的存储方式
和数据库相关的系统表保存在$PGDATA/base目录下相应数据库的文件夹下,文件 夹命名为pg_database里记录的数据库oid(Object identifiers),系统表都有一 个列名为对象标识符oid,用于标识postgres里各个对象,如表、序列、索引等,以 前版本是隐藏的
所有数据库共享的系统表,如pg_database,保存在$PGDATA/global下
范例: 查看系统表
#查看系统表 postgres=# \dS postgres=# \dS+ #列出所有pg开头的系统表 postgres=# \dt pg_* #列出所有pg开头的系统视图 postgres=# \dv pg_* #查看系统表pg_database的结构 postgres=# \d pg_database Table "pg_catalog.pg_database" Column | Type | Collation | Nullable | Default ----------------+-----------+-----------+----------+--------- oid | oid | | not null | datname | name | | not null | datdba | oid | | not null | encoding | integer | | not null | datlocprovider | "char" | | not null | datistemplate | boolean | | not null | datallowconn | boolean | | not null | dathasloginevt | boolean | | not null | datconnlimit | integer | | not null | datfrozenxid | xid | | not null | datminmxid | xid | | not null | dattablespace | oid | | not null | datcollate | text | C | not null | datctype | text | C | not null | datlocale | text | C | | daticurules | text | C | | datcollversion | text | C | | datacl | aclitem[] | | | postgres=# \d pg_tables; View "pg_catalog.pg_tables" Column | Type | Collation | Nullable | Default -------------+---------+-----------+----------+--------- schemaname | name | | | tablename | name | | | tableowner | name | | | tablespace | name | | | hasindexes | boolean | | | hasrules | boolean | | | hastriggers | boolean | | | rowsecurity | boolean | | |
范例: 查看指定表对应的文件
testdb=# select * from pg_relation_filepath('t1'); #pg_relation_filepath系统函数 pg_relation_filepath base/16408/16409 [root@ubuntu2004 ~]#ll /pgsql/data/base/16408/16409 -rw------- 1 postgres postgres 76562432 Jan 16 03:44 /pgsql/data/base/16408/16409
表的CRUD
SQL的CRUD,即 Insert,update,delete,select 四条语句范例:
db1=# create database testdb; db1=# \c testdb testdb=# create table tb1 (id serial,name varchar(10)); CREATE TABLE testdb=# \d tb1; Table "public.tb1" Column | Type | Collation | Nullable | Default --------+-----------------------+-----------+----------+--------------------------------- id | integer | | not null | nextval('tb1_id_seq'::regclass) name | character varying(10) | | | testdb=# insert into tb1 (name)values('wang'); INSERT 0 1 testdb=# insert into tb1 (name)values('li'); INSERT 0 1 testdb=# select * from tb1; testdb=# update tb1 set name='zhao' where id=2; UPDATE 1 testdb=# select * from tb1; testdb=# delete from tb1 where id=2; DELETE 1 testdb=# select * from tb1; #清空表 testdb=# truncate tb1; testdb=# truncate table tb1; TRUNCATE TABLE testdb=# select * from tb1;
范例: 查看表的列信息及大小
hellodb=# \d students; hellodb=# select pg_column_size(name),name from students;
范例:
testdb=# select generate_series(3,6); 3 4 5 6 testdb=#
索引管理
范例:创建和删除索引
testdb=# create table tb1(id int,info text,crt_time timestamp); CREATE TABLE testdb=# insert into tb1 select generate_series(1,100000),md5(random()::text),clock_timestamp(); INSERT 0 100000 testdb=# select * from tb1 limit 3; 1 | 4d801e211aca0b2787ecbd489eb91460 | 2020-03-18 03:06:55.279125 2 | c798c226fcf884c0d892de5f6bed0355 | 2020-03-18 03:06:55.279367 3 | 268445645ff62f6c7cbbad98a74704b8 | 2020-03-18 03:06:55.279369 #创建索引 testdb=# create index idx_tb1_id on tb1(id); #索引名, idx_表名_列名 CREATE INDEX testdb=# \d tb1 Table "public.tb1" Column | Type | Collation | Nullable | Default ----------+-----------------------------+-----------+----------+--------- id | integer | | | info | text | | | crt_time | timestamp without time zone | | | Indexes: "idx_tb1_id" btree (id) #删除索引 testdb=# drop index idx_tb1_id ; DROP INDEX testdb=# \d tb1 testdb=#
范例: 使用索引
#打开时间 testdb=#\timing on #查询条件是索引列 testdb=# explain analyze select * from tb1 where id = 99999; QUERY PLAN ----------------------------------------------------------------------------------------------------------------- Index Scan using idx_tb1_id on tb1 (cost=0.29..8.31 rows=1 width=45) (actual time=0.112..0.114 rows=1 loops=1) #Index Scan 索引查询 Index Cond: (id = 99999) Planning Time: 0.473 ms Execution Time: 0.136 ms #查询条件不是索引列 testdb=# explain analyze select * from tb1 where info ='f522a254fa2314150c574160bf1e7139'; QUERY PLAN -------------------------------------------------------------------------------------------------- Seq Scan on tb1 (cost=0.00..2185.00 rows=1 width=45) (actual time=0.014..12.195 rows=1 loops=1) #Seq Scan 不是索引 Filter: (info = 'f522a254fa2314150c574160bf1e7139'::text) Rows Removed by Filter: 99999 Planning Time: 0.052 ms Execution Time: 12.211 ms (5 rows) #关闭索引 testdb=# set enable_indexscan=off; testdb=# set enable_bitmapscan=off; #再次查询全表扫描 testdb=# explain analyze select * from tb1 where id = 99999; testdb=# explain (analyze,verbose,costs,buffers,timing) select * from tb1 where id = 99999;
表空间
#列出所有表空间,实际上PostgresQL中的表空间就是对应一个目录, #放在这个表空间的表,就是把表的数据文件放到这个表空间下。 postgres=# \db List of tablespaces Name | Owner | Location ------------+----------+---------- pg_default | postgres | pg_global | postgres | (2 rows) testdb=# \db+ #显示表空间的大小 List of tablespaces Name | Owner | Location | Access privileges | Options | Size | Description ------------+----------+----------+-------------------+---------+--------+------------- pg_default | postgres | | | | 138 MB | pg_global | postgres | | | | 565 kB | (2 rows) #复制表到文件中 testdb=# select * from t1; testdb=# copy t1 to '/tmp/t1.txt'; COPY 2 [root@ubuntu2004 ~]#cat /tmp/t1.txt 1 2
范例:表空间pg_tblspc目录
[root@ubuntu2004 ~]#su - postgres postgres@ubuntu2004:~$ mkdir ts1 postgres@ubuntu2004:~$ psql testdb #创建表空间 postgres=# create tablespace ts1 location '/home/postgres/ts1/'; CREATE TABLESPACE postgres=# \db List of tablespaces Name | Owner | Location ------------+----------+-------------------- pg_default | postgres | pg_global | postgres | ts1 | postgres | /home/postgres/ts1 (3 rows) postgres@ubuntu2004:~$ readlink /pgsql/data/pg_tblspc/16442 /home/postgres/ts1 #删除表空间,提前清空表空间中的表 testdb=# drop tablespace ts1; DROP TABLESPACE
范例: 查看表空间对应的文件
[root@ubuntu2004 ~]#ls /pgsql/data/pg_tblspc [root@ubuntu2004 ~]#su -postgres postgres@ubuntu2004:~$ mkdir /tmp/tbs1 postgres@ubuntu2004:~$ psql testdb=# create tablespace tbs1 location '/tmp/tbs1' ; testdb=# create table tb1(id int) tablespace tbs1; testdb=# select * from pg_relation_filepath('tb1'); postgres@ubuntu2004:~$ tree /pgsql/data/pg_tblspc/ postgres@ubuntu2004:~$ tree /tmp/tbs1/
查看系统信息
可以通过系统函数查看系统信息,也可以通过show/set 查看和修改配置
#查看版本信息 postgres=# select version(); #查看数据库启动时间 postgres=# select pg_postmaster_start_time(); #查看加载配置文件时间 postgres@ubuntu2004:~$ pg_ctl reload postgres=# select pg_conf_load_time(); #查看时区和时间 postgres=# show timezone; Etc/UTC (1 row) #临时修改 postgres=# set timezone='Asia/Shanghai' #永久修改时区 postgres@ubuntu2004:~$ vim /pgsql/data/postgresql.conf timezone = 'Asia/Shanghai' postgres@ubuntu2004:~$ pg_ctl reload postgres=# select now(); #查看当前用户 postgres=# select user; postgres=# select current_user; postgres=# select session_user; #查看当前数据库 postgres=# \c #连接数据库 postgres=# \c testdb #查看当前session所在的客户端IP和端口 [root@rocky8 ~]#psql -h 10.0.0.200 -U postgres postgres=# select inet_client_addr(),inet_client_port(); #查看当前session所连接的数据库服务器的IP和端口 postgres=# select inet_server_addr(),inet_server_port(); #查询当前session对应的后台服务时程pid postgres=# select pg_backend_pid(); ps auxf |grep postgres #查看当前内置变量 postgres=> \set #查看当前指定配置 postgres=# show max_connections; postgres=# select current_setting('max_connections'); postgres=# select current_setting('listen_addresses'); #显示系统函数 postgres=# \dfS+ #查看连接数 postgres=# select count(*) from pg_stat_activity; #查看当前最大的连接数 postgres=# select setting from pg_settings where name = 'max_connections'; #查看所有设置名称 postgres=# select name from pg_settings; #查看当前设置名和值 postgres=# select name,setting from pg_settings; #查看指定的当前的参数设置 postgres=# show port; postgres=# show archive_mode; archive_mode -------------- off
