Python: 数据结构-算法-设计模式
- TAGS: Python
Python 数据结构与算法
主要内容:
- 数据结构与算法的应用场景介绍
- 算法分析
- 数据结构性能
- 链表
- 列表数据结构
- 栈数据结构
- 队列数据结构
- 排序算法
- 搜索算法
- 树数据结构
- 树的遍历方法
- 树性质及应用
- 图数据结构
- 动态规划
数据结构-非线性数据结构-图
某一个节点上有一批任务需要执行,如何执行?
一个接一个排好队开始执行,但是这样的执行流程可能很没有效率,而且没有必要。举例,获取主机名和获取 IP 地址不需要严格的顺序,谁先执行都可以,同时执行也没有问题,这样的任务能并行就并行,不需要串行。
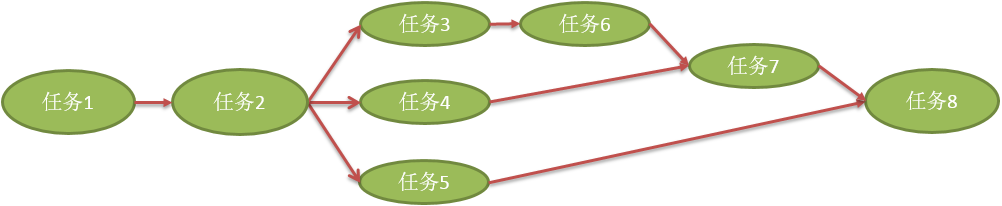
如何实现多个任务的流程执行呢?如何描述这样的任务呢?
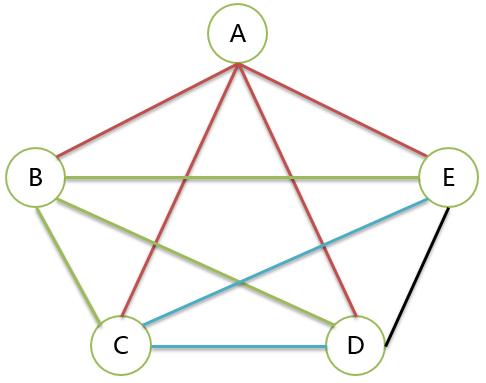
看上面的任务并行图,不能使用“树”来描述任务的关系。这里需要使用“图”来描述。
图 Graph
经典定义:图 Graph 由 顶点 和 边 组成,顶点的有穷非空集合为 V,边的集合为E,记作 G(V, E) 。
顶点 Vertex,数据元素的集合,顶点的集合,有穷非空;
边 Edge,数据元素关系的集合,顶点关系的集合,可以为空。
边可以有方向。
无向边记作 (A, B) 或者 (B, A) ,使用小括号。
有向边记作 <A, B> ,即从顶点 A 指向顶点 B。 <B, A> 表示顶点 B 指向顶点A。使用尖括号。
有向边也叫做 弧 ,边表示为 弧尾指向弧头 。
图重要概念
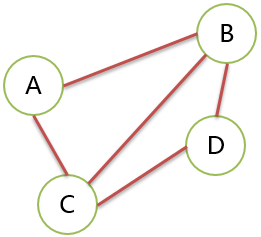
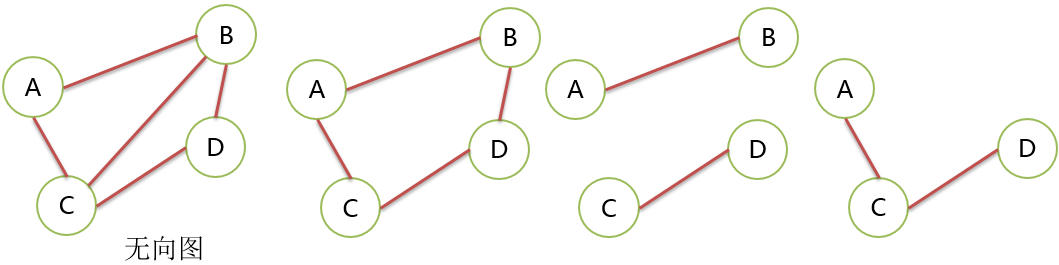
无向图 Undirected Graph
无方向的边构成的图。
G=(V,E) V={A,B,C,D} E={(A,B),(A,C),(B,C),(B,D),(C,D)}
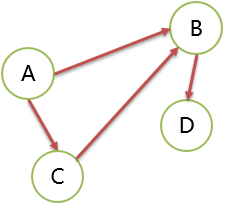
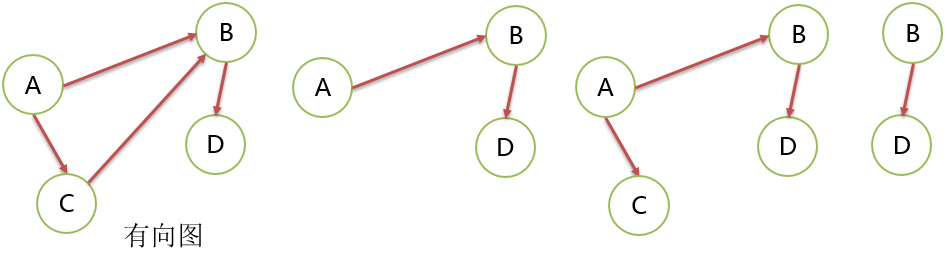
有向图 Directed Graph
有方向的边构成的图。 G=(V,E) V={A,B,C,D} E={<A,B>,<A,C>,<C,B>,<B,D>}
稀疏图 Sparse Graph
图中边很少。最稀疏的情况,只有顶点没有边,这就是数据结构 Set。
稠密图 Dense Graph
图中边很多。最稠密的情况,任意 2 个顶点之间都有关系。
完全图 Complete Graph
包括了所有可能的边,达到了稠密图最稠密的情况,任意 2 个顶点之间都有边相连。
有向的边的完全图,叫做有向完全图。边数为 n(n-1) 。
无向的边的完全图,叫做无向完全图。边数为 n(n-1)/2 。
| 顶点数 | 无向 | 有向 |
|---|---|---|
| 1 | 0 | 0 |
| 2 | 1 | 2 |
| 3 | 3 | 6 |
| 4 | 6 | 12 |
| 5 | 10 | 20 |
5边形,1+2+3+4,这就是1+2+…+(n-1)=n(n-1)/2
子图
如果图G(V, E)和G'(V', E') 满足V'≤ V且 E'≤E,则G'是 G的子图。
换句话说,就是一个图的部分顶点和部分边组成的图为子图,有向图要注意边的方向。
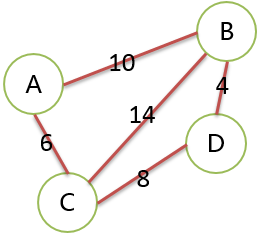
边的权 Weight
给边赋予的值称为权。权可以表示距离、所需时间、耗费的时间等。
约定,后面默认说的图,都是不带权的。
网 network
图中的边有权,图称为网。
自环 Loop
若一条边的两个顶点为同一个顶点,则此边称作自环。
边中存在这样一个边(u,v) 或者<u,v>,u=v。
简单图
无重复的边或者顶点到自身的边(自环)的图。
我们以后讨论的是简单图的性质。
下面 2 个图都不是简单图。
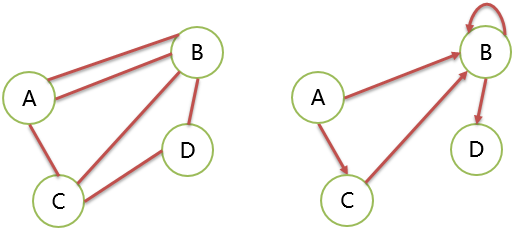
邻接
图的边集为 E。
无向图,若 (u,v) ∈ E ,则称 u 和 v 相互邻接,互为邻接顶点。
有向图,若 <u,v> ∈ E ,则称 u 邻接到 v,或 v 邻接于 u。
简单说,就是 2 点之间有条边,2 点邻接。
关联(依附)
若 (u,v) ∈ E 或者若 <u,v> ∈ E , 则称边依附于顶点 u、v 或顶点 u、v与边相关联。
这说的是点和边的关系。
度 Degree
一个顶点的度是指与该顶点相关联的边的条数,顶点 v 的度记作 TD(v)。
无向图顶点的边数叫做度。
有向图的顶点有入度和出度,顶点的度数为入度和出度之和 TD(v)=ID(v)+OD(v)。
- 入度(In-degree):一个顶点的入度是指与其关联的各边之中,以其为终点的边数。
- 出度(Out-degree):出度则是相对的概念,指以该顶点为起点的边数。
路径 Path
图 G(V,E) ,其任意一个顶点序列,相邻 2个顶点都能找到边或弧依次连接,就说明有路径存在。有向图的弧注意方向。所有顶点都属于V,所有边都必须属于 E。
路径长度:等于顶点数-1,等于此路径上的边数。
简单路径:路径上的顶点不重复出现,这样的路径就是简单路径。
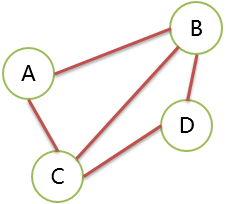
无向图中 A 到 D 的路径有 ABD、ABCD、ACD、ACBD 等。
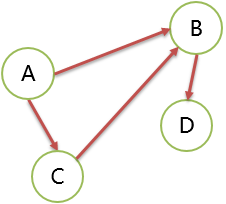
有向图中 A 到 D 的路径有 ABD、ACBD 等。
回路
路径的起点和终点相同,这条路径就是回路。
简单回路:除了路径的起点和终点相同外,其它顶点都不同。
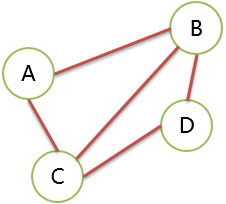
ABCD 就是简单路径。
ACDBA 就是简单回路。
ABCDBA 是回路,但是不是简单回路。
连通
无向图中,顶点间存在 路径 ,则两顶点是连通的。
注意:连通指的是顶点 A、D 间有路径,而不是说,这两个顶点要邻接。
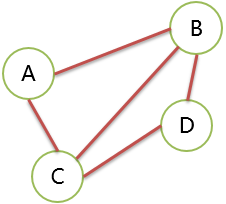
例如 A 到 D 存在路径,则 A、D 顶点是连通的。
连通图
- 无向图中,如果图中任意两个顶点之间都连通,就是连通图。
连通分量
- 无向图中,指的是“极大连通子图”。
- 无向图未必是连通图,但是它可以包含连通子图。
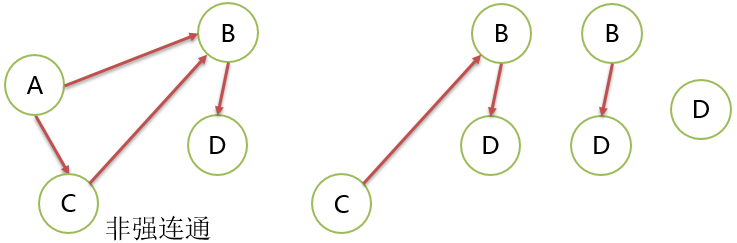
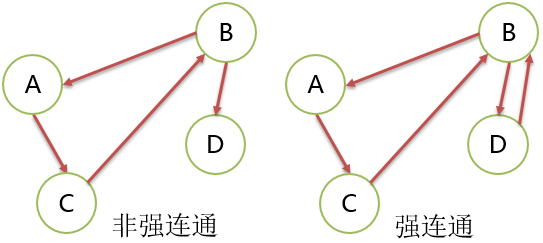
强连通
有向图中,顶点间存在 2 条相反的路径,即从 A 到 B 有路径,也存在从 B 到 A的路径,两顶点是强连通的。
下图就没有 2 个顶点是强连通的。
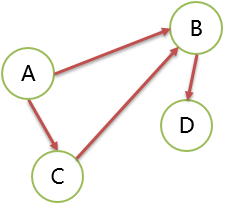
强连通图
- 有向图中,如果图中任意 2 个顶点都是强连通的图。
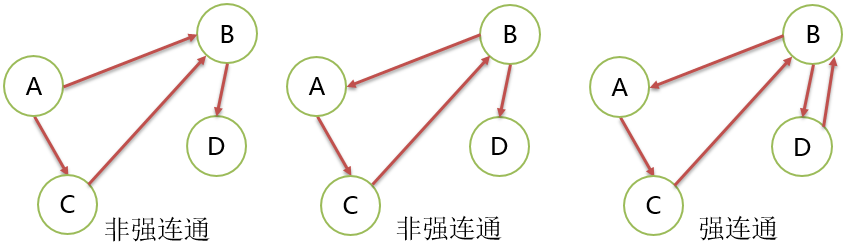
强连通分量
- 有向图中,指的是“极大强连通子图”。
- 有向图未必是强连通图,但是可以包含强连通的分量。
生成树Spanning Tree
对连通图进行遍历,所有经过的顶点和边的组合就可以看做是一个树,就是生成树。
它是一个 极小连通子图 ,它要包含图的 所有 n 个顶点,但只有足以构成一棵树的 n-1 条边。
- 如果一个图有n个顶点,且少于n-1条边,那么一定是非连通图。因为至少要n-1条边才行啊
- 如果一个图有n个顶点,且多于n-1条边,那么一定有环存在,一定有2个顶点间存在第二条路径。但是不一定是连通图,但是一定有环。
- 如果一个图有n个顶点,且有n-1条边,但不一定是生成树。要正好等于n-1条边,且这些边足以构成一棵树
特点
- 连通图的生成树不唯一
- 这些生成树顶点个数和边数相同,都是包含n个顶点和n-1条边
- 生成树不可能有环,添一条边就有环,少一条边就不连通。
最小生成树Minimum Spanning Tree
- 生成树中,图的边有权,那么边的权值之和最小的生成树,就是小生成树。
有向树
一个有向图恰好有一个入度为 0 的顶点,其他顶点的入度都为1。注意,这里不关心出度。
生成树森林:若干有向树构成有向树森林。
DAG
一个无环的有向图称做有向无环图(Directed Acyclic Graph),称为DAG
一个有向图中,任意一个顶点,都找不到一条能回到该顶点的路径。
有向无环图不一定能转化为树(因为可能有交叉),但是树一定是有向无环图
邻接矩阵
图是由 vertex 和 edge 组成,所以可以分成 2 个数组表示。
顶点用一维数组表示,例如 v0、v1、v2、v3。
边使用二维数组表示,由顶点构成的二维数组。
无向图表示示例,有 4 个顶点的无向图:
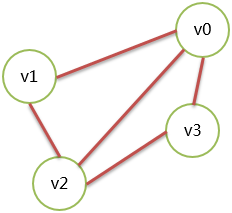
| v0 | v1 | v2 | v3 | ||
|---|---|---|---|---|---|
| v0 | 0 | 1 | 1 | 1 | |
| v1 | 1 | 0 | 1 | 0 | v1度数为2,2条边使用了这个顶点 |
| v2 | 1 | 1 | 0 | 1 | |
| v3 | 1 | 0 | 1 | 0 |
如果对角线上数字为 1,说明出现了自环。
如果除了对角线全是 1,说明没有自环,且是一个无向完全图。
上面的矩阵,称为 图的邻接矩阵 。
顶点的度数,等于对应的行或者列求和。
邻接点,矩阵中为 1 的值对应的行与列对应的顶点就是邻接点。
无向图的邻接矩阵是一个对称矩阵。
有向图表示示例,有 4 个顶点的有向图:
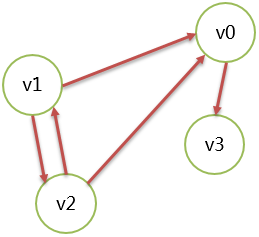
| v0 | v1 | v2 | v3 | ||
|---|---|---|---|---|---|
| v0 | 0 | 0 | 0 | 1 | |
| v1 | 1 | 0 | 1 | 0 | v1出度为2,边有 <v1,v0>、<v1,v2> |
| v2 | 1 | 1 | 0 | 0 | v2出度为2,边有 <v2,v0>、<v2,v1> |
| v3 | 0 | 0 | 0 | 0 | |
| v0入度为2 | v1入度为1 |
有向图的邻接矩阵不一定对称。对称的说明 2 个顶点间有环,例如 <v1,v2> 和 <v2,v1> 。
如何设计一个有向无环图
有向无环图 Directed Acyclic Graph,无环路的有向图。
思考:假设有下面的几种情况?
