Career: SRE 运维
- TAGS: Career
运维职业发展路线
互联网运维职业发展
- 基础运维
- 监控运维
- 系统运维
- 应用运维
- 自动化运维
- 架构师
- 总监或 CTO
运维的未来是什么?
一切皆自动化
"运维的未来是,让研发人员能够借助工具、自动化和流程,并且让他们能够在运维干预极少的情况下部署和运营服务,从而实现自助服务。每个角色都应该努力使工作实现自动化。"-–—《运维的未来》
初中级运维
高级运维
常见的面试问题
原理
十五大原理
(要求能熟练画图并口头清晰表达)
- DNS系统架构与解析原理
- http协议通信原理
- TCP/IP的3次握手和四次断开原理
- MySQL主从同步原理
- Nginx配合Php工作Fastcgi工作原理
- Lvs的的4种模式工作原理
- Memcachecd:工作原理(内存管理机制)
- Keepalived高可用服务工作原理
- 描述CDN工作原理详细过程以及购买CDN后具体解析操作步骤?
- linux默认文件系统,文件删除原理
- raid 0 15 10的原理、特点,性能区别,集群中咅角色如何选择RAID。
- 一致性哈希算法作用及原理
- 描迷linux下磁盘读写数据的原理,磁盘分区的原理,默认文件系统工作原理
- 详细描述Linux权限管理体系。
- 描沭你维护过的大规樽集群网站架构的设计原理。
DNS系统架构与解析原理
Client -->hosts文件 --> Client DNS Service Local Cache --> DNS Server (recursion递归) --> DNS Server Cache -->DNS iteration(迭代) --> 根--> 顶级域名DNS-->二级域名DNS…
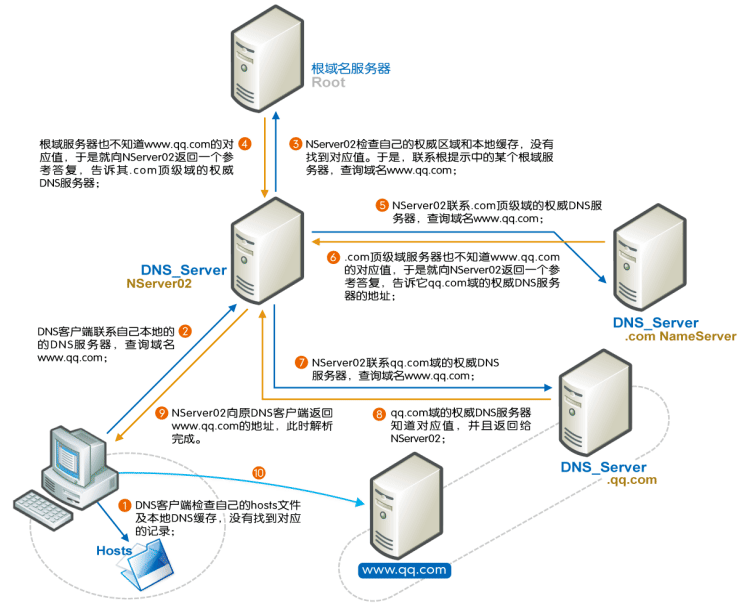
上图中分 8 个步骤介绍了域名解析的流程,但在此之前会先检查本机的缓存配置+ hosts 解析,然后才真正执行上图的流程:
首先,再进行dns服务器解析之前,会查缓存,总共有两次缓存的查询:
浏览器缓存检查:浏览器会首先搜索浏览器自身的 DNS 缓存,缓存时间比较短,大概只有1分钟,且只能容纳 1000 条缓存,看自身的缓存中是否有对应的条目,而且没有过期,如果有且没有过期则解析到此结束。
操作系统缓存检查 + hosts 解析:如果浏览器的缓存里没有找到对应的条目,操作系统也会有一个域名解析的过程,那么浏览器先搜索操作系统的 DNS 缓存中是否有这个域名对应的解析结果,如果找到且没有过期则停止搜索,解析到此结束。在 Linux 中可以通过 /etc/hosts 文件来设置,可以将任何域名解析到任何能够访问的IP 地址。如果在这里指定了一个域名对应的 IP 地址,那么浏览器会首先使用这个 IP地址。当解析到这个配置文件中的某个域名时,操作系统会在缓存中缓存这个解析结果,缓存的时间同样是受这个域名的失效时间和缓存的空间大小控制的。
接着就进行dns解析:
第一步:客户端通过浏览器访问域名为 www.baidu.com (http://www.baidu.com) 的网站,发起查询该域名的 IP 地址的 DNS 请求。该请求发送到了本地 DNS 服务器上。本地 DNS 服务器会首先查询它的缓存记录,如果缓存中有此条记录,就可以直接返回结果。如果没有,本地 DNS 服务器还要向 DNS 根服务器进行查询。
第二步:本地 DNS 服务器向根服务器发送 DNS 请求,请求域名为 www.baidu.com (http://www.baidu.com) 的 IP 地址。
第三步:根服务器经过查询,没有记录该域名及 IP 地址的对应关系。但是会告诉本地 DNS 服务器,可以到域名服务器上继续查询,并给出域名服务器的地址(.com 服务器)。
第四步:本地 DNS 服务器向 .com 服务器发送 DNS 请求,请求域名 www.baidu.com (http://www.baidu.com) 的 IP 地址。
第五步:com 服务器收到请求后,不会直接返回域名和 IP 地址的对应关系,而是告诉本地DNS 服务器,该域名可以在 baidu.com 域名服务器上进行解析获取 IP 地址,并告诉 baidu.com 域名服务器的地址。
第六步:本地 DNS 服务器向 baidu.com 域名服务器发送 DNS 请求,请求域名 www.baidu.com (http://www.baidu.com) 的 IP 地址。
第七步:baidu.com 服务器收到请求后,在自己的缓存表中发现了该域名和 IP 地址的对应关系,并将 IP 地址返回给本地 DNS 服务器。
第八步:本地 DNS 服务器将获取到与域名对应的 IP 地址返回给客户端,并且将域名和 IP 地址的对应关系保存在缓存中,以备下次别的用户查询时使用。
http协议通信原理
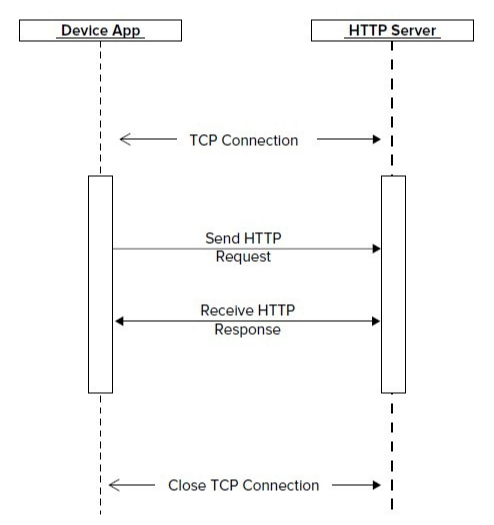
客户端发送请求—httpd得到请求-—httpd解析请求的格式(html,css)—请求相应php解析—php解析程序执行完毕—db数据库–返回结果html给httpd–httpd把数据返回给客户端(可能是压缩过的)—浏览器接到返回结果
HTTP通信原理
第一个:http是osi模型中的应用层协议,http的重要应用服务是www服务。
第二个:要讲一下dns的解析原理。
第三个:http的一个请求信息包含的内容(请求报文)。
第四个:http服务返回的信息内容包括消息主体,消息头(header)(响应报文)。
第五个:用户通过浏览器访问网站的请求和返回数据的流程。
TCP/IP的3次握手和四次断开原理
TCP三次握手
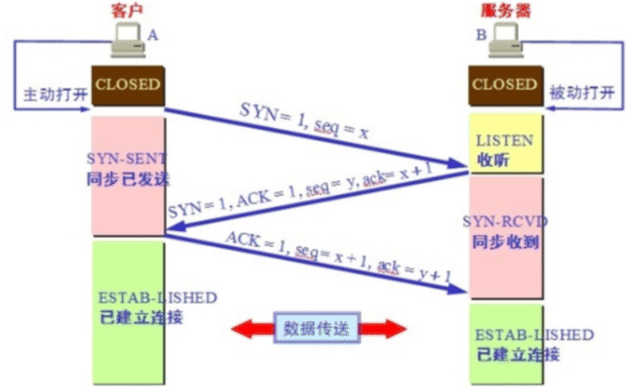
tcp的三次握手的过程和必要性(这里假设A是client,B是server)
- 第一次握手:A 发送请求,先把 TCP 包头中标记 SYN 标记为1,数据包的编 号即包头中的序号打上序号,如是第一个包则写成1,即 seq = 1。通俗讲 A 发送 SYN包(SYNC=j)连接请求到达B,并进入SYN_SEND状态,等待服务器B确 认
- 第二次握手:B 回应请求,TCP 包头中标记 SYN 为 1, ACK 为1,请求通信和 确认你来过来的信息,同时数据包的编号 seq = y,包头中确认号为 A 发来 包的序号加 1 即 ack = x + 1 希望下次发 x + 1。通俗讲 B 收到 SYN 包后, 也会发送一个 SYN 包给 A,这个包里面带有ACK=j+1 用来确认 A 的 SYN,和 B 自己的 SYN=k,B 进入 SYN_RECV 状态
- 第三次握手:A 发回应 让 B 确认刚才请求,标记 ACK = 1,包序号 x + 1, 确认号 y + 1。通俗讲 A 收到 B 的 SYN + ACK 包,向 B 发送确认包 ACK(ACK=k+1),发送完毕,A 和 B 进入 ESTABLISHED 状态,完成三次握手
此时A客户端就可以向B服务器发送数据了
TCP四次挥手
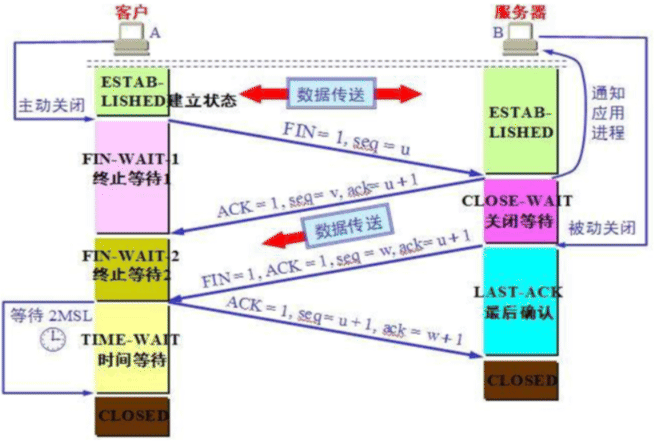
A 完整的断开连接:
- 第一次挥手:A->B,是ESTABLISHED状态;A向B发出释放连接请求的报文,其 中FIN(终止位)= 1,seq(序列号)=u;在A发送完之后,A的TCP客户端进入 FIN-WAIT-1(终止等待1)状态。此时A还是可以进行收数据的
- 第二次挥手:B->A:B在收到A的连接释放请求后,随即向A发送确认报文。其 中ACK=1,seq=v,ack(确认号)= u +1;在B发送完毕后,B的服务器端进入 CLOSE_WAIT(关闭等待)状态。此时A收到这个确认后就进入FIN-WAIT-2(终 止等待2)状态,等待B发出连接释放的请求。此时B还是可以发数据的
B 完整的断开连接:
- 第三次挥手:B->A:当B已经没有要发送的数据时,B就会给A发送一个释放连 接报文,其中FIN=1,ACK=1,seq=w,ack=u+1,在B发送完之后,B进入 LAST-ACK(最后确认)状态。
- 第四次挥手:A->B;当A收到B的释放连接请求时,必须对此发出确认,其中 ACK=1,seq=u+1,ack=w+1;A在发送完毕后,进入到TIME-WAIT(时间等待)状 态。B在收到A的确认之后,进入到CLOSED(关闭)状态。在经过时间等待计时 器设置的时间之后,A才会进入CLOSED状态。
注意:
- 客户端收到服务端断开请求,发送确认;客户端状态变为TIMED_WAIT #完成双 向传输连接关闭,等待所有分组消失 (报文最长时间的2倍)2MSL
- 特殊的状态 CLOSING 客户端向服务端发送了FIN但没有收到服务端的ACK而是 服务端FIN;进入CLOSING状态的接下来的流程和FIN_WAIT 2接下来的流程是一 样的 #双方同时尝试关闭传输连接,等待对方确认
MySQL主从同步原理
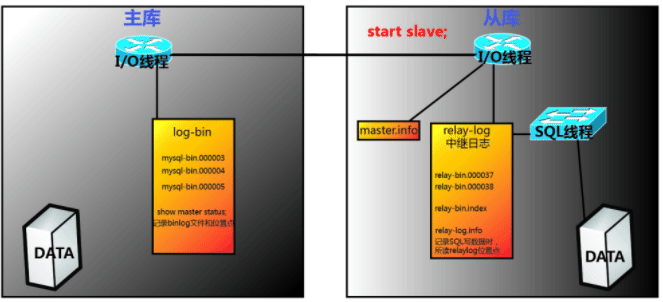
MySQL主从复制原理
- Slave上面的IO进程链接上Master,并请求从指定日志文件的指定位置(或者从最开始的日志)之后的日志内容;
- Master接收到来自Slave的IO进程的请求后,通过负责复制的IO进程根据请求信息读取指定日志指定位置之后的日志信息,返回给Slave的IO进程。返回信息中除了日志所包含的信息之外,还包括本次返回的信息已经到Master端的bin-log文件的名称以及bin-log的位置;
- Slave的IO进程接收到信息后,将接收到的日志内容依次添加到Slave端的relay-log文件的最末端,并将读取到的Master端的bin-log的文件名和位置记录到master-info文件中,以便在下一次读取的时候能够清楚的告诉Master,我需要从某个bin-log的哪个位置开始往后的日志内容,请发给我;
- Slave的Sql进程检测到relay-log中新增加了内容后,会马上解析relay-log的内容称为在Master端真实执行时候的那些可执行的内容,并在自身执行。
Nginx配合Php工作Fastcgi工作原理
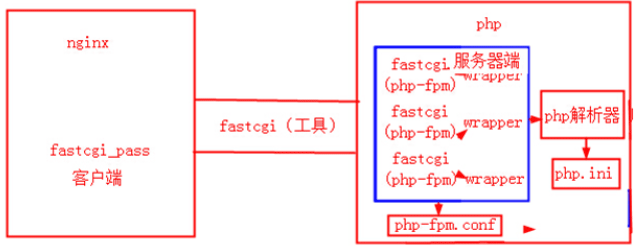
- 首先FastCGI进程管理自身初始化,启动多个CGI解析器进程(多个php-cgi进程)并等待来自nginx的连接。PHP采用PHP-FPM进程管理器启动多个FastCGI进程。
- 当客户端请求道达Nginx时,nginx服务器将请求转发到FastCGI主进程,FastCGI主进程选择并连接到一个CGI解释器(子进程)。Web服务器将CGI环境变量和标准输入发送到FastCGI子进程php-cgi。
- FastCGI子进程完成处理后将标准输出和错误信息从同一连接返回Web服务器(Nginx)。当FastCGI子进程关闭连接时,请求便告知处理完成。FastCGIz子进程接着等待并处理来自FastCGI进程管理的下一个连接
fastcgi是http server和动态脚本语言间通信的接口或者工具
fastcgi的优点是把动态语言和HTTP Server分离开来
fastcgi接口采用C/S的结构
php动态语言服务端可以启动多个fastcgi的守护进程(对PHP来说表现形式为php-fpm)
nginx就是把动态请求通过fastcgi_pass抛给php的php-fpm服务来解析的
Lvs的的4种模式工作原理
DR模式的工作原理
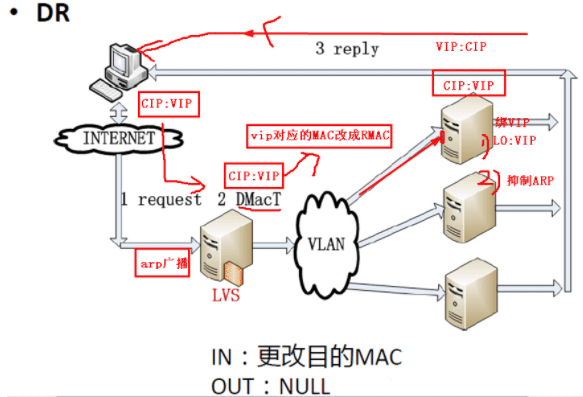
客户端请求报文:源地址CIP目标地址VIP,通过网关路由到达LVS负载均衡节点,因为LVS本身不响应请求,只是进行请求转发到后发,所以当负载均衡节点接收到请求后,会通过LVS调度算法将报文中的目标MAC地址修改为后端其中一台real server所对应的mac地址(在部署LVS的过程中需要后端real server进行通信时就已经记录了LVS管理节点下的real server的mac地址),real server处理完请用户请求后就直接通过路由网关返回数据(源vip目标cip)给客户端。
这里要注意:real server收到报文后,发现vip不在本机上,所以在本地lo回环接口上绑定vip来接收报文,并且real server要抑制vip,防止arp广播时real server抢包、防止和lvs vip冲突。
NAT模式工作原理
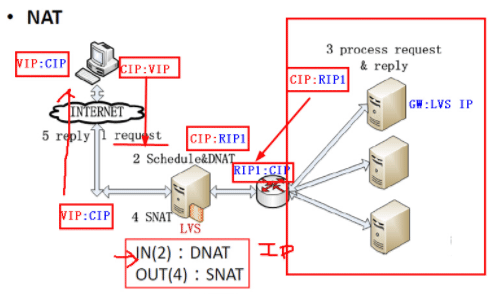
- NAT模式下LVS会改写用户发送请求报文中的目的IP地址为RIP,然后将请求报文发送给real server
- 当RIP返回数据包给客户端的时候,因为real server的网关配置的是LVS所以real server发送的数据包会经过LVS,然后lvs会改写返回报文中的源IP地址
- 最后lvs会将报文发送给用户端
- vip只需要绑定LVS服务器上即可,不需要做ARP抑制
- NAT模式下LVS的接收转发效率相比DR模式会降低许多
FULLNAT模式工作原理
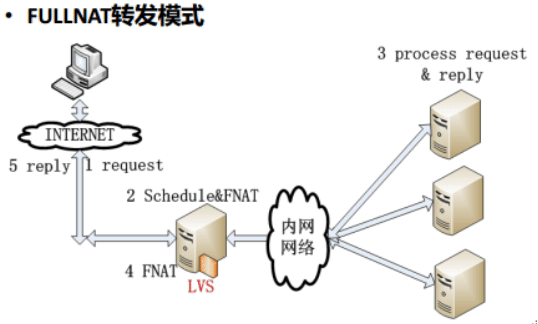
- 与NAT模式相比会更改用户请求报文中的源IP地址和目标IP地址
- 用户发送请求报文时会更改源IP地址为其中一台调度器的IP地址 目的IP地址为其中一台real server的IP地址
real server返回用户报文时会更改目的IP地址为用户端的IP地址,源IP地址为其中一台lvs调度器的IP地址
tunnel模式工作原理
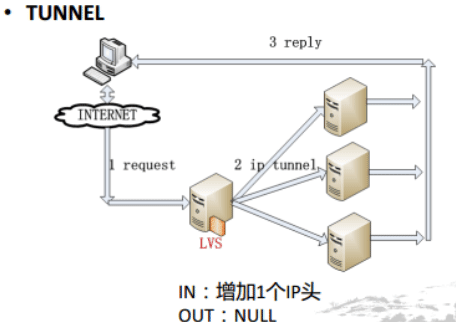
- 与DR模式相同的是real server处理完用户请求之后会将处理结果通过路由器返回给客户端而不经过LVS
- 与DR模式不同的是LVS和realserver之间的通信是通过隧道进行的
- 同样需要在LVS和real server绑定VIP
隧道模式其实就是在LVS和real server上建立tunnel隧道,增加一个IP包头
tunnel可以做跨机房,效果不是特别好。跨公网不稳定。
Memcachecd:工作原理(内存管理机制)
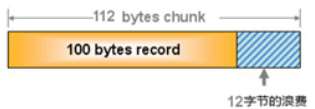
- memcached利用slab allocation机制来分配和管理内存
- slab allocation内存管理机制原理是按照预先规定的大小,将分配给memcached的内存分割成特定长度的内存块(chunk),再把尺寸相同的内存块分成组(chunks slab class),这些内存块不会释放,可以重复利用
- memcached服务器端保存一个空闲的内存块列表,当有数据存入时根据接收到的数据大小,分配一个能存下这个数据的最小内存块
这种方式有时会造成内存浪费,解决方法是:启动memcached时指定-f参数
Keepalived高可用服务工作原理
高可用之间的故障切换转移是通过VRRPE协议实现的。VRRP协议是通过一个竞选的协议来实现虚拟路由器的功能。高可用之间是通过VRRP协议通信的,VRRP协议是通过竞选机制来确定主备的,主的优先级高于备。因为工作时候,主会获得所有的资源。备节点处于等待状态,当主挂的时候,备节点,接管主节点的资源,然后顶替主节点,对外提供服务。他的广播方式是通过IP多波包的方式(224.0.0.18)的广播方式。在keepalived之间,只有作为主的服务器,会一直发送VRRP广播包。告诉备,他还活着。此时,备不会抢占主。当主不可用时候,即备见听不到主发送的广播包的时候,就会启动相关服务接管资源。接管速度可以小于一秒。保障业务的连续性。VRRP的数据包是加密协议进行加密发送广播包。备可以有多个,通过VRRP竞选。
描述CDN工作原理详细过程以及购买CDN后具体解析操作步骤?