范例: show 和 set 查看和修改配置
# 查看参数 SHOW name; SHOW ALL; postgres=# show all; #修改配置 SET [ SESSION | LOCAL ] configuration_parameter { TO | = } { value |'value' | DEFAULT } SET [ SESSION | LOCAL ] TIME ZONE { timezone | LOCAL | DEFAULT } postgres=# show maintenance_work_mem ; postgres=# set maintenance_work_mem to '128MB'; testdb=# set maintenance_work_mem='128MB'; #写法2 SET postgres=# show maintenance_work_mem ; #注意:不是所有配置都可以直接修改的 postgres=# set max_connections to '200'; ERROR: parameter "max_connections" cannot be changed without restarting the server #查看数据库的大小,pg_size_pretty函数会把数字以MB,GB等易读格式显示 postgres=# select pg_database_size('hellodb'),pg_size_pretty(pg_database_size('hellodb')); pg_database_size | pg_size_pretty 8029039 | 7841 kB
范例: explain可以查看SQL的执行计划
#explain可以查看SQL的执行计划 hellodb=# explain select * from students; hellodb=# explain analyze select * from students; hellodb=# explain analyze verbose select * from students;
查看用户和权限
#查看所有用户\du或\dg postgres=# \du List of roles Role name | Attributes -----------+------------------------------------------------------------ postgres | Superuser, Create role, Create DB, Replication, Bypass RLS #查看当前用户 postgres=# select user ; postgres=# select current_user; #显示表,视图,序列的权限分配情况 postgres=# \z postgres=# \z t1 #和\z功能相同 postgres=# \dp
事务管理和锁
PGSQL的事务中支持DML,DDL(除了create database,create tablespace),DCL
在psql中事务是自动提交的。和MySQL相同,执行完一条delete或update语句后,事务就自动提交了如果不想自动提交,方法有两种。
方法一:运行begin;命令,然后执行DML,DDL,DCL等语句,最后再执行commit或rollback语句。
方法二:直接使用psql中的命令关闭自动提交的功能。\set AUTOCOMMIT off,注意,命令中的 AUTOCOMMIT是大写的,不能使用小写,如果使用小写、虽然不会报错,但会导致关闭自动提交的操作不起作用。
#开始事务 BEGIN [ISOLATION LEVEL { SERIALIZABLE | REPEATABLE READ | READ COMMITTED | READ UNCOMMITTED }] #提交和取消事务 COMMIT|END ROLLBACK #关闭自动提交,可以用rollback取消DML语句 \set AUTOCOMMIT off #使用commit; 来提交 \set AUTOCOMMIT on #查看AUTOCOMMIT状态 \echo :AUTOCOMMIT #查看事务ID select txid_current();
范例:
postgres@ubuntu2004:~$ psql postgres=# \c testdb testdb=# begin; BEGIN testdb=# create table tb1 (id int); testdb=# insert into tb1 values (1); testdb=# select * from tb1; 1 testdb=# rollback; ROLLBACK testdb=# \d Did not find any relations. #查看事务ID postgres=# select txid_current(); 543 #事务块中不支持create database testdb=# begin; BEGIN testdb=# create database db1; 2022-01-18 01:54:36.823 UTC [14674] ERROR: CREATE DATABASE cannot run inside a transaction block 2022-01-18 01:54:36.823 UTC [14674] STATEMENT: create database db1; ERROR: CREATE DATABASE cannot run inside a transaction block #查看ctid(数据所在的数据块的编号及位移),xmin(插入事务XID),xmax(删除记录的事务XID) testdb=# select ctid,xmin,xmax,* from tb1; #查看锁信息 testdb=# select relation::regclass,* from pg_locks;
常用的系统函数
官方内置系统函数帮助 -http://postgres.cn/docs/current/functions-info.html
常用系统函数
#查看当前日志文件lsn位置; select pg_current_wal_lsn(); select pg_current_xlog_location(); #当前xlog buffer中的insert位置,注意和上面pg_current_xlog_location()的区别: SELECT pg_current_wal_insert_lsn(); select pg_current_xlog_insert_location(); #查看某个1sn对应的日志名: select pg_walfile_name(lsn) ; select pg_xlogfile_name(1sn); #查看某个1sn在日志中的偏移量: select pg_walfile_name_offset('lsn号'); select pg_xlogfile_name_offset('lsn号'); #查看两个lsn位置的差距; select pg_wa1_1sn_diff('lsn号','lsn号'); select pg_xlog_1ocation_diff('lsn号','lsn号'); #查看备库接收到的1sn位置: select pg_last_wal_receive_lsn(); select pg_last_xlog_receive_location(); #查看备库回放的lsn位置: select pg_last_xact_replay_timestamp(); select pg_last_xlog_relay_location(); #创建还原点: select pg_create_restore_point(now()::text); #查看表的数据文件路径,filenode: select pg_relation_filenode( '表名'); #查看表students的oid: select 'students'::regclass::oid; #查看当前会话pid: select pg_backend_pid(); #生成序列: select generate_series (1,8,2); #生成uuid (pg13新特性): se1ect gen_random_uuid(); #重载配置文件信息: select pg_reload_conf(); #查看数据库启动时间: select pg_postmaster_start_time();
用户和角色
PostgreSQL使用角色role的概念来管理数据库访问权限。角色是一系列相关权限 的集合。为了管理方便,通常会把一系列相关的数据库权限赋给一个角色,如果 哪个用户需要这些权限,就把角色赋给相应的用户。由于用户也拥有一系列的相 关权限,为了简化管理,在PostgreSQL中,角色与用户是没有区别的,一个用户 也是一个角色,因此可以把一个用户的权限赋给另一个用户。
用户和角色在整个数据库实例中都是全局的,即在同一个实例中的不同数据库中,看到的用户也都是相同的。
在初始化数据库实例时,会创建一个预定义的超级用户,这个用户的名称与初始 化该数据库实例的操作系统用户名相同。比如:如果数据库实例是建立在操作系 统用户dba (通常使用 postgres用户)下的,这个数据库超级用户的名称也会叫 dba。可以用这个超级用户连接数据库,注意:dba默认会连接同名的数据库dba, 而默认dba不存在,所以需要登录时指定连接数据库postgres进行登录,然后再创 建其它的用户
创建用户和角色
在PostgreSQL中,用户与角色是没有区别的。
用户和角色可以用来实现以下功能:
- 用来登录数据库实例
- 管理数据库对象
创建用户与角色的语法如下:
CREATE USER name [[WITH] option [ ...]] CREATE ROLE name [[WITH] option [ ...]] #上面两个命令都可以创建用户,不同的是CREATE USER创建的用户默认可以登录,而CREATE ROLE不可以登录 #除了CREATE USER 默认创建出来的用户有LOGIN 的权限,而CREATE ROLE #创建出来的用户没有“LOGIN"的权限之外,CREATE RULE 与 CREATE USER没有其他任何的区别。 #上面语法中的“option”可以是如下内容。 SUPERUSER | NOSUPERUSER:表示创建出来的用户是否为超级用户。只有超级用户才能创建超级用户。 CREATEDB /NOCREATEDB:指定创建出来的用户是否有执行'CREATE DATABASE'的权限。 CREATEROLE NOCREATEROLE:指定创建出来的用户是否有创建其他角色的权限。 CREATEUSER NOCREATEUSER:指定创建出来的用户是否有创建其他用户的权限。 INHERIT |NOINHERIT:如果创建的一个用户拥有某一个或某几个角色,这时若指定INHERIT, 则表示用户自动拥有相应角色的权限,否则这个用户没有该角色的权限。 LOGIN | NOLOGIN:指定创建出来的用户是否有“LOGIN”的权限,可以临时地禁 止一个用户的“LOGIN”权限,这时此用户就不能连接到数据库 CONNECTION LIMIT connlimit:指定该用户可以使用的并发连接数量。默认值是-1,表示没有限制。 [ENCRYPTED | UNENCRYPTED ] PASSWORD'password' : 用于控制存储在系统表里面的口令是否加密。 VALID UNTIL 'timestamp':密码失效时间,如果不指定这个子句,那么口令将永远有效。 INROLE role name [,...]:指定用户成为哪些角色的成员,请注意没有任何选项可以把新角色添 加为管理员,必须使用独立的GRANT命令来做这件事情。 IN GROUP role_name [,...]:与IN ROLE相同,是已过时的语法。 ROLE role_name [,...]: role_name将成为这个新建的角色的成员。 ADMIN role_name [,...]: role_name将有这个新建角色的WITH ADMIN OPTION权限。 USER role_name[,....]:与ROLE子句相同,但已过时。 SYSID uid:此子句主要是为了SQL向下兼容,实际没有什么用处。
用户管理案例
#查看帮助 \h create user \h alter user \h drop user \h create role \h alter role \h drop role #以下两个命令用法相似 create user #创建的用户默认可以连接 create role #创建的用户默认无法连接 #修改用户 alter user #删除用户 drop user #显出所有用户和角色 #\du和\dg命令等价。原因是在PostgreSQL数据库中用户和角色不分的。 \du \dg
范例:
#创建可以登录的用户和密码 CREATE USER wang WITH PASSWORD '123456'; #创建不可登录用户 create role zhao WITH PASSWORD '123456'; #创建可以连接的用户 CREATE ROLE li WITH LOGIN PASSWORD '123456' VALID UNTIL '2020-07-01' #创建管理员 CREATE ROLE admin WITH SUPERUSER LOGIN PASSWORD '123456' ; #创建复制用户 CREATE USER repl REPLICATION LOGIN ENCRYPTED PASSWORD '123456'; #修改密码 ALTER USER admin with password '654321'; #修改权限和密码 alter user wang with nologin password '123'; alter user zhao with login; #删除用户 DROP USER song; #查看用户信息 \du #查看指定用户信息 \du wang
范例:修改 postgres用户密码
#使用postgres用户登录(PostgresSQL安装后会自动创建postgres用户) [root@rocky8 ~]#su - postgres #登录postgresql数据库 [root@rocky8 ~]# psql -U postgres #安全起见,修改数据库管理员postgres用户的密码 postgres=# ALTER USER postgres WITH ENCRYPTED PASSWORD '123456'; ALTER ROLE
权限管理
在PostgreSQL数据库中,每个数据库的对象(包括数据库)都有一个所有者,也就 是说任何数据库对象都是属于某个用户的,所有者默认就拥有所有权限。所以不 需要把对象的权限再赋给所有者。自己创建的数据库对象,自己当然有全部的权 限。当然,所有者出于安全考虑也可以选择废弃一些自己的权限。在 PostsgreSQL数据库中,删除一个对象及任意修改它的权利是所有者固有的,不能 被赋予或撤销。所有者也隐含地拥有把操作该对象的权限赋给别人的权利。
一个用户的权限分为两类,一类是在创建用户时就指定的权限,这些权限如下:
- 超级用户的权限
- 创建数据库的权限
- 是否允许LOGIN的权限
以上这些权限是创建用户时指定的,后续可使用ALTER ROLE命令来修改。
还有一类权限,是由命令GRANT和 REVOKE来管理的,这些权限如下:
- 在数据库中创建模式(SCHEMA)
- 允许在指定的数据库中创建临时表连接某个数据库
- 在模式中创建数据库对象,如创建表、视图函数等
- 在一些表中做SELECT、UPDATE、INSERRDELETE等操作等
#GRANT命令有两个作用 #1.让某个用户成为某个角色的成员,从而使其拥有角色的权限: GRANT role_name [, ...] T0 role_name [, ...] [ WITH ADMIN OPTION ]; #2.把某些数据库逻辑结构对象的操作权限赋予某个用户(或角色),命令的格式如下: GRANT some privileqes ON database_object_type object_name TO role_name; 其中,“some privileges”表示在这个数据库对象中的权限,“database_object_type”是数据库对象的类型, 如“TABLE”、“SEQUENCE”、“SCHEMA”,等。
PostgreSQL中的权限是按以下几个层次进行管理的:
- cluster权限:实例权限通过pg_hba.conf配置
- 管理赋在用户特殊属性上的权限,如超级用户的权限、创建数据库的权限、创建用户的权限、Login权限等
- 在数据库中创建模式的权限
- 表空间权限:通过grant/revoke控制权限操作表,物化视图,索引等
- 在模式中创建数据库对象的权限,如创建表、创建索引,等等
- 查询表、往表中插入数据、更新表、删除表中数据的权限
- 操作表中某些字段的权限
权限案例
范例:
#授权创建新数据库 postgres=# alter user wang with CREATEDB; #database权限设置 GRANT create ON DATABASE testdb TO wang; #schema权限 ALTER SCHEMA wang OWNER to wang; GRANT select,insert,update,delete ON ALL TABLES IN SCHEMA wang TO wang; #创建test的schema指定所有者为joe CREATE SCHEMA IF NOT EXISTS test AUTHORIZATION joe; #object权限 GRANT select,insert,update,delete ON testdb.t1 TO wang; #创建数据库并指定所有者的用户 create user wang with password '123456'; CREATE DATABASE zabbix OWNER wang;
范例: 创建业务用户和授权
postgres=# create database pinxixi; postgres=#\c pinxixi pinxixi=#create user wanrentuan with password '123456'; #方法1 pinxixi=#create schema wanrentuan; pinxixi=#ALTER SCHEMA wanrentuan OWNER to wanrentuan; #方法2 pinxixi=#CREATE SCHEMA AUTHORIZATION wanrentuan; #方法3 pinxixi=#GRANT select, insert,update,delete oN ALL TABLES IN SCHEMA wanrentuan to wanrentuan;
范例:
#将创建一个名为“readonly”的用户 CREATE USER readonly with password '123456'; #把在public的schema下现有的所有表的SELECT 权限赋给用户readonly GRANT SELECT ON ALL TABLES IN SCHEMA public TO readonly;
安装使用图形化工具pgadmin
pgadmin 介绍
pgAdmin是一个免费的开源图形数据库管理工具,用于管理PostgreSQL和衍生的 关系数据库,如EnterpriseDB的EDB Advanced Server。pgAdmin可以以两种模式 安装:服务器模式和桌面模式。服务器模式下的pgAdmin可以部署在不同的Web服 务器中,如:Apache,Nginx等
pgAdmin 是一个在PostgreSQL许可下发布的免费软件项目。该软件可从 PostgreSQL镜像网络以源代码和二进制格式获得。因为从源代码编译比较繁琐, 建议尽可能使用安装二进制包。
pgAdmin 4 是对 pgAdmin 的完全重写,使用 Python 和 Javascript/jQuery构建
安装pgadmin
范例: 安装Windows版本的pgadmin
- 修改语言环境 Prefernces –>Miscellaneous–>User language
- 关闭并重新打开pgadmin才能看到显示已汉化
范例: Ubuntu20.04 安装 pgadmin
[root@ubuntu2004 ~]#apt install pgadmin4 -y [root@ubuntu2004 ~]#pgadmin4
范例: 基于docker 安装 pgadmin
[root@rocky8 ~]#docker run -e PGADMIN_DEFAULT_EMAIL[email protected] \ -e PGADMIN_DEFAULT_PASSWORD=123456 -d --name pgadmin -p 80:80 \ dpage/pgadmin4
PostgreSQL 体系架构
体系架构概览
PostgreSQL和MySQL相似,也采用典型的C/S模型。
PostgreSQL体系结构分两部分
- 实例 instance
- 磁盘存储
实例 instance 包括
- 进程
- 内存存储结构
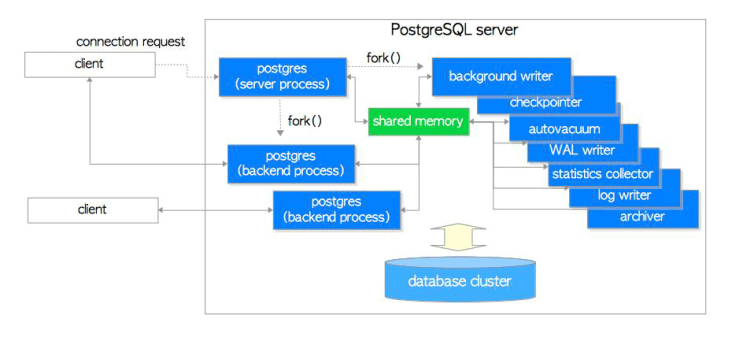
进程和内存结构
PostgreSQL是进程架构模型,MySQL是线程架构模型。
下图来自《POSTGRESQL修炼之道从小工到专家》
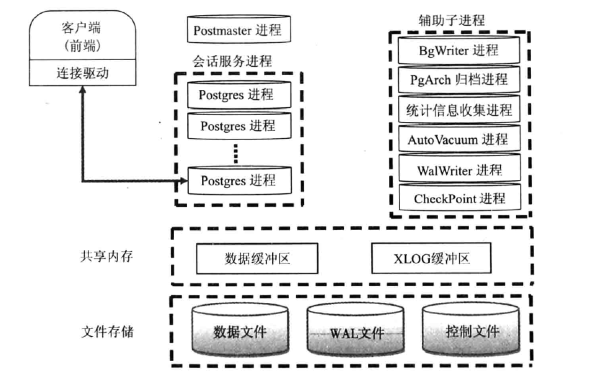
进程
- Postmaster 主进程
- 它是整个数据库实例的主控制进程,负责启动和关闭该数据库实例。
- 实际上,使用pg ctl来启动数据库时,pg_ctl也是通过运行postgres来启动数据库的,只是它做了一些包装,更容易启动数据库。
- 它是第一个PostgreSQL进程,此主进程还会fork出其他子进程,并管理它们。
- 当用户和PostgreSQL建立连接时,首先是和Postmaster进程建立连接。首先,客户端会发出身份验证的信息给Postmaster进程,Postmaster进程根据消息中的信息进行身份验证判断,如果验证通过,它会fork出一个会话子进程为这个连接服务。
- 当某个服务进程出现错误的时候,Postmaster主进程会自动完成系统的恢复。恢复过程中会停掉所有的服务进程,然后进行数据库数据的一致性恢复,等恢复完成后,数据库又可以接受新的连接。
- 验证功能是通过配置文件pg_hba.conf和用户验证模块来提供。
postmaster 程序是指向postgres的软链接
[root@ubuntu2004 ~]#ll /apps/pgsql/bin/postmaster lrwxrwxrwx 1 root root 8 Dec 28 01:19 /apps/pgsql/bin/postmaster ->postgres*
- BgWriter 后台写进程
- 为了提高插入、删除和更新数据的性能,当往数据库中插入或者更新数据时,并不会马上把数据持久化到数据文件中,而是先写入Buffer中
- 该辅助进程可以周期性的把内存中的脏数据刷新到磁盘中
- WalWriter 预写式日志进程
- WAL是write ahead log的缩写,WAL log旧版中称为xlog,相当于MySQL中Redo log预写式日志是在修改数据之前,必须把这些修改操作记录到磁盘中,这样后面更新实际数据时,就不需要实时的把数据持久化到文件中了。即使机器突然宕机或者数据库异常退出,导致一部分内存中的脏数据没有及时的刷新到文件中,在数据库重启后,通过读取WAL日志,并把最后一部分WAL日志重新执行一遍,就能恢复到宕机时的状态了
- WAL日志保存在pg_wal目录(早期版本为pg_xlog)下。每个xlog文件默认是16MB,为了满足恢复要求,在pg_wal目录下会产生多个WAL日志,这样就可保证在宕机后,未持久化的数据都可以通过WAL日志来恢复,那些不需要的WAL日志将会被自动覆盖
- Checkpointer 检查点进程
- 检查点(Checkpoints)是事务序列中的点,保证在该点之前的所有日志信息都更新到数据文件中。
- 在检查点时,所有脏数据页都冲刷到磁盘并且向日志文件中写入一条特殊的检查点记录。在发生崩溃的时候,恢复器就知道应该从日志中的哪个点(称做redo 记录)开始做 REDO操作,因为在该记录前的对数据文件的任何修改都已经在磁盘上了。在完成检查点处理之后,任何在redo记录之前写的日志段都不再需要,因此可以循环使用或者删除。在进行 WAL归档的时 候,这些日志在循环利用或者删除之前应该必须先归档保存
- 检查点进程 (CKPT)在特定时间自动执行一个检查点,通过向数据库写入进程 (BgWriter)传递消息来启动检查点请求
- AutoVacuum 自动清理进程
- 执行delete操作时,旧的数据并不会立即被删除,在更新数据时,也不会在旧的数据上做更新,而是新生成一行数据。旧的数据只是被标识为删除状态,在没有并发的其他事务读到这些旧数据时,它们才会被清除掉
- autovacuum lanucher负责回收垃圾数据的master进程,如果开启了autovacuum的话,那么postmaster会fork这个进程
- autovacuum worker负责回收垃圾数据的worker进程,是lanucher进程fork出来的
- PgStat 统计数据收集进程
- 此进程主要做数据的统计收集工作
- 收集的信息主要用于查询优化时的代价估算。统计的数据包括对一个表或索引进行的插入、删除、更新操作,磁盘块读写的次数以及行的读次数等。
- 系统表pg_statistic中存储了PgStat收集的各类统计信息
- PgArch 归档进程
- 默认没有此进程,开启归档功能后才会启动archiver进程
- WAL日志文件会被循环使用,也就是说WAL日志会被覆盖,利用PgArch进程会在覆盖前把WAL日志备份出来,类似于binlog,可用于备份功能
- PostgreSQL 从8.X版本开始提供了PITR (Point-In-Time-Recovery)技术,即就是在对数据厍进行过一次全量备份后,该技术将备份时间点后面的WAL日志通过归档进行备份,将来可以使用数据库的全量备份再加上后面产生的WAL日志,即可把数据库向前恢复到全量备份后的任意一个时间点的状态
- SysLogger 系统日志进程
- 默认没有此进程,配置文件 postgresql.conf设置参数logging_collect设置为“on”时,主进程才会启动SysLogger辅助进程
- 它从Postmaster主进程、所有的服务进程以及其他辅助进程收集所有的stderr输出,并将这些输出写入到日志文件中
- startup 启动进程
- 用于数据库恢复的进程
- Session 会话进程
- 每一个用户发起连接后,一旦验证成功,postmaster进程就会fork—个新的子进程负责连接此用户。
- 通常表现为进程形式: postgres postgres [local] idle
案例: 查看进程
[root@ubuntu2004 ~]#ps auxf|grep ^postgres
范例: 开启归档后再查看进程
[root@ubuntu2004 ~]#ps auxf|grep ^postgres
内存结构
PostgreSQL的内存空间包括共享内存和本地内存两部分
- 共享内存
- PostgreSQL启动后,会生成一块共享内存,共享内存主要用做数据块的缓冲区,以便提高读写性能。WAL日志缓冲区和CLOG(Commit log)缓冲区也存在于共享内存中。除此以外,一些全局信息也保存在共享内存中,如进程信息、锁的信息、全局统计信息等。
- PostgreSQL9.3之前的版本与Oracle数据库一样,都是使用“SystemV”类型的共享内存,但到PostgreSQL9.3之后,PostgreSQL使用mmap()方式共享内存,好处能使用较大的共享内存。
- 可以通过配置postgresql.conf文件中shared_buffers指定,默认128M,建议是内存的50%
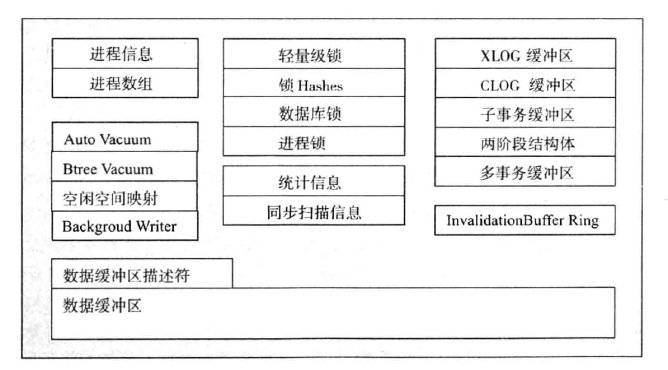
本地内存
后台服务进程除访问共享内存外,还会申请分配一些本地内存,以便暂存一些不需要全局存储的数据。
都可以通过在配置postgresql.conf文件中指定
这些内存缓冲区主要有以下几类:
- temp_buffers:用于访问临时表的本地缓冲区,默认为8M
- work_mem:内部排序操作和Hash表在使用临时磁盘文件之前使用的内存缓冲区,默认为4M
- maintenance_work_mem:在维护性操作(比如VACUUM、CREATE INDEX和ALTERTABLE ADD FOREIGN KEY 等)中使用的内存缓冲区,默认为64M
范例:查看内存空间
postgres=# show shared_buffers; 128MB postgres=# show maintenance_work_mem; 64MB postgres=# show work_mem; 4MB
数据更新过程
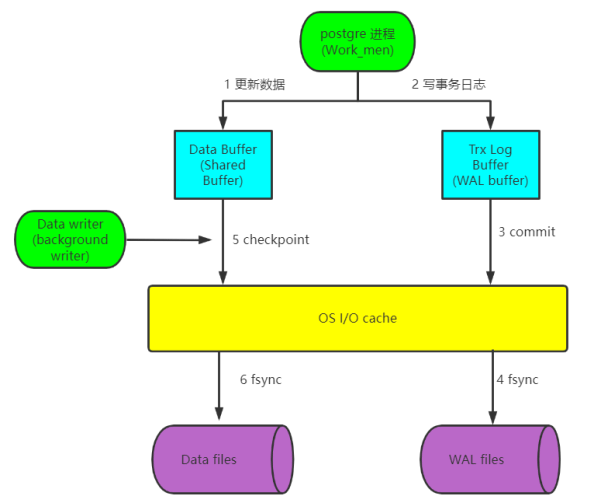
- 先将数据库文件中的更改的数据加载至内存
- 在内存更新数据
- 将日志写入内存WAL的缓存区
- 将日志提交,将日志写入操作系统 cache
- 同步日志到磁盘
- 后台写数据库的更新后的数据到操作系统 cache
- 写完数据后,更新检查点checkpoint
- 同步数据到磁盘
数据库目录结构
数据库目录介绍
数据库数据存放在环境变量PGDATA指向数据目录。这个目录是在安装时指定的, 所以在安装时需要指定一个合适的目录作为数据目录的根目录,而且,每一个数 据库实例都要有一个对应的目录。目录的初始化是使用initdb来完成的。
PGDATA - File segment, Tablespace, Control file, Online WAL log, ARCH WAL log, Log file
初始化完成后,PGDATA数据目录下就会生成三个配置文件。
postgresql.conf #数据库实例的主配置文件,基本上所有的配置参数都在此文件中。 pg_hba.conf #认证配置文件,配置了允许哪些IP的主机访问数据库,认证的方法是什么等信息。 pg_ident.conf #认证方式ident的用户映射文件。
此外在PGDATA目录下还会生成如下一些子目录
base #默认表空间的目录,每个数据库都对应一个base目录下的子目录,每个表和索引对应一个独立文件 global #这个目录对应pg_global表空间,存放实例中的共享对象 pg_clog #存储事务提交状态数据 pg_bba.conf #数据库访问控制文件 pg_log #数据库系统日志目录,在查询一些系统错误时就可查看此目录下日志文件。(根据配置定义,可能没有这个目录) pg_xact #提交日志commit log的目录,pg 9之前叫pg_clog pg_multixact #共享行锁的事务状态数据 pg_notify #异步消息相关的状态数据 pg_serial #串行隔离级别的事务状态数据 pg_snapshots #存储执行了事务snapshot导出的状态数据 pg_stat_tmp #统计信息的临时文件 pg_subtrans #子事务状态数据 pg_stat #统计信息的存储目录。关闭服务时,将pg_stat_tmp目录中的内容移动至此目录实现保存 pg_stat_tmp #统计信息的临时存储目录。开启数据库时存放统计信息 pg_tblsp #存储了指向各个用户自建表空间实际目录的链接文件 pg_twophase #使用两阶段提交功能时分布式事务的存储目录 pg_wal #WAL日志的目录,早期版一本目录为pg_xlog PG_VERSION #数据库版本 postmaster.opts #记录数据库启动时的命令行选项 postmaster.pid #数据库启动的主进程信息文件,包括PID,SPGDATA目录, 数据库启动时间,监听端口,socket文件路径,临听地址,共享内存的地址信 息(ipsc可查看),主进程状态
范例:
[root@ubuntu2004 ~]#ll $PGDATA
范例:
[root@ubuntu2004 ~]#ls /pgsql/data [root@ubuntu2004 ~]#cat /pgsql/data/PG_VERSION 14 [root@ubuntu2004 ~]#cat /pgsql/data/postgresql.auto.conf # Do not edit this file manually! # It will be overwritten by the ALTER SYSTEM command. [root@ubuntu2004 ~]#cat /pgsql/data/postmaster.opts /apps/pgsql/bin/postgres "-D" "/pgsql/data" postgres@ubuntu2004:~$ cat /pgsql/data/postmaster.pid 892 /pgsql/data 1579156864 5432 /tmp/ * 5432001 0 ready [root@ubuntu2004 ~]#find /tmp -type s -ls
postgresql.conf 配置项
PostgreSQL 的配置参数是在postgresql.conf文件中集中管理的,这个文件位于数据库实例的目录下$PGDATA
- 此文件中的每个参数配置项的格式都是“参数名=参数值”
-配置文件中可以使用“#”注释。
- 所有配置项的参数名都是大小写不敏感的
- 参数值有以下五种类型。
- 布尔:布尔值都是大小写无关的,可以是on、off、true,false、yes、no、1、0。
- 整数:数值可以指定单位。如一些内存配置的参数可以指定KB、MB、GB等单位。
- 另外还支持浮点数,字符串,枚举
- postgresql.conf文件中可以使用include指令包含其他文件中的配置内容,如:include filenamejj,如果指定被包含的文件名不是绝对路径,那么就相对于当前配置文件所在目录的相对路径。此外,包含还可以被嵌套。
- 所有的配置参数都在系统视图pg_settings中
- $PGDATA目录下如果含有postgresql.conf和postgresql.auto.conf,而 postgresql.auto.conf的优先级高于postgresql.conf,即如果一个参数同时 存在postgresql.auto.conf和postgresql.conf里面,系统会先读 postgresql.auto.conf的参数配置
常用配置说明
