Python: 基础语法与数据结构
- TAGS: Python
指导
招聘要求:
- 平台: linux平台
- 系统:线程、进程、Shell编程
- 网络:网络原理、HTTP协议。Socket开发、IO多路复用、异步IO开发
- 算法要求:斐波那契数列、求质数、常见排序算法等,甚至要求现场写
- 数据库:关系型数据库至少会MySQL,NOSQL应该了解,最好会一个
- 中间件:消息队列原理和应用,例如RabbitMQ
- WEB开发:偏后端,MVC框架要求会Django、Flask、Tornado之一
- 可视化:WEB的前端开发多一些HTML、JS要会
- 数据分析和A1:要求掌握数据分析的数据理论,机器学习常用库使用
主要内容:
- 基础:操作系统、网络基础、数据库基础、Python语言基础….
- 进阶:函数封装思想、面向对象设计、装饰器、Mixin…
- 高级:网络编程、并发编程、消息中间件、ORM、传统网页开发(HTML、CSS、jQuery、ECharts)、最新前端开发(ES6、React、Antd)..
- 实战:WEB框架(Django、Flask等)、数据库建模、前后端分离WEB系统、Restful API设计、任务流程
- 系统、爬虫Scrapy与数据分析…
- 高端:数据清洗、企业数据分析、预测推荐、金融量化、机器学习及算法(回归算法、KNN、决策树、SVM) …
职业方向:
- 运维自动化工程师:需求多样,问题复杂
- 全栈工程师:偏向 WEB 开发,掌握 WEB 前端后端开发
- 爬虫工程师:掌握常见爬取库,可以使用爬虫框架开发
- 大数据开发工程师:可以使用 Python 语言完成,注重算法应用
- 分析工程师:科学计算,数据建模,注重算法的设计
- AI工程师:大量算法、Google 的 TensorFlow 等框架
Python 怎么学?
- 冰冻三尺非一日之寒!学真本事,必定会有枯燥难学的知识。会当临绝顶,一定先爬山
- 多写,写出好的代码就是要不停的练习,唯手熟尔
- 少问,多自己调试Bug,对问题的解决能力,决定着你水平的高低
- 不要盲目下手,先构思
- 不要苛求完美,先做出效果来。不管黑猫白猫,抓住老鼠就是好猫
- 少看博客,多自己整理知识。多看官方手册,仅做为参考。忘了就去查手册
- 慎用删除
- 再简单的代码,如果放到生产环境前,必须测试
- 通一门,则无所谓语言了,核心是程序逻辑(方法和数据结构)
- 掌握设计思想,激发创造性思维,多验证,多思考,多总结,多实践
Google Python 编程风格指南
- 英文版 https://github.com/google/styleguide
- 中文版 https://github.com/zh-google-styleguide/zh-google-styleguide
人工智能路线:
- 基础语法
- 变量、常量、数据类型、赋值、运算符、表达式、条件语句、循环语句、数组、函数、递归、类
- 数据结构和算法(必学)
基础数据结构
顺序表、链表、栈、队列
二叉树、二叉搜索树、图
邻接矩阵、邻接表、哈希表
算法基础
线性枚举、模拟、递推
十大排序、哈希、贪心
前缀和、双指针、滑窗
二分查找、广搜、深搜
最短路、二分匹配、DP
- 数学基础(大学必学)
- 高等数学、离散数学、线性代数、概率论、数理统计
- 机器学习
算法
线性回归、逻辑回归
决策树、数据预处理
数据清洗、特征工程
支持向量机、聚类算法
- 神经网络原理
- TensorFlow、PyTorch、卷积神经网络、循环神经网络
自然语言处理
记法分析、句法分析
语义理解、工具和库
如NLTK、SpaCy等
神经网络、反向传播
循环神经网络(RNN)
长短时记忆网络(LSTM)
门控循环单元(GRU)
卷积神经网络(CNN)
计算机视觉
目标检测、图像分类
语义分割、实例分割
目标跟踪、图像识别
深度学习、生成对抗网络
数据集、特征提取、特征图
模型训练、模型评估、准确率
召回率、F1值、超分辨率