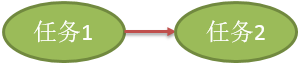
两个任务,任务本身就是顶点,任务先后执行。
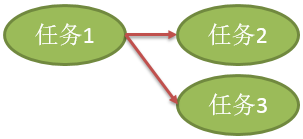
三个任务,任务 1 执行完后,才能分别执行任务 2 或者任务 3。
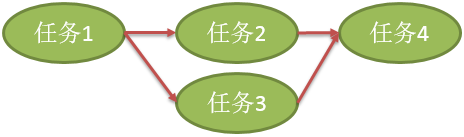
四个任务,任务 1 执行完后,才能分别执行任务 2 或者任务 3,最后执行任务4。
要思考任务 4 执行的前提是 “任务 2 or 任务 3 做完” 还是 “任务 2 and 任务3 做完” ?
可以看到任务的执行过程就是流程的设定(Pipeline),所以要设计一个流程系统来跑任务。
通过上面几个例子,思考:
- 如何选择执行的起点。
- 如何知道哪个任务是终点。
起点的选择
入度为 0 的顶点就是起始的点。
DAG 可以有多个起始点。
我们的系统约定有且只能有一个起始点。
终点的判断
出度为 0 的顶点,pipeline 执行结束。
Pipeline 可能有多个终点。
环路检查
Pipeline 设计的过程中应当注意避免出现环路,因为出现环路就不是 DAG 了。
自环检测,弧头指向顶点自身。
多顶点构成环路的检测。
环路检测必须实现,否则当定义好的流程执行起来,有可能进入环路后,永远执行不能终止。
构建模型
工具
模型构建的工具有很多,IBM Rational Rose(现在是 Rational Software Architect)、Sybase Power Designer等企业级建模工具。Oracle 也提供了一个MySQLWorkbench,使用它的社区版就可以开始模型设计了。
DAG 定义
使用数据库表的存储方式定义 DAG。
问题是如何使用数据库的表描述一个 DAG?
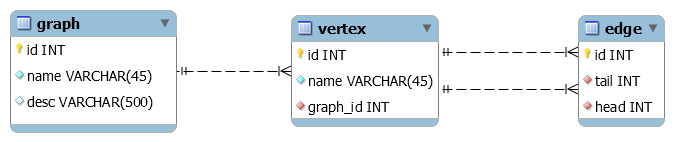
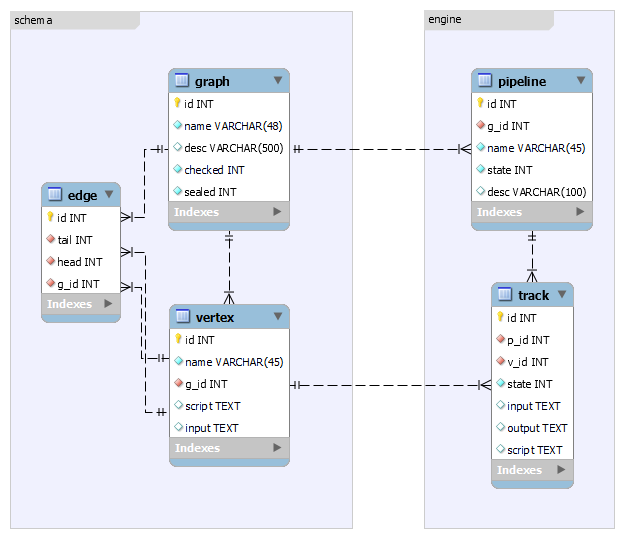
DAG 也是图,是图就有顶点、边,所以可以设计 2 个表,顶点表、边表来描述一个图。为了存储多个图,定义一个图的表。
一个图的定义包含了图的信息、顶点信息、边信息,一张图就是一个流程模板,顶点表示任务,边表示流向。
图 graph
| 字段名 | 类型 | 说明 |
|---|---|---|
| id | int | 主键 |
| name | varchar | 非空,唯一,图的名称 |
| desc | varchar | 可为空,描述 |
顶点表 vertex
| 字段名 | 类型 | 说明 |
|---|---|---|
| id | int | 主键 |
| name | varchar | 非空,顶点的名称 |
| g_id | int | 外键,描述顶点属于哪一个图 |
边表 edge
| 字段名 | 类型 | 说明 |
|---|---|---|
| id | int | 主键 |
| tail | int | 外键,弧尾顶点,顶点在 vertex 表中必须存在 |
| head | int | 外键,弧头顶点,顶点在 vertex 表中必须存在 |
| g_id | int | 外键,描述边属于哪一个图 |
通过弧尾、弧头顶点来描述有向边。
业务设计
任务设计
流程定义在表中,"任务"如何描述呢?
方法一:subprocess 执行 bash 脚本 script。
- 优点:简单,易行。
- 缺点:要启动外部进程。bash 脚本表达能力较弱,难调试。
方法二:嵌入其它语言的脚本,例如 lua 语言。
- 优点:不启动子进程,功能强大。
- 缺点:技术要求高,需要学习其它脚本语言。
python 中执行 lua 脚本,https://pypi.python.org/pypi/lupa/
安装:
$ pip install lupa
from lupa import LuaRuntime import logging logging.basicConfig(format="%(process)d %(thread)d %(message)s", level=logging.INFO) lua = LuaRuntime() print(lua.eval("1+3")) def pyfunc(n): import socket logging.info('hello') return socket.gethostname() luafunc = lua.eval(''' function(f,n) return f(n) end ''') logging.info('main') print(luafunc(pyfunc, 1)) add = lua.eval(''' function (x, y) return x+y end ''') print(add(4, 5))
其实,还可以运行 JS 脚本。
选择方法一,任务脚本样例如下,存储 shell 脚本文本就行了。
"echo www.brinnatt.com"
在表 vertex 中增加一个字段,存储脚本。
| 字段名 | 类型 | 说明 |
|---|---|---|
| id | int | 主键 |
| name | varchar | 非空,顶点的名称 |
| g_id | int | 外键,描述顶点属于哪一个图 |
| script | text | 可以为空,存储任务脚本 |
执行条件
脚本执行之前,可能需要提供一些参数,才能开始执行脚本。
依然在 vertex 表中增加 input 字段,定义输入参数的描述。
vertex 表
| 字段名 | 类型 | 说明 |
|---|---|---|
| id | int | 主键 |
| name | varchar | 非空,顶点的名称 |
| g_id | int | 外键,描述顶点属于哪一个图 |
| script | text | 可以为空,存储任务脚本 |
| input | text | 可以为空,存储json格式的输入参数定义 |
//json定义
{
"name1":{
"type":"",
"required":true
},
"name2":{
"type":"",
"required":true,
"default": 1
}
}
name就是参数的名称,后面定义该参数的类型、是否必须提供等属性。可以定义多个参数。
作用:进入某个节点的时候,就必须满足条件,提供足够的参数。
如果提供的参数满足要求,就进入节点,否则一直等待,直到参数满足要求。
如果满足了,才能去执行 script。
input 就是一个约束的定义。
任务执行
当流程走到某一个顶点的时候,读取任务即脚本,执行这个脚本。
如何执行?
手动执行或自动执行。
1、手动执行
流程走到这个顶点,等待用户操作,需要用户手动干预。例如输入该顶点任务需要的一些配置参数,等待用户输入后才能进行下一步;例如该顶点任务完成后由用户选择下一个执行顶点。
2、自动执行
自动填写 input,例如使用缺省值,来满足用户为交互式填写的时候自动补全数据。脚本执行后,自动跳转到下一个顶点。当然这个所谓自动,程序不会智能的选择路径,需要提前指定好,执行完脚本,就可以跳转到下一个顶点了。
任务流转设计
当流程走到某一个顶点的时候,读取任务即脚本,或手动流转,或自动流转。
手动流转,需要人工选择下一个顶点,可以提供可视化界面供用户方便的选择。
自动流转,就需要在信息中提供下一个节点的信息,供程序自动完成。
那么,如何区分一个顶点是否自动执行呢?
把 vertex 表中的 script 字段改为 json。
如果 next 不存在,则不能自动执行,需要手动操作。
如果 next 存在,则程序自动跳转。
{
"script":"echo brinnatt"
}
{
"script":"echo brinnatt",
'next':'B'
}
{
"script":"echo brinnatt",
'next':2
}
为了方便用户,next 可以提供 2 种类型参数:
int 表示使用 vertex 的 id;
str 表示使用 vertex 的 name,但是必须是同一个 graph id。同一个 DAG的定义中,要求顶点的名字不能冲突,所以可以用。
流程结束
如果进入一个节点,执行完脚本,先检测其出度为 0,执行完流程就结束了。
如何判断出度为 0 呢?
在 edge 表中,使用当前节点的顶点 ID 作为弧尾 t,找不到弧头 h的任何记录。
执行引擎设计
pipeline 设计
前面设计的仅仅是流程 DAG定义,可以认为这是一个模板定义,流程真正执行的时候需要记录执行这个流程的任务流的数据。DAG相当于类定义,pipeline 相当于实例,处理数据。
创建表 pipeline
| 字段名 | 类型 | 说明 |
|---|---|---|
| id | int | 主键 |
| g_id | int | 外键,指明使用的是哪一个流程DAG定义 |
| current | int | 外键,顶点id,表示当前走到哪一个节点 |
这个表以后还要添加其它字段,存储一些附加信息,例如谁加入的流程、执行时间等。
一个 pipeline 应该指定哪一个 DAG,并选择 DAG 的起点。因为 DAG可能有多个起点,即入度为 0 的顶点,需要指定。然后把这些信息记录在pipeline 表中,current 为起点顶点的 id。
提取 current 顶点的 input 信息,input为空,直接执行脚本,否则要等用户输入满足了,才能执行 script。
不管是手动流转还是自动流转,如果到了下一个节点,需要修改 current字段的值。
任务流执行完毕,修改最后一个节点的状态为完成。
举例:当前节点任务是打包,调用 maven 命令执行打包,先要提取input,要求用户输入 ip 地址、输出目录等信息,然后才能执行打包脚本。
历史轨迹设计
pipeline 表只能看到有哪些流程正在运行,但是究竟走了 DAG中的哪些节点,不清楚,执行节点前有输入了哪些参数也不清楚。
如何查看、回溯当前 pipeline 的执行轨迹?