listen_addresses='*' #监听客户端的地址,默认是本地的,需要修改为*或者0.0.0.0 port = 5432 #pg端口,默认是5432 max_connections = 2000 #最大连接数,默认100 unix_socket_directories #socket文件的位置,默认在/tmp下面 shared_buffers #数据缓存区,建议值1/4--1/2主机内存,和Oracle的buffer cache类似 maintenance_work_mem #维护工作内存,用于vacuum,create index,reindex等。建议值(1/4主机内存)/autovacuum_max_workers max_worker_processes #总worker数 max_parallel_workers_per_gather #单条QUERY中,每个node最多允许开启的并行计算WORKER数 wal_level #wal级别,版本11+默认是replica wal_buffers #类似Oracle的log buffer checkpoint_timeout #checkpoint时间间隔 max_wal_size #控制wal的最大数量 min_wal_size #控制wal的最小数量 archive_command #开启归档命令,示例:'test ! -f /arch/%f && cp %p /arch/%f' autovacuum #开启自动vacuum
范例: 查看系统配置
postgres=# \d pg_settings; View "pg_catalog.pg_settings" Column | Type | Collation | Nullable | Default -----------------+---------+-----------+----------+--------- name | text | | | setting | text | | | unit | text | | | category | text | | | short_desc | text | | | extra_desc | text | | | context | text | | | vartype | text | | | source | text | | | min_val | text | | | max_val | text | | | enumvals | text[] | | | boot_val | text | | | reset_val | text | | | sourcefile | text | | | sourceline | integer | | | pending_restart | boolean | | postgres=# select name,short_desc,setting from pg_settings where name like 'listen_addresses'; name | short_desc | setting ------------------+----------------------------------------------------+--------- listen_addresses | Sets the host name or IP address(es) to listen to. | 0.0.0.0 #查看运行时参数 postgres=# show listen_addresses; 0.0.0.0
范例:查看和修改配置
postgres=# show timezone; Etc/UTC (1 row) #动态修改配置 postgres=# set timezone="Asia/Shanghai"; postgres=# show timezone; Asia/Shanghai (1 row) #有些参数不支持动态修改 postgres=# set port=1234; ERROR: parameter "port" cannot be changed without restarting the server
范例:postgresql.auto.conf 文件优先于postgresql.conf
[root@ubuntu2004 ~]#vim /pgsql/data/postgresql.auto.conf # Do not edit this file manually! # It will be overwritten by the ALTER SYSTEM command. port = 1234 [root@ubuntu2004 ~]#vim /pgsql/data/postgresql.conf port = 4321 [root@ubuntu2004 ~]#systemctl restart postgresql.service [root@ubuntu2004 ~]#ss -ntlp|grep postmaster postgres@ubuntu2004:~$ psql -p1234 postgres=# show port; 1234
pg_ident.conf
pg_ident.conf是用户映射配置文件。结合pg_hba.conf文件,method为ident可以用特定的操作系统用户以指定的数据库用户身份登录数据库。
这个文件记录着与操作系统用户匹配的数据库用户,如果某操作系统用户在本文 件中没有映射用户,则默认的映射数据库用户与操作系统用户同名。比如,服务 器上有名为user1的操作系统用户,同时数据库上也有同名的数据库用户user1, user1登录操作系统后可以直接输入psql,以user1数据库用户身份登录数据库且 不需密码
如果操作系统用户和数据库用户不同名,可以用下面格式进行映射
#pg_ident.conf如下实现操作系统test用户映射为数据库用户dba #MAPNAME SYSTEM-USERNAME PG-USERNAME map1 test dba #pg_hba.conf如下: #TYPE DATABASE USER CIDR-ADDRESS METHOD local all all ident map=map1
范例: 操作系统用户和数据库用户同名
[root@ubuntu2004 ~]#useradd -s /bin/bash -m dba [root@ubuntu2004 ~]#su - postgres postgres@ubuntu2004:~$ psql postgres=# create user dba WITH PASSWORD '123456'; [root@ubuntu2004 ~]#vim /pgsql/data/pg_hba.conf local all all ident #如果本地操作系统账号和数据库账号同名,就可以自动关联登录 [root@ubuntu2004 ~]#pg_ctl -D /pgsql/data restart #测试连接 [root@ubuntu2004 ~]#su - dba dba@ubuntu2004:~$ psql postgres postgres=>
范例: 操作系统用户和数据库用户不同名
[root@ubuntu2004 ~]#su - postgres postgres@ubuntu2004:~$ psql postgres=# create user dba WITH PASSWORD '123456'; [root@ubuntu2004 ~]#useradd -s /bin/bash -m test [root@ubuntu2004 ~]#vim /pgsql/data/pg_ident.conf # MAPNAME SYSTEM-USERNAME PG-USERNAME map1 test dba [root@ubuntu2004 ~]#vim /pgsql/data/pg_hba.conf local all all ident map=map1 #在此行上面加上面行 local all all trust [root@ubuntu2004 ~]#pg_ctl -D /pgsql/data restart #测试连接 [root@ubuntu2004 ~]#su - test #直接登录失败 test@ubuntu2004:~$ psql psql: error: connection to server on socket "/tmp/.s.PGSQL.5432" failed: FATAL: Peer authentication failed for user "test" #需要指定映射的数据库的用户和数据库 test@ubuntu2004:~$ psql -Udba postgres postgres=>
数据文件
PostgreSQL中的每个索引和表都是一个单独的文件,称为Segment。默认是每个大于1G的Segment会被分割pg_class.efilenode.1这样的文件。 Segment的大小可以在initdb时通过选项—with-segsize=SEGSIZE指定
注意:truncate表之后relfilenode会变。对应的物理文件名字也会变。
Segment 物理位置
$PGDATA/BASE/DATABASE_OID/PG_CLASS.RELFILENODE
范例: 数据文件路径
[root@ubuntu2004 postgresql-14.2]#./configure --help|grep size --with-blocksize=BLOCKSIZE set table block size in kB [8] --with-segsize=SEGSIZE set table segment size in GB [1] --with-wal-blocksize=BLOCKSIZE set WAL block size in kB [8] #查看数据目录路径 testdb=# show data_directory; /pgsql/data #查看数据库的OID testdb=# select oid,datname from pg_database; #查看表的node testdb=# select relfilenode from pg_class where relname='tb1'; relfilenode 16397 #查看指定表的目录路径 testdb=# select pg_relation_filepath('tb1'); base/16384/16397 postgres@ubuntu2004:~$ ls -l $PGDATA/base/16384/16397 -rw------- 1 postgres postgres 8192 May 16 14:26 /pgsql/data/base/16384/16397
控制文件
控制文件存放了数据库当前的状态,存放在PGDATA/global/pg_control
#PG14版的控制文件 postgres@ubuntu2004:~$ file /pgsql/data/global/pg_control /pgsql/data/global/pg_control: PGP Secret Sub-key - #PG12版的控制文件 postgres@ubuntu2004:~$ file /pgsql/data/global/pg_control /pgsql/data/global/pg_control: data #查看控制文件内容 postgres@ubuntu2004:~$ pg_controldata $PGDATA pg_control version number: 1700 Catalog version number: 202406281 Database system identifier: 7434814718768345198 Database cluster state: in production #数据库当前状态 pg_control last modified: Mon 11 Nov 2024 09:07:11 PM EST Latest checkpoint location: 0/D173AF8 Latest checkpoint's REDO location: 0/D173AF8 Latest checkpoint's REDO WAL file: 00000001000000000000000D #预写日志 Latest checkpoint's TimeLineID: 1 Latest checkpoint's PrevTimeLineID: 1 Latest checkpoint's full_page_writes: on Latest checkpoint's NextXID: 0:802 Latest checkpoint's NextOID: 32827 Latest checkpoint's NextMultiXactId: 1 Latest checkpoint's NextMultiOffset: 0 Latest checkpoint's oldestXID: 730 Latest checkpoint's oldestXID's DB: 1 Latest checkpoint's oldestActiveXID: 0 Latest checkpoint's oldestMultiXid: 1 Latest checkpoint's oldestMulti's DB: 1 Latest checkpoint's oldestCommitTsXid:0 Latest checkpoint's newestCommitTsXid:0 Time of latest checkpoint: Mon 11 Nov 2024 09:07:11 PM EST Fake LSN counter for unlogged rels: 0/3E8 Minimum recovery ending location: 0/0 Min recovery ending loc's timeline: 0 Backup start location: 0/0 Backup end location: 0/0 End-of-backup record required: no wal_level setting: replica wal_log_hints setting: off max_connections setting: 1000 max_worker_processes setting: 8 max_wal_senders setting: 10 max_prepared_xacts setting: 0 max_locks_per_xact setting: 64 track_commit_timestamp setting: off Maximum data alignment: 8 Database block size: 8192 Blocks per segment of large relation: 131072 WAL block size: 8192 Bytes per WAL segment: 16777216 Maximum length of identifiers: 64 Maximum columns in an index: 32 Maximum size of a TOAST chunk: 1996 Size of a large-object chunk: 2048 Date/time type storage: 64-bit integers Float8 argument passing: by value Data page checksum version: 0 Mock authentication nonce: c8438a61af4513aba125b7c2e39f2cf9cea0545b5eaf729c7b0f6d8afb7cf31b
日志文件(重点)
日志种类
- 运行日志: $PGDATA/log(pg10之前为$PGDATA/pg_log),默认不存在,需要开启配置项 logging_collector
- 在线重做日志:$PGDATA/pg_wal(pg10之前为$PGDATA/pg_xlog)
- 事务提交日志:$PGDATA/pg_xact (pg10之前为$PGDATA/pg_clog)
- 服务器日志:可以在启动的时候指定:pg_ctl start -l ./logfile
运行日志
- 运行日志配置项