图像增强、图像修复、姿态估计
人脸识别、物体识别、场景理解
强化学习
环境、主体、状态、行为
奖赏、策略、价值函数
深度强化学习、探索与利用
马尔可夫决策过程、贝尔曼方程
无模型与基于模型、经验重放
多巴胺、延迟回报、训练算法
数据处理和特征工程
数据清洗、数据预处理、数据标准化
数据归一化、数据缺失值处理、异常
值检测与处理、数据变换、特征提取
特征选择、特征构建、特征缩放
独热编码、标签编码、文本数据处理
数值数据处理、时间序列数据处理
主成分分析(PCA)、特征重要性评估
特征工程方法、数据质量提升、数据理解
计算机基础知识
冯·诺依曼体系

- 艾伦·麦席森·图灵(Alan Mathison Turing,1912年6月23日-1954年6月7日),英国数学家、逻辑学家,被称为计算机科学之父,人工智能之父。图灵提出的著名的图灵机模型为现代计算机的逻辑工作方式奠定了基础。图灵机已经有输入、输出和内部状态变化机制了。

- 冯·诺依曼著名匈牙利裔美籍犹太人数学家、计算机科学家、物理学家和化学家 ,数字计算机之 父。他提出了以二进制作为数字计算机的数制基础,计算机应该按照程序顺序执行,计算机应 该有五大部件。
冯·诺依曼体系结构
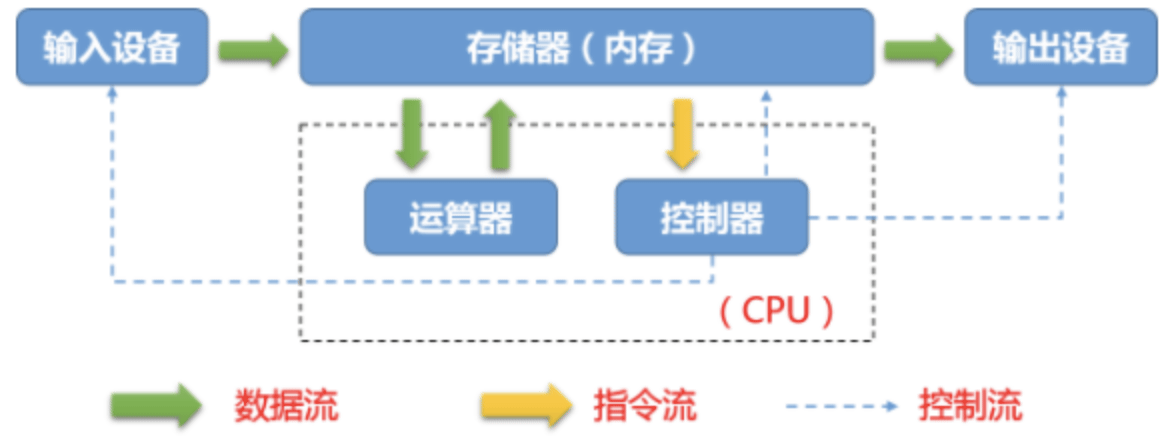
五大核心部件:
- 中央处理器CPU
- 运算器:用于完成各种算术运算、逻辑运算和数据传送等数据加工处理。
- 控制器:用于控制程序的执行,是计算机的大脑。运算器和控制器组成计算机的中央处理器(CPU)。控制器根据存放在存储器中的指令序列(程序)进行工作,并由一个程序计数器控制指令的执行。控制器具有判断能力,能根据计算结果选择不同的工作流程。
- 存储器:用于记忆程序和数据,例如:内存。程序和数据以二进制代码形式不加区别地存放在存储器中,存放位置由地址确定。内存是掉电易失的设备。
- 输入设备:用于将数据或程序输入到计算机中,例如:鼠标、键盘。
- 输出设备:将数据或程序的处理结果展示给用户,例如:显示器、打印机。
CPU中还有寄存器和多级缓存Cache。
- CPU并不直接从速度很慢的IO设备上直接读取数据,CPU可以从较慢的内存中读取数据到CPU的寄存器上运算
- CPU计算的结果也会写入到内存,而不是写入到IO设备上
计算机语言
语言是人与人沟通的表达方式。 计算机语言是人与计算机之间沟通交互的方式。
机器语言
- 一定位数的二进制的0和1组成的序列,也称为机器指令
- 机器指令的集合就是机器语言
- 与自然语言差异太大,难学、难懂、难写、难记、难查错
汇编语言
- 用一些助记符号替代机器指令,称为汇编语言。ADD A,B 指的是将寄存器A的数与寄存器B的数相加得到的数放到寄存器A中
- 汇编语言写好的程序需要汇编程序转换成机器指令
- 汇编语言只是稍微好记了些,可以认为就是机器指令对应的助记符。只是符号本身接近自然语言
低级语言
- 机器语言、汇编语言都是面向机器的语言,都是低级语言
- 不同机器是不能通用的,不同的机器需要不同的机器指令或者汇编程序
高级语言
- 接近自然语言和数学语言的计算机语言
- 高级语言首先要书写源程序,通过编译程序把源程序转换成机器指令的程序
- 1954年正式发布的Fortran语言是最早的高级语言,本意是公式翻译
- 人们只需要关心怎么书写源程序,针对不同机器的编译的事交给编译器关心处理
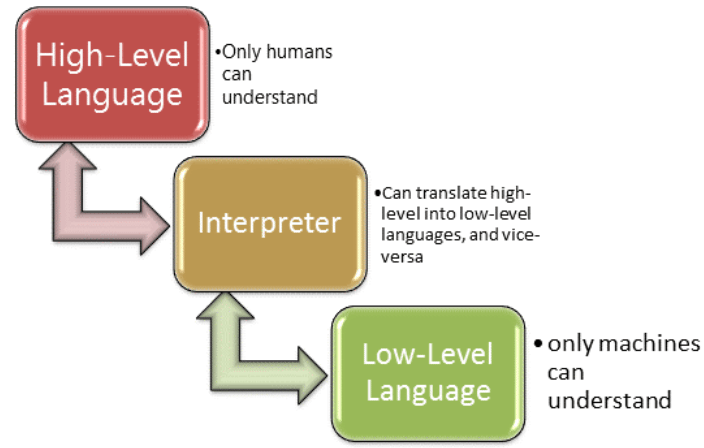
- 语言越高级,越接近人类的自然语言和数学语言
- 语言越低级,越能让机器理解
- 高级语言和低级语言之间需要一个转换的工具:编译器、解释器
编译语言
- 把源代码转换成目标机器的CPU指令
- C、C++等语言的源代码需要本地编译
解释语言
- 解释后转换成字节码,运行在虚拟机上,解释器执行中间代码
- Java、Python、C#的源代码需要被解释器编译成中间代码(Bytecode),在虚拟机上运行
高级语言的发展
- 非结构化语言