track 表:
| 字段名 | 类型 | 说明 |
|---|---|---|
| id | int | 主键 |
| p_id | int | 外键,哪一个流程的历史 |
| v_id | int | 外键,顶点的ID,经过的历史节点 |
| input | text | 可以为空,输入的参数值 |
| output | text | 可以为空,任务的输出 |
状态设计
在 pipeline 表、track 表中增加 state字段,来描述在某个节点上执行的状态,是等待中,还是正在运行,还是成功或失败,还是执行完毕。
STATE_WAITING = 0
STATE_RUNNING = 1
STATE_SUCCEED = 2
STATE_FAILED = 3
STATE_FINISH = 4
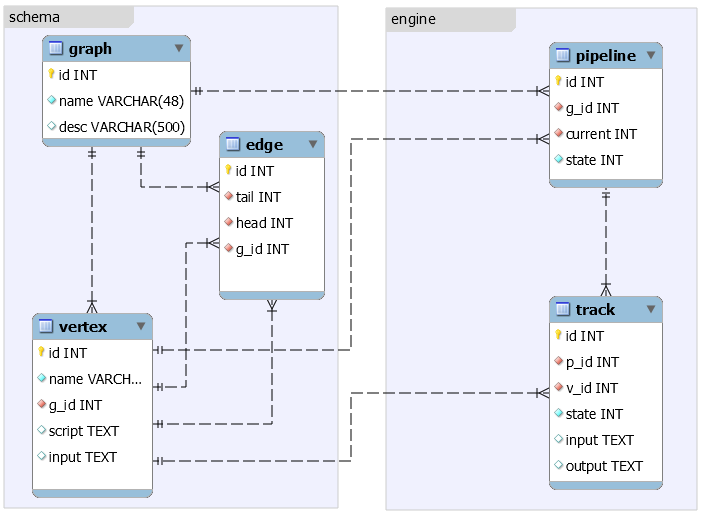
DAG 定义,需要 graph 表、vertex 表、edge 表。
Pipeline 执行,需要 pipeline 表、track 表。
模型:
DAG 检测
这需要用到图论的知识。
1、DFS 算法
DFS(Depth First Search)深度优先遍历,递归算法。
需要改进算法以适用于有向图。不能直接检测有向图是否有环。
2、拓扑排序算法
拓扑排序就是把有向图中的顶点以线性方式排序,如果有弧 <u,b> 则最后线性排序的结果,顶点 u 总是在顶点 v 的前面。
一个有向图能被拓扑排序的充要条件是:它必须是 DAG。
kahn 算法:
(1)选择一个入度为 0 的顶点并输出它
(2)删除以此顶点为弧尾的弧
重复上面 2 步,直到输出全部顶点为止,或者图中不存在入度为 0 的顶点为止。
如果输出了全部顶点,就是 DAG。
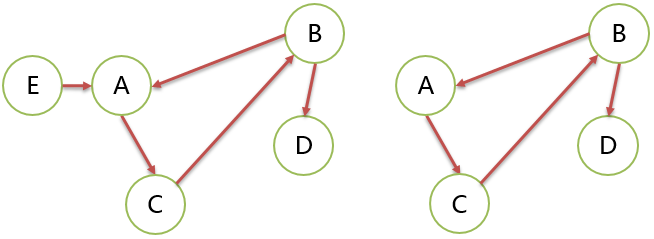
举例:
上图可以找到一个入度为 0 的顶点 A,从它开始,可以得到序列ACBD。最后输出了全部顶点。所以这个图是 DAG。
上面 2 个图都不是 DAG。左图一个环,右图 2 个环。
这 2 个图都找不到入度为 0 的起始顶点,都不是 DAG。
上图虽然可以找到入度为 0的顶点,但是移除它和关联的边,剩下顶点找不到入度为 0 的顶点,它不是DAG。
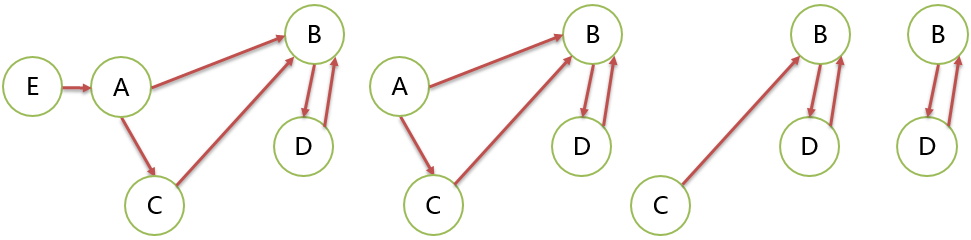
上图依然不是 DAG,B、D 之间有环。
代码实现
数据库模型入库:
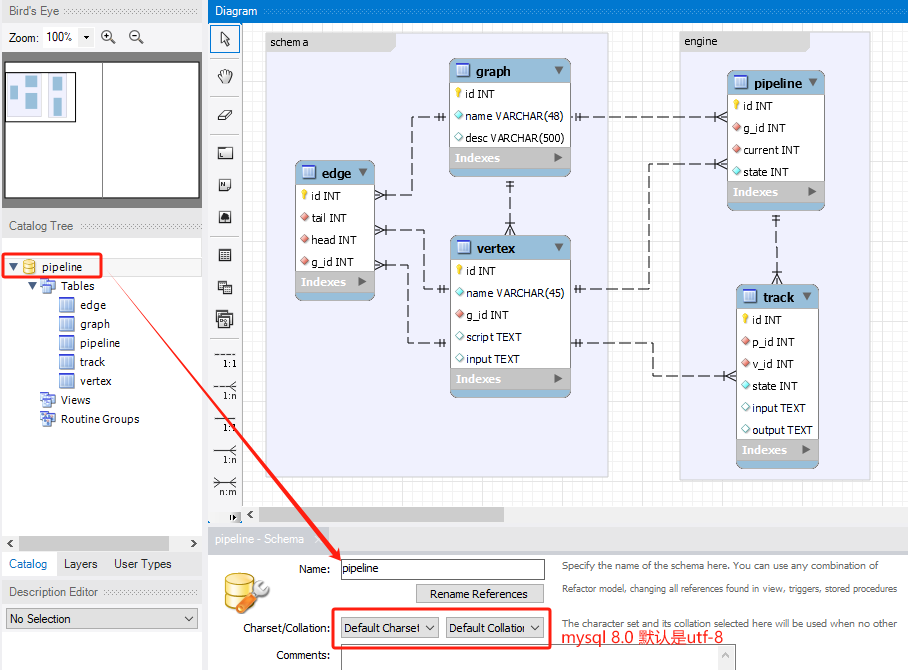
修改 Schema 即数据库的名称为 pipeline,然后使用模型生成数据库的表。
Database –> Forward Engineer 打开操作界面,按提示连接数据库,导入数据。
项目构建
新建一个项目,构建一个包 pipeline。
包下有:
config.py 公共配置
model.py ORM 映射
配置文件
config.py
USERNAME = 'brinnatt' PASSWD = 'brinnatt' DBIP = '192.168.136.131' DBPORT = 3306 DBNAME = 'pipeline' URL = f'mysql+pymysql://{USERNAME}:{PASSWD}@{DBIP}:{DBPORT}/{DBNAME}' DATABASE_DEBUG = True
单例模式
一个类只能实例化一次,只能拥有一个实例。
# 实现 1 import time class A: def __new__(cls, *args, **kwargs): print('~~~~~~~~~~~~') print(cls) print(args) print(kwargs) if not hasattr(cls, '_instance'): setattr(cls, '_instance', super().__new__(cls)) setattr(cls, '_count', 0) return cls._instance def __init__(self, url, debug): print('============') if self._count == 0: self.url = url self.debug = debug self.__class__._count = 1 else: raise Exception('Just One Instance') def __repr__(self): return "<B {} {}>".format(self.url, self.debug) b = A(1, debug=2) print(b.__dict__) time.sleep(2) b1 = A(10, 20) print(b1.__dict__)
装饰器实现:
# 单例装饰器 import functools def singleton(cls): instance = None @functools.wraps(cls) def getinstance(*args, **kwargs): nonlocal instance if not instance: print(args) print(kwargs) instance = cls(*args, **kwargs) return instance return getinstance @singleton class B: '''class B''' def __init__(self, url, debug): self.url = url self.debug = debug b = B(1, 2) print(id(b), b.__dict__, b.__doc__) b1 = B(10, 20) print(id(b1), b1.__dict__, b.__doc__)
Model 层
创建 ORM,封装数据操作类。
$ pip install sqlalchemy pymysql
model.py
from sqlalchemy import Column, Integer, String, Text, ForeignKey, create_engine from sqlalchemy.orm import relationship, sessionmaker from sqlalchemy.ext.declarative import declarative_base import functools from . import config STATE_WAITING = 0 STATE_RUNNING = 1 STATE_SUCCEED = 2 STATE_FAILED = 3 STATE_FINISH = 4 Base = declarative_base() # schema定义 # 图 class Graph(Base): __tablename__ = "graph" id = Column(Integer, primary_key=True, autoincrement=True) name = Column(String(48), nullable=False, unique=True) desc = Column(String(500), nullable=True) # 经常从图查看所有顶点、边的信息 # 这里必须使用foreign_keys,这是因为从一端查多端,其值必须使用引号 vertexes = relationship('Vertex', foreign_keys='Vertex.g_id') edges = relationship('Edge', foreign_keys='[Edge.g_id]') # 顶点表 class Vertex(Base): __tablename__ = "vertex" id = Column(Integer, primary_key=True, autoincrement=True) name = Column(String(48), nullable=False) input = Column(Text, nullable=True) # 输入参数 script = Column(Text, nullable=True) g_id = Column(Integer, ForeignKey('graph.id'), nullable=False) # graph = relationship('Graph') 一端或多端只需要一方定义即可,都定义会指示冲突 # 从顶点查它的边,这里必须使用foreign_keys,这是因为从一端查多端,其值必须使用引号 tails = relationship('Edge', foreign_keys='[Edge.tail]') heads = relationship('Edge', foreign_keys='Edge.head') # 边表 class Edge(Base): __tablename__ = 'edge' id = Column(Integer, primary_key=True, autoincrement=True) tail = Column(Integer, ForeignKey('vertex.id'), nullable=False) head = Column(Integer, ForeignKey('vertex.id'), nullable=False) g_id = Column(Integer, ForeignKey('graph.id'), nullable=False) # Engine # pipeline 表 class Pipeline(Base): __tablename__ = 'pipeline' id = Column(Integer, primary_key=True, autoincrement=True) g_id = Column(Integer, ForeignKey('graph.id'), nullable=False) current = Column(Integer, ForeignKey('vertex.id'), nullable=False) state = Column(Integer, nullable=False, default=STATE_WAITING) vertex = relationship('Vertex') class Track(Base): __tablename__ = 'track' id = Column(Integer, primary_key=True, autoincrement=True) p_id = Column(Integer, ForeignKey('pipeline.id'), nullable=False) v_id = Column(Integer, ForeignKey('vertex.id'), nullable=False) state = Column(Integer, nullable=False, default=STATE_WAITING) input = Column(Text, nullable=True) output = Column(Text, nullable=True) # 任务输出 vertex = relationship('Vertex') pipeline = relationship('Pipeline') # 后面使用方便 # 封装数据库的引擎、会话到类中 # 单例模式 def singleton(cls): instance = None @functools.wraps(cls) def getinstance(*args, **kwargs): nonlocal instance if not instance: print(args) print(kwargs) instance = cls(*args, **kwargs) return instance return getinstance @singleton class Database: def __init__(self, url, **kwargs): self._engine = create_engine(url, **kwargs) self._session = sessionmaker(bind=self._engine)() @property def session(self): return self._session @property def engine(self): return self._engine # 创建表 def create_all(self): Base.metadata.create_all(self._engine) # 删除表 def drop_all(self): Base.metadata.drop_all(self._engine) # 模块加载一次,db也是单例的 db = Database(config.URL, echo=config.DATABASE_DEBUG)
service 层
需求:
1、定义流程 DAG,即 Schema 定义。
2、执行某一个 DAG 的流程。
问题:
DAG 是否允许修改?
可以这样考虑,如果 DAG定义好还未使用,可以修改,一旦被使用过,不许修改。
所谓使用过,就是 pipeline 表中使用到了 graph 的主键 id,或者在 graph表中增加一个字段表示是否被使用过。
- DAG 定义
service.py
from .model import db from .model import Graph, Vertex, Edge from .model import Pipeline, Track # 创建DAG def create_graph(name, desc=None): g = Graph() g.name = name g.desc = desc db.session.add(g) try: db.session.commit() return g except: db.session.rollback() # 为DAG增加顶点 def add_vertex(graph: Graph, name: str, input=None, script=None): v = Vertex() v.g_id = graph.id v.name = name v.input = input v.script = script db.session.add(v) try: db.session.commit() return v except: db.session.rollback() # 为DAG增加边 def add_edge(graph: Graph, tail: Vertex, head: Vertex): e = Edge() e.g_id = graph.id e.tail = tail.id e.head = head.id db.session.add(e) try: db.session.commit() return e except: db.session.rollback() # 删除顶点 # 删除顶点就要删除所有顶点关联的边 def del_vertex(id): query = db.session.query(Vertex).filter(Vertex.id == id) v = query.first() if v: # 找到顶点后,删除关联的边,然后删除顶点 try: db.session.query(Edge).filter((Edge.tail == v.id) | (Edge.head == v.id)).delete() query.delete() db.session.commit() except: db.session.rollback() return v
通过上面的代码,可以发现事务的处理代码都差不多,提出来使用装饰器。
from .model import db from .model import Graph, Vertex, Edge from .model import Pipeline, Track from functools import wraps def transactional(fn): @wraps(fn) def wrapper(*args, **kwargs): ret = fn(*args, **kwargs) try: db.session.commit() return ret except Exception as e: print(e) db.session.rollback() return wrapper # 创建DAG @transactional def create_graph(name, desc=None): g = Graph() g.name = name g.desc = desc db.session.add(g) return g # 为DAG增加顶点 @transactional def add_vertex(graph: Graph, name: str, input=None, script=None): v = Vertex() v.g_id = graph.id v.name = name v.input = input v.script = script db.session.add(v) return v # 为DAG增加边 @transactional def add_edge(graph: Graph, tail: Vertex, head: Vertex): e = Edge() e.g_id = graph.id e.tail = tail.id e.head = head.id db.session.add(e) return e # 删除顶点 # 删除顶点就要删除所有顶点关联的边 @transactional def del_vertex(id): query = db.session.query(Vertex).filter(Vertex.id == id) v = query.first() if v: # 找到顶点后,删除关联的边,然后删除顶点 db.session.query(Edge).filter((Edge.tail == v.id) | (Edge.head == v.id)).delete() query.delete() return v
- 测试数据
编写 test.py,测试函数:
import json from pipeline.service import Graph, Vertex, db from pipeline.service import create_graph, add_vertex, add_edge # 测试数据 def test_create_dag(): try: # 创建DAG g = create_graph('test1') # 成功则返回一个Graph对象 # 增加顶点 input = { "ip": { "type": "str", "required": True, "default": "192.168.0.100" } } script = { "script": "echo 'test1.A'\nping {ip}", "next": "B" } # 这里为了让用户方便,next可以接收2种类型,数字表示顶点的id,字符串表示同一个DAG中该名称的节点,不能重复 a = add_vertex(g, 'A', json.dumps(input), json.dumps(script)) # next顶点验证可以在定义时,也可以在使用时 b = add_vertex(g, 'B', None, 'echo B') c = add_vertex(g, 'C', None, 'echo C') d = add_vertex(g, 'D', None, 'echo D') # 增加边 ab = add_edge(g, a, b) ac = add_edge(g, a, c) cb = add_edge(g, c, b) bd = add_edge(g, b, d) # 创建环路 g = create_graph('test2') # 环路 # 增加顶点 a = add_vertex(g, 'A', None, 'echo A') b = add_vertex(g, 'B', None, 'echo B') c = add_vertex(g, 'C', None, 'echo C') d = add_vertex(g, 'D', None, 'echo D') # 增加边, abc之间的环 ba = add_edge(g, b, a) ac = add_edge(g, a, c) cb = add_edge(g, c, b) bd = add_edge(g, b, d) # 创建DAG g = create_graph('test3') # 多个终点 # 增加顶点 a = add_vertex(g, 'A', None, 'echo A') b = add_vertex(g, 'B', None, 'echo B') c = add_vertex(g, 'C', None, 'echo C') d = add_vertex(g, 'D', None, 'echo D') # 增加边 ba = add_edge(g, b, a) ac = add_edge(g, a, c) bc = add_edge(g, b, c) bd = add_edge(g, b, d) # 创建DAG g = create_graph('test4') # 多入口 # 增加顶点 a = add_vertex(g, 'A', None, 'echo A') b = add_vertex(g, 'B', None, 'echo B') c = add_vertex(g, 'C', None, 'echo C') d = add_vertex(g, 'D', None, 'echo D') # 增加边 ab = add_edge(g, a, b) ac = add_edge(g, a, c) cb = add_edge(g, c, b) db = add_edge(g, d, b) except Exception as e: print(e) test_create_dag()
- DAG 验证
当增加一个 DAG 定义后,或修改了 DAG 定义,就需要对 DAG进行验证,判断是否是一个 DAG 图。如何知道一个写入数据库的 DAG是有效的呢?
在 graph 表增加一个字段 checked,为 1就是检测通过,以后可以创建一个流程执行,为 0 检测不通过。
注意,如果有一个流程使用了这个 DAG,它就不允许被修改和删除。
为了实现这个功能,且不要每一次都查询一下这个 DAG 被使用,可以在 graph表提供一个字段 sealed,一旦设置就不能修改和删除,表示有人用了。
在 DAG 定义后、修改后,就立即进行 DAG检验,这样使用的时候就不用每次都检验。
图 graph
字段名 类型 说明 id int 主键 name varchar 非空,唯一,图的名称 desc varchar 可为空,描述 checked int 不可为空,默认 0。0 表示经验证不能使用,1 表示可以创建执行流程 sealed int 不可为空,默认 0。0 表示未使用,1 表示已经有执行流程使用了,被封闭不可修改 # 图 class Graph(Base): __tablename__ = "graph" id = Column(Integer, primary_key=True, autoincrement=True) name = Column(String(48), nullable=False, unique=True) desc = Column(String(500), nullable=True) checked = Column(Integer, nullable=False, default=0) sealed = Column(Integer, nullable=False, default=0) # 经常从图查看所有顶点、边的信息 # 这里必须使用foreign_keys,这是因为从一端查多端,其值必须使用引号 vertexes = relationship('Vertex', foreign_keys='Vertex.g_id') edges = relationship('Edge', foreign_keys='[Edge.g_id]')
查找所有入度为 0 的顶点:
-- 找出graph id为1的所有顶点和边 select * from vertex v INNER JOIN edge e on v.g_id = e.g_id AND v.g_id = 1 -- 找出graph id为1的顶点和边,且弧尾是顶点的,因为左联,有head为null select * from vertex v LEFT JOIN edge e on v.g_id = e.g_id AND e.head = v.id WHERE v.g_id = 1 -- 增加一个条件edge head为null就可以提取出指定graph中入度为0的顶点 SELECT v.* FROM vertex v LEFT JOIN edge e ON v.g_id = e.g_id AND e.head = v.id WHERE v.g_id = 1 AND e.head IS NULL
采用左联在 edge 里面找 null 的方式,找入度为 0 的顶点。
但是这种找法不适合验证 DAG,因为第一批入度 0的顶点找到后,还需要再次查询,找第二批顶点。
能否换个思路呢?