logging_collector:这个参数启用日志收集器,它是一个捕捉被发送到stderr的日志消息的后台进程,并且它会将这些消息重定向到日志文件中;默认是OFF,修改参数需要重启。 log_destination:有三种输出方法,stderr,csvlog,syslog;在windows上还支持eventlog。默认是stderr,如果使用csvlog的话,logging_collector必须开启。也可以同时使用csvlog和stderr,会记录两种格式的日志。 log_directory:指定日志的存放位置,默认是$PGDATA/log log_filename:日志的命名格式,默认是postgresql-%Y-%m-%d_%H%M%S.log。支持strftime格式 log_file_mode:当logging_collector被启用时,这个参数设置日志文件的权限(在Windows上这个参数将被忽略)。这个参数值应当是一个数字形式的模式,它可以被chmod和umask系统调用接受(要使用通常的十进制格式,该数字必须以一个0(零)开始)。默认的权限是0600,表示只有服务器拥有者才能读取或写入日志文件。其他常用的设置是0640,它允许拥有者的组成员读取文件。不过要注意你需要修改 log_directory为将文件存储在集簇数据目录之外的某个位置,才能利用这个设置。 log_rotation_age:当logging_collector被启用时,这个参数决定一个个体日志文件的最长生命期。当这些分钟过去后,一个新的日志文件将被创建。将这个参数设置为零将禁用基于时间的新日志文件创建。 log_rotation_size:当logging_collector被启用时,这个参数决定一个个体日志文件的最大尺寸。当这么多千字节被发送到一个日志文件后,将创建一个新的日志文件。将这个参数设置为零将禁用基于尺寸的新日志文件创建。 log_truncate_on_rotation:默认为off,设置为on的话,如果新建了一个同名的日志文件,则会清空原来的文件,再写入日志,而不是在后面追加。 log_min_messages:控制哪些消息级别被写入到服务器日志。有效值是DEBUG5、DEBUG4、 DEBUG3、 DEBUG2、DEBUG1、INFO、NOTICE、WARNING、 ERROR、LOG、FATAL和 PANIC。每个级别都包括以后的所有级别。级别越靠后,被发送的消息越少。默认值是WARNING。 log_min_error_statement:控制哪些导致错误情况的 SQL语句被记录在服务器日志中。。默认值是ERROR,要有效地关闭记录错误语句,将这个参数设置为PANIC。 log_min_duration_statement:相当于mysql的long_query_time,记录慢SQL,超过这个时间的SQL将会被记录到日志里。以ms为单位 log_checkpoints:导致检查点和重启点被记录在服务器日志中。一些统计信息也被包括在日志消息中,包括写入缓冲区的数据和写它们所花的时间。 log_connections:导致每一次尝试对服务器的连接被记录,客户端认证的成功完成也会被记录。只有超级用户能在会话开始时更改这个参数,在会话中它不能被更改。默认为off。 log_disconnections:导致会话终止也会被记录。日志输出提供的信息类似于log_connections,不过还外加会话的持续时间。只有超级用户能在会话开始时更改这个参数,在会话中它不能被更改。默认 为off。 log_duration:导致每一个完成的语句的持续时间被记录。默认值是off。如果log_duration为on并且log_min_duration_statement为正值,所有持续时间都将被记录,但是只有超过阈值的语句才会被记录查询文本。这种行为有助于在高负载安装中收集统计信息。 log_error_verbosity:有效值是TERSE、DEFAULT和VERBOSE,默认值是default,控制每条日志信息的详细程度,VERBOSE输出包括SQLSTATE错误码,以及产生错误的源代码文件名、函数名和行号 log_hostname:默认情况下,连接日志消息只显示连接主机的 IP地址。打开这个参数将导致也记录主机名。注意根据你的主机名解析设置,这可能会导致很微小的性能损失。 log_line_prefix:设置日志输出格式(能够记录时间,用户名称,数据库名称,客户端IP和端口,方便定位问题)默认值是'%m [%p] ',它记录时间戳和进程ID。 log_lock_waits:控制当一个会话为获得一个锁等到超过deadlock_timeout时,是否要产生一个日志消息。这有助于决定是否锁等待造成了性能低下。默认值是off log_statement:控制哪些 SQL 语句被记录。有效值是 none (off)、ddl、mod和all(所有语句)。默认值是none log_replication_commands:每一个复制命令都被记录在服务器日志中。 log_temp_files:控制记录临时文件名和尺寸。临时文件可以被创建用来排序、哈希和存储临时查询结果。一个零值记录所有临时文件信息,而正值只记录尺寸大于或等于指定千字节数的文件。默认设置为-1,它禁用这种记录。 log_timezone:设置在服务器日志中写入的时间戳的时区。默认值是GMT。
- 将csv格式运行日志存储至数据库
postgres@ubuntu2004:~$ vim /pgsql/data/postgresql.conf #修改下面两行 log_destination = 'csvlog' logging_collector = on postgres@ubuntu2004:~$ pg_ctl restart postgres@ubuntu2004:~$ psql #先创建对应的表结构,只适用于PG12 testdb=#CREATE TABLE pg_log( log_time timestamp(3) with time zone, user_name text, database_name text, process_id integer, connection_from text, session_id text, session_line_num bigint, command_tag text, session_start_time timestamp with time zone, virtual_transaction_id text, transaction_id bigint, error_severity text, sq1_state_code text, message text, detail text, hint text, interna7_query text, interna7_query_pos integer, context text, query text, query_pos integer, location text, application_name text, PRIMARY KEY (session_id,session_line_num) ); #将csv文件中的日志导入到表中 testdb=# copy pg_log from '/pgsql/data/log/postgresql-2020-10-07_090454.csv' with csv;
在线WAL日志
Online WAL(WRITE-AHEAD LOG)日志功能是为了保证崩溃后的安全,如果系统崩溃,可以"重放"从最后一次检查点以来的日志项来恢复数据库的一致性。但是也存在日志膨胀的问题,相当于MySQL的事务日志redolog
参考文档: https://www.postgresql.org/docs/17/runtime-config-wal.html
Online WAL 日志文件位置
wal文件存放在$PGDATA/pg_wal下。PG10之前为pg_xlog
设置Online WAL日志的大小
#初始化实例时,可以指定单个WAL文件的大小,默认16M initdb --wal-segsize=SIZE #WAL日志总的大小默认值 max_wal_size = 1GB min_wal_size = 80MB max_wal_size (integer) #在自动WAL检查点之间允许WAL增长到的最大尺寸。这是一个软限制,在特殊的情况下WAL尺寸可能会超过 max_wal_size,例如在重度负荷下、 archive_command失败或者高的wal keep_segments设置。如果指定值时没有单位,则以兆字节为单位。默认为1GB。增加这个参数可能导致崩溃 恢复所需的时间。这个参数只能在postgresql.conf或者服务器命令行中设置。 min_wal_size (integer) #只要WAL磁盘用量保持在这个设置之下,在检查点时旧的WAL文件总是被回收以便未来使用,而不是直接被 删除。这可以被用来确保有足够的WAL空间被保留来应付WAL使用的高峰,例如运行大型的批处理任务。 如果指定值时没有单位,则以兆字节为单位。默认是80MB。这个参数只能在postgresql.conf 或者服务器命令行中设置。 #注意:PG9.4之前版本中的checkout_segments可以指定在自动的WAL检查点之间的日志文件段的最大数量 (通常每个段16兆字节)。缺省是3。从PG9.5开始淘汰此配置项,用max_wal_size和min_wal_size代替
范例:创建一个表,10万条记录
\c hellodb create table emp(id int, name char(10), age int); create or replace function for_loop() returns void as $$ begin for i in 1..100000 loop INSERT INTO emp("id", "name", "age") VALUES (i, 'user1', 20); end loop; end; $$ language plpgsql; select for_loop(); select count(*) from emp; #WAL日志总的大小默认值 hellodb=# show max_wal_size; 1GB hellodb=# show min_wal_size; 80MB
LSN和Online WAL文件命名格式
LSN: Log Sequence Number 用于记录WAL文件当前的位置,这是WAL日志唯一的、全局的标识。
WAL日志中写入是有顺序的,所以必须得记录WAL日志的写入顺序。而LSN就是负责给每条产生的WAL日志记录唯一的编号
WAL 日志LSN编号规则:
高32位/低32位
WAL 文件名称为16进制的24个字符组成,每8个字符一组
每组的意义如下:
00000001 00000000 00000001 时间线 逻辑id 物理id 其中前8位:00000001表示timeline 中间8位:00000000表示logid,即LSN高32位 最后8位:00000001表示logseg,即LSN低32位/(2**24)的值,即低32位中最高8位,16进制的高2位
范例:
#查看当前LSN postgres=# select pg_current_wal_lsn(); 0/610001C0 #查看当前LSN对应的WAL日志文件 postgres=# select pg_walfile_name(pg_current_wal_lsn()); 000000010000000000000061
查看LSN和WAL文件对应关系
范例:
#查看当前事务ID postgres=# select txid_current(); txid_current | 610 #查看当前LSN号 postgres=# select pg_current_wal_lsn(); pg_current_wal_lsn | 0/610001C0 #61代理文件名,0001C0为事件号16进制 #查看当前LSN对应的WAL日志文件 #WAL日志文件中的最后8位的logseg前6位始终是0,最后两位是LSN的低32位的前两位。如上例中logseg最后两位是61,LSN低32位的前两位也是61。 postgres=# select pg_walfile_name(pg_current_wal_lsn()); pg_walfile_name | 000000010000000000000061 #查看当前WAL日志偏移量 #LSN在WAL日志文件中的偏移量即LSN低32位中后24位对应的十进制值。如上面0001C0对应十进制即下面的448 postgres=# select pg_walfile_NAME_OFFSET(pg_current_wal_lsn()); pg_walfile_name_offset | (000000010000000000000061,448) #事件号16进制转换 postgres@debian:/pgsql/data$ echo 'obase=16; 448' |bc 1C0 #按时间排序显示WAL文件名 postgres=#select * from pg_ls_waldir() order by modification asc;
切换WAL日志
#默认WAL文件达到16M,自动切换另一个WAL postgres=# select pg_switch_wal(); #PG10版本前用下面命令 postgres=# select pg_switch_xlog();
查看WAL文件内容
命令pg_waldump可以查看WAL日志的具体内容
注意: pg_waldump执行结果中tx:后面的数字是txid,即事务ID,WAL中同一个事务的记录此值是相同的
[root@ubuntu2004 ~]#pg_waldump /pgsql/data/pg_wal/000000010000000000000022
创建恢复点
#事先创建恢复点,将来可用它进行还原,相当于快照 postgres=# select pg_create_restore_point( 'test-restore-point');
归档WAL日志
归档日志记录的是checkpoint前的WAL日志,即数据的历史日志,即把pg_wal里面的在线日志备份出来,功能上归档日志相当于MySQL的二进制日志
生产环境中为了保证数据高可用性,通常需要开启归档,当系统故障后可以通过归档的日志文件对数据进行恢复
#配置归档需要开启如下参数: wal_level = replica #该参数的可选的值有minimal,replica和logical,wal的级别依次增高,在wal的信息也越多。由于 minimal这一级别的wal不包含从基础的备份和wal日志重建数据的足够信息,在该模式下,无法开启wal日志归档 #从PostgreSQL10开始,默认使用的replica此级别,也建议使用此级别,之前版本默认是最小级别minimal archive_mode = on #上述参数为on,表示打开归档备份,可选的参数为on,off,always 默认值为off,所以要手动打开,需要重启服务生效 #在 PostgreSQL中配置归档的方法是配置参数archive_command,参数的配置值可以是一个Unix命令,此命令把WAL日志文档拷贝到其他地方 archive_command = '[ ! -f /archive/%f ] && cp %p /archive/%f' archive_command = 'DIR=/archive/`date +%%F`;[ -d $DIR ] || mkdir -p $DIR;cp %p $DIR/%f' #该参数的默认值是一个空字符串,值可以是一条shell命令或者一个复杂的shell脚本 #用"%p"表示将要归档的wal文件包含完整路径的信息的文件名 #用"%f"代表不包含路径信息的wal文件的文件名 #注意:wal_level和archive_mode参数修改都需要重新启动数据库才可以生效。而修改archive_command则不需要。 #无论当时是否需要归档,这要建议将上面两个参数开启
示例:本地归档备份
archive_mode = on archive_command = 'cp %p /pgsql/backup/%f' #上面的命令中“archive_mode = on”表示打开归档备份 #参数archive_command的配置值是一个Unix的cp命令 #命令中的%p表示在线WAL日志文件的全路径名称 #%f表示不包括路径的WAL日志文件名。
在实际执行时备份时,PostgreSQL会把%p替换成实际在线WAL日志文件的全路径名,并把%f替换成不包括路径的WAL日志名。
使用操作系统命令 scp还可以把WAL日志拷贝到其他机器上,从而实现对归档日志进行远程备份
示例: 远程归档备份
archive_mode =on
archive_command = 'scp %p [email protected]:/pgsql/backup/%f'
使用上面拷贝WAL文件的方式来同步主、备数据库之间数据时,备库会落后主库 一个WAL日志文件,具体落后多长时间取决于主库上生成一个完整的WAL文件所需 要的时间。
范例: 启用归档
#配置参数 vim /pgsql/data/postgresql.conf wal_level = replica #此为默认值可以不做修改 #- Archiving - archive_mode = on #archive_command = 'DIR=/archive/`date +%F`;[ -d $DIR ] || mkdir -p $DIR;cp %p $DIR/%f' archive_command = 'DIR=/archive/`date +%%F`;[ -d $DIR ] || mkdir -p $DIR;cp %p $DIR/%f' mkdir /archive chown -R postgres. /archive #重启数据库 pg_ctl restart -mf #插入数据,查看归档 \c testdb create table t1 (id int); insert into t1 values (generate_series(1,100000)); select ctid,* from t1; #说明:ctid表示数据所在的数据块的编号及位移 #比如(0,1) 表示第0个块中的第一条记录,块从0开始编号,记录从1开始编号 #触发检查点 checkpoint #切换日志,即使当前日志文件不再使用,而切换使用下一个日志文件,如果开启归档,会自动触发对当前日志文件的归档 select pg_switch_wal(); #查看 select pg_walfile_NAME_OFFSET(pg_current_wal_lsn()); #检查归档 tree /archive/ /archive/ └── 2020-07-18 └── 000000010000000000000001