linux默认文件系统,文件删除原理
文件删除和软链接没关系,控制文件删除主要是看文件的进程调用数i_count和文件的硬链接i_link数
在没有进程条用文件的情况下,i_link=0时,文件就被删除了
当新创建一个文件时i_link=1,为这个文件创建一个硬链接,i_link=2!
当有进程占用这个文件时,i_count+1,icount=1
只有当i_link和i_count都为0时文件才被删除了
raid 0 15 10的原理、特点,性能区别,集群中咅角色如何选择RAID。
- RAID 0:又称为Stripe(条带化)或条带模式,是RAID级别红具有最高的存储性能。它是把多块盘形成组合成一块逻辑盘。
RAID 0的原理就是把连续的数据分散到多个磁盘存取,当系统有读写请求数据的时候可以多个磁盘并行的执行,每个磁盘读写属于它自己的那部分数据请求,这种数据上的并行操作,可以利用总线的带宽,显著提高磁盘整体存取性能(最好使用两块一样大小的磁盘)。
RAID 0要求至少1块磁盘,支持多块盘,对于RAID 0来说如果有一块盘宕掉,那么整个硬盘就会宕掉,没有容错功能任何一个磁盘的损坏都会造成整个RAID盘全部数据的丢失。
- RAID 1,又称为MIrror或Mirroring(镜像)。也是要求至少两块盘,他的宗旨是最大限度的保证用户数据的可行性和可修复性。RAID 1的操作方式是把用户写入磁盘的数据百分之百的自动复制到另外一个磁盘上面。整个RAID容量大额大小等于两个磁盘中最小的哪块磁盘的容量(最好使用两块一样大小的磁盘)。数据有50%的冗余,在存储的时候同时写入两块磁盘,实现了数据的完整备份,但相对降低了数据的写入性能。但是读取数据的时候可以并发,基本上相当于RAID 0的读取效率。一块硬盘宕掉了对整个硬盘的数据没有影响。如果某一块盘坏掉了,只要把一块盘加进去就可以让数据完整的读取恢复。
- RAID 5:奇偶校验,安全性强,每一块硬盘都会写入奇偶校验信息,提供数据的安全保障,是介于RAID 0 和RAID 1之间的一种存储性能、数据安全、和存储成本兼顾的存储解决方案。RAID 5需要三块或以上的硬盘,可以提供热备盘实现故障的恢复,而且只有同时宕掉两块盘的时候,整个RAID盘的数据才会完全损坏,只损坏一块盘的时候,系统会根据奇偶校验位重建数据,临时提供服务,此时如果有热备盘,系统会自动的在热备攀上重建恢复故障盘上的数据。RAID 5不对存储的数据进行备份,而是把数据和相对应的奇偶校验信息存储到罪城RAID 5的各个磁盘上面,奇偶校验信息和相对应的数据分别存放在不同的磁盘上,让RAID 5的一个磁盘发生数据损坏后利用剩下的数据和相应的奇偶校验信息去回复故障盘的数据。RAID 5具有RAID 0相近似额数据读取速度,只是多了一个奇偶校验信息,写入数据的速度回避对单个磁盘进行写入操作稍慢,写入效率还是差一点,但是读取效率还是不错的。
- RAID 10:也被称之为RAID 0+1,也就是说是RAID 0和RAID 1的组合模式,RAID 10的存储方式是数据性能和安全性能兼顾的一种方案,由于RAID 10也是通过数据的100%备份功能提供数据安全保障。空间利用率与RAID 0相同,但是成本较高。先是一个镜像,然后是一个条带。适用于基友大量数据需要存取,同时又对数据安全性要求严格的领域:银行、金融、商业超市、仓储库房、各种档案管理等。
集群中角色选型:
①生产环境选择的依据就是:价格、性能、冗余。
②负载均衡器硬件选择及raid级别:
没有什么数据存储,很重要,需要的就是稳定,对CPU和内存有一定的要求,磁盘大小要求不高。一般选择1U就可以了,
LVS1Z主:DELL R610 1U,CPU E5606*2,4G*2内存,硬盘:SAS 146G*2 RAID 1
LVS2Z主:DELL R610 1U,CPU E5606*2,4G*2内存,硬盘:SAS 146G*2 RAID 1
③WEB层硬件选择及RAID级别:
WWW主站1业务(两台):DELL R710,CPU E5606*2,4G*4内存,硬盘:SAS 300G*2 RAID 0
WWW主站2业务(两台):DELL R710,CPU E5606*2,4G*4内存,硬盘:SAS 300G*2 RAID 0
一般web服务器大都是负载均衡设备,有很多台,可以使用raid0,效率比较高,如果机房机器很多,老跑机房换硬盘,也可以考虑使用raid5.
④数据库层的硬件选择及raid级别:
- MySQL主库1:DELL R710,E5606*2,4G*8内存,硬盘:SAS 600G*6(或者146*6) RAID10
- MySQL主库2:DELL R710,E5606*2,4G*8内存,硬盘:SAS 600G*6(或者146*6) RAID10
- MySQL从库1-1:DELL R710,E5606*2,4G*4内存,硬盘:SAS 15k 600G*4 RAID0或者600*5 RAID5
- MySQL从库1-2:DELL R710,E5606*2,4G*4内存,硬盘:SAS 15k 600G*4 RAID0或者600*5 RAID5
- MySQL主库2-1:DELL R710,E5606*2,4G*4内存,硬盘:SAS 15k 600G*4 RAID0或者600*5 RAID5
- MySQL主库2-2:DELL R710,E5606*2,4G*4内存,硬盘:SAS 15k 600G*4 RAID0或者600*5 RAID5
注意:这里也可以选择R610,如果机器海量,需要尽量统一,方便管理,考虑到跑机房老换硬盘装系统成本,可以考虑RAID5.