把所有的顶点、边都先查一遍,然后在客户端数据结构中想办法处理,而不是多次来查询数据库。
kahn 算法实现
算法 1:
def check_graph(graph: Graph) -> bool: """验证是否是一个合法的DAG""" # 反正要遍历所有顶点和边,不如一次性把所有顶点和边都查回来,在内存中反复遍历 query = db.session.query(Vertex).filter(Vertex.g_id == graph.id) vertexes = [vertex.id for vertex in query] # 顶点列表 query = db.session.query(Edge).filter(Edge.g_id == graph.id) edges = [(edge.tail, edge.head) for edge in query] # ([1, 2, 3, 4], [(1, 2), (1, 3), (3, 2), (2, 4)]) # 遍历顶点,去找 while True: vis = [] # 就放一个索引,用列表是为了用的方便 for i, v in enumerate(vertexes): for _, h in edges: if h == v: # 当前顶点有入度 break else: # 没有break,说明遍历所有边,没有找到该顶点作为弧头,就是入度为0 ejs = [] for j, (t, _) in enumerate(edges): if t == v: # 找这个顶点的出度的边 ejs.append(j) vis.append(i) # 待移除的入度为0的顶点的索引 for j in reversed(ejs): # 逆向 edges.pop(j) break # 一旦找到入度为0的顶点,就需要从列表中删除,列表重新遍历 else: # 遍历一遍剩余顶点,都没有break,说明没有找到入度0的顶点 return False for i in vis: vertexes.pop(i) print(vertexes, edges) if len(vertexes) + len(edges) == 0: # 检验通过,修改checked字段为1 try: graph = db.session.query(Graph).filter(Graph.id == graph.id).first() if graph: graph.checked = 1 db.session.add(graph) db.session.commit() return True except Exception as e: db.session.rollback() raise e
算法思路:
一次把一个 DAG 的所有顶点、所有边都拿回来。
遍历顶点,拿出一个顶点,就去边列表中找它是否作为弧头,如果它是弧头,立即判断下一个顶点。如果这个顶点在边列表中都没有找到它作为弧头,就是入度为0 的顶点,就可以移除它作为弧尾的边和它本身了。
注意,因为移除会导致列表索引的变化,所以采用了先记录索引,后倒序删除索引的方式。
如果入度为 0的顶点和它作为弧尾的有向边都移除,最后剩下一个空图,就说明此图是DAG。空图的判断,使用非负整数相加为 0,则一定都是 0。
如果一轮遍历,没有找到入度为 0 的顶点,说明它不是 DAG。
算法 1 迭代次数太多了。
算法 2:
from collections import defaultdict def check_graph(graph: Graph) -> bool: query = db.session.query(Vertex).filter(Vertex.g_id == graph.id) vertexes = {vertex.id for vertex in query} query = db.session.query(Edge).filter(Edge.g_id == graph.id) edges = defaultdict(list) ids = set() # 有入度的顶点 for edge in query: # defaultdict(<class 'list'>, {1: [(1, 2), (1, 3)], 2: [(2, 4)], 3: [(3, 2)]}) edges[edge.tail].append((edge.tail, edge.head)) ids.add(edge.head) print('-=' * 30) print(vertexes, edges) # ===============测试数据=============== # {1, 2, 3, 4} # defaultdict(<class 'list'>, {1: [(1, 2), (1, 3)], 2: [(2, 4)], 3: [(3, 2)]}) # vertexes = {1, 2, 3, 4} # edges = {1: [(1, 2), (1, 3)], 2: [(2, 4)], 3: [(3, 2)]} # ids = set() # 有入度的顶点 # ===================================== if len(edges) == 0: return False # 一条边都没有,这样的DAG业务上不用 # 如果edges不为空,一定有ids,也就是有入度的顶点 zds = vertexes - ids # zds入度为0的顶点 # zds为0说明没有找到入度为0的顶点,算法终止 if len(zds): for zd in zds: if zd in edges: del edges[zd] while edges: # 将顶点集改为当前入度顶点集ids vertexes = ids ids = set() # 重新寻找有入度的顶点 for lst in edges.values(): for edge in lst: ids.add(edge[1]) zds = vertexes - ids print(vertexes, ids, zds) if len(zds) == 0: # 有环路 break for zd in zds: if zd in edges: # 有可能顶点没有出度 del edges[zd] print(edges) # 边集为空,剩下所有顶点都是入度为0的,都可以多次迭代删除掉 if len(edges) == 0: # 检验通过,修改checked字段为1 try: graph = db.session.query(Graph).filter(Graph.id == graph.id).first() if graph: graph.checked = 1 db.session.add(graph) db.session.commit() return True except Exception as e: db.session.rollback() raise e return False
算法思路:
还是一次把顶点、边都从数据库拿出来,减少和数据库的交互。
顶点 id 不可能重复,所以采用 set。
边从库中拿出的时候,就把弧尾作为字典 key 便于删除入度为 0 的顶点的边。
注意一点,只要边字典有值,就说明一定有入度不为 0 的顶点。
如果用当前的顶点集减去所有入度不为 0 的顶点集,结果有 2 种可能:
1、不为空集,说明这是入度为 0 的顶点集
2、空集,说明有环
判断依据:
- 如果边字典为空退出循环,说明已经没有边了,但是顶点集可能还有顶点。
- 如果顶点集还有顶点,都是入度为 0 的顶点,都可以移除的。
- 说明就是 DAG。
- 如果入度为 0 的顶点没有找到就退出。
- 如果边字典不为空,说明有环。
两种算法效率测试:
def check_graph1(graph=None) -> bool: """验证是否是一个合法的DAG""" # ===============测试数据=============== # ([1, 2, 3, 4], [(1, 2), (1, 3), (3, 2), (2, 4)]) vertexes = [1, 2, 3, 4] edges = [(1, 2), (1, 3), (3, 2), (2, 4)] # ===================================== # 遍历顶点,去找 while True: vis = [] # 就放一个索引,用列表是为了用的方便 for i, v in enumerate(vertexes): for _, h in edges: if h == v: # 当前顶点有入度 break else: # 没有break,说明遍历所有边,没有找到该顶点作为弧头,就是入度为0 ejs = [] for j, (t, _) in enumerate(edges): if t == v: # 找这个顶点的出度的边 ejs.append(j) vis.append(i) # 待移除的入度为0的顶点的索引 for j in reversed(ejs): # 逆向 edges.pop(j) break # 一旦找到入度为0的顶点,就需要从列表中删除,列表重新遍历 else: # 遍历一遍剩余顶点,都没有break,说明没有找到入度0的顶点 return False for i in vis: vertexes.pop(i) if len(vertexes) + len(edges) == 0: return True return False def check_graph2(graph=None) -> bool: """验证是否是一个合法的DAG""" # ===============测试数据=============== # {1, 2, 3, 4} defaultdict(<class 'list'>, {1: [(1, 2), (1, 3)], 2: [(2, 4)], 3: [(3, 2)]}) vertexes = {1, 2, 3, 4} edges = {1: [(1, 2), (1, 3)], 2: [(2, 4)], 3: [(3, 2)]} ids = set() # 有入度的顶点 # ===================================== if len(edges) == 0: return False # 一条边都没有,这样的DAG业务上不用 # 如果edges不为空,一定有ids,也就是有入度的顶点 zds = vertexes - ids # zds入度为0的顶点 # zds为0说明没有找到入度为0的顶点,算法终止 if len(zds): for zd in zds: if zd in edges: del edges[zd] while edges: # 将顶点集改为当前入度顶点集ids vertexes = ids ids = set() # 重新寻找有入度的顶点 for lst in edges.values(): for edge in lst: ids.add(edge[1]) zds = vertexes - ids if len(zds) == 0: # 有环路 break for zd in zds: if zd in edges: # 有可能顶点没有出度 del edges[zd] # 边集为空,剩下所有顶点都是入度为0的,都可以多次迭代删除掉 if len(edges) == 0: return True return False import datetime start = datetime.datetime.now() for _ in range(100000): check_graph1() print((datetime.datetime.now() - start).total_seconds()) start = datetime.datetime.now() for _ in range(100000): check_graph2() print((datetime.datetime.now() - start).total_seconds()) # 测试结果 0.211792 0.171121
算法 2 有明显优势,使用算法 2
from pipeline.service import Graph, db from pipeline.service import check_graph def test_check_all_graph(): query = db.session.query(Graph).filter(Graph.checked == 0).all() for g in query: if check_graph(g): g.checked = 1 db.session.add(g) try: db.session.commit() print('done') except Exception as e: db.session.rollback() raise e test_check_all_graph()
验证成功,就会设置 DAG 图的 checked 字段为 1。
业务上应该在创建一个新的 DAG 的时候立即验证,或在修改一个 DAG后立即验证。
- 如果边字典为空退出循环,说明已经没有边了,但是顶点集可能还有顶点。
流程系统
目前已经完成了流程定义的实现,下面要使用它来实现任务流程的流转。
目前设计存在如下问题:
- 用户是否需要频繁查取正在运行任务状态?需要的,使用 pipeline 表以减少对 track 的查询,提高效率。
- pipeline 表不能很好的描述多节点,如果描述当前运行的流程有分支,且正在执行的超过一个顶点,就不好描述了,因为每一个顶点都有自己的状态,这张表就要描述一对多关系,目前不适合。
- 如果一个流程有多起点,pipeline 如何描述?目前不适合。
- 如果一个流程任务对应的顶点大于 1
- 如何在 pipeline 表中表示,目前不适合。
- 运行条件是什么?要求前面所有任务都必须是成功状态。
graph LR A --> C --> D B --> C --> E
为了解决上面的问题:
- 目前 pipeline 表的设计不能很好地满足业务需求,直接废弃原有设计。将
pipeline 表改成用来记录任务流信息,字段有 g_id、name、desc、state 等。
- g_id 表示使用哪一个 DAG。
- name 任务流名称,例如 WEB 服务器检查。
- desc 任务流详细描述。
- state 记录整个任务流的状态,有 3 种。
- 有节点运行就是 STATE_RUNNING。
- 有节点失败就是 STATE_FAILED。
- 全部节点都成功就是 STATE_FINISH。
- 用 track 表来记录流程信息,一个任务流产生,在它这里记录数据,使用 pipeline 任务流 ID 即 p_id,并记录状态。
- 任务节点执行状态,有 5 种。没有 FINISH,它是描述整个任务流的。
- STATE_WAITING = 0
- STATE_PENDING = 1
- STATE_RUNNING = 2
- STATE_SUCCEED = 3
- STATE_FAILED = 4
- 如何解决频繁查询全部节点信息的状态?创建任务流时,从 vertex 表中复制到 track 表,所有顶点状态为 STATE_WAITING。起点要被设置为 STATE_PENDING。
- 如何解决反复查询当前正在执行的任务?在 state 字段上建立索引,提高查询效率。
- 什么是正在执行的任务节点?STATE_WAITING 表示等待执行,STATE_PENDING 表示入调度器准备执行,STATE_RUNNING 表示该此节点正在执行。
- 如何描述一个任务流执行完成了?
- 有一个任务顶点执行失败,则整个任务执行失败,所有节点不再继续执行。pipeline 中表示为 STATE_FAILED。
- 所有节点都成功 STATE_SUCCEED ,则将 pipeline 中的状态置为 STATE_FINISH。
- 如果一个流程有多起点,在所有节点信息复制到 track 表中的时候就将这些节点的状态置为 STATE_PENDING。
- 如果一个流程节点的入度大于 1,需要它的前驱节点都要是成功状态 STATE_SUCCEED,它才能被置为 STATE_PENDING。
- 如果流程节点执行完成,就是成功、失败这两种状态之一,这些状态都要写入 track 表,如果 track 表中该 p_id 的所有节点都成功,pipeline 中该任务状态 STATE_FINISH。
- 如果一个流程有多终点,同上,所有节点都必须成功,否则就是失败。
- 如果一个 DAG 定义中有孤立的顶点,如 A -> B C,C
是一个孤立的顶点,如何解决?
- 可以认为不合法,使用 =所有顶点集 - 所有边关联的顶点集 = 孤立顶点集=。
- 可以认为合法,就是一个入度为 0 的顶点,可以执行。可以认为是多起点,同时又是多终点。
- 本项目认为*合法*。
- 节点流转,要求其所有前驱节点必须是成功状态 STATE_SUCCEED。
- track 表增加记录用户操作的脚本 script 字段,减少使用 input 替换的时间。
模型设计修改如下:
model.py 修改:
class Pipeline(Base): __tablename__ = 'pipeline' id = Column(Integer, primary_key=True, autoincrement=True) g_id = Column(Integer, ForeignKey('graph.id'), nullable=False) # current = Column(Integer, ForeignKey('vertex.id'), nullable=False) name = Column(String(48), nullable=True) state = Column(Integer, nullable=False, default=STATE_WAITING) desc = Column(String(100)) # vertex = relationship('Vertex') # 从pipeline去查所有节点信息 tracks = relationship('Track', foreign_keys='Track.p_id') class Track(Base): __tablename__ = 'track' id = Column(Integer, primary_key=True, autoincrement=True) p_id = Column(Integer, ForeignKey('pipeline.id'), nullable=False) v_id = Column(Integer, ForeignKey('vertex.id'), nullable=False) state = Column(Integer,index=True, nullable=False, default=STATE_WAITING) # +索引 input = Column(Text, nullable=True) output = Column(Text, nullable=True) # 任务输出 script = Column(Text, nullable=True) vertex = relationship('Vertex') # pipeline = relationship('Pipeline') # 一端多端随便写一个即可,不要重复 def __repr__(self): return f"<{self.__class__.__name__} {self.id} {self.p_id} {self.v_id}" __str__ = __repr__
执行引擎
- 开启一个流程
开启一个流程的时候,需要在界面中选取一个 checked 为 1 的即验证过的 DAG。为流程起名、填写描述,提交。
创建一个流程后,得到流程 ID 即 p_id,将流程所有顶点加入到 track 表。
读取所有边,找出入度为 0 的顶点,这些顶点在 track 表中的状态置为RUNNING,其它非起点节点置为 WAITING。
如何用 SQL 找到入度为 0 的顶点?子查询实现:
SELECT id FROM vertex WHERE vertex.g_id = 1 AND id NOT IN ( SELECT head FROM edge WHERE edge.g_id = 1)
如何 sqlalchemy 实现这个子查询呢?