- 编号或标签、GOTO,子程序可以有多个入口和出口
- 有分支、循环
- 结构化语言
- 任何基本结构只允许是唯一入口和唯一出口
- 顺序、分支、循环,废弃GOTO
- 面向对象语言
- 更加接近人类认知世界的方式,万事万物抽象成对象,对象间关系抽象成类和继承
- 封装、继承、多态
- 函数式语言
- 古老的编程范式,应用在数学计算、并行处理的场景。引入到了很多现代高级语言中
- 函数是“一等公民”,高阶函数
程序program
算法 + 数据结构 = 程序- 数据是一切程序的核心
- 数据结构是数据在计算机中的类型和组织方式
- 算法是处理数据的方式,算法有优劣之分
只有选对了合理的数据结构,并采用合适的操作该数据结构的算法,才能写出高性能的程序
写程序的难点
- 理不清数据
- 搞不清处理方法
- 无法把数据设计转换成数据结构,无法把处理方法转换成算法
- 无法用设计范式来进行程序设计
开发环境
emacs大佬聊聊编程语言:https://manateelazycat.github.io/think/2023/04/23/programming-languages/
Python: 创建 deepin 的前期写了很多 Python 代码,只用看一本书《Python 核心编程》就可以实现入门到精通。Python 告诉我世间所有数据都可以用string,number,bool,list,dict,tuple来组合。它从来不像其他编程语言那样宣扬宗教理念和小技巧, 核心东西就那么多, 你永远可以信赖它,完美的原型设计语言,简单实用
Python 语言
python发展
- 荷兰人Guido van Rossum,2005年加入Google,2013年加入 Dropbox
- 他是英国BBC喜剧《Monty Python's Flying Circus》的忠实粉丝
- 1989年,创立了Python语言,1991年初发布第一个公开发行版
Python哲学
>>> import this The Zen of Python, by Tim Peters Beautiful is better than ugly. Explicit is better than implicit. Simple is better than complex. Complex is better than complicated. Flat is better than nested. Sparse is better than dense. Readability counts. Special cases aren't special enough to break the rules. Although practicality beats purity. Errors should never pass silently. Unless explicitly silenced. In the face of ambiguity, refuse the temptation to guess. There should be one-- and preferably only one --obvious way to do it. Although that way may not be obvious at first unless you're Dutch. Now is better than never. Although never is often better than *right* now. If the implementation is hard to explain, it's a bad idea. If the implementation is easy to explain, it may be a good idea. Namespaces are one honking great idea -- let's do more of those!