RAID0就是为了最大化他的磁盘IO,
⑤存储层硬件选择及raid级别:
如果能够购买存储硬件设备,那么最好不过了。备份服务器一般考虑容量和冗余即可,对性能要求不高。
共享存储如果做线上备份,要注意使用和数据库一样的配置。
- 数据备份:DELL R610,E5606*2,16G内存,硬盘:SATA 10k 2T*4 可以不做raid交叉备份。
- 数据备份:DELL R710,E5606*2,16G内存,硬盘:SATA 10k 2T*6 raid5 做个raid5是折中方案。
- 共享NFS1:DELL R710,E5606*2,16G内存,硬盘:SAS 15k 600G*6 RAID10/RAID5/RAID0
- 共享NFS2:DELL R710,E5606*2,16G内存,硬盘:SAS 15k 600G*6 RAID10/RAID5
注意如果使用分布式存储MFS,GFS,那么服务器使用普通的服务器就可以了。
⑥监控管理网管层硬件选择及raid级别:
监控及报警服务器监控及出口网关等:DELL R610,E5606*1 8G 内存,146G*2 raid1
注意:也可以不单独采购,和备份服务器使用同一台机器。
⑦网络设备:(采用全千兆交换机)
CISCO,H3C,DLINK(3000YUAN左右)
注意所有的设备要带独立的远程管理卡。
一致性哈希算法作用及原理
一致性哈希算法作用
- 保证每个对象只请求一个对应的服务器
- 保证节点当掉,整个数据更新重新分配比列降到最低。
一致性哈希原理描述
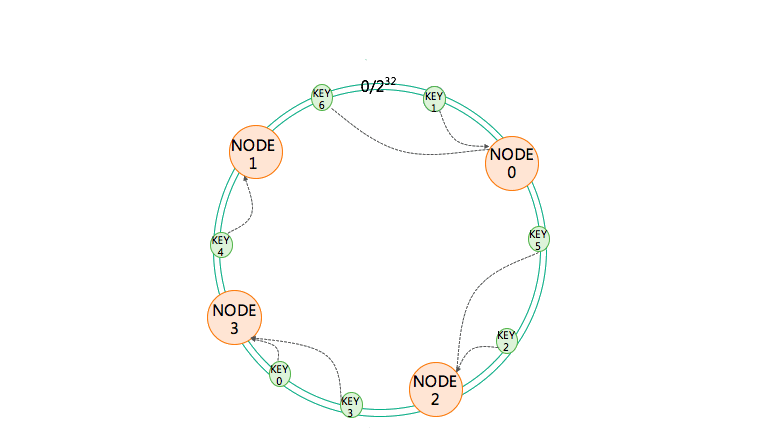
按照常用的hash算法来将对应的key哈希到一个具有2^32次方个桶的空间中,即0~(2^32)-1的数字空间中。
对每个服务器的节点取模,求它的哈希值并把这个哈希值放到环上,所有的服务器都取哈希值放到环上,每一次进行服务器查找路由计算的时候,把 key 也取它的哈希值,取到哈希值以后把 key 放到环上,顺时针查找距离它最近的服务器的节点是哪一个,它的路由节点就是哪一个。通过这种方式也可以实现,key 不变的情况下找到的总是相同的服务器。这种一致性哈希算法除了可以实现像余数哈希一样的路由效果以外,对服务器的集群扩容效果也非常好。
在一致性哈希环上进行服务器扩容的时候,新增加一个节点不需要改动前面取模算法里的除数,导致最后的取值结果全部混乱,它只需要在哈希环里根据新的服务器节点的名称计算它的哈希值,把哈希值放到这个环上就可以了。放到环上后,它不会影响到原先节点的哈希值,也不会影响到原先服务器在哈希环上的分布,它只 会影响到离它最近的服务器 ,比如上图中 NODE3 是新加入的服务器,那么它只会影响到 NODE1,原先访问 NODE1 的 key 会访问到 NODE3 上,也就是说对缓存的影响是比较小的,它只会影响到缓存里面的一小段。如果缓存中一小部分数据受到了影响,不能够正确的命中,那么可以去数据库中读取,而数据库的压力只要在它的负载能力之内,也不会崩溃,系统就可以正常运行。所以通过一致性哈希算法可以实现缓存服务器的顺利伸缩扩容。
但是一致性哈希算法有着致命的缺陷。我们知道哈希值其实是一个随机值,把一个随机值放到一个环上以后,可能是 不均衡 的,也就是说某两个服务器可能距离很近,而和其它的服务器距离很远,这个时候就会导致有些服务器的负载压力特别大,有些服务器的负载压力非常小。同时在进行扩容的时候,比如说加入一个节点 3,它影响的只是节点 1,而我们实际上希望加入一个服务器节点的时候,它能够分摊其它所有服务器的访问压力和数据冲突。
所以对这个算法需要进行一些 改进 ,改进办法就是 使用虚拟节点 。也就是说我们这一个服务器节点放入到一致性哈希环上的时候,并不是把真实的服务器的哈希值放到环上,而是将一个服务器虚拟成若干个虚拟节点,把这些虚拟节点的 hash 值放到环上去。在实践中通常是把一个服务器节点虚拟成 200 个虚拟节点,然后把 200 个虚拟节点放到环上。key 依然是顺时针的查找距离它最近的虚拟节点,找到虚拟节点以后,根据映射关系找到真正的物理节点。
第一,可以解决我们刚才提到的负载不均衡的问题,因为有更多的虚拟节点在环上,所以它们之间的距离总体来说大致是相近的。第二,在加入一个新节点的时候,是加入多个虚拟节点的,比如 200 个虚拟节点,那么加入进来以后环上的每个节点都可能会受到影响,从而分摊原先每个服务器的一部分负载。
描迷linux下磁盘读写数据的原理,磁盘分区的原理,默认文件系统工作原理
读写原理:读数据时将磁盘上的磁粒子转换成电脉冲信号,通过数据转换器,转换成电脑可以识别数据。
磁盘读写数据的原理。 磁盘读写数据时,按照柱面来读写数据的。可能会先读一个盘面的某一个磁道的数据,读完之后,再向下读取相同磁道不同盘面的数据。直到所有盘面相同磁道的数据被读取完毕,切换到下一个柱面。这个切换过程叫做寻道看,寻道要靠步进电机控制,让磁头做移动了,这是机械运动,因此很慢。写是同理。
存储原则(读和写都是按照柱面来进行的)①磁盘是按照柱面来读写数据的,即现读取盘面的某一个磁道,读完整个磁道之后,如果数据没有读完,次头也不回切换到别的磁道,而是选择切换磁头,读取下一个盘面的相同半径磁道,知道所有盘面的形同半径的磁道全读完之后才会切换到不同半径的磁道(柱面),这个切换磁道的过程就是寻道(效率最差、机械的) ②不同磁头的切换是电子切换(所有磁头同时读一个柱面相同半径的磁道),不同磁道切换需要做径向移动。磁盘运作,尽量是避免机械运动而完成数据读取和查找任务。
分区原理:磁盘分区的实质上就是定义一个以磁盘的的开始和结束。
文件系统工作原理 NFS系统是通过网络进行数据传输和共享的,NFS的共享端口是不固定的,这样NFS采用RPC服务(中间人),是多数大型网站采用的这个服务。RPC最主要的功能就是记录每个NFS功能所对应的的端口号,并且在NFS客户端请求时将该端口和功能的对应信息传递给请求数据的NFS客户端,从而可以客户端可以链接正确的NFS客户端。这样保证正确的数据传输。
文件系统工作原理
文件系统的工作与操作系统的文件数据有关。现在的操作系统的文件数据除了文件实际内容外,通常含有非常多的属性。例如文件权限(rwx)与文件属性(所有者、用户组、时间参数等)。文件系统通常会将这两部分的数据分别存放在不同的区块,权限和属性放到inode中,数据则放到block区块中。另外,还有一个超级块(super block)会记录整个文件系统的整体信息,包括inode与block的总量、使用量、剩余量等等。
每个inode与block都有编号,至于这个三个数据的意义可以简略说明如下:
superblock:记录此filesystem的整体信息,包括inode/block的总量、使用量、剩余量,以及文件系统的格式与相关信息等。
inode:记录文件的属性,一个文件占用一个inode,同时记录此文件的数据所在的block号码。
block:记录文件的内容,若文件太大时,会占用多个block。
由于每个inode与block都有编号,而每个文件都会占用一个inode,inode内则有文件数据放置的block号码。因此,我们可以知道的是,如果能够找到文件的inode的话,那么自然就会知道这个文件说放置数据的block号码,当然也就能够读出该文件的实际数据了。这是个比较有效率的做法,因为如此一来我们的磁盘就能够在短时间内读出全部的数据,读写的性能比较好。
我们将inode与block区块用图解来说明一下,如图所示,文件系统先格式化出inode与block的区块,假设某一个档案的属性与权限数据是放置到inode 4号,而这个inode记录了档案数据的实际放置点位2,7,13,15这四个block号码,此时我们的操作系统就能够据此来排列磁盘的阅读顺序,可以一口气将四个block内容读出来!
这种数据存储的方法我们成为索引式系统。
下面我们来看一下windows系统中的FAT,这种格式的文件系统并没有inode存在,所以FAT没有办法将这个文件的所有block在一开始就读出来。每个block号码都记录在前一个block当中,他的读取方式有点像地下这样
上图中我们假设文件的数据依序写入1->7->4->15号这四个block号码中,但这个文件系统没有办法一口气就知道四个block的号码,他的要一个一个的将block读出后,才会知道下一个block在何处。如果同一个文件数据写入的block分散的太厉害时,则我们的磁盘读取头将无法在磁盘转一圈就读到所有的数据,因此就会多转好几圈才能完整的读取到这个文件的内容。
这就是为什么在windows系统中常常需要碎片整理,需要碎片整理的原因就是文件写入的block太过离散了,此时文件读取的效能将会变的很差。这个时候可以通过碎片整理将同一个文件所属的blocks汇整在一起,这样数据的读取会比较容易。
再来讨论一下inode这个吧!如前所述inode的内容在记录档案的属性以及该档案 实际数据是放置在哪几号block内!基本上,inode记录的文件数据至少有底下这些:
- 该文件的存取模式(read/write/excute);
- 该文件的拥有者与群组(owner/group);
- 该文件的容量;
- 该文件建立或状态改变的时间(ctime);
- 最近一次的读取时间(atime);
- 最近修改的时间(mtime);
- 定义文件特性的旗标(flag),如setuid…;
- 该文件真正的内容指向(pointer);
inode的数量与大小也是在格式化的时候就已经固定了,除次之外inode 还有一下特色
- 每个inode 大小均固定为128bytes;
- 每个文件都仅会占用一个inode;
- 文件系统能共建立的文件数量与inode的数量有关;
- 系统读取文件时需要先找到inode,并分析inode所记录的权限与用户是否符合,若符合才能够开始实际读取block的内容。
superblock(超级块)
superblock是记录整个filesystem相关信息的地方,没有superblock,就没有这个filesystem了。他记录的信息主要有:
block与inode的总量
未使用与已使用的inode/block数量;
block与inode 大小(block为1,2,4K,inode为128bytes);
filesystem的挂载时间、最近一次写入数据的时间、最近一侧检验磁盘(fsck)的时间等文件系统的相关信息;
一个valid bit数值,若此文件系统已被挂载,则valid bit为0,若未被挂载,则valid bit为1.
superblock是非常重要的,因为我们这个文件系统的基本信息都写在这里。一般来说,superblock的大小为1025bytes。
文件创建的过程是:
1.先查找一个空的inode
2.写入新的inode table
3.创建Directory,对应文件名,向block中写入文件内容
详细描述Linux权限管理体系。
- 权限集中管理目标:根据公司不同部门,不同职能,分等级,分层次的实现对Linux服务器的管理权限,最小化,规范化。以减少运维成本,消除安全隐患,提高工作效率,实现高质量的,快速化的完成项目进度以及日常系统维护。
- 重点解决问题:root权限泛滥,单个用户权限过大。用户权限认证必须是高可用的,并符合权限最小化原则。方案设计的原则:给用户尽可能少的权限但仍允许完成他们的工作。
- 用户权限集中管理主要实现三个功能:
- 规范、统一的权限认证,用户名和密码能正确匹配。
- 控制登录用户那些能做,那些不能做,根据所在组别进行区分授权。
- 记录登录用户登陆时间,命令操作等,所有登录信息和操作信息,集中至统一数据库,以便事后分析(日志审计)。
- 根据职能以及业务划分权限: 首先是相关系统(网络)管理人员的权限设定。再者就是普通工作人员:包括程序员、系统分析师、架构师、程序分析师、软件工程师、网站设计师、网站程序设计员等所有跟系统分析和系统开发相关岗位的工作人员。根据工作职能及业务需要分配权限。
权限集中管理作为运维管理的一部分,融入公司日常规范化管理,确定权限相关的申请、审批流程,规范后期服务器管理维护。
描沭你维护过的大规樽集群网站架构的设计原理。
运维技术问题
shell或者python脚本,增加nginx自定义指标做监控,如何做这个流程?