# 查询这个graph的所有顶点 vertexes = db.session.query(Vertex.id).filter(Vertex.g_id == graph.id) if not vertexes: return # 查出所有起点,入度为0,子查询实现 query = vertexes.filter(Vertex.id.notin_(db.session.query(Edge.head).filter(Edge.g_id == graph.id))) zds = {x[0] for x in query} # query每一个元素是一个元组 print(zds)
在 pipeline 包中新建一个 executor.py:
# executor.py from .model import Graph, Vertex, Edge, Pipeline, Track from .model import STATE_WAITING, STATE_PENDING, STATE_RUNNING from .service import transactional, db # 开启一个流程,用户指定一个名称、描述 @transactional def start(graph: Graph, name: str, desc=None): # 判断流程是否存在,且checked为1即检验过的 g = db.session.query(Graph).filter(Graph.id == graph.id).filter(Graph.checked == 1).first() if not g: return # 写入pipeline表 p = Pipeline() p.name = name p.desc = desc p.g_id = g.id p.state = STATE_RUNNING # 开启一个流程运行 db.session.add(p) # 查询这个graph的所有顶点全部 vertexes = db.session.query(Vertex.id).filter(Vertex.g_id == graph.id) if not vertexes: return # 查出所有起点,入度为0,子查询实现 query = vertexes.filter(Vertex.id.notin_( db.session.query(Edge.head).filter(Edge.g_id == graph.id) )) zds = {x[0] for x in query} # query是多条记录对象,每一条记录是一个元组,元组的元素取决于查了哪些字段 print("-->", zds) for v in vertexes: # 写入track表 t = Track() t.p_id = p.id t.v_id = v.id t.state = STATE_WAITING if v.id not in zds else STATE_PENDING db.session.add(t) print("-->", v, t.state, v.id) # 标记有人使用过了,sealed封闭 if g.sealed == 0: g.sealed = 1 db.session.add(g) return p
# test.py中 from pipeline.service import Graph from pipeline.executor import start # 测试start def test_start(): g = Graph() g.id = 1 p = start(g, '流程1') test_start()
- input 验证
开启一个流程后,顶点可能设置了input,这时候就要有一个界面,让用户填写参数。这是一个交互过程,也可以实现为自动填写参数。
获取参数后需要验证,验证失败要抛出异常,验证成功就用来替换执行脚本,生成可以运行的脚本。
然后将参数、脚本存入数据库的 track 表。
在 track 表添加 script 字段,存储执行的脚本。
input = { "ip":{ "type":"str", "required":True, "default":'127.0.0.1' } } required 是否必须,True则用户必须输入值,default缺省值忽略 default 缺省值,如果非必须值,用户没有填写了,使用缺省值 script = { 'script':'echo "test1.A"\nping {ip}', 'next': ['B'] } {ip} 占位符,用户提供参数后,使用名称ip进行替换
特别注意,如果使用 ping 命令测试,windows 默认 ping 4 下,Linux 下会一直ping 下去,所以如果使用 Linux 测试项目脚本,一定要注意使用
ping {ip} -c 4,此命令发送 4 个包就会停止命令。以下是 Linux ping 命令使用,注意命令的返回值。0 为正确执行。-w 指定秒数必须完成 ping 命令,如果没有完成都算失败。
[root@rocky ~]# ping www.baidu.com -w 8 -c 2; echo $? PING www.a.shifen.com (39.156.66.14) 56(84) bytes of data. 64 bytes from 39.156.66.14 (39.156.66.14): icmp_seq=1 ttl=128 time=43.7 ms 64 bytes from 39.156.66.14 (39.156.66.14): icmp_seq=2 ttl=128 time=44.5 ms --- www.a.shifen.com ping statistics --- 2 packets transmitted, 2 received, 0% packet loss, time 999ms rtt min/avg/max/mdev = 43.656/44.096/44.536/0.440 ms 0 [root@rocky ~]# [root@rocky ~]# ping www.baidu.com -w 1 -c 2; echo $? PING www.a.shifen.com (39.156.66.18) 56(84) bytes of data. 64 bytes from 39.156.66.18 (39.156.66.18): icmp_seq=1 ttl=128 time=44.8 ms --- www.a.shifen.com ping statistics --- 1 packets transmitted, 1 received, 0% packet loss, time 0ms rtt min/avg/max/mdev = 44.785/44.785/44.785/0.000 ms 1
返回指定流程的信息,比如说在浏览器中,获取当前流程的信息:
# executor.py中 # 查询流程的某种状态节点 @transactional def show_pipeline(id, state=STATE_PENDING): """显示指定的流程的信息""" p = db.session.query( Pipeline.id, Pipeline.name, Pipeline.state, Track.id, Track.v_id, Track.state, Vertex.input, Vertex.script). \ join(Track, (Track.p_id == id) & (Pipeline.id == Track.p_id)). \ join(Vertex, Track.v_id == Vertex.id). \ filter(Pipeline.state != STATE_FAILED). \ filter(Track.state == state) return p.all()
下面要模拟在浏览器中,看到了当前浏览器显示的信息,如果需要提供参数,就显示交互界面,让用户输入。
然后,数据提交,验证后,替换 script 脚本中的占位符,生成可以执行的脚本。
# test.py中 # 这部分代码模拟用户提供参数,形成一个字典 from pipeline.executor import show_pipeline import simplejson ps = show_pipeline(1) # 返回运行节点列表 print('-' * 30) print(ps) print('-' * 30) for p_id, p_name, p_state, t_id, v_id, t_state, inp, script in ps: print(p_id, p_name, p_state, t_id, v_id, t_state, inp, script) d = {} # 如果参数是必须,则交互,让用户提交 if inp: inp = simplejson.loads(inp) for k in inp.keys(): if inp[k].get('required1', False): d[k] = input(f'{k}=') print(d)
然后填充脚本 script:
# service.py中 import simplejson # 类型转换用 TYPES = { 'str': str, 'string': str, 'int': int, 'integer': int } @transactional def finish_params(t_id, d: dict, inp): """完成所有参数值""" params = {} # 最终的参数 if inp: print(inp) print(d) for k, v in inp.items(): print(k, v) val = d.get(k) if isinstance(val, TYPES.get(v['type'], str)): params[k] = val elif v.get('default'): # 类型不对,但是有缺省值 params[k] = v.get('default') else: raise TypeError('参数类型错误') # 将input存入数据库 track = db.session.query(Track).filter(Track.id == t_id).first() if track: track.input = simplejson.dumps(params) # 转成字符串 db.session.add(track) return params @transactional def finish_script(t_id, script: str, params: dict): '''使用参数替换脚本''' newline = '' if script: if isinstance(script, str): script = simplejson.loads(script).get('script') import re regex = re.compile(r'{([^{}]+)}') start = 0 for matcher in regex.finditer(script): newline += script[start:matcher.start()] print(matcher, matcher.group(1)) key = matcher.group(1) tmp = params.get(key, '') newline += str(tmp) start = matcher.end() else: newline += script[start:] # 把生成的script存入库 track = db.session.query(Track).filter(Track.id == t_id).first() if track: track.script = newline # 转成字符串 db.session.add(track) return newline
测试代码:
# test.py中 from pipeline.executor import show_pipeline from pipeline.executor import finish_params, finish_script import simplejson ps = show_pipeline(1) # 返回运行节点列表 print('-' * 30) print(ps) print('-' * 30) for p_id, p_name, p_state, t_id, v_id, t_state, inp, script in ps: print(p_id, p_name, p_state, t_id, v_id, t_state, inp, script) d = {} # 如果参数是必须,则交互,让用户提交 if inp: inp = simplejson.loads(inp) for k in inp.keys(): if inp[k].get('required', False): d[k] = input('{}= '.format(k)) print(d) params = finish_params(t_id, d, inp) print(params) # 准备好参数 print(script, '+++++++++') script = finish_script(t_id, script, params) print(script) # 拿到替换好的脚本,准备执行
# 数据库Track表如下 mysql> select * from track; +----+------+------+-------+-----------------------+--------+---------------------------------+ | id | p_id | v_id | state | input | output | script | +----+------+------+-------+-----------------------+--------+---------------------------------+ | 1 | 1 | 1 | 1 | {"ip": "172.16.10.8"} | NULL | echo 'test1.A' ping 172.16.10.8 | | 2 | 1 | 2 | 0 | NULL | NULL | NULL | | 3 | 1 | 3 | 0 | NULL | NULL | NULL | | 4 | 1 | 4 | 0 | NULL | NULL | NULL | +----+------+------+-------+-----------------------+--------+---------------------------------+ 4 rows in set (0.00 sec)
- 执行
执行脚本,脚本执行的是命令,而命令就是写好的程序,这些程序执行就是一个个进程。
python 有很多运行进程的方式,不过都过时了。建议使用标准库 subprocess模块,启动一个子进程。
class Popen: def __init__(self, args, bufsize=-1, executable=None, stdin=None, stdout=None, stderr=None, preexec_fn=None, close_fds=True, shell=False, cwd=None, env=None, universal_newlines=None, startupinfo=None, creationflags=0, restore_signals=True, start_new_session=False, pass_fds=(), *, user=None, group=None, extra_groups=None, encoding=None, errors=None, text=None, umask=-1, pipesize=-1):
shell 为 True,则使用 shell 来执行 args,建议 args 是一个字符串。
from subprocess import Popen, PIPE p = Popen('echo hello', shell=True, stdout=PIPE) code = p.wait() # 阻塞等,code为0是正确执行 text = p.stdout.read() # bytes print(code, text)
脚本执行的输出可能非常大,使用 PIPE 不太合适,使用临时文件模块:
from subprocess import Popen, PIPE from tempfile import TemporaryFile with TemporaryFile('w+') as f: p = Popen('echo hello brinnatt', shell=True, stdout=f) code = p.wait() # 阻塞等,code为0是正确执行 f.seek(0) text = f.read() print(code, text)
由于 wait 会阻塞,所以使用多线程,使用 subprocess 的 Popen开启子进程执行。但是开启线程后返回的结果就不能直接拿到了。使用concurrent.futures 来异步并发执行,并获取返回的结果。
先学习一个例子:
from concurrent.futures import ThreadPoolExecutor, as_completed import random import threading import time def test_func(sec, key): print(f'Enter --> {threading.current_thread()} {sec}s key={key}') threading.Event().wait(sec) if key == 3: raise Exception(f'{key} failed !!!!!!!!!!!') return f'ok {threading.current_thread()}' futures = {} def run(fs): print('-' * 30) time.sleep(1) print('-' * 30) print(fs) # 只要有一个任务没有完成就阻塞,完成一个,执行一次 # 如果内部有异常result()会将这个异常抛出 # 有异常也算执行完了complete # fs为空也不阻塞 for future in as_completed(fs): id = fs[future] try: print("Result", '-->', id, future.result()) except Exception as e: print('Error', '-->', e) print('Who', '-->', id, 'failed') threading.Thread(target=run, args=(futures,)).start() with ThreadPoolExecutor(max_workers=3) as executor: for i in range(7): futures[executor.submit(test_func, random.randint(1, 8), i)] = i # 运行结果 ------------------------------ Enter --> <Thread(ThreadPoolExecutor-0_0, started 14060)> 5s key=0 Enter --> <Thread(ThreadPoolExecutor-0_1, started 5524)> 1s key=1 Enter --> <Thread(ThreadPoolExecutor-0_2, started 16016)> 4s key=2 ------------------------------ {<Future at 0x1acb30257e0 state=running>: 0, <Future at 0x1acb3025ba0 state=running>: 1, <Future at 0x1acb3025ed0 state=running>: 2, <Future at 0x1acb30261a0 state=pending>: 3, <Future at 0x1acb3026260 state=pending>: 4, <Future at 0x1acb3026320 state=pending>: 5, <Future at 0x1acb30263e0 state=pending>: 6} Enter --> <Thread(ThreadPoolExecutor-0_1, started 5524)> 4s key=3 Result --> 1 ok <Thread(ThreadPoolExecutor-0_1, started 5524)> Enter --> <Thread(ThreadPoolExecutor-0_2, started 16016)> 1s key=4 Result --> 2 ok <Thread(ThreadPoolExecutor-0_2, started 16016)> Enter --> <Thread(ThreadPoolExecutor-0_0, started 14060)> 5s key=5 ResultEnter --> <Thread(ThreadPoolExecutor-0_1, started 5524)> 8s key=6 --> 0 ok <Thread(ThreadPoolExecutor-0_0, started 14060)> Error --> 3 failed !!!!!!!!!!! Who --> 3 failed Result --> 4 ok <Thread(ThreadPoolExecutor-0_2, started 16016)> Result --> 5 ok <Thread(ThreadPoolExecutor-0_0, started 14060)> Result --> 6 ok <Thread(ThreadPoolExecutor-0_1, started 5524)>
可以看出 as_completed 会盯着所有的future,完成一个,执行一个,直到所有的 future 完成。
执行器类实现:
# 调用执行器的execute方法,此方法会自动将任务提交,并异步执行 # executor.py中 from subprocess import Popen, PIPE from tempfile import TemporaryFile from concurrent.futures import ThreadPoolExecutor, as_completed import threading import uuid from queue import Queue class Executor: def __init__(self, workers=5): self.__pool = ThreadPoolExecutor(max_workers=workers) self.__event = threading.Event() self.__tasks = {} self.__queue = Queue() threading.Thread(target=self._run).start() threading.Thread(target=self._save_track).start() def _execute(self, script: str): with TemporaryFile('w+') as f: output = [] code = 0 for line in script.splitlines(): p = Popen(line, shell=True, stdout=f) code = p.wait() # 阻塞等,code为0是正确执行 f.seek(0) # 回到开头 text = f.read() output.append(text) code += code return code, '\n'.join(output) def execute(self, p_id, t_id, script: str): """异步执行方法,提交数据就行了,运行后,会提供运行结果,或返回失败""" key = uuid.uuid4().hex # uuid没有用上,只是说以后不重复key或id可以用uuid try: self.__tasks[self.__pool.submit(self._execute, script)] = (key, p_id, t_id) # future 对象 # 修改状态为准备执行RUNNING track = db.session.query(Track).filter(Track.id == t_id).one() track.state = STATE_RUNNING db.session.add(track) db.session.commit() except Exception as e: db.session.rollback() print(e) def _run(self): # 线程等待任务 while not self.__event.wait(1): for future in as_completed(self.__tasks): key, p_id, t_id = self.__tasks[future] try: code, text = future.result() del self.__tasks[future] self.__queue.put(p_id, t_id, code, text) except Exception as e: print(key, e) del self.__tasks[future] # 失败任务以后处理 TODO def _save_track(self): while not self.__event.is_set(): p_id, t_id, code, text = self.__queue.get() # 阻塞取 track = db.session.query(Track).filter(Track.v_id == t_id).first() track.state = STATE_SUCCEED if code == 0 else STATE_FAILED # 修改状态 track.output = text if code != 0: # 失败,必须立即将任务流状态设置为失败 track.pipeline.state = STATE_FAILED db.session.add(track) try: db.session.commit() except Exception as e: print(e) db.session.rollback() EXECUTOR = Executor() # 全局任务执行器对象
注意,有可能出现下面的错误:
'latin-1' codec can't encode characters in position 55-56: ordinal not in range(256)运行的没有问题,字符串也没有错误,甚至数据库客户端执行都没有问题,但是自己写的程序显示latin-1 长度超了。原因在于数据库连接没有设定字符集。
# config.py中对数据库连接指定字符集 USERNAME = 'brinnatt' PASSWD = 'WelC0me168!' DBIP = '192.168.136.131' DBPORT = 3306 DBNAME = 'pipeline' PARAMS = "charset=utf8mb4" URL = f'mysql+pymysql://{USERNAME}:{PASSWD}@{DBIP}:{DBPORT}/{DBNAME}?{PARAMS}' DATABASE_DEBUG = True
测试代码:
from pipeline.executor import show_pipeline, EXECUTOR from pipeline.service import finish_script, finish_params import simplejson ps = show_pipeline(1) # 返回运行节点列表 print('-' * 30) print(ps) print('-' * 30) for p_id, p_name, p_state, t_id, v_id, t_state, inp, script in ps: print(p_id, p_name, p_state, t_id, v_id, t_state, inp, script) d = {} # 如果参数是必须,则交互,让用户提交 if inp: inp = simplejson.loads(inp) for k in inp.keys(): if inp[k].get('required', False): d[k] = input('{}= '.format(k)) print(d) params = finish_params(t_id, d, inp) print(params) # 准备好参数 print(script, '+++++++++') script = finish_script(t_id, script, params) print(script) # 拿到替换好的脚本,准备执行 EXECUTOR.execute(p_id, t_id, script) # 异步执行
测试通过。
流转
手动流转以后实现。这里实现自动流转。
如何知道轮到哪个节点执行了?保持一定频率反复到 track表查询什么节点可以执行了吗?