范例: 远程归档
#在10.0.0.200的备份服务器上创建目录 postgres@ubuntu2004:~$ mkdir /pgsql/backup/ #在postgreSQL服务器上实现到10.0.0.200备份服务器上的key验证 postgres@ubuntu2004:~$ ssh-keygen postgres@ubuntu2004:~$ ssh-copy-id 10.0.0.200 #在postgreSQL服务器上修改配置 postgres@ubuntu2004:~$ vim /pgsql/data/postgresql.conf # - Archiving - archive_mode = on archive_command = 'scp %p 10.0.0.200:/pgsql/backup/%f' postgres@ubuntu2004:~$ pg_ctl -D /pgsql/data restart #在postgreSQL服务器上执行大量数据更新 postgres@ubuntu2004:~$ cat for_loop.sql \c hellodb create table emp(id int,name char(10),age int); create or replace function for_loop() returns void as $$ begin for i in 1..1000000 loop INSERT INTO emp("id","name", "age") VALUES (i,'wang',20); end loop; end; $$ language plpgsql; select for_loop(); select count(*) from emp; postgres@ubuntu2004:~$ psql -f for_loop.sql #在10.0.0.200的备份服务器上可看到日志的备份出现 postgres@ubuntu2004:~$ ls /pgsql/backup/ 000000010000000000000001 000000010000000000000003 000000010000000000000005 000000010000000000000007 000000010000000000000009 000000010000000000000002 000000010000000000000004 000000010000000000000006 000000010000000000000008 00000001000000000000000A
PostgreSQL 备份恢复
备份说明
防止数据丢失的最重要方法就是备份。这些数据丢失有的是因硬件损坏导致的,有的是因人为原因(如误操作)而导致的,也有因为应用程序的bug而误删数据等情况。
备份的内容包括:
- 数据(配置文件)
- 归档WAL日志
- 表空间目录
数据库备份方式
- 逻辑备份: 适用于跨版本和跨平台的备份恢. 类似于mysqldump
- 物理备份: 适用于小版本的恢复,但不支持跨平台和大版本. 磁盘文件
逻辑备份
PostgreSQL提供了pg_dump、pg_dumpall 命令进行数据库的逻辑备份。
两者的功能差不多,只是pg_dumpall是将一个PostgreSQL数据库集群全部转储到一个脚本文件中,而pg_dump命令可以选择一个数据库或部分表进行备份。
另外利用COPY命令也能对表和SQL子集进行备份,实现表的还原
pg_dump和pg_dumpall
pg_dump是PostgreSQL提供的一个非常有用的数据库备份工具。它甚至可以在数据库正在使用的时候进行完整一致的备份。pg_dump工具执行时,可以将数据库备份成一个文本文件或归档文件,该文件中实际上包含了多个CREATE和INSERT语句,使用这些语句可以重新创建表和插入数据。
pg_dumpall工具可以存储一个数据库集群里的所有数据库到一个脚本文件。本质上pg_dumpall是通过对数据库集群里的每个数据库调用pg_dump实现这个功能。
pg_dumpall还可以备份出所有数据库公用的全局元数据对象。这些信息包括:数据库用户和组,密码以及适用于整个数据库的访问权限。而pg_dump并不保存这些对象。
pg_dump可生成归档格式的备份文件,然后与pg_restore配合使用,从而提供一种灵活的备份和恢复机制。
pg_dump可以将整个数据库备份到一个归档格式的备份文件中,而pg_restore则可从这个归档格式的备份文件中选择性地恢复部分表或数据库对象。归档格式的备份文件又分为两种,最灵活的输出文件格式是“custom”自定义格式(使用命令项参数-Fc来指定),它允许对归档元素进行选取和重新排列,并且默认时是压缩的;另一种格式是tar格式(使用命令项参数-Ft来指定),这种格式的文件不是压缩的,并且加载时不能重排列,但是它也很灵活,可以用标准UNIX下的 tar工具进行处理。
pg_dumpall只支持文本格式 pg_dump 的具体使用语法如下:
pg_dump [connection-option...] [option...] [dbname] #连接选项和psql基本相同,pg_dump连接选项的参数如下 -h host或--host=host #指定运行服务器的主机名。如果以斜杠开头,则被用作到UNIX域套接字的路径。默认情况下,如果设置了SPGHOST 环境变量,则从此环境变量中获取,否则尝试一个UNIX域套接字连接。 -p port或--port=port #指定服务器正在侦听的TCP端口或本地UNIX域套接字文件的扩展。 默认情况下,如果设置了$PGPORT环境变量,则从此环境变量中获取,否则取值为默认端口5432(编译时可以改变这个默认端口)。 -U username或--username=username指定要连接的用户名。 -w或--no-password #从不提示密码。密码可以通过其他方式如~/.pgpass文件获取 dbname #指定连接的数据库名,实际上也是要备份的数据库名。如果没有使用这个参数,则使用环境变量 SPGDATABASE。如果SPGDATABASE 也没声明,那么可使用发起连接的用户名。 #pg_dump专用选项 -a或--data-only #这个选项只是对纯文本格式有意义。只输出数据,不输出数据定义的SQL语句。 -b或--blobs #在转储中是否包含大对象。除非指定了选择性转储的选项--schema、--table、--schema-only开关, 否则默认会转储大对象。此选项仅用于选择性转储时控制是否转储大对象。 -c或一clean #这个选项只对纯文本格式有意义。指定输出的脚本中是否生成清理该数据库对象语句(如drop table命令)。 -C或--create #这个选项只对纯文本格式有意义。指定脚本中是否输出一条create database语句和连接到该数据库的语句。一般在备份的源数据库与恢复的目标数据库的名称一致时,才指定这个参数。 -E encoding或--encoding=encoding #以指定的字符集编码创建转储。默认转储是依据数据库编码创建的。 如果不指定此参数,可以通过设置环境变量SPGCLIENTENCODING达到相同的目的 -f file --file=file #输出到指定的文件中。如果没有指定此参数,则输出到标准输出中。 -F format或--format=format #选择输出的格式。format可以是p、c或t。 p是plain 的意思,为纯文本SQL 脚本文件的格式,这是默认值。大库不荐 c是custom的意思,以一个适合pg_restore使用的自定义二进制格式输出并归档。这是最灵活的输出格式,在该格式中允许手动查询并且可以在pg restore恢复时重排归档项的顺序。该格式默认是压缩的。 t是tar的意思,以一个适合输人pg_restore的 tar格式输出并归档。该输出格式允许手动选择并且在恢复时重排归档项的顺序,但是这个重排序是有限制的,比如,表数据项的相关顺序在恢复时不能更改。同时, tar格式不支持压缩,并且对独立表的大小限制为8GB。 -n schema或--schema=schema #只转储匹配schema的模式内容,包括模式本身以及其中包含的对象。 如果没有声明这个选项,所有目标数据库中的非系统模式都会被转储出来。可以使用多个-n选项指定多个模式。 -t table或--table=table #只转储出匹配table的表、视图、序列。可以使用多个-t选项匹配多个表。同样table参数将按照psql 的\d命令的规则被解释为匹配模式,因此可以使用通配符匹配多个模式。在使用通配符时,最好用引号进行界定,以防止shell将通配符进行扩展。 -T table或--exclude-table=table #不转储任何匹配table模式的表。模式匹配规则与t完全相同。 可以指定多个-T以排除多种匹配的表。如果同时指定了-t和-T,那么将只转储匹配-t但不匹配-T的表。如果出现了-T而未出现-t,那么匹配-T的表不会被转储。
使用pg_dump 的自定义备份或tar类型的备份需要使用pg_restore工具来恢复。
pg_restore命令的格式如下:
pg_restore [connection-option...] [option...] [filename] pg_restore 的连接参数与pg_dump基本相同,如下 -h host或--host=host -p port或--port=port -U username或--username=username-w或--no-password -W或--password -d dbname或--dbname=dbname #不同之处在于,pg_restore使用-d的参数来连接指定的数据库并恢复数据至此数据库 filename #要恢复的备份文件的位置。如果没有声明,则使用标准输入。 -a或--data-only #只恢复数据,而不恢复表模式(数据定义)。 -c或--clean #创建数据库对象前先清理(删除)它们。 -C或--create #在恢复数据库之前先创建它。如果出现了这个选项,和-d在一起的数据库名只是用于发出最初的CREATE DATABASE命令,所有数据都恢复到名字出现在归档中的数据库中。 -F format 或--format=format #指定备份文件的格式。pg_restore可自动判断格式,如果一定要指定,它可以是t或c之一。 t表示 tar,指备份文件是一个tar文件。 c表示custom,备份的格式是来自pg_dump的自定义格式,这是最灵活的格式,因为它允许对数据重新排序,也允许重载表模式元素,默认这个格式是压缩的。 -n namespace或--schema=schema #只恢复指定名字的模式里的定义和/或数据。这个选项可以和-t选项一起使用,只恢复一个表的数据。 -t table或--table=table #只恢复指定的表的定义和/或数据。可以与-n参数(指定schema)联合使用。
范例:
#备份单个数据库test中的所有表到指定目录, 注意,这样写没有创建库的SQL pg_dump -U postgres -f /backup/test_backup test #备份test数据库中的t1表和t2表∶ pg_dump -U postgres -t t1 -t t2 -f /backup/test_backup_t1_t2 test
范例
#备份指定数据库,注意,没有创建库的SQL pg_dump -d testdb > /backup/testdb.sql #恢复过程 #注意:事先需要存在数据库,且删除所有表后才能恢复 psql -d testdb < /backup/testdb.sql
范例:使用pg_dumpall备份所有的数据库,其操作和pg_dump类似
#备份全部数据库,每个数据库都需要输入密码,有N个数据库,就需要输入N次密码 pg_dumpall -U postgres -f full_backup.sql gp_dumpall > full_backup.sql #恢复 psql < full_backup.sql
范例: 使用pg_dump 和pg_restore备份还原
#当连接的是一个本地数据库,并不需要密码时,要对数据库hellodb进行备份,备份文件的格式是脚本文件格式 #有创建库的SQL pg_dump -C hellodb > hellodb.sql #使用pg_dump也可以备份一个远程的数据库,如下面的命令备份10.0.0.200机器上的hellodb数据库 pg_dump -h 10.0.0.200 -U postgres -C hellodb > hellodb.sql #如果想生成的备份文件格式为自定义格式,可以使用下面的命令: pg_dump -Fc -h 10.0.0.200 -Upostgres hellodb > hellodb.dump file hellodb.dump hellodb.dump: PostgreSQL custom database dump - v1.14-0 #定制的格式 #查看备份的项目 pg_restore -l hellodb.dump [root@rocky8 ~]#pg_restore -l /backup/hellodb.dump ; ; Archive created at 2022-02-16 15:21:03 CST ; dbname: hellodb ; TOC Entries: 34 ; Compression: -1 ; Dump Version: 1.14-0 ; Format: CUSTOM ; Integer: 4 bytes ; Offset: 8 bytes ; Dumped from database version: 14.2 ; Dumped by pg_dump version: 14.2 #把上述备份文件恢复到另一个数据库hellodb2中 #先创建数据库才能恢复 psql -U postgres -h 10.0.0.200 -c "create database hellodb2" #还原 pg_restore -h 10.0.0.200 -U postgres -d hellodb2 hellodb.dump #只备份数据库hellodb中的表students pg_dump -h 10.0.0.200 -Upostgres -t students hellodb > students.sql #备份schema1模式中所有以job开头的表,但是不包括job_log表 pg_dump -t 'schema1.job*' -T schema1.job_log hellodb > schema1.emp.sql #备份所有数据库对象,但是不包括名字以_log结尾的表 pg_dump -T '*log' hellodb > log.sql #先从10.0.0.200备份数据库hellodb,然后恢复到10.0.0.100机器上 pg_dump -h 10.0.0.200 -U postgres hellodb -Fc > hellodb.dump pg_restore -h 10.0.0.100 -U postgres -C -d postgres hellodb.dump #在pg_restore命令中,-d中指定的数据库可以是10.0.0.200机器上实例中的任意数据库,pg_restore仅用该数据库名称进行连接, -C 表示先执行CREATE DATABASE命令创建hellodb数据库,然后再重新连接到 hellodb数据库,最后把备份的表和其他对象建到hellodb数据库中 #将备份出来的数据重新加载到一个新建的不同名称的数据库hellodb2中 createdb -T template0 hellodb2 pg_restore -d hellodb2 hellodb.dump #注意,上面的命令从template0而不是template1创建新数据库,确保干净。这里没有使用-C选项,而是直接连接到将要恢复的数据库上。
COPY命令实现备份还原
帮助文档 http://www.postgres.cn/docs/12/sql-copy.html
COPY命令支持在PostgreSQL表和文件之间交换数据。
COPY TO把一个表的所有内容都拷贝到一个文件,而COPY FROM从一个文件里拷贝数据到一个表里(把数据附加到表中已经存在的内容里)。COPY TO还能拷贝SELECT查询的结果。
如果声明了一个字段列表,COPY将只在文件和表之间拷贝已声明字段的数据。如果表中有任何不在字段列表里的字段,那么COPY FROM将为那些字段插入缺省值。
带文件名的COPY指示PostgreSQL服务器直接从文件中读写数据。 如果声明了文件名,那么服务器必须可以访问该文件,而且文件名必须从服务器的角度声明。 如果使用了PROGRAM选项,则服务器会从指定的这个程序进行输入或是写入该程序作为输出。 如果使用了STDIN或STDOUT选项,那么数据将通过客户端和服务器之间的连接来传输。
命令:
#导出 COPY { table_name [ ( column_name [, ...] ) ] | ( query ) } TO { 'filename' | PROGRAM 'command' | STDOUT } [ [ WITH ] ( option [, ...] ) ] #导入: COPY table_name [ ( column_name [, ...] ) ] FROM { 'filename' | PROGRAM 'command' | STDIN } [ [ WITH ] ( option [,...] ) ] #常用参数说明: table_name 现存表的名字(可以有模式修饰) column_name 可选的待拷贝字段列表。如果没有声明字段列表,那么将使用所有字段 query 一个必须用圆括弧包围的SELECT或VALUES命令,其结果将被拷贝 filename 输入或输出文件的路径名。输入文件名可以是绝对或是相对的路径,但输出文件名必须是绝对路径。 Windows用户可能需要使用E”字符串和双反斜线作为路径名称 PROGRAM 需执行的程序名。在COPY FROM命令中,输入是从程序的标准输出中读取,而在COPY TO中,命令的输出会作为程序的标准输入。 注意,程序一般是在命令行界面下执行,当用户需要传递一些变量给程序时,如果这些变量的来源不是可靠 的,用户必须小心过滤处理那些对命令行界面来说是有特殊意义的字符。 基于安全的原因,最好是使用固定的命令字符串,或者至少是应避免直接使用用户输入(应先过滤特殊字符) STDOUT 声明输入将写入客户端应用 FORMAT 选择被读或者写的数据格式:text、csv(逗号分隔值),或者binary。默认是text #注意: copy命令必须在psql命令行执行,执行用户必须为superuser,否则会提示错误如果 用普通用户进行执行,需要在copy前面加入“\”,即 \copy即可
范例: 导出
#示例: COPY students TO '/tmp/students.csv' WITH csv; #可以导出指定的属性: COPY students(stuid,name) TO '/tmp/students.csv' WITH csv; #可以使用select 语句: COPY (select * from students) TO '/tmp/students.csv' WITH csv; #可以指定要导出哪些字段并带有列名: COPY (select stuid,name,age from students) TO '/tmp/students.csv' WITH csv header;
范例:导入
#导入命令基本与导出一样,只是将TO 改为 FROM create table students2 (likestudents); COPY students2 FROM '/tmp/students.csv' WITH csv; #如果导出的时候,指定了header属性,那么在导入的时候,也需要指定: COPY students(stuid,name,age,gender) TO '/tmp/students.csv' WITH csv header; COPY students2(stuid, name,age,gender) FROM '/tmp/students.csv' WITH csv header;
物理备份
生产用的较多
物理备份分为冷备份和热备份
冷备份:最简单的物理备份就是冷备份,也就是把数据库停止,然后把数据库的PGDATA目录拷贝出来即可。
由于PostgreSQL把与数据库实例有关的配置文件和数据文件都放在$PGDATA目录下,所以PostgreSQL做冷备份很简单
- 热备份:不停止数据库的数据库备份,称之为热备份或在线备份。在PostgreSQL中通常的热备份方法有两种。
- 第一种方法:使用数据库的PITR方法利用pg_basebackup工具进行热备份
- 第二种方法:使用文件系统或块设备级别的快照功能完成备份。因为使用了快照,所以也能让备份出来的数据库与原数据库一致。
热备份流程
- 以数据库超级用户身份连接到数据库,发出命令: SELECT pgstart_backup ( 'label'); pg_start_backup()主要做了以下两个工作:
- 设置写日志标志为:XLogCtl->Insert.forcePageWrites =true,也就是把这个标志设置为true后,数据库会把变化的整个数据块都记录到数据库中,而不仅仅是块中记录的变化。
- 强制发生一次checkpoint点。
- 执行备份。使用任何方便的文件系统工具比如tar,或直接把数据目录复制下来。这些操作过程中既不需要关闭数据库,也不需要停止数据库的任何操作。
- 再次以数据库超级用户身份连接数据库,然后发出命令:SELECT pg_stop_backup();
这将中止备份模式并自动切换到下一个WAL段。自动切换是为了让在备份间隔中写人的最后一个WAL段文件可以立即为下次备份做好准备。
- 拷贝备份过程中产生的归档WAL日志文件
范例:冷备份还原
#备份,先停服务 pg_ctl stop mkdir /backup cp -a $PGDATA/ /backup/pgdata-`date +%F` pg_ctl start #还原 pg_ctl stop rm -rf $PGDATA/* cp -a /backup/pgdata-2022-02-16/* $PGDATA/ pg_ctl start
范例: 热备份和还原
psql -c "select pg_start_backup(now()::text);" #以当前时间做为标签 tar -cf /backup/full_`date +%F`.tar /pgsql/data/ psql -c "select pg_stop_backup();" tar -rf /backup/full_`date +%F`.tar /archive/ #还原 pg_ctl stop -D $PGDATA rm -rf $PGDATA tar xf /backup/full_`date +%F`.tar -C /pgsql/data/ pg_ctl start -D $PGDATA
范例: 利用LVM快照做备份
#如果PGDATA是基于LVM存放的,可以执行基于逻辑卷快照备份 [root@ubuntu2004 ~]#systemctl stop postgresql ;lvcreate -n pgdata_snapshot -s - L 1G /dev/mapper/ubuntu--vg-ubuntu--lv; systemctl start postgresql [root@ubuntu2004 ~]#mount /dev/ubuntu-vg/pgdata_snapshot /mnt [root@ubuntu2004 ~]#cp -a /mnt/pgsql/data/ /backup/pgdata-`date +%F` [root@ubuntu2004 ~]#lvremove /dev/ubuntu-vg/pgdata_snapshot
PITR(Point-in-Time Recovery)介绍
PostgreSQL支持类似于MySQL的主从复制的架构,一个Master 服务器database同步数据到多个 Standby Server
PostgreSQL的主从同步是基于WAL(write ahead log预写式日志)日志实现的
PostgreSQL在数据目录的$PGDATA/pg_wal 重做日志目录中始终维护着一个WAL日志文件。这个日志文件用于记录数据库数据文件的每次改变。当初设计这个日志文件的主要目的是为了在数据库异常崩溃后,能够通过重放最后一次checkpoint点之后的日志文件,把数据库推到一致状态。
事实上,这种日志文件机制,也提供了一种数据库热备份方案:在把数据库使用文件系统的方式备份出来的同时把相应的在线WAL日志也备份出来。虽然直接拷贝数据库数据文件会导致拷贝出来的文件不一致 (比如拷贝的多个数据文件不是同一个时间点文件;拷贝一个8KB的数据块时,也存在不一致的情况:假设刚拷贝完前4KB的块,数据库又写了后4KB的块内容,那么所拷贝的块就不是一个完整的数据块),但因为有了WAL日志,即使备份出来的数据块不一致,也可以重放备份开始后的 WAL日志,把备份的内容推到一致状态。
由此可见,有了WAL日志之后,备份数据库时不再需要完美的一致性备份了,备份中任何数据的非一致性都会被重放WAL日志文件进行纠正,所以在备份数据库时可以通过简单的cp命令或tar等拷贝、备份文件来实现数据库的在线备份。
不停地重放WAL日志就可以把数据推到备份结束后的任意一个时间点,这就是基于时间点的备份Point-in-Time Recovery,缩写为PITR。
使用简单的cp命令或其他命令把数据库给在线拷贝出来的备份,被称为基础备份。后续WAL日志的备份与此基础备份构成一个完整备份。把基础备份恢复到另一台主机,然后不停地从原始数据库机器上接收 WAL日志,在新机器上持续重放WAL日志,这样就可以在任何时间内在另一台机器上打开新产生的数据库。它拥有当前数据最新的数据状态。此新主机上的数据库称为Standby 数据库,当前的主数据库出现问现故障无法正常提供服务时,可以把Standby数据库打开提供服务,从而实现高可用。
把WAL日志传送到另一台机器上的方法有两种,一种是通过归档WAL日志实现,一种是被称为流复制的方法
pg_basebackup实现完全备份和还原
pg_basebackup是基于流复制协议可以实现完全备份,并支持热备份
这个工具会把整个数据库实例的数据都拷贝出来,而不只是把实例中的部分(如某个数据库或某些表)单独备份出。
该工具使用replication协议连接到数据库实例上,所以主数据库中的pg_hba.conf必须允许replication连接,也就是在pg_hba.conf中必须有类似下面的内容:
local replication dba trust host replication dba 0.0.0.0/0 md5 #上面的dba为备份的用户名,如果指令all,即所有用户
pg_basebackup的命令行参数
pg_basebackup命令的使用方法如下:
pg_basebackup [option.. .] 此命令后可以跟多个选项,选项的具体说明如下。 -D directory或--pgdata=directory :指定把备份写到哪个目录。如果这个目录或这个目录路径中的各级父目录不存在,则pg_basebackup就会自动创建这个目录。 -F format或--format=format: 指定输出的格式。“format”指一种格式,它目前又支持两种格式,一种是原样输出,即把主数据库中的各个数据文件、 配置文件、目录结构都完全一样地写到备份目录,这种情况 下“format”指定为“p”或“plain”;另一种是tar格式,相当于把输出的备份文件打包到一个tar文件中,这种情况下“format”应为“t”或“tar”。 -x或--xlog: 备份时会把备份中产生的xlog文件也自动备份出来,这样才能在恢复数据库时,应用这些xlog文件把数据库推到 一个一致点,然后真正打开这个备份的数据库。这个选项与选项“-X fetch”是完全一样的。使用这个选项,需要设置“wal_keep_segments”参数,以保证在备份过程中,需要的WAL日志文件不会被覆盖。 -X method或--xlog-method=method : " method”可以取的值为“f”、“ fetch”、“s”.“stream",其中“f”与“fetch相同,其意义与“-x”参数是一样的。“s”与“stream”表示的意思也相同, 表示备份开始后,启动另一个流复制连接从主库接收WAL日志。这种方式避免了使用“-X f”时, 主库上的WAL日志有可能被覆盖而导致失败的问题。但这种方式需要与主库建两个连接, 因此使用这种方式时,主库的“max_wal_senders”参数至少要设置为2或大于2的值。新版取消此选项 -z或--gzip: 仅能与tar输出模式配合使用,表明输出的tar备份包是经过gzip压缩的,相当于生成了一个*.tar.gz的备份包。 -Z level或--compress=level: 指定gzip的压缩级别,可以选1~9的数字,与gzip命令中的压缩级别是一样的,9表示最高压缩率,但也最耗CPU。 -R, --write-recovery-conf #将复制的配置信息保存,生成standby.signal -c fast/spread或--checkpoint=fast|spread:设置checkpoint的模式是fast还是spread。 -l label或--label=label: 指定备份的一个标识,备份的标识是一个任意字符串,便于今后维护人员识别这个备份,该标识就是手工做基础备份时运行“ select pg_start_backup(‘label')”传递给pg_start_backup函数的参数。在备份集中有一个文件叫“backup label”,这里面除了记录开始备份时 WAL日志的起始位置、Checkpoint 的WAL日志位置、备份的开始时间外,也记录了这个标识串的信息。 -P或--progress :允许在备份过程中实时地打印备份的进度。当然这个打印的进度不是百分之百精确的,因为在备份过程中, 数据库的数据还会发生变化,还会不断产生一些WAL日志。 -v或--verbose:详细模式,使用了-P参数后,还会打印出正在备份的具体文件的信息。 -V或--version:打印pg_basebackup的版本后退出。 -?或--help:显示帮助信息后退出。控制连接数据库的参数。 -h host或--host=host:指定连接的数据库的主机名或IP地址。 -p port或--port=port:指定连接的端口。 -s interval或--status-interval=interval :指定向服务器端周期反馈状态的秒数,如果服务器上配置了流复制的超时,在使用--xlog=stream选项时, 则需要设置这个参数,默认值为10秒。如果设置为0,表示不向服务器反馈状态。 -U username或--username=username:指定连接的用户名。 -w或--no-password:指定从来不提示输入密码。 -W或--password:强制让pg _basebackup出现输入密码的提示。 -R write configuration for replication
完全备份
#在postgreSQL服务器先授权 [postgres@gpserver ~]$vi /pgsql/data/pg_hba.conf host replication all 10.0.0.0/24 md5 [postgres@gpserver ~]$pg_ctl restart -D $PGDATA #在备份服务器执行下面操作 #注意:备份目录/pgsql/backup/必须为空 [postgres@gpserver ~]mkdir -p /pgsql/backup/ #备份, -Ft备份成tar包, -R 必须要加 [postgres@gpserver ~]$pg_basebackup -D /pgsql/backup/ -Ft -Pv -Upostgres -h 10.0.0.200 -p 5432 -R #自动在$PGDATA目录下生成备份记录文件 [postgres@gpserver ~]$cat /pgsql/data/backup_label.old START WAL LOCATION: 0/45000028 (file 000000010000000000000045) CHECKPOINT LOCATION: 0/45000060 BACKUP METHOD: streamed BACKUP FROM: master START TIME: 2020-05-11 10:38:49 UTC LABEL: pg_basebackup base backup START TIMELINE: 1 #查看备份生成的文件 [postgres@gpserver ~]$ 1s /pgsql/backup/ base.tar pg_wal.tar backup_manifest
利用完全备份实现恢复
#在备份服务器上执行下面操作进行还原 [root@@gpserver ~]#mkdir /archive/ [root@@gpserver ~]#chown postgres.postgres /archive/ #确认备份文件存在 [postgres@gpserver ~]$ 1s /pgsql/backup/ base.tar pg_wal.tar #模拟故障 [postgres@gpserver ~]$echo $PGDATA /pgsql/data [postgres@gpserver ~]$ pg_ctl -D $PGDATA stop [postgres@gpserver ~]$ rm -rf $PGDATA/* [postgres@gpserver ~]$ rm -rf /archive/* #进行还原 [postgres@gpserver ~]$ tar xf /pgsql/backup/base.tar -C $PGDATA/ [postgres@gpserver ~]$ tar xf /pgsql/backup/pg_wal.tar -C /archive #修改配置 [postgres@gpserver ~]$ vim $PGDATA/postgresql.conf #添加下面行 restore_command = 'cp /archive/%f %p' recovery_target = 'immediate' #如果pg_basebackup执行时添加-R选项,可以不执行下面,否则会无法启动服务,执行下面指令创建文件后才能启动 [postgres@gpserver ~]$touch /pgsql/data/recovery.signal [postgres@gpserver ~]$pg_ctl start -D $PGDATA #停止恢复过程,否则为只读 postgres=# select pg_wal_replay_resume();
利用PITR实现误删除的实战案例
场景说明
每天2:00备份,第二天10:00误删除数据库,如何恢复?