1.假如我们要监控Nginx 进程数量,可以使用系统命令获取监控值 2.shell或者python脚本,增加nginx自定义指标做监控 3.添加到zabix agent配置文件并重启 4到zabbix server使用zabbix_ get命令测试监控项能不能获取到监控值 5.在界面添加监控项或者制作模板等
nginx中配置CPU亲和性,worker_processes和work_cpu_affinity有什么好处
降低了系统对CPU和内存的开销,主要是nginx的工作进程内存开销和回收,一般来说 work_cpu_affinity配置为auto就可以了。
MySQL主从同步原理(或者说主从同步过程)?MySQL主从同步如何配置?
Master IO线程 Slave两个IO SQL线程 1、同步位置发给master IO线程 2、master读取指定同步位置开始到当前的binlog发给slave的IO线程 3、slave的IO线程将接受到的数据依次写入中继日志 4、slave的SQL线程读取中继日志并还原成SQL语句,然后逐条还原到从库
dockerfile打镜像的常用命令,如何减小镜像的体积?
# 第一问 命令省略 # 第二问 选择最精简的基础镜像 合并目的相同的命令,减少镜像的层数,比如RUN指令 清理镜像构建的中间产物 使用多阶段构建镜像(作为了解)
如何加速docker build构建镜像的过程?
1、变动越小的命令,越靠前,增加 cache 缓存使用率。 dockerfile中有可能导致缓存失效的命令WORKDIR、CMD、ENV、ADD等,像这些命令最好放到dockerfile底部,以便在构建镜像过程中最大限度使用缓存。 在 Docker 官方的最佳实践文档中要求,尽可能的使用 COPY,因为 COPY 的语义很明确,就是复制文件而已,而ADD 则包含了更复杂的功能,其行为也不一定很清晰。最适合使用ADD的场合,就是所 提及的需要自动解压缩的场合。另外需要注意的是,ADD 指令会令镜像构建缓存失效,从而可能会令镜 像构建变得比较缓慢。因此在 COPY 和 ADD 指令中选择的时候,可以遵循这样的原则,所有的文件复制均使用 COPY 指令,仅在需要自动解压缩的场合使用 ADD。 2、合并目的相同的命令,减少 layer 层数。 3、优化网络请求,使用国内源,或者内网服务加速构建。 4、少装些东西,不是代码依赖的就尽量别装了
dcoker容器有哪几种状态?
create running exited restart
nginx默认几种调度算法
round-robin 轮询 ip_hash:会话绑定 url_hash:url 做hash算法绑定
如何统计网站访问量
cat log| awk '{print $1}' | sort | uniq -n | sort -rn | head -10
有一个日志文件比较大导致空间占满,如果快速释放磁盘空间
截断式删除 > , echo "" > file
k8s中service是做什么的?
主要是做动态的发现后端主机的endpoint并提供负载均衡的一个入口。
有状态和无状态服务的区别
http请求无状态,多次请求之间没有依赖关系 有状态就是多次访问之间有关联关系,需要记录多次之间的访问关系
如何监控当前数据库的连接数?
Threads_connected ,表示当前连接数。准确的来说,Threads_running是代表当前并发数
haproxy有哪些调度算法
rr轮询 , lastconn最少连接,wrr ,ip_hash
4和7层负载均衡的区别是什么?
4层修改用户请求的目标路由直接转发到服务器 7层是把用户的报文拆分开,由负载均衡替代用户发送到服务端。同样的返回报文的时候先发给负载均 衡器,然后负载均衡修改报文后再发给用户。所以我们看到的日志的用户ip是负载均衡器的ip地址,因 此需要做ip透传x-forward
你最擅长什么
明确自己的职业规划,容器化方向,k8s,网络
1.1、说下公司的持续集成CICD
- 全部采用docker镜像安装, 避免环境因素造成安装问题
- 使用gitlab做代码仓库
- 使用jenkins做构建测试
- sonarQube静态代码扫描
基于ansible的代码发布 这些都是杰哥视频里面讲过的,一定要记清楚。
面试官继续会问之前公司开发环境、测试环境、发布是不是都用的同一个jenkins?测试环境人员权限如何分配?
你可以回答开发环境和测试环境用的是一个jenkins,测试环境人员权限需要给每个测试人员开通单独的账号,单独的权限,这样子保证每个人看到的是不同的项目。jenkins中管理员可以查看所有的项目,但是测试人员没必要这样子操作,精准一下权限的管控。基本上简单的几句话就可以了额。
关于权限这一块大家再去看看杰哥他们讲的视频,jenkins这块我是至少遇到两次问我权限怎么分配的。
1.2、网络上你遇到过哪些故障?丢包怎么解决的?
一般上这种问题问的不多,问的话可能是自建idc机房。所以遇到的网络问题比较多。
关于丢包问题,这种需要一一确认才行,整个链路中网卡设备,光纤,路由器,交换机等等都会出现故障,任何一个出现都会导致丢包问题,我个人遇到的丢包是光纤损坏,因为去机房明显看到光纤比较陈旧,使用的时间比较长了,一般来说交换机最不容易出现故障,基本用个7、8年都是都没问题的。
1.3、简单谈谈lvs和nginx两个负载均衡区别等等
关于lvs和nginx,如果面试官问你工作上用了nginx还是lvs,大家最好是说nginx,因为目前nginx已经很厉害了,并发方面做的相当优秀了,而国内的lvs,反而是中大型公司会去考虑使用这个,因此实际上使用lvs的不多额。而且lvs有一些天生的缺陷。lvs很多年没有更新了
1.5、docker用过吗?都做了哪些服务?
公司在用docker,目前还没有大范围使用,像redis、gitlab、jenkins、jumpserver等业务是跑在docker上的。
1.6、公司服务器的配置是怎么样的?
尽量往阿里云上面去说,然后跑了什么服务,用的大概哪种配置的服务器,关于配置,要把cpu型号,核心数。内存,硬盘这几个说清楚。其次有些服务比如数据的配置会高一点。如果对云服务器的计算优化型,存储优化性比较了解的也可以说说。
经典的dell R720 dellR730服务器。Cpu型号是E5-2650v3 双u。20h64gb等等。一定要记住一台服务器的型号。10G 100G
云服务器也要记住一个型号,说自己采用的是计算优化型,cpu是e5-2682 v4 。内存差不多16g等
1.7、公司的数据安全怎么做的?
多备份。比如MySQL,公司采用xtrabackup备份,然后增量备份等等。记住一些备份的选项,可能面试官会问。 然后是gitlab代码,每两天备份一次并上传到服务器上。
1.8、从运维角度做过哪些系统优化?
安全:禁用ssh的22端口,放在公网的机器一定去掉密码登录,而选择密钥登录的方式 防火墙要加上去。规则都要设置好(看情况)。 尽量使用普通用户登录系统,添加sudo权限。 系统:配置国内yum源,安装一些常见的软件工具pidstat,perf,htop等性能监控工具。 优化系统参数,比如调大文件描述符,tcp优化参数等
1.9、数据库的安全和优化怎么做的?
mysql服务,公司早期采用的普通机械硬盘到固态盘的更换。mysql调优参数,比如增大innode的buffer值。设置一定范围的连接数。还有sql语句的优化,协助开发优化查询,主要是看查询上是否有索引等等。 架构的优化,比如自己使用mycat设计了主从分离,然后把老王讲过的那些往上说就行了。
1.10、Linux 如何挂载硬盘到指定目录并且保证开机自动启动?
答:Linux使用mount命令来挂在硬盘至指定的目录。 fuser
mount常用的语法为: mount [options] source_disk destition_directory
Linux在开机自启动的时候如果要自动挂载硬盘,需要在/etc/fstab文件中添加挂载硬盘的信息即可。格式为:"设备文件 挂载点 文件系统类型 挂载选项 是否备份 是否自检"一共六段信息。
1.12、当根目录硬盘写满时,如何定位到哪个目录使用硬盘最多?
答:=du –sh /*= 命令即可,找到根目录下占用磁盘较大的目录之后,再进入此目录继续执行=du –sh *= 命令一直找到最终目录即可。本题还可以配合=–max-depth=参数来查找。
1.13、如何在 /data 下找到大小超过1G的文件?