为了减少对数据库的查询,最好的方式应该是由前一个节点成功完成后触发一次查询。
查询完成的节点的下一个节点是否存在、是否具备执行的条件等:
- 首先,需要在 pipeline 中查看当前任务状态是否已经失败,如果失败,则不再继续找下一个节点。否则成功执行,继续下面操作。
- 本节点成功执行,置为成功,在 track 表查询一下本任务流除自己之外还有没有其它节点在运行中,遍历所有其它节点。
- 首先判断如果有一个失败,就立即置 pipeline 的 state 为 STATE_FAILED。
- 如果其它节点都是成功,则置 pipeline 的 state 为 STATE_FINISH。
- 如果碰到一个 STATE_WAITING、STATE_RUNNING,就搜索下一级节点。
- 下一个节点
- 没有下一级节点,说明该节点是终点。是终点,不代表没有其它终点。本节点没有下一级它就不用管其它节点了,只需要把自己的状态置为成功就行了。
- 如果节点没有执行失败,一定会成功执行,其它节点继续执行,如果最后一个终点执行完,会发现其他节点全是成功状态,所以它将 pipeline 的 state 置为 STATE_FINISH 就可以了。
测试数据准备:
# 由于将script格式更改了,所以重新提供该函数 # 测试数据 def test_create_dag(): try: # 图1 创建DAG g = create_graph('test1') # 成功则返回一个Graph对象 # 增加顶点 input = { "ip": { "type": "str", "required": True, "default": "127.0.0.1" } } script = { 'script': 'echo "test1.A"\nping {ip}', 'next': 'B' } # 这里为了让用户方便,next可以接收2种类型,数字表示顶点的id,字符串表示同一个DAG中该名称的节点,不能重复 a = add_vertex(g, 'A', json.dumps(input), json.dumps(script)) # next顶点验证可以在定义时,也可以在使用时 b = add_vertex(g, 'B', None, '{"script":"echo B"}') c = add_vertex(g, 'C', None, '{"script":"echo C"}') d = add_vertex(g, 'D', None, '{"script":"echo D"}') # 增加边 ab = add_edge(g, a, b) ac = add_edge(g, a, c) cb = add_edge(g, c, b) bd = add_edge(g, b, d) # 图2 创建环路 g = create_graph('test2') # 环路 # 增加顶点 a = add_vertex(g, 'A', None, '{"script":"echo A"}') b = add_vertex(g, 'B', None, '{"script":"echo B"}') c = add_vertex(g, 'C', None, '{"script":"echo C"}') d = add_vertex(g, 'D', None, '{"script":"echo D"}') # 增加边, abc之间的环 ba = add_edge(g, b, a) ac = add_edge(g, a, c) cb = add_edge(g, c, b) bd = add_edge(g, b, d) # 图3 创建DAG g = create_graph('test3') # 多个终点 # 增加顶点 a = add_vertex(g, 'A', None, '{"script":"echo A"}') b = add_vertex(g, 'B', None, '{"script":"echo B"}') c = add_vertex(g, 'C', None, '{"script":"echo C"}') d = add_vertex(g, 'D', None, '{"script":"echo D"}') # 增加边 ba = add_edge(g, b, a) ac = add_edge(g, a, c) bc = add_edge(g, b, c) bd = add_edge(g, b, d) # 图4 创建DAG g = create_graph('test4') # 多入口 # 增加顶点 a = add_vertex(g, 'A', None, '{"script":"echo A"}') b = add_vertex(g, 'B', None, '{"script":"echo B"}') c = add_vertex(g, 'C', None, '{"script":"echo C"}') d = add_vertex(g, 'D', None, '{"script":"echo D"}') # 增加边 ab = add_edge(g, a, b) ac = add_edge(g, a, c) cb = add_edge(g, c, b) db = add_edge(g, d, b) except Exception as e: raise e
流转代码实现:
class Executor: def __init__(self, workers=5): self.__pool = ThreadPoolExecutor(max_workers=workers) self.__event = threading.Event() self.__tasks = {} self.__queue = Queue() threading.Thread(target=self._run).start() threading.Thread(target=self._save_track).start() def _execute(self, script: str): with TemporaryFile('w+') as f: output = [] code = 0 for line in script.splitlines(): p = Popen(line, shell=True, stdout=f) code = p.wait() # 阻塞等,code为0是正确执行 f.seek(0) # 回到开头 text = f.read() output.append(text) code += code return code, '\n'.join(output) def execute(self, p_id, t_id, script: str): """异步执行方法,提交数据就行了,运行后,会提供运行结果,或返回失败""" key = uuid.uuid4().hex # uuid没有用上,只是说以后不重复key或id可以用uuid try: self.__tasks[self.__pool.submit(self._execute, script)] = (key, p_id, t_id) # future 对象 # 修改状态为准备执行RUNNING track = db.session.query(Track).filter(Track.id == t_id).one() track.state = STATE_RUNNING db.session.add(track) db.session.commit() except Exception as e: db.session.rollback() raise e def _run(self): # 线程等待任务 while not self.__event.wait(1): for future in as_completed(self.__tasks): key, p_id, t_id = self.__tasks[future] try: code, text = future.result() del self.__tasks[future] self.__queue.put((p_id, t_id, code, text)) except Exception as e: print(key, e) del self.__tasks[future] # 失败任务以后处理 TODO def _save_track(self): while not self.__event.is_set(): p_id, t_id, code, text = self.__queue.get() # 阻塞取 track = db.session.query(Track).filter(Track.v_id == t_id).first() track.state = STATE_SUCCEED if code == 0 else STATE_FAILED # 修改状态 track.output = text if code != 0: # 失败,必须立即将任务流状态设置为失败 track.pipeline.state = STATE_FAILED else: # +++++++++++ 流转代码 +++++++++++ # 所有其他节点 others = db.session.query(Track).filter((Track.p_id == p_id) & (Track.v_id != t_id)).all() # 等待,待运行, 运行,成功,失败 states = {STATE_WAITING: 0, STATE_PENDING: 0, STATE_RUNNING: 0, STATE_SUCCEED: 0, STATE_FAILED: 0} for other in others: states[other.state] += 1 print('+' * 30) print(states, len(others)) print('+' * 30) if states[STATE_FAILED] > 0: track.pipeline.state = STATE_FAILED elif states[STATE_SUCCEED] == len(others): # 除了它之外全是成功说明全部成功 track.pipeline.state = STATE_FINISHED else: # 说明还有没运行完的节点,开始找下一级节点们 nexts = db.session.query(Edge).filter(Edge.tail == track.v_id).all() if nexts: # 有下一级,将这些节点的state改为STATE_PENDING for next in nexts: print(next.head) t = db.session.query(Track).filter(Track.v_id == next.head).one() t.state = STATE_PENDING db.session.add(t) else: # 没有下一级,是终点 # 如果自己是多终点的最后的一个终点,那么其他节点都是成功的 # 在上面的判断states[STATE_SUCCEED] == len(others)就成立了 pass # +++++++++++ 流转代码 +++++++++++ db.session.add(track) try: db.session.commit() except Exception as e: db.session.rollback() print(e) EXECUTOR = Executor() # 全局任务执行器对象
循环测试代码如下:
while True: ps = show_pipeline(1) # 返回运行节点列表 print('-' * 30) print(ps) print('-' * 30) time.sleep(1) print('~~~~~~~~~~~~~ sleeping ~~~~~~~~~~~~') for p_id, p_name, p_state, t_id, v_id, t_state, inp, script in ps: print(p_id, p_name, p_state, t_id, v_id, t_state, inp, script) d = {} # 如果参数是必须,则交互,让用户提交 if inp: inp = simplejson.loads(inp) for k in inp.keys(): if inp[k].get('required', False): d[k] = input('{}= '.format(k)) print(d) params = finish_params(t_id, d, inp) print(params) # 准备好参数 print(script, '+++++++++') script = finish_script(t_id, script, params) print(script) # 拿到替换好的脚本,准备执行 EXECUTOR.execute(p_id, t_id, script) # 异步执行
至此主流程已经完成,可以继续扩展功能和 bug 调试。
完整代码
config.py
USERNAME = 'brinnatt' PASSWD = 'WelC0me168!' DBIP = '192.168.136.131' DBPORT = 3306 DBNAME = 'pipeline' CHARSET = 'utf8mb4' URL = f'mysql+pymysql://{USERNAME}:{PASSWD}@{DBIP}:{DBPORT}/{DBNAME}?charset={CHARSET}' DATABASE_DEBUG = True
model.py
from sqlalchemy import Column, Integer, String, Text, ForeignKey, create_engine from sqlalchemy.orm import relationship, sessionmaker from sqlalchemy.ext.declarative import declarative_base import functools from . import config STATE_WAITING = 0 STATE_PENDING = 1 STATE_RUNNING = 2 STATE_SUCCEED = 3 STATE_FAILED = 4 STATE_FINISHED = 5 Base = declarative_base() # schema定义 # 图 class Graph(Base): __tablename__ = "graph" id = Column(Integer, primary_key=True, autoincrement=True) name = Column(String(48), nullable=False, unique=True) desc = Column(String(500), nullable=True) checked = Column(Integer, nullable=False, default=0) sealed = Column(Integer, nullable=False, default=0) # 经常从图查看所有顶点、边的信息 # 这里必须使用foreign_keys,这是因为从一端查多端,其值必须使用引号 vertexes = relationship('Vertex', foreign_keys='Vertex.g_id') edges = relationship('Edge', foreign_keys='[Edge.g_id]') # 顶点表 class Vertex(Base): __tablename__ = "vertex" id = Column(Integer, primary_key=True, autoincrement=True) name = Column(String(48), nullable=False) input = Column(Text, nullable=True) # 输入参数 script = Column(Text, nullable=True) g_id = Column(Integer, ForeignKey('graph.id'), nullable=False) # 从顶点查它的边,这里必须使用foreign_keys,这是因为从一端查多端,其值必须使用引号 tails = relationship('Edge', foreign_keys='[Edge.tail]') heads = relationship('Edge', foreign_keys='Edge.head') # 边表 class Edge(Base): __tablename__ = 'edge' id = Column(Integer, primary_key=True, autoincrement=True) tail = Column(Integer, ForeignKey('vertex.id'), nullable=False) head = Column(Integer, ForeignKey('vertex.id'), nullable=False) g_id = Column(Integer, ForeignKey('graph.id'), nullable=False) # Engine # pipeline 表 class Pipeline(Base): __tablename__ = 'pipeline' id = Column(Integer, primary_key=True, autoincrement=True) g_id = Column(Integer, ForeignKey('graph.id'), nullable=False) # current = Column(Integer, ForeignKey('vertex.id'), nullable=False) name = Column(String(48), nullable=True) state = Column(Integer, nullable=False, default=STATE_WAITING) desc = Column(String(100)) # vertex = relationship('Vertex') # 从pipeline去查所有节点信息 # tracks = relationship('Track', foreign_keys='Track.p_id') class Track(Base): __tablename__ = 'track' id = Column(Integer, primary_key=True, autoincrement=True) p_id = Column(Integer, ForeignKey('pipeline.id'), nullable=False) v_id = Column(Integer, ForeignKey('vertex.id'), nullable=False) state = Column(Integer, index=True, nullable=False, default=STATE_WAITING) # +索引 input = Column(Text, nullable=True) output = Column(Text, nullable=True) # 任务输出 script = Column(Text, nullable=True) vertex = relationship('Vertex') pipeline = relationship('Pipeline') # 一端多端随便写一个即可,不要重复 def __repr__(self): return f"<{self.__class__.__name__} {self.id} {self.p_id} {self.v_id}" __str__ = __repr__ # 封装数据库的引擎、会话到类中 # 单例模式 def singleton(cls): instance = None @functools.wraps(cls) def getinstance(*args, **kwargs): nonlocal instance if not instance: print(args) print(kwargs) instance = cls(*args, **kwargs) return instance return getinstance @singleton class Database: def __init__(self, url, **kwargs): self._engine = create_engine(url, **kwargs) self._session = sessionmaker(bind=self._engine)() @property def session(self): return self._session @property def engine(self): return self._engine # 创建表 def create_all(self): Base.metadata.create_all(self._engine) # 删除表 def drop_all(self): Base.metadata.drop_all(self._engine) # 模块加载一次,db也是单例的 db = Database(config.URL, echo=config.DATABASE_DEBUG)
service.py