python的版本
从2020年开始,不在支持Python2,官方还提供了一个倒计时网站https://pythonclock.org/
Python2和3的区别
- 语句函数化,例如print(1,2)打印出1 2,但是2.x中意思是print语句打印元组,3.x中意思是函数的2个参数
- 整除,例如1/2和1//2,3.x版本中/为自然除
- 3.x中raw_input重命名为input,不再使用raw_input
- round函数,在3.x中i.5的取整变为距离最近的偶数
- 3.x字符串统一使用Unicode
- 异常的捕获、抛出的语法改变
2015年后,各主要国内外大公司都已经迁移到了Python3。很多重要的Python第三方库也陆续停止了对Python2的支持,所以,Python 3已经是必须学习的版本。2018年Python3的使用比例已经超过了85%。
在公司内,往往老项目维护维持2.x版本暂不升级,新项目使用3.x开发。
开发时,假如使用3.6.6,部署时应尽量保持一致,不要随意升级版本,更不要降低版本。
不要迷信版本,学会一个版本,好好学会一门语言,其他都不是问题。当然,也不要迷信语言。
在最合适的领域使用最合适的语言。
截止2021年3月,3.8、3.9版本依然为不稳定版本
python环境安装
window环境安装
官方: https://www.python.org/downloads/
IDE工具
- Pycharm https://www.jetbrains.com/pycharm/download/ 社区版够用了,写项目时用。
这里下载 3.12.7 版本,点 Download 下载找到对应文件下载。安装时勾选增加PATH路径,自定义安装至少安装帮助文档和 pip。
安装地址如: D:\python\python3127
打开 windows 命令行
python -V pip -V
多版本共存 : 我的电脑属性–环境变量–在 Path 中添加多个路径,用上移下移功能调整顺序切换版本。
D:\python\python382 D:\python\python312 D:\python\python368 D:\python\python3102
pip 使用
配置文件位置:
- windows配置文件:~/pip/pip.ini 注意打开文件的扩展名
- linux配置文件:~/.pip/pip.conf
- 最新版本位置:~/.config/pip/pipconf
软件包安装位置: {Python目录}/lib/site-packages
国内源
- 阿里源: https://developer.aliyun.com/mirror/ 进入 PyPI
- 清华源: https://mirrors.tuna.tsinghua.edu.cn/ 进入 pypi 的问号
python -m pip install --upgrade pip pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple # ~/.config/pip/pip.conf # 或者 cat >~/.pip/pip.conf<<\EOF [global] index-url=https://mirrors.aliyun.com/pypi/simple/ [install] trusted-host=mirrors.aliyun.com EOF
常用命令
pip install pkganme #安装包 pip list #多出已安装包
导出包
虚拟环境的好处就在于和其他项目运行环境隔离。每一个独立的环境都可以使用pip命令导出已经安装的包,在另一个环境中安装这些包。
pip freeze > requirement #导出依赖包 mkdir ~/projects/pro1 cd ~/projects/pro1 pyenv local m364 mv ../web/requirement ./ pip install -r requirement #导入依赖包
安装ipython和jupyter
ipython
增强的交互式python工具,如果不想用命令行就安装个 jupyter 页面交互的。
pip list pip install ipython ipython
jupyter
是基于web的交互式笔记,其中可以非常方便的使用python,安装依赖ipython
pip install jupyter jupyter notebook help jupyter notebook --ip=0.0.0.0 --no-browser # 会输出 token ss -tanl
访问: http://127.0.0.1:8888 用 token 设置新密码并登录,点击 "new python3"
常用快捷键
- 之前插入代码块:a
- 之后插入代码块: b
- 增加行号,点住行首按l
- 删除 dd
- 运行代码块
shift + enter,选择下面的代码块 - 运行当前代码块
ctrl + enter - 出问题时 点 kernel 菜单中的 restart
JupyterLab
是基于web的交互式笔记,替代jupter.