答: find /data –size +1G -ctime +7 –type f| xargs mv
1.14、TCP/IP协议三次握手的过程
必会
1.15、如何查看网卡流量
列举几个常见的工具,比如nload,sar -n DEV 1 5 命令等等。接下来可能会问你如果无法安装这些工具你有什么思路查看网卡流量呢?这个就可以把我之前给大家分享的脚本拿出来,然后用shell脚本的方 式实现查看网卡流量。顺便提醒一下,最好的监控方式就是使用监控软件,比如zabbix,prometheus等等。
1.16、如何查看nginx并发连接数
两种方法, 一种是开启nginx的监控功能,也就是编译nginx的时候带上http_stub_status_module模块,然后就可以开启status功能,此时在web上面就可以查看到并发连接数信息 第二种就是使用netstat -n命令来获取。=netstat -n | awk '^tcp {++S[$NF]} END {for(a in S) printa, S[a]}'=
1.18、nginx日常参数优化都做过什么?动静分离做过吗?描述简单步骤
工作进程绑定,最大上传文件大小,事件驱动模型优化,文件描述符优化,防盗链,隐藏版本信息,对于404,502等默认页面的优化,从而对用户友好展示。防止ddos单ip并发连接的控制。status监控模块得开启等等。limit_rate限制上传速率。client_max_body_size允许用户上传的文件最大大小。
动静分离:要说做过,动静分离是让动态网站里的动态网页根据一定规则把不变的资源和经常变的资源区分开来,动静资源做好了拆分以后,我们就可以根据静态资源的特点将其做缓存操作,这就是网站静态化处理的核心思路,杰哥架构师视频里面把动静分离讲过,怎么操作,自己研究。
1.19、nginx做web服务器有处理过故障吗?
之前web服务报错413,查阅后发现是客户端请求的数据量太大,没有指定http请求最大大小。配置文件修改了client_max_body_size限制了请求体的大小,设置了50m,完全解决了问题。
504错误,请求后端服务的时候,后端服务很长时间才响应,查看错误日志后修改了proxy_read_timeout和proxy_read_time解决了问题。
1.20、MySQL主从原理?MySQL主从不同步的原因有哪些?你处理过没有?
主从原理自己下去看老王的视频,这里就不再多说了。
主从不同步的原因比如:机器宕机,网线故障,主键重复等等,然后接下来就说自己正好处理过由于主键重复造成数据不一致的问题。
这个最开始是我们的zabbix平台报警说主从故障了,我就赶紧登录系统查看是什么原因造成的。发现Slave_SQL_Running 值为 NO。然后就是查看主从库的日志,使用的是show slave status\G命令发现一个1062的错误,Error 'Duplicate entry for key1' on query,后来跟开发询问是否执行了什么操作,开发说在master上插入了一条记录,然而之前slave已经有该记录了,所以造成了主键重复的故障,我的方法就是在从库上把重复的主键记录删除,然后又重启了主从集群,然后问题就解决了。
1.21、ftp主动和被动的区别
1.22、nginx反向代理配置,此类url www.baidu.com/rufuse ,禁止访问,返回403
server_name www.baidu.com;
location /rufuse {
return 403;
}
1.23、如何使用iptables将本地80端口的请求转发到8080端口,当前主机的ip地址192.168.16.1,其中本地网卡为eth0。
iptables -t nat -A PREROUTING -p tcp -i eth0 --dport 80 -j DNAT --to 192.168.16.1:8080
1.24、nginx日志统计2020年10月18日10:00到12:00之间的IP访问量排名
cat nginx.log | grep "18/10/2020" | sed -n '/10:00:00/,/12:00:00/p' | awk '{print $1}' | sort|uniq -c |sort -nr
1.25、分布式文件系统是否有过了解
如果没用过就说没有用过。用过的话这个自己下去简单总结一下这方面的知识。
1.26、写一个nginx日志切割的脚本。
LOGS_PATH=/usr/local/nginx/logs/history CUR_LOGS_PATH=/usr/local/nginx/logs YESTERDAY=$(date -d "yesterday" +%Y-%m-%d) mv ${CUR_LOGS_PATH}/access.log ${LOGS_PATH}/access_${YESTERDAY}.log ## 像nginx主进程发送USR1信号,USR1信号是重新打开日志文件 kill -USR1 $(cat /usr/local/nginx/logs/nginx.pid)
cp可能会丢失当前0.1秒间的数据,mv不会。因为文件被nginx占用会打开一个文件描述符,mv移动文件时文件描述符会把它的指针移动到移动后的文件,此时向nginx发送USR1信号时会把日志写入到新的文件中,数据平滑转移
1.27、raid的几种模式,raid5空间利用率
这个面试题比较常见 raid0 提高读写性能,最少两块容量为N的硬盘,容量为2N raid1 提高数据安全性,提高读取性能,不能提高写入性能,2003自带raid1功能,最少两块容量为N的硬盘,容量为N raid10 先提高安全性,再提高性能,最少4块容量为N的硬盘,容量为2N,RAID10比RAID01在安全性方面要强(体现在容错率上) raid01 先提高性能,再提高安全性,最少4块容量为N的硬盘,容量为2N raid5 提升安全性,安全性低于raid10(三块盘的情况下),大文件读写没有优势,小文件读写能力低于raid10,最低三块盘,容量为2块盘
raid5空间利用率是?(N-1)/N
1.28、公司的日志收集架构都用了什么技术?有改进吗?
你可以说公司采用的是elk日志收集系统,最初的时候,filebeat采集数据,logstash处理数据,主要是做一些数据的格式化,制定字段的统计操作,然后es单节点存储数据,最后是kibana展示数据。然后说后来我们就进行了改进,主要是旧的日志收集架构存在一些问题: 1)当logstash挂掉之后,存在丢数据问题。因为之前是单节点的logstash,然后物理机故障了。 2)es也是单节点的,es也挂过,但是filebeat还是不断的推数据给logstash从而导致数据丢失。 这些都说明组件之间耦合度极高,所以后来我们就进行了优化。filebeat和logstash之间我们加了kafka用于临时缓存数据,并用于解藕日志消费程序耦合。logstash的话我们主要是使用多个logstash实例,有的处理业务日志,有的是慢查询日志等等。
1.29、工作上有遇到logstash方面的疑难问题吗?
遇到过,遇到过logstash的性能瓶颈,我们的做法就是增大内存和提高logstash的工作线程数量。除此之外还有jvm的调优,我们的一个标准就是jvm的设置堆内存的大小是物理机内存的一半。
个人精心准备
2.1、 讲一下LAMP和LNMP的区别。
LAMP架构中php作为apache的模块来处理php的请求,而在LNMP中,有独立的php-fpm服务,Nginx代理php-fpm服务,Nginx把php的请求通过代理的形式交给php-fpm处理。 由于apache和Nginx架构设计不同,Nginx对于静态文件的处理能力相对apache来说更强。
他可能会问你,在架构设计上有何不同呢?Nginx是基于事件驱动的模型,它只需要一个woker进程就可以支持上万个请求并发,而apache即使是最新版本,也是多线程多进程模型,apache要想支持更多并发,需要开启更多的线程。
2.2、说一下上一家公司的业务,比如核心业务是什么?
这个题需要结合你们公司的实际情况,描述你们公司做的是啥业务。并不是让你回答你维护的业务,而是说你们公司做的是啥。 核心业务就是最赚钱的那个业务。 千万别说你不清楚,否则对方会认为你的工作经历是编的,或者认为你根本就不关心公司的情况。希望大家看到这个题之后,要好好想想该怎么表达。
面试官很喜欢问上家公司的架构 这个如果大家有工作经验的,相信都知道怎么说,不管是网站,存储,虚拟化,容器架构等,有了解的就说自己的架构,如果不懂的,老王的课程讲的也有。比如网站+数据库。zabbix监控架构,jenkins cicd这一块杰哥讲的都很好,就说公司采用java语言。然后把你学习到的gitlab+jenkins+maven架构说上去。
2.3、公司服务器有多少台,分别做什么角色?
简单描述一下架构。 100多台服务器,可以说公司大大小小一共几个业务,最大的业务用了有10台服务器,其中最前端是nginx+keepalived,web服务器主要是tomcat,用了三台,数据库一主多从,用mycat作为中间件,另外还有一个redis服务器,作为缓存服务,redis采用的是哨兵模式,哨兵+shell脚本自动进行故障切换。还有日志收集elk,用来统计用户网站的pv访问量,接口访问延时统计,以及真实用户的来源绘制地图。zabbix作为监控服务,监控各个服务器的资源使用率,以及访问接口的延迟时间,邮件告警运维人员。
公司的业务不止这么一些,包括测试环境的服务器。或者其他业务,比如我们还接手一些超算集群的业务,这个集群更加庞大。
2.4、你们公司网站访问量有多大?
往小了说,比如说日pv在5w左右,这个量级,一两台服务器就足够支撑了。至于什么是pv、uv、IP、并发等概念,自己下去了解。
还有一点需要注意的,pv和uv之间的差距是10-50倍之间,比如日pv是100万,那么uv说个2-10之间就行了,千万不要说pv100万,uv90万,一听就是瞎扯。
如果你很了解这一块,给大家说个经验值,20台左右的服务器,并发大约是200万是可以支撑的,当然 如果你没有这一块的经验值,就不要说这个数字,因为里面牵扯到的系统优化太多了,不单单是应用的优化,还有系统,网络等参数的优化,所以就说个日pv在5-10w就可以了,并发差不多就是100-300左右
2.5、公司业务上线流程是怎样的?用什么工具上线?
公司使用jenkins上线部署代码。流程是,开发人员先在自己的电脑上开发功能代码,然后把代码推送 到gitlab,测试机通过webhook自动把代码拉取到测试机,开发人员会先做一次测试,功能没问题,会 把代码发布到预上线的机器上,此时测试人员才会测试,如果没问题,才会正式发布到生产环境。有时 候也会先灰度发布一两台生产环境。
2.6、公司的代码存在哪里?
存到了自建的gitlab上。
2.7、说一下你写过的规模最大的shell脚本是什么,描述一下该shell脚本的工作逻辑。
可以说那个监控脚本,老王的课堂也是写了不少脚本,都可以拿来参考。
2.8、懂python吗?用python写过什么项目?
学过python,基础语法没问题,没有写过大项目,但是写过不少python脚本。当然,如果你学了cmdb项目,并掌握了,可以说用django开发过一个小cmdb平台,基于阿里云api的。
2.9、你们公司的数据里有多大?MySQL是什么架构?