from .model import db from .model import Graph, Vertex, Edge, Track, Pipeline from .model import STATE_WAITING, STATE_PENDING, STATE_RUNNING, STATE_FAILED from functools import wraps from collections import defaultdict import simplejson # 类型转换用 TYPES = { 'str': str, 'string': str, 'int': int, 'integer': int } def transactional(fn): @wraps(fn) def wrapper(*args, **kwargs): ret = fn(*args, **kwargs) try: db.session.commit() return ret except Exception as e: print(e) db.session.rollback() return wrapper # 创建DAG @transactional def create_graph(name, desc=None): g = Graph() g.name = name g.desc = desc db.session.add(g) return g # 为DAG增加顶点 @transactional def add_vertex(graph: Graph, name: str, input=None, script=None): v = Vertex() v.g_id = graph.id v.name = name v.input = input v.script = script db.session.add(v) return v # 为DAG增加边 @transactional def add_edge(graph: Graph, tail: Vertex, head: Vertex): e = Edge() e.g_id = graph.id e.tail = tail.id e.head = head.id db.session.add(e) return e # 删除顶点 # 删除顶点就要删除所有顶点关联的边 @transactional def del_vertex(id): query = db.session.query(Vertex).filter(Vertex.id == id) v = query.first() if v: # 找到顶点后,删除关联的边,然后删除顶点 db.session.query(Edge).filter((Edge.tail == v.id) | (Edge.head == v.id)).delete() query.delete() return v def check_graph(graph: Graph) -> bool: query = db.session.query(Vertex).filter(Vertex.g_id == graph.id) vertexes = {vertex.id for vertex in query} query = db.session.query(Edge).filter(Edge.g_id == graph.id) edges = defaultdict(list) ids = set() # 有入度的顶点 for edge in query: # defaultdict(<class 'list'>, {1: [(1, 2), (1, 3)], 2: [(2, 4)], 3: [(3, 2)]}) edges[edge.tail].append((edge.tail, edge.head)) ids.add(edge.head) print('-=' * 30) print(vertexes, edges) # ===============测试数据=============== # {1, 2, 3, 4} # defaultdict(<class 'list'>, {1: [(1, 2), (1, 3)], 2: [(2, 4)], 3: [(3, 2)]}) # vertexes = {1, 2, 3, 4} # edges = {1: [(1, 2), (1, 3)], 2: [(2, 4)], 3: [(3, 2)]} # ids = set() # 有入度的顶点 # ===================================== if len(edges) == 0: return False # 一条边都没有,这样的DAG业务上不用 # 如果edges不为空,一定有ids,也就是有入度的顶点 zds = vertexes - ids # zds入度为0的顶点 # zds为0说明没有找到入度为0的顶点,算法终止 if len(zds): for zd in zds: if zd in edges: del edges[zd] while edges: # 将顶点集改为当前入度顶点集ids vertexes = ids ids = set() # 重新寻找有入度的顶点 for lst in edges.values(): for edge in lst: ids.add(edge[1]) zds = vertexes - ids print(vertexes, ids, zds) if len(zds) == 0: # 有环路 break for zd in zds: if zd in edges: # 有可能顶点没有出度 del edges[zd] print(edges) # 边集为空,剩下所有顶点都是入度为0的,都可以多次迭代删除掉 if len(edges) == 0: # 检验通过,修改checked字段为1 try: graph = db.session.query(Graph).filter(Graph.id == graph.id).first() if graph: graph.checked = 1 db.session.add(graph) db.session.commit() return True except Exception as e: db.session.rollback() raise e return False @transactional def finish_params(t_id, d: dict, inp): """完成所有参数值""" params = {} # 最终的参数 if inp: print(inp) print(d) for k, v in inp.items(): print(k, v) val = d.get(k) if isinstance(val, TYPES.get(v['type'], str)): params[k] = val elif v.get('default'): # 类型不对,但是有缺省值 params[k] = v.get('default') else: raise TypeError('参数类型错误') # 将input存入数据库 track = db.session.query(Track).filter(Track.id == t_id).first() if track: track.input = simplejson.dumps(params) # 转成字符串 db.session.add(track) return params @transactional def finish_script(t_id, script: str, params: dict): '''使用参数替换脚本''' newline = '' if script: if isinstance(script, str): script = simplejson.loads(script).get('script') import re regex = re.compile(r'{([^{}]+)}') start = 0 for matcher in regex.finditer(script): newline += script[start:matcher.start()] print(matcher, matcher.group(1)) key = matcher.group(1) tmp = params.get(key, '') newline += str(tmp) start = matcher.end() else: newline += script[start:] # 把生成的script存入库 track = db.session.query(Track).filter(Track.id == t_id).first() if track: track.script = newline # 转成字符串 db.session.add(track) return newline # 开启一个流程,用户指定一个名称、描述 @transactional def start(graph: Graph, name: str, desc=None): # 判断流程是否存在,且checked为1即检验过的 g = db.session.query(Graph).filter(Graph.id == graph.id).filter(Graph.checked == 1).first() if not g: return # 写入pipeline表 p = Pipeline() p.name = name p.desc = desc p.g_id = g.id p.state = STATE_RUNNING # 开启一个流程运行 db.session.add(p) # 查询这个graph的所有顶点全部 vertexes = db.session.query(Vertex.id).filter(Vertex.g_id == graph.id) if not vertexes: return # 查出所有起点,入度为0,子查询实现 query = vertexes.filter(Vertex.id.notin_( db.session.query(Edge.head).filter(Edge.g_id == graph.id) )) zds = {x[0] for x in query} # query是多条记录对象,每一条记录是一个元组,元组的元素取决于查了哪些字段 print("-->", zds) for v in vertexes: # 写入track表 t = Track() t.p_id = p.id t.v_id = v.id t.state = STATE_WAITING if v.id not in zds else STATE_PENDING db.session.add(t) print("-->", v, t.state, v.id) # 标记有人使用过了,sealed封闭 if g.sealed == 0: g.sealed = 1 db.session.add(g) return p # 查询流程的某种状态节点 @transactional def show_pipeline(id, state=STATE_PENDING): """显示指定的流程的信息""" p = db.session.query( Pipeline.id, Pipeline.name, Pipeline.state, Track.id, Track.v_id, Track.state, Vertex.input, Vertex.script). \ join(Track, (Track.p_id == id) & (Pipeline.id == Track.p_id)). \ join(Vertex, Track.v_id == Vertex.id). \ filter(Pipeline.state != STATE_FAILED). \ filter(Track.state == state) return p.all()
executor.py
# executor.py from .model import Edge, Track from .model import STATE_WAITING, STATE_PENDING, STATE_RUNNING, STATE_SUCCEED, STATE_FAILED, STATE_FINISHED from .service import db from subprocess import Popen from tempfile import TemporaryFile from concurrent.futures import ThreadPoolExecutor, as_completed import threading import uuid from collections import defaultdict from queue import Queue class Executor: def __init__(self, workers=5): self.__pool = ThreadPoolExecutor(max_workers=workers) self.__event = threading.Event() self.__tasks = {} self.__queue = Queue() threading.Thread(target=self._run).start() threading.Thread(target=self._save_track).start() def _execute(self, script: str): with TemporaryFile('w+') as f: output = [] code = 0 for line in script.splitlines(): p = Popen(line, shell=True, stdout=f) code = p.wait() # 阻塞等,code为0是正确执行 f.seek(0) # 回到开头 text = f.read() output.append(text) code += code return code, '\n'.join(output) def execute(self, p_id, t_id, script: str): """异步执行方法,提交数据就行了,运行后,会提供运行结果,或返回失败""" key = uuid.uuid4().hex # uuid没有用上,只是说以后不重复key或id可以用uuid try: self.__tasks[self.__pool.submit(self._execute, script)] = (key, p_id, t_id) # future 对象 # 修改状态为准备执行RUNNING track = db.session.query(Track).filter(Track.id == t_id).one() track.state = STATE_RUNNING db.session.add(track) db.session.commit() except Exception as e: db.session.rollback() raise e def _run(self): # 线程等待任务 while not self.__event.wait(1): for future in as_completed(self.__tasks): key, p_id, t_id = self.__tasks[future] try: code, text = future.result() del self.__tasks[future] self.__queue.put((p_id, t_id, code, text)) except Exception as e: print(key, e) del self.__tasks[future] # 失败任务以后处理 TODO def _save_track(self): while True: p_id, t_id, code, text = self.__queue.get() # 阻塞取 track = db.session.query(Track).filter(Track.v_id == t_id).first() track.state = STATE_SUCCEED if code == 0 else STATE_FAILED # 修改状态 track.output = text if code != 0: # 失败,必须立即将任务流状态设置为失败 track.pipeline.state = STATE_FAILED else: # +++++++++++ 流转代码 +++++++++++ # 所有其他节点 others = db.session.query(Track).filter((Track.p_id == p_id) & (Track.v_id != t_id)).all() # 等待,待运行, 运行,成功,失败 states = {STATE_WAITING: 0, STATE_PENDING: 0, STATE_RUNNING: 0, STATE_SUCCEED: 0, STATE_FAILED: 0} for other in others: states[other.state] += 1 print('+' * 30) print(states, len(others)) print('+' * 30) if states[STATE_FAILED] > 0: track.pipeline.state = STATE_FAILED elif states[STATE_SUCCEED] == len(others): # 除了它之外全是成功说明全部成功 track.pipeline.state = STATE_FINISHED else: # 还有节点没有做完,判断自己有没有下一级 # heads = db.session.query(Edge.head).filter(Edge.tail == track.v_id).all() # if len(heads) == 0: # pass # 什么都不做,因为你没下一级,就是其中一个先做完的终点 # else: query = db.session.query(Edge).filter(Edge.g_id == track.pipeline.g_id) t2h = defaultdict(list) h2t = defaultdict(list) for e in query: t2h[e.tail].append(e.head) h2t[e.head].append(e.tail) if track.v_id in t2h.keys(): nexts = t2h[track.v_id] for n in nexts: tails = h2t[n] # n pending 条件是tails所有状态都必须是成功 # 统计tails是否都是成功的,可以pending, # select count(state) from track where track.v_id in (1,2,4) # and track.state = STATE_SUCCEED and pid s_count = db.session.query(Track).filter(Track.p_id == track.p_id) \ .filter(Track.v_id.in_(tails)) \ .filter(Track.state == STATE_SUCCEED).count() if s_count == len(tails): # pending nx = db.session.query(Track).filter(Track.v_id == n).one() nx.state = STATE_PENDING db.session.add(nx) else: pass # 什么都不做 else: pass # 什么都不做,因为你没下一级,就是其中一个先做完的终点 db.session.add(track) try: db.session.commit() except Exception as e: db.session.rollback() raise e EXECUTOR = Executor() # 全局任务执行器对象
app.py
import json import time import simplejson from pipeline.service import Graph, db, finish_script, finish_params from pipeline.service import create_graph, add_vertex, add_edge, check_graph from pipeline.service import start, show_pipeline from pipeline.executor import EXECUTOR db.drop_all() db.create_all() # 由于将script格式更改了,所以重新提供该函数 # 测试数据 # 由于将script格式更改了,所以重新提供该函数 # 测试数据 def test_create_dag(): try: # 图1 创建DAG g = create_graph('test1') # 成功则返回一个Graph对象 # 增加顶点 input = { "ip": { "type": "str", "required": True, "default": "127.0.0.1" } } script = { 'script': 'echo "test1.A"\nping {ip}', 'next': 'B' } # 这里为了让用户方便,next可以接收2种类型,数字表示顶点的id,字符串表示同一个DAG中该名称的节点,不能重复 a = add_vertex(g, 'A', json.dumps(input), json.dumps(script)) # next顶点验证可以在定义时,也可以在使用时 b = add_vertex(g, 'B', None, '{"script":"echo B"}') c = add_vertex(g, 'C', None, '{"script":"echo C"}') d = add_vertex(g, 'D', None, '{"script":"echo D"}') # 增加边 ab = add_edge(g, a, b) ac = add_edge(g, a, c) cb = add_edge(g, c, b) bd = add_edge(g, b, d) # 图2 创建环路 g = create_graph('test2') # 环路 # 增加顶点 a = add_vertex(g, 'A', None, '{"script":"echo A"}') b = add_vertex(g, 'B', None, '{"script":"echo B"}') c = add_vertex(g, 'C', None, '{"script":"echo C"}') d = add_vertex(g, 'D', None, '{"script":"echo D"}') # 增加边, abc之间的环 ba = add_edge(g, b, a) ac = add_edge(g, a, c) cb = add_edge(g, c, b) bd = add_edge(g, b, d) # 图3 创建DAG g = create_graph('test3') # 多个终点 # 增加顶点 a = add_vertex(g, 'A', None, '{"script":"echo A"}') b = add_vertex(g, 'B', None, '{"script":"echo B"}') c = add_vertex(g, 'C', None, '{"script":"echo C"}') d = add_vertex(g, 'D', None, '{"script":"echo D"}') # 增加边 ba = add_edge(g, b, a) ac = add_edge(g, a, c) bc = add_edge(g, b, c) bd = add_edge(g, b, d) # 图4 创建DAG g = create_graph('test4') # 多入口 # 增加顶点 a = add_vertex(g, 'A', None, '{"script":"echo A"}') b = add_vertex(g, 'B', None, '{"script":"echo B"}') c = add_vertex(g, 'C', None, '{"script":"echo C"}') d = add_vertex(g, 'D', None, '{"script":"echo D"}') # 增加边 ab = add_edge(g, a, b) ac = add_edge(g, a, c) cb = add_edge(g, c, b) db = add_edge(g, d, b) except Exception as e: raise e def test_check_all_graph(): query = db.session.query(Graph).filter(Graph.checked == 0).all() for g in query: if check_graph(g): g.checked = 1 db.session.add(g) try: db.session.commit() print('done') except Exception as e: db.session.rollback() raise e # 测试start def test_start(): g = Graph() g.id = 1 p = start(g, '流程1') if __name__ == '__main__': test_create_dag() test_check_all_graph() test_start() while True: ps = show_pipeline(1) # 返回运行节点列表 print('-' * 30) print('->-->---->', ps) print('-' * 30) time.sleep(3) print('~~~~~~~~~~~~~ sleeping ~~~~~~~~~~~~') for p_id, p_name, p_state, t_id, v_id, t_state, inp, script in ps: print(p_id, p_name, p_state, t_id, v_id, t_state, inp, script) d = {} # 如果参数是必须,则交互,让用户提交 if inp: inp = simplejson.loads(inp) for k in inp.keys(): if inp[k].get('required1', False): d[k] = input('{}= '.format(k)) print(d) params = finish_params(t_id, d, inp) print(params) # 准备好参数 print(script, '+++++++++') script = finish_script(t_id, script, params) print(script) # 拿到替换好的脚本,准备执行 EXECUTOR.execute(p_id, t_id, script) # 异步执行
可视化
为了给用户提供友好的界面显示效果,在网页往往需要显示出 DAG 的图形。
使用 echarts 可以很好的完成这个功能。
https://echarts.apache.org/examples/zh/editor.html?c=graph-simple
在线修改例子如下:
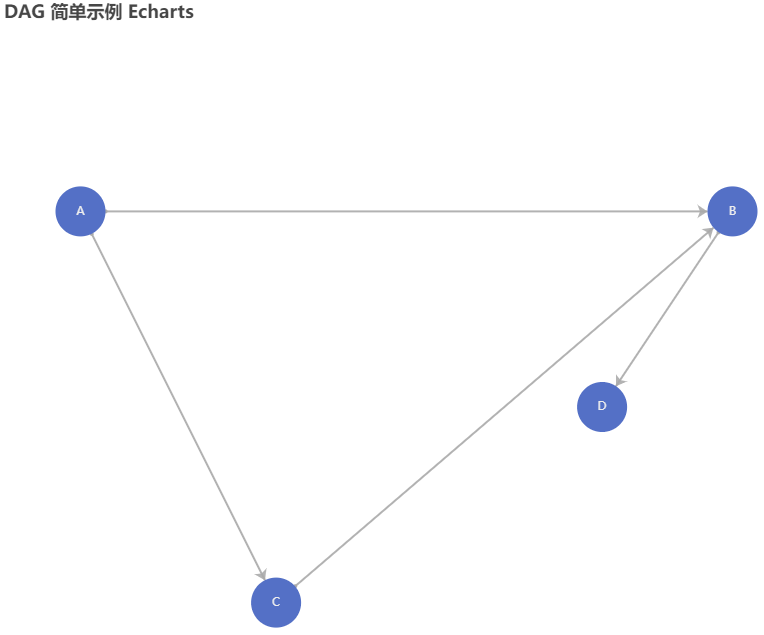