故障恢复过程
备份数据和归档
还原流程
- 还原完全备份
- 归档日志恢复:
- 备份中的归档
- 恢复2:00到10:00之间的归档
- 恢复在线redo
备份
#在PG服务器开启归档 [postgres@pgserver ~]$ vim /pgsql/data/postgresql.conf archive_mode = on archive_command = 'test ! -f /archive/%f &&cp %p /archive/%f' [postgres@gpserver ~]$pg_ctl restart -D $PGDATA #在PG服务器上创建测试数据 postgres=#create database testdb; postgres=#\c testdb testdb=# create table t1(id int); testdb=# insert into t1 values(1); #在备份服务器对PG数据库进行远程完全备份 [postgres@backup ~]$pg_basebackup -D /pgsql/backup/ -Ft -Pv -Upostgres -h 10.0.0.200 -p 5432 -R #在PG服务器上继续生成测试数据 testdb=# insert into t1 values(2); #模拟数据库删除 postgres=# drop database testdb; #发现故障,停止用户访问 #查看当前日志文件 postgres=# select pg_walfile_name(pg_current_wal_lsn()); -[ RECORD 1 ] + pg_walfile_name | 000000020000000000000020 #查看当前事务ID postgres=# select txid_current(); 521
故障还原
#在PG服务器上切换归档日志 postgres=#select pg_switch_wal(); #在要还原的服务器停止服务,准备还原 [postgres@pgserver ~]$pg_ctl stop -D $PGDATA [postgres@pgserver ~]$rm -rf /pgsql/data/* #在测试的还原服务器进行还原 [postgres@backup ~]$tar xf /pgsql/backup/base.tar -C /pgsql/data/ #此步可以不执行 [postgres@backup ~]$tar xf /pgsql/backup/pg_wal.tar -C /archive/ #复制PG服务器的归档日志到还原的测试服务器 [postgres@pgserver ~]$rsync -a 10.0.0.200:/archive/ /archive/ #查看故障点事务ID [postgres@backup ~]$pg_waldump /archive/000000020000000000000020 |grep -B 10 "DROP dir" rmgr: Database len (rec/tot): 34/ 34, tx: 521, lsn: 0/3D000828, prev 0/3D0007B0, desc: DROP dir 1663/16445 #查看此指令的事务ID为521,前一个事务为520 #修改配置文件postgresql.conf,或者postgresql.auto.conf文件也可以 [postgres@backup ~]$vi /pgsql/data/postgresql.conf #加下面两行 restore_command = 'cp /archive/%f %p' #指定还原至上面查到的事务ID recovery_target_xid = '520' #也可以通过下面方式指定还原至的位置 recovery_target_name = 'restore_point' #指定还原点名称 recovery_target_time = '2021-01-17 16:26:12' #指定还原至时间点 recovery_target_lsn = '0/3E000148' #指定还原到LSN号的位置 #启动服务 [postgres@backup ~]$pg_ctl start -D $PGDATA #验证数据 [postgres@backup ~]$psql postgres=# \c testdb #验证数据是否还原,恢复后读取正常 testdb=# select * from t1; id 1 2 3 #当前无法写入 testdb=# insert into t1 values(4); ERROR: cannot execute INSERT in a read-only transaction [postgres@pgserver ~]$pg_controldata pg_control version number: 1700 Catalog version number: 202406281 Database system identifier: 7434814718768345198 Database cluster state: in archive recovery #数据库状态不对 ... #恢复正常模式 postgres=# select pg_wal_replay_resume(); [postgres@pgserver ~]$pg_controldata pg_control version number: 1700 Catalog version number: 202406281 Database system identifier: 7434814718768345198 Database cluster state: in production #数据库状态正常 #恢复正常写入 testdb=# insert into t1 values(4);
PostgreSQL 高可用
流复制介绍
流复制 streaming replication 是实现PostgreSQL的高可用的常见技术.
PostgreSQL流复制相当于MySQL的主从复制,可以实现数据同步和数据备份
官方文档:http://postgres.cn/docs/12/warm-standby.html#STREAMING-REPLICATION
什么是流复制
PostgreSQL通过 WAL 日志来传送的方式有两种:基于文件的日志传送和流复制。
不同于基于文件的日志传送,流复制的关键在于“流”,所谓流就是没有界限的一串数据,类似于河里的水流,是连成一片的。
流复制比使用基于文件方式的日志传送更能使一台后备服务器保持最新的状态。后备服务器连接到主服务器,主服务器则在 WAL 记录产生时即将它们以流式传送给后备服务器而不必等到 WAL 文件被填充。
比如有一个大文件要从本地主机发送到远程主机,如果是按照“流”接收到的话,我们可以一边接收,一边将文本流存入文件系统。这样,等到“流”接收完了,硬盘写入操作也已经完成。
流复制发展历史
PostgreSQL在流复制出现之前,使用的就是基于文件的日志传送:对WAL日志进行拷贝,因此从库始终落后主库一个日志文件,并且还需要使用rsync工具同步数据目录。
而流复制出现是从2010年推出的PostgreSQL9.0开始的,其历史大致为:
- 起源:PostgreSQL9.0开始支持流式物理复制,用户可以通过流式复制,构建只读备库(主备物理复制,块级别一致)。流式物理复制可以做到极低的延迟(通常在1毫秒以内)。
- 同步流复制:PostgreSQL9.1开始支持同步复制,但是当时只支持一个同步流复制备节点(例如配置了3个备,只有一个是同步模式的,其他都是异步模式)。同步流复制的出现,保证了数据的0丢失。
- 级联流复制:PostgreSQL9.2支持级联流复制。即备库还可以再连备库。
- 流式虚拟备库:PostgreSQL9.2还支持虚拟备库,即就是只有WAL,没有数据文件的备库。
- 逻辑复制:PostgreSQL9.4开始可以实现逻辑复制,逻辑复制可以做到对主库的部分复制,例如表级复制,而不是整个集群的块级一致复制。
- 增加多种同步级别:PostgreSQL9.6版本开始可以通过synchronous_commit参数,来配置事务的同步级别。
流复制原理
备库不断的从主库同步相应的数据,并在备库apply每个WAL record,这里的流复制每次传输单位是 WAL日志的record。
流复制按照同步方式分类
流复制类似于MySQL的的同步机制,支持以下两种同步机制
- 异步复制
- 同步流复制
在实际生产环境中,建议需要根据环境的实际情况来选择同步或异步模式,同步 模式需要等待备库的写盘才能返回成功,如此一来,在主备库复制正常的情况下, 能够保证备库的数据不会丢失,但是带来的一个负面问题,一旦备库宕机,主库 就会挂起而无法进行正常操作,即在同步模式中,备库对主库的有很大的影响, 而异步模式就不会。因此,在生产环境中,大多会选择异步复制模式,而非同步 模式.
流复制特点
- 延迟极低,不怕大事务
- 支持断点续传
- 支持多副本
- 配置简单
- 备库与主库物理完全一致,并支持只读
实现流复制
基础环境准备
两个主机节点
10.0.0.101 Master 10.0.0.102 Standby
Master节点配置
#创建复制的用户并授权 [postgres@master ~]$ psql postgres=#create role repluser with replication login password '123456'; #修改pg_hba.conf进行授权 [postgres@master ~]$vi /pgsql/data/pg_hba.conf host replication repluser 0.0.0.0/0 md5 #修改配置(可选): [postgres@master ~]$vi /pgsql/data/postgresql.conf synchronous_standby_names = '*' #开启此项,表示同步方式,需要同时打开synchronous_commit = on,此为默认值,默认是异步方式 synchronous_commit = on #开启同步模式 archive_mode = on #建议打开归档模式,防止长时间无法同步,WAL被覆盖造成数据丢失 archive_command = '[ ! -f /archive/%f ] && cp %p /archive/%f' wa1_level = replica #设置wal的级别 max_wal_senders = 5 #这个设置可以最多有几个流复制连接,一般有几个从节点就设置几个 wal_keep_segments = 128 #设置流复制保留的最多的WAL文件数目 wal_sender_timeout = 60s #设置流复制主机发送数据的超时时间 max_connections = 200 # 一般查多于写的应用从库的最大连接数要比较大 hot_standby = on #对主库无影响,用于将来可能会成为从库,这台机器不仅仅是用于数据归档,也用于数据查询,在从库上配置此项后为只读 max_standby_streaming_delay = 30s #数据流备份的最大延迟时间 wal_receiver_status_interval = 10s #多久向主报告一次从的状态,当然从每次数据复制都会向主报告状态,只是设置最长的间隔时间 hot_standby_feedback = on #如果有错误的数据复制,是否向主进行反馈 wal_log_hints = on #对非关键更新进行整页写入 [postgres@master ~]$pg_ctl restart -D /pgsql/data
Standby节点配置
#清空数据和归档 [postgres@standby ~]$ pg_ctl stop -D $PGDATA [postgres@standby ~]$ rm -rf /pgsql/data/* [postgres@standby ~]$ rm -rf /archive/* [postgres@standby ~]$ rm -rf /pgsql/backup/* #备份主库数据到备库 [postgres@standby ~]$ pg_basebackup -D /pgsql/backup/ -Ft -Pv -Urepluser -h 10.0.0.101 -p 5432 -R #还原备份的数据,实现初始的主从数据同步 [postgres@standby ~]$ tar xf /pgsql/backup/base.tar -C /pgsql/data [postgres@standby ~]$ tar xf /pgsql/backup/pg_wal.tar -C /archive/ #方法1 #修改postgresql.conf文件 [postgres@standby ~]$ vi /pgsql/data/postgresql.conf #添加下面两行 primary_conninfo = 'host=10.0.0.101 port=5432 user=repluser password=123456' restore_command = 'cp /archive/%f %p' #此项可不配置 #修改配置(可选): hot_standby = on #开启此项,此是默认项 recovery_target_timeline = latest # 默认 max_connections = 120 # 大于等于主节点,正式环境应当重新考虑此值的大小 max_standby_streaming_delay = 30s wal_receiver_status_interval = 10 shot_standby_feedback = on max_wal_senders = 15 logging_co1lector = on log_directory = 'pg_log' log_filename = 'postgresql-%Y-%m-%d_%H%M%S.log' #方法2 #修改postgresql.auto.conf [postgres@standby ~]$ vi /pgsql/data/postgresql.auto.conf primary_conninfo = 'host=10.0.0.101 port=54321 user=repluser password=123456 sslmode=disable sslcompression=0 gssencmode=disable krbsrvname=post_session_attrs=any' #此行自动生成,只修改用户名即可 restore_command = 'cp /archive/%f %p' [postgres@standby ~]$ pg_ctl -D /pgsql/data start
监控同步状态
在主库查看状态
[root@master ~]#pg_controldata pg_control version number: 1201 Catalog version number: 201909212 Database system identifier: 7051752604814091288 Database cluster state: in production #主库状态 ...... postgres=#select pid,state,client_addr,sync_priority,sync_state from pg_stat_replication; pid | state | client_addr | sync_priority | sync_state 21373 | streaming | 10.0.0.102 | 0 | async #下面只在主节点查看同步模式,注意:如果无从节点连接,将无任何显示信息 postgres=# SELECT pg_current_wal_insert_lsn(),* from pg_stat_replication; -[ RECORD 1 ] + pg_current_wal_insert_lsn | 0/5B002988 #当前lsn号 pid | 33479 usesysid | 16452 usename | repluser application_name | walreceiver client_addr | 10.0.0.8 client_hostname | client_port | 56742 backend_start | 2020-05-18 11:50:21.970079+00 backend_xmin | state | streaming sent_lsn | 0/5B002988 write_lsn | 0/5B002988 #同步的lsn号,和上面一致,说明同步,有差表示有同步延迟 flush_lsn | 0/5B002988 replay_lsn | 0/5B002988 write_lag | flush_lag | replay_lag | sync_priority | 1 sync_state | async #当前是异步,同步显示为sync reply_time | 2020-05-18 12:00:20.851292+00 #服务器查看数据库是否为备库,f表主库 t表示为备库 postgres=# select * from pg_is_in_recovery(); postgres=# select application_name,client_addr,sync_state from pg_stat_replication; application_name | client_addr | sync_state walreceiver | 10.0.0.200 | async (1 row) [root@master ~]#ps aux |grep walsender postgres 1295 0.0 0.3 160748 6448 ? Ss 08:47 0:00 postgres: walsender repluser 10.0.0.8(39850) streaming 0/4F912580 #发送WAL日志进程
在从库查看状态
#从节点可以读 hellodb=# select * from teachers; #从节点不支持写 hellodb=# delete from teachers where tid=4; ERROR: cannot execute DELETE in a read-only transaction postgres=# select * from pg_is_in_recovery(); pg_is_in_recovery | t postgres=# \x Expanded display is on. postgres=# SELECT * FROM pg_stat_wal_receiver; #查看进程 [root@standby ~]#ps aux|grep postgres walreceiver streaming 0/4F912580 #接收WAL日志进程
切换主从
将从库切换为主库
#从库切为主,能写入 [postgres@slave ~]$ pg_ctl promote [postgres@slave ~]$ pg_controldata pg_ctl restart #恢复正常模式 postgres=# select pg_wal_replay_resume();
原主库切换为从库
#在原主库修复故障后,在主库服务器重复上面Standby节点配置的步骤 #在原主库服务器创建standby.signal文件 [postgres@master ~]$touch $PGDATA/standby.signal #在原主库服务器启动服务 [postgres@master ~]$pg_ctl -D /pgsql/data restart #在原主库服务器查看状态 [postgres@master ~]$/pgsql/data$ pg_controldata pg_control version number: 1201 Catalog version number: 201909212 Database system identifier: 7051752604814091288 Database cluster state: in archive recovery pg_control last modified: Thu Jan 20 10:23:03 2022 Latest checkpoint location: 0/5E000060 hellodb=# select * from pg_is_in_recovery(); t
重新验证同步状态
在新主库创建数据,验证是否能同步至原主库
实现同步的流复制
配置同步的流复制
主节点需要特殊的如下配置,从节点配置再执行
[postgres@master ~]$vi /pgsql/data/postgresql.conf synchronous_standby_names = '*' #开启此项,表示同步方式,默认是异步方式 synchronous_commit = on #开启同步模式
验证同步状态
#在主节点查看sync状态 postgres=# select pid,state,client_addr,sync_priority,sync_state from pg_stat_replication; #从节点停止服务 postgres@slave:~$ pg_ctl stop #主节点只支持读,但写入时会处于卡顿状态,直至从节点恢复正常同步 hellodb=# delete from teachers where tid=4; ......