数据库的数据量,一般都不会太大,这个论坛www.55188.com,老牌的论坛,访问量日pv在100w左右,目前数据量有80G左右。这个量级已经很恐怖了。可能小公司的网站或者业务,数据量不会超过10G。 根据你们公司的实际情况,模拟吧。
这个80G的论坛,用到的架构也只是一主一从,而且都没有做读写分离,从库存在的意义仅仅是作为备用。当然,该业务的数据库服务器配置也是可以的,40核64G,平时负载1以下。我觉得大家不用说的多么牛逼,架构说一个一主二从+mycat已经足够了。这个不就是咱们大作业让大家做的架构么。
2.10、你在工作中遇到过什么比较棘手的问题?你是如何解决的?
这个就有些侧重于高级运维的面试题了。 1)udp flood 大流量攻击,流量180G,可能是竞争对手恶意攻击。解决方法只有一个,接入商业的防护,比如阿里云的高防IP或者知道创宇的创宇盾(他们去防300G都不是问题) 2)由于新来同事误操作,清空了一个表,导致业务中断了2小时,期间你是通过备份和binlog日志恢复的数据。后续,你做了一个延迟主从(延迟30分钟)防止误操作的情况。关于binlog的日志恢复,这一块咱们的企业教练都是讲过的额, 3)网站访问慢的故障排查 1、首先要确定是用户端还是服务端的问题。当接到用户反馈访问慢,那边自己立即访问网站看看,如果自己这边访问快,基本断定是用户端问题,就需要耐心跟客户解释,协助客户解决问题。 2、如果访问也慢,那么可以利用浏览器的调试功能,看看加载那一项数据消耗时间过多,是图片加载慢,还是某些数据加载慢。 3、针对服务器负载情况。查看服务器硬件(网络、CPU、内存)的消耗情况。如果是购买的云主机,比如阿里云,可以登录阿里云平台提供各方面的监控,比如 CPU、内存、带宽的使用情况。 4、如果发现硬件资源消耗都不高,那么就需要通过查日志,比如看看 MySQL慢查询的日志,看看是不是某条 SQL 语句查询慢,导致网站访问慢。
? 怎么去解决? 1、如果是出口带宽问题,那么久申请加大出口带宽。 2、如果慢查询比较多,那么就要开发人员或 DBA 协助进行 SQL 语句的优化。 3、如果数据库响应慢,考虑可以加一个数据库缓存,如 Redis 等等。然后也可以搭建MySQL 主从,一台 MySQL 服务器负责写,其他几台从数据库负责读。 4、申请购买 CDN 服务,加载用户的访问。 5、如果访问还比较慢,那就需要从整体架构上进行优化咯。做到专角色专用,多台服务器提供同一个服务。
2.11、举例说一下你对哪些应用程序做过调优?具体如何调优的?优化前后的变化是什么?
1)mysql的调优案例https://www.cnblogs.com/FengGeBlog/p/13867812.html 2)nginx的调优,网上例子很多,这里推荐一个 https://blog.csdn.net/zhydream77/article/details/89394310 3)tcp的一个优化,我们内部使用的一个应用程序,存储使用的是iscsi,但是应用程序偶尔出现连接存储异常导致整个服务不可用,报错的日志是iscsi connection error,tcp connection closed的错误,网上也没有相关的解决方案,我们临时的解决方案就是重启这个服务还有iscsi的连接,但是后期仍然有报错,。所以我们就是自己摸索。主要是报连接方面的错误,所以我们就着手查看tcp相关的资料,经过2天的研究,最终我们决定把一个参数改大点,就是net.core.somaxconn参数,原来是1024,我们修改成4096。然后几个月过去了问题再也没出现过。
2.12、Redis数据类型有几种?哪几种?
有5种:string、hash、集合、有序集合、列表
2.13、Redis数据持久化有几种? 区别是什么?
rdb和aof aof类似于mysql的二进制日志,它把所有的操作都记录在日志里。而rdb就是真正存储的数据,相当于把内存中redis的所有数据快照到了磁盘中。
2.14、你们公司有用到自动化运维工具吗?
有用到ansible,我们用ansible来更改一些服务的配置、管理计划任务、管理用户、还会批量执行一些命令或者脚本。
2.16、对于数据库的备份有没有做过有效性的检测?
有做过,我们每个月都会把备份数据还原到一个测试库上,用来验证备份的数据是否可用。这一块一定要记住备份的参数,如果数据量说的比较小,就是使用的是mysqldump来备份的,数据量比较大,就说使用的是xtrabackup工具备份,同时记住一些备份的参数。防止面试官问你等情况。
2.17、 数据有没有丢失过?有没有做过恢复?
没有丢过,做过故障演练,把备份数据恢复到一个测试库上。
2.18、你写过的shell脚本有多少?说一个你认为比较复杂的shell脚本。
从我工作以来,基本上每周都会写几个脚本,这样算下来大概有100多个(大概工作1年),其中一个最复杂的脚本是,写的计算公司业务的各种指标数据的脚本。 因为考虑的情况特别多,所以脚本最终写完大概有1000多行,函数有20多个。
2.19、作为运维工程师,你对该职位的认知和理解有哪些?日常工作应该怎么做呢?
负责服务的稳定性,确保服务可以7*24小时不间断的为用户提供服务,保证用户数据安全。提升用户体验 通过技术手段优化服务器和架构,降低公司成本 在工作中应该做什么? 1、监控,报警,线上部署 2、脚本自动化,工具自动化 3、故障处理 4、容器化业务迁移
2.20、docker 后端存储驱动 devicemapper、overlay 几种的区别?
面试官想考察的就是aufs、overlay 或者是 devicemapper 等几种存储驱动的区别。
AUFS (Another UnionFS)是一种 Union FS,是文件级的存储驱动,AUFS 简单理解就是将多层的文件系统联合挂载成统一的文件系统,这种文件系统可以一层一层地叠加修改文件,只有最上层是可写层,底下所有层都是只读层,对应到 Docker,最上层就是 container 层,底层就是 image 层,
Overlay 也是一种 Union FS,和 AUFS 多层相比,Overlay 只有两层:一个 upper 文件系统和一个lower 文件系统,分别代表 Docker 的容器层(upper)和镜像层(lower)。当需要修改一个文件时,使用 CopyW 将文件从只读的 lower 层复制到可写层 upper,结果也保存在 upper 层,
Device mapper,提供的是一种从逻辑设备到物理设备的映射框架机制,前面讲的 AUFS 和OverlayFS 都是文件级存储,而 Device mapper 是块级存储,所有的操作都是直接对块进行操作,而不是文件 我这里也只是简单说说,你要是能回答出来这些就很不错了哦。
2.21、k8s 创建一个pod的详细流程,涉及的组件怎么通信的?
k8s 创建一个 Pod 的详细流程如下: (1) 客户端提交创建请求,可以通过 api-server 提供的接口,或者是通过 kubectl 命令行工具,支持的数据类型包括 JSON 和 YAML。 (2) api-server 处理用户请求,将 pod 信息存储至 etcd 中。 (3) kube-scheduler 通过 api-server 提供的接口监控到未绑定的 pod,尝试为 pod 分配 node 节点,主要分为两个阶段,预选阶段和优选阶段,其中预选阶段是遍历所有的 node 节点,根据策略筛选出候选节点,而优选阶段是在第一步的基础上,为每一个候选节点进行打分,分数最高者胜出。 (4) 选择分数最高的节点,进行 pod binding 操作,并将结果存储至 etcd 中。 (5) 随后目标节点的 kubelet 进程通过 api-server 提供的接口监测到 kube-scheduler 产生的 pod 绑定事件,然后从 etcd 获取 pod 清单,下载镜像并启动容器。
2.23、k8s 架构体系了解吗?简单描述下
这道题主要考察 k8s 体系,涉及的范围其实太广泛,可以从本身 k8s 组件、存储、网络、监控等方面阐述, Master节点 Master节点主要有四个组件,分别是:api-server、controller-manager、kube-scheduler 和etcd。
api-server kube-apiserver 作为 k8s 集群的核心,负责整个集群功能模块的交互和通信,集群内的各个功能模块如 kubelet、controller、scheduler 等都通过 api-server 提供的接口将信息存入到 etcd 中,当需要这些信息时,又通过 api-server 提供的 restful 接口,如get、watch 接口来获取,从而实现整个 k8s集群功能模块的数据交互。
kube-scheduler kube-scheduler 简单理解为通过特定的调度算法和策略为待调度的 Pod 列表中的每个 Pod 选择一个最合适的节点进行调度,调度主要分为两个阶段,预选阶段和优选阶段,其中预选阶段是遍历所有的node 节点,根据策略和限制筛选出候选节点,优选阶段是在第一步的基础上,通过相应的策略为每一个候选节点进行打分,分数最高者胜出,随后目标节点的 kubelet 进程通过 api-server 提供的接口监控到 kube-scheduler 产生的 pod 绑定事件,从 etcd 中获取 Pod 的清单,然后下载镜像,启动容器。
ETCD 强一致性的键值对存储,k8s 集群中的所有资源对象都存储在 etcd 中。
Node节点 node节点主要有三个组件:分别是 kubelet、kube-proxy 和 容器运行时 docker 。
kubelet 在 k8s 集群中,每个 node 节点都会运行一个 kubelet 进程,该进程用来处理 Master 节点下达到该节点的任务,同时,通过 api-server 提供的接口定期向 Master 节点报告自身的资源使用情况,并通过cadvisor 组件监控节点和容器的使用情况。
kube-proxy kube-proxy 就是一个智能的软件负载均衡器,将 service 的请求转发到后端具体的 Pod 实例上,并提供负载均衡和会话保持机制,目前有三种工作模式,分别是:用户模式(userspace)、iptables 模式和 IPVS 模式。
2.24、k8s 中服务级别,怎样设置服务的级别才是最高的?