option = { title: { text: "DAG 简单示例 Echarts" }, tooltip: {}, animationDurationUpdate: 1500, animationEasingUpdate: "quinticInOut", series: [ { type: "graph", layout: "none", symbolSize: 50, roam: true, label: { normal: { show: true } }, edgeSymbol: ["circle", "arrow"], edgeSymbolSize: [4, 10], edgeLabel: { normal: { textStyle: { fontSize: 20 } } }, data: [ { name: "A", x: 300, y: 300 }, { name: "B", x: 400, y: 300 }, { name: "C", x: 330, y: 360 }, { name: "D", x: 380, y: 330 } ], // links: [], links: [ { source: 0, target: 1 }, { source: 0, target: 2 }, { source: 2, target: 1 }, { source: 1, target: 3 } ], lineStyle: { normal: { opacity: 0.9, width: 2, curveness: 0 } } } ] };
获得效果如下:
Flask 框架代码实现
前面写好的项目可以嵌入到 flask 框架中,flask 框架主要负责后端的数据计算,前端可视化可以借用 jQuery 库发起 ajax 调用获取后端数据,然后操作浏览器的 DOM 树。
jQuery 相对 Vuejs、Reactjs 来说,要轻量级很多。使用 jQuery 的方法很简单,直接在 html 中引入 jQuery 库,就可以使用 jQuery 语法。
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>jQuery Usage</title> <!-- 引入 jquery --> <script src={{url_for('static', filename="js/jquery-2.1.1.min.js")}}></script> </head>
注意:模板中调用 url_for 生成路径,这点很重要,否则访问静态路径会出错(404)。
- 使用 Flask 微框架
- 使用 Jinja2 模板技术
- 使用 JQuery 发起 AJAX 异步调用
- 使用 ECharts 图表组件
- 使用 uWSGI 部署
- Flask 安装
官网:https://flask.palletsprojects.com/en/3.0.x/quickstart/
$ pip install flask
在项目根目录下构建 3 个目录:
- web 目录,存放后端代码。
- templates 目录,存放模板文件。
- static 目录存放 js、css 等静态文件。其下建立 js 目录,放入 jquery、echarts 的 js 文件。
- 模板定义
准备 4 个模板文件,如下:
index.html 首页
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd"> <html lang="en"> <head> <title>亮天生学院</title> <meta http-equiv="Content-Type" content="text/html;charset=utf-8"> </head> <body> <h2>DAG-Flask-JQuery-Ajax-ECharts</h2> <ul> <li><a href="1">图表1</a></li> <li><a href="2">图表2</a></li> <li><a href="3">图表3</a></li> </ul> </body> </html>
chart1.html 简单图表:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="utf-8"> <title>ECharts</title> <!-- 引入 jquery --> <script src={{url_for('static', filename="js/jquery-2.1.1.min.js" )}}></script> <!-- 引入 echarts.js --> <script src={{url_for('static', filename="js/echarts.min.js" )}}></script> </head> <body> <!-- 为ECharts准备一个具备大小(宽高)的Dom --> <div id="main" style="width: 600px;height:400px;"></div> <script type="text/javascript"> // 基于准备好的dom,初始化echarts实例 var myChart = echarts.init(document.getElementById('main')); // JQuery Ajax调用 $.get('/dag/1', function (data) { console.log(data); // 指定图表的配置项和数据 var option = { title: { text: 'ECharts 入门示例' }, tooltip: {}, legend: { // 图例 data: ['销量', '产量'] }, xAxis: { // x轴 data: data.xs }, yAxis: {type: 'value'}, // Y轴 series: [{ // 数据数据 name: '产量', type: 'bar', data: data.data }, { name: '销量', type: 'bar', data: data.data.map(x => x + parseInt(Math.random() * 10 - 5)) }] }; // 使用刚指定的配置项和数据显示图表 myChart.setOption(option); }) </script> </body> </html>
注意:模板中调用 url_for 生成路径,这点很重要,否则访问静态路径会出错(404)。
chart2.html DAG 图表( JQuery AJAX ):
<!DOCTYPE html> <html lang="en"> <head> <meta charset="utf-8"> <title>ECharts</title> <!-- 引入 jquery --> <script src={{url_for('static', filename="js/jquery-2.1.1.min.js" )}}></script> <!-- 引入 echarts.js --> <script src={{url_for('static', filename="js/echarts.min.js" )}}></script> </head> <body> <!-- 为ECharts准备一个具备大小(宽高)的Dom --> <div id="main" style="width: 600px;height:400px;"></div> <script type="text/javascript"> // 基于准备好的dom,初始化echarts实例 var myChart = echarts.init(document.getElementById('main')); $.get('/dag/2', function (data) { console.log(data); // 指定图表的配置项和数据 option = { title: { text: 'DAG 简单示例 Echarts' }, tooltip: {}, animationDurationUpdate: 1500, animationEasingUpdate: 'quinticInOut', series: [ { type: 'graph', layout: 'none', symbolSize: 50, roam: true, label: { normal: { show: true } }, edgeSymbol: ['circle', 'arrow'], edgeSymbolSize: [4, 10], edgeLabel: { normal: { textStyle: { fontSize: 20 } } }, data: data.data, // links: [], links: data.links, lineStyle: { normal: { opacity: 0.9, width: 2, curveness: 0 } }, tooltip: { // 提示框,鼠标放在节点或边上试一试 formatter: "{b}<br />{c}", // {b}表示类目,{c}表示数值 backgroundColor: "#000000" //背景色 } } ] }; // 使用刚指定的配置项和数据显示图表 myChart.setOption(option); }) </script> </body> </html>
chart3.html DAG 图表( JQuery AJAX ):
<!DOCTYPE html> <html lang="en"> <head> <meta charset="utf-8"> <title>ECharts</title> <!-- 引入 jquery --> <script src={{url_for('static', filename="js/jquery-2.1.1.min.js" )}}></script> <!-- 引入 echarts.js --> <script src={{url_for('static', filename="js/echarts.min.js" )}}></script> </head> <body> <!-- 为ECharts准备一个具备大小(宽高)的Dom --> <div id="main" style="width: 600px;height:400px;"></div> <script type="text/javascript"> // 基于准备好的dom,初始化echarts实例 var myChart = echarts.init(document.getElementById('main')); $.get('/dag/3', function (data) { console.log(data); myChart.hideLoading(); // 指定图表的配置项和数据 option = { title: { text: data.title }, tooltip: {trigger: 'item'}, animationDurationUpdate: 1500, animationEasingUpdate: 'quinticInOut', series: [ { type: 'graph', layout: 'none', symbolSize: 50, roam: true, label: { normal: { show: true } }, edgeSymbol: ['circle', 'arrow'], edgeSymbolSize: [4, 10], edgeLabel: { normal: { textStyle: { fontSize: 20 } } }, data: data.data, // links: [], links: data.links, lineStyle: { show: false, normal: { opacity: 0.9, width: 2, curveness: 0 } }, tooltip: { // 提示框,鼠标放在节点或边上试一试 // 使用函数重新定义显示文字的格式,回调送入3个参数 formatter: function (params, ticket, callback) { if (params.dataType === 'edge') // 连线没有值返回空串 return ''; if (params.value) return params.name + '<br />' + params.value return params.name } //, backgroundColor: "#000000" } } ] }; // 使用刚指定的配置项和数据显示图表 myChart.setOption(option); // 遍历数据 echarts.util.map(data.data, function (item, dataIndex) { console.log(item); console.log(dataIndex); }); // 鼠标事件,click点击 myChart.on('mouseover', function (item) { console.log(item); if (item.value) { console.log(item.value) } }); }); </script> </body> </html>
服务端代码实现,创建应用 app:
# web/__init__.py中 from flask import Flask, make_response, render_template, jsonify from web.service import getdag app = Flask('pipeline_web') @app.route('/', methods=['GET']) # 路由,可以指定方法列表,缺省GET def index(): # 视图函数 return render_template('index.html') @app.route('/<int:graphid>') # index.html中访问不同的模板页 def showdag(graphid): return render_template('chart{}.html'.format(graphid)) @app.route('/dag/<int:graphid>') # (rule, **options) def showajaxdag(graphid): if graphid == 1: return simplegraph() elif graphid == 2: return jsonify(getdag(1)) elif graphid == 3: return jsonify(getdag(1)) def simplegraph(): xs = ["衬衫", "羊毛衫", "雪纺衫", "裤子", "高跟鞋", "袜子"] data = [5, 20, 36, 10, 10, 20] return jsonify({'xs': xs, 'data': data})
在项目根目录创建测试文件:
# 启动测试应用 from web import app # 启动测试应用 if __name__ == '__main__': app.run(host='0.0.0.0', port=5000)
模板一旦被调用,返回的 HTML 页面会立即发起 AJAX 调用,请求 DAG 数据,视图函数会向 Service 层请求数据。
从 pipeline 中复制 config.py、model.py 到 web 目录下。
在 web 包下创建 service.py 文件。
from .model import db, Pipeline, Track, Vertex, Edge import random def randomxy(): return random.randint(300, 500) # 随机模仿 x y坐标 def getdag(p_id): # 根据pipeline的id返回流程数据,让前端页面绘制DAG图 ps = db.session.query( Pipeline.id, Pipeline.name, Pipeline.state, Vertex.id, Vertex.name, Vertex.script, Track.script ).join( Track, (Pipeline.id == Track.p_id) & (Pipeline.id == 1) ).join( Vertex, Vertex.id == Track.v_id ) edges = db.session.query(Edge.tail, Edge.head) \ .join(Pipeline, (Pipeline.g_id == Edge.g_id) & (Pipeline.id == 1)) data = [] # 顶点数据 vertexes = {} # 让edges查询少join title = '' for p_id, p_name, p_state, v_id, v_name, v_script, t_script in ps: if not title: title = p_name data.append( { 'name': v_name, 'x': randomxy(), 'y': randomxy(), 'value': t_script if t_script else v_script } ) vertexes[v_id] = v_name print(data) links = [] # 边 for tail, head in edges: links.append( { 'source': vertexes[tail], 'target': vertexes[head] } ) return {'title': title, 'data': data, 'links': links}
启动服务,看看效果。
uWSGI + Flask 部署
uwsgi 安装在 Linux 服务器上:
# yum install python-devel # 安装pyenv虚拟环境,然后安装以下依赖包 $ pip isntall uwsgi flask $ pip install pymysql sqlalchemy cryptography
在服务器构建 Python 运行虚拟环境,建立目录,将 templates、static、web 三个目录及文件复制到服务器上该目录下。
在 Flask 项目根目录下运行 $ uwsgi --http :8000 -w web:app
uwsgi 的配置文件:
[uwsgi] http = 0.0.0.0:5000 module = web:app
$ uwsgi flask.ini
Python 常见设计模式
主要内容:
- 构建模式-单例模式
- 构建模式-工厂模式
- 结构模式-Composite(组合)
- 行为模型-Observer(观察者)
- 其他编程模式介绍
singleton单例模式
一个模块只加载一次,如果在模块设定全局变量为一个实例,看似这个实例是全局唯一,但是不能阻止别人在使用同一个类再次实例化一个实例出来。这不是单例模式。例如logging.root实例,它虽然只有一个,但是不能别人再创建一个RootLogger的实例。
单例模式: 一个类只能实例化一次,只能拥有一个实例
实例化方法实现
# 方法1 使用__new__ class Singleton: def __new__(cls, *args, **kwargs): print(hasattr(cls, '__instance')) if not hasattr(cls, '__instance'): setattr(cls, '__instance', super().__new__(cls)) return getattr(cls, '__instance') # A实例 a = Singleton() print(a) print(Singleton()) print(Singleton())
执行结果
D:\project\pyproj\pycharm\.venv1\Scripts\python.exe D:\project\pyproj\pycharm\t7.py
False
<__main__.A object at 0x000001DA68581010>
True
<__main__.A object at 0x000001DA68581010>
True
<__main__.A object at 0x000001DA68581010>
完善展示
class Singleton: def __new__(cls, *args, **kwargs): if not hasattr(cls, '__instance'): #判断类属性中有没有实例 setattr(cls, '__instance', super().__new__(cls)) return getattr(cls, '__instance') # A实例 def __init__(self, x): self.x = x def __repr__(self): return "<{} {}>, id={}".format(__class__.__name__, self.x, id(self)) a = Singleton(1) print(a) print(Singleton(2)) print(Singleton(3))
执行结果
D:\project\pyproj\pycharm\.venv1\Scripts\python.exe D:\project\pyproj\pycharm\t7.py <Singleton 1>, id=1577203470352 <Singleton 2>, id=1577203470352 <Singleton 3>, id=1577203470352
装饰器实现
logger版本改造
# 方法2 函数做装饰器 from functools import wraps def singleton(cls): __instance = None wraps(cls) def wrapper(*args, **kwargs): nonlocal __instance if __instance is None: __instance = cls(*args, **kwargs) return __instance return wrapper @singleton class A: # A = singleton(A) A = wrapper def __init__(self, x): self.x = x def __repr__(self): return "<{} {}>, id={}".format(__class__.__name__, self.x, id(self)) a = A(1) print(a) print(A(2)) print(A(3))
D:\project\pyproj\pycharm\.venv1\Scripts\python.exe D:\project\pyproj\pycharm\t7.py <A 1>, id=2452181159952 <A 1>, id=2452181159952 <A 1>, id=2452181159952
元编程
# 方法3 元编程 class Singleton(type): def __new__(cls, name, bases, attrs): print('new~~~') return super().__new__(cls, name, bases, attrs) def __call__(self, *args, **kwargs): print('call~~~') # 实例化在这里控制 print(self.__name__, self) print(args, kwargs) class A(metaclass=Singleton): pass print(A) A(123)
D:\project\pyproj\pycharm\.venv1\Scripts\python.exe D:\project\pyproj\pycharm\t7.py new~~~ <class '__main__.A'> call~~~ A <class '__main__.A'> (123,) {}
主要用call方法
# 方法3 元编程 class Singleton(type): def __call__(self, *args, **kwargs): print('call~~~') # 实例化在这里控制 # print(self.__name__, self) # print(args, kwargs) if not hasattr(self, '__instance'): setattr(self, '__instance', super().__call__(*args, **kwargs)) getattr(self, '__instance').__init__(*args, **kwargs) return getattr(self, '__instance') class A(metaclass=Singleton): def __init__(self, x): self.x = x def __repr__(self): return "<{} {}>, id={}".format(__class__.__name__, self.x, id(self)) print(A) print(A(123)) print(A(456))
D:\project\pyproj\pycharm\.venv1\Scripts\python.exe D:\project\pyproj\pycharm\t7.py <class '__main__.A'> call~~~ <A 123>, id=1993739472912 call~~~ <A 456>, id=1993739472912