在 k8s 中,Qos 主要有三种类别,分别是 BestEffort、Burstable 和 Guaranteed,三种类别区别如下: BestEffort 什么都不设置(CPU or Memory),佛系申请资源。 Burstable Pod 中的容器至少一个设置了CPU 或者 Memory 的请求 Guaranteed Pod 中的所有容器必须设置 CPU 和 Memory,并且 request 和 limit 值相等。
2.25、kubelet 监控 Node 节点资源使用是通过什么组件来实现的
这道题主要考察 cAdvisor 组件。 cAdvisor 是用于监控容器运行状态的利器之一,在 Kubernetes 系统中,cAdvisor 已被默认集成到kubelet 组件内,当 kubelet 服务启动时,它会自动启动 cAdvisor 服务,然后 cAdvisor 会实时采集所在节点的性能指标及在节点上运行的容器的性能指标。kubelet 的启动参数 –cadvisor-port 可自定义 cAdvisor 对外提供服务的端口号,默认是 4194
2.26、CDN的工作原理
2.27、如何解决系统程序变更不停机?
- 服务间解耦与隔离,确保单次升级的范围和影响可控。
- 根据兼容性和依赖关系决定服务的升级顺序。在升级时,先升级那些没有外部依赖的服务。等到被依赖方升级完毕之后,再去升级依赖方。确定了每一个服务的升级顺序之后,我们再根据服务的实际情况确定升级方案。
- 根据服务是否无状态决定升级方式。无状态服务的特点使得它们很容易通过水平扩展来动态扩缩容。因此在保证兼容的前提下,它们的升级流程相对通用并且简单:有状态服务升级的麻烦之处在于,状态的存储、恢复、转移往往由服务根据实际情况单独设计因而升级较为困难
- 提前准备好监控和回滚方案,灰度升级。使用金丝雀发布或者蓝绿发布的方式,把风险降低到最小。
2.28、如何实现系统资源、服务等的监控、报警、及自动处理?
问题排查
这一块大家一定要记住两个案例,至少准备两个,这两个一定要背会排查的步骤,此外也一定要记住细节,细节到记录了某个参数,参数是什么,有什么作用。
1、cpu占用过高的问题 一个cpu占用过高的问题排查,要背会。如果公司没有使用java,就说自己是帮助客户排查故障的。 https://www.cnblogs.com/FengGeBlog/p/13860758.html
2、to many open files问题排查 这个问题是tomcat报错的,研发的同学部署好了一套应用,在测试环境,刚搭建好没多久,结果访问报404的错误,这个问题非常奇怪。就看了一下是什么问题
查看catalina.out文件之后,仔细看了一下,某个地方报错,显示的就是mant open files的错误。后来翻看了一下,这个错误报了好多次。应该是与这个问题有关,to mant open files的错误就是说程序打开的文件数过多,那么这里就是超过系统限制的文件数量以及通讯链接。
所以后来我就查看了这个系统上面的文件描述符的大小,发现是默认地1024,没有对其进行优化,我们的一个环境的默认优化是65535,看到出来这个测试环境的机器忘记进行了优化,我们的tomcat启动是使用的java用户进行启动,所以就在/etc/securiy/limit.conf文件内部专门针对java用户改了两个参数,把值都改为65535,然后这个问题就解决了。
3、为什么内存很充足但是java程序仍然申请不到内存。 用户有一台 8G 内存的实例,剩余内存还很多(7G 左右),而 java 程序使用了 4G 内存申请,直接抛出 OOM。
在程序日志发现oom的信息提示是申请4g内存失败。 1、那首先是拿到free -h,客户的是centos7系统,拿到available信息之后,发现就将近7g的内存可以申请使用 2、接下来只能通过其他的方式查看了,个人认为有可能是客户调的某些系统优化参数导致的,所以就打印了一下sysctl -p命令并着重查看与memory相关的参数、 3、刚开始没有查看到太大的问题,所以我觉得使用java命令去申请超出我的测试机器物理内存尝试一下,执行命令java -Xmx8192M -version然后拿到了报错。
大概执行了几次,第一次是java -Xmx4096M -version 第二次是java -Xmx5000M -version 第三次java -Xmx8192M -version 测试证明正常申请内存 是不会有问题的,只有超额的内存才会oom,那为什么会超额呢?这个问题当时也是纠结了一段时间,
后来再次查看sysctl -p命令,看到了vm.overcommit_memory=2这个参数,研究一下发现问题所在,这个值一共有三个,分别是0、1、 2。不同的值是不一样的
0 — 默认设置。:当应用进程尝试申请内存时,内核会做一个检测。内核将检查是否有足够的可用内存供应用进程使用;如果有足够的可用内存,内存申请允许;否则,内存申请失败,并把错误返回给应用进程。
举个例子,比如 1G 的机器,A 进程已经使用了 500M,当有另外进程尝试 malloc 500M 的内存时,内
核就会进行 check,
发现超出剩余可用内存,就会提示失败。
1:对于内存的申请请求,内核不会做任何 check,直到物理内存用完,触发 OOM 杀用户态进程。
同样是上面的例子,
1G 的机器,A 进程 500M,B 进程尝试 malloc 500M,会成功,但是一旦 kernel 发现内存使用率接近 1 个 G( 内核有策略 ),就触发 OOM,杀掉一些用户态的进程 ( 有策略的杀 )。
2:当 请求申请的内存 >= SWAP 内存大小 + 物理内存 * N,则拒绝此次内存申请。解释下这个
N:N 是一个百分比,
根据 overcommit_ratio/100 来确定,比如 overcommit_ratio=50(我的测试机默认 50%),那么N 就是 50%。
vm.overcommit_ratio只有当 vm.overcommit_memory = 2 的时候才会生效,内存可申请内存为SWAP 内存大小 + 物理内存 * overcommit_ratio/100
看看上面日志的 overcommit 信息
CommitLimit: 4004708 kB 小于客户申请的 4096M
Committed_AS: 2061568 kB
CommitLimit:最大能分配的内存 ( 测试下来在 vm.overcommit_memory=2 时候生效 ),具体的值是SWAP 内存大小(ecs 均未开启) + 物理内存 * overcommit_ratio / 100
Committed_AS:当前已经分配的内存大小
4、最后把主机的参数vm.overcommit_memory改为0,问题解决了。
4、系统出现大量的time_wait问题总结 一次意外,服务器遭受了ddos攻击,对我们造成了极大的影响,虽然我们把前端用户访问入口关闭暂停了ddos攻击,但是服务器端出现了大量的time-wait,导致的结果就是新建连接失败,而且占用了系统大量的资源,我们的临时解决方法就是这样的。
在系统配置里面添加两个参数
net.ipv4.tcp_tw_recycle = 1 net.ipv4.tcp_tw_reuse = 1 net.ipv4.tcp_fin_timeout = 300 net.ipv4.tcp_syncookies = 1
改成1之后,并执行sysctl -p命令立即生效,。然后就慢慢下来了。 mysqlbinlog binlogfile redis命令行–> info memory (maxmemory:10000000000bytes) ,config get maxmemory , config set maxmemory 20000000000
运维技能
脚本
$* : 脚本所有参数; 是以一个单字符串显示所有向脚本传递的参数,与位置变量不同,参数可超过9个,将所有的参数视为单个字符串。 $@ : 脚本所有参数;将命令行每个参数视为独立的字符串。 $? : 代表上一个命令执行后的退出状态, 0表成功,1表错误。
数字相加
seq -s+ 1 100 |bc echo {1..100} | tr ' ' '+' | bc sum=0;for i in {1..100};do let sum+=i;done ;echo sum=$sum for((sum=0,i=0;i<=100;i++));do let sum+=i; done; echo $sum # c语文风格 awk 'BEGIN{ total=0;i=1;while(i<=100){total+=i;i++};print total}' #比较快
read和输入重定向进行赋值
s8 scripts]#cat test.txt 1 2 [root@centos8 scripts]#read i j < test.txt ; echo i=$i j=$j i=1 j=2 [root@centos8 scripts]#echo 1 2 | read x y ; echo x=$x y=$y x= y= [root@centos8 ~]#echo 1 2 | ( read x y ; echo x=$x y=$y ) x=1 y=2 [root@centos8 ~]#echo 1 2 | { read x y ; echo x=$x y=$y; } x=1 y=2 [root@centos8 ~]#man bash
管理命令会运行在一个独立的子进程shell中,
# 关于 () 和 {}中多个命令组合 ( list ) 会开启子shell,并且list中变量赋值及内部命令执行后,将不再影响后续的环境, 帮助参看:man bash搜索(list) { list; } 不会启子shell, 在当前shell中运行,会影响当前shell环境, 帮助参看:man bash 搜索{ list; } 这里{ list; }& ; wait 方式实例并行处理。wait代表等待所有命令执行结束,不加wait最后要手动按回车键。
ip 地址获取
ip a | egrep -v 'inet6|127.0.0.1|\/32' | grep -Eow "(([1-9]?[0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])\.){3}([1-9]?[0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-4])" | head -n1 /sbin/ip a | egrep -v 'inet6|127.0.0.1|\/32' | awk -F'[ /]+' '/inet/{print $3}' | head -n1 /usr/sbin/ifconfig | egrep -v 'inet6|127.0.0.1|\/32' | sed -n '/inet /p'| awk '{print $2}' | tail -1 ip a |egrep -v 'inet6|127.0.0.1|\/32'|sed -nr "/inet /s/[^0-9]+([0-9.]+).*/\1/p"|head -n1 IP=$(ip -o -4 addr list ens33|perl -n -e 'if (m{inet\s([\d\.]+)\/\d+\s}xms) {print "$1"}')
业务
nginx
server_name 优先级
server_name NAME [...]; 后可跟一个或多个主机名;名称还可以使用通配符和正则表达式(~); (1) 首先做精确匹配;例如:www.cici.com (2) 左侧通配符;例如:*.cici.com (3) 右侧通配符,例如:www.cici.* (4) 正则表达式,例如:~^.*\.cici\.com$ (5) default_server
- location段优先级
1. = 严格匹配这个查询。如果找到,停止搜索。 2. ^~ 匹配路径的前缀,如果找到,停止搜索。 3. ~ 为区分大小写的正则匹配 4. ~* 为不区分大小写匹配 5.!~和!~*分别为区分大小写不匹配及不区分大小写不匹配
软件升级
- 软连接