JupyterLab 使您能够以灵活、集成和可扩展的方式处理文档和活动,例如Jupyter 笔记本、文本编辑器、终端和自定义组件。
pip install jupyterlab jupyter lab
桌面端jupterlab: jupyterlab-desktop
GNU/Linux环境
多版本共存
centos8 多环境
yum install python36 python38 #多版本共存 alternatives --config --list alternatives --config python3 # 交互式选择,全局切换
ide 使用 pycharm 社区功能足够了。
编译安装
yum install gcc libffi-devel openssl-devel -y wget https://www.python.org/ftp/python/3.7.0/Python-3.7.0.tgz tar -xzvf Python-3.7.0.tgz cd Python-3.7.0 ./configure --prefix=/usr/local/python3 make && make install ln -sv /usr/local/python3/bin/python3 /usr/bin/python3 ln -sv /usr/local/python3/bin/pip3 /usr/bin/pip3 -- vi /usr/bin/yum 将头部 #!/usr/bin/python 修改为 #!/usr/bin/python2.7 vim /usr/libexec/urlgrabber-ext-down 将/usr/bin/python改为/usr/bin/python2.7 -- 一种安装python库的方法是: $ wget https://bootstrap.pypa.io/get-pip.py $ sudo python get-pip.py $ sudo pip install psi lockfile paramiko setuptools epydoc 另一种安装python库的方法是先安装easy_install, 在安装pip以及依赖的python libs $ yum install -y python-setuptools $ easy_install pip $ pip install psi paramiko
虚拟环境
- venv
apt-get install -y python3.9 python3.9-dev python3-venv python -m venv /path/to/new/virtual/environment
范例:
python3.9 -m venv /opt/py3 source /opt/py3/bin/activate deactivate命令退出自动载入 Python 虚拟环境配置 此项仅为懒癌晚期的人员使用,防止忘记载入 Python 虚拟环境导致程序无法运行。使用autoenv
cd /opt git clone https://github.com/kennethreitz/autoenv.git echo 'source /opt/autoenv/activate.sh' >> ~/.bashrc source ~/.bashrc
python命令行输出json echo '{"id":343,"name":"kanpiaoxue"}' | python -m json.tool
- virtualenv虚拟环境
虚拟环境,之后做开发基本上是在虚拟环境中进行。普通用户启动
# 安装虚拟环境 pip3 install virtualenv # 新建一个普通用户 useradd python echo python | passwd --stdin python su - python # 设置虚拟环境 mkdir ~/venvs cd venvs virtualenv v38 virtualenv -p /usr/bin/python3.6 v36 #指定python版本解释器
工程目录,激活虚拟环境
mkdir ~/projs/cmdb source ~/venvs/v36/bin/activate # 退出虚拟环境 deactivate
- pyenv
官网:https://github.com/pyenv/pyenv
更新:
pyenv update自动安装:
#安装git yum install git -y #python 编译依赖 yum -y install gcc make patch gdbm-devel openssl-devel sqlite-devel readline-devel zlib-devel bzip2-devel # (ubuntu) sudo apt-get update; sudo apt-get install -y make build-essential libssl-dev zlib1g-dev libbz2-dev libreadline-dev libsqlite3-dev wget curl llvm libncurses5-dev xz-utils tk-dev libxml2-dev libxmlsec1-dev libffi-dev liblzma-dev #创建用户python useradd python echo 'C_python2023' | passwd --stdin python su - python #使用python用户登录后安装Pyenv curl -L https://github.com/pyenv/pyenv-installer/raw/master/bin/pyenv-installer | bash #直接从github中把脚本文件内容复制出来再执行 #在python用户的~/.bash_profile中追加 cat <<\EOF>> ~/.bash_profile #command -v pyenv >/dev/null || export PATH="$PYENV_ROOT/bin:$PATH" #add pyenv export PYENV_ROOT="$HOME/.pyenv" [[ -d $PYENV_ROOT/bin ]] && export PATH="$PYENV_ROOT/bin:$PATH" eval "$(pyenv init - bash)" eval "$(pyenv virtualenv-init -)" EOF source ~/.bash_profile #以后更新pyenv使用 pyenv update
下载的 pyenv-installer 是一个shell脚本。
手动安装:
git -c advice.detachedHead=0 clone --branch master --depth 1 https://github.com/pyenv/pyenv.git /home/python/.pyenv git -c advice.detachedHead=0 clone --branch master --depth 1 https://github.com/pyenv/pyenv-doctor /home/python/.pyenv/plugins/pyenv-doctor git -c advice.detachedHead=0 clone --branch master --depth 1 https://github.com/pyenv/pyenv-update /home/python/.pyenv/plugins/pyenv-update git -c advice.detachedHead=0 clone --branch master --depth 1 https://github.com/pyenv/pyenv-virtualenv /home/python/.pyenv/plugins/pyenv-virtualenv cat <<\EOF>> ~/.bash_profile # Load pyenv automatically by appending #~/.bash_profile if it exists, otherwise ~/.profile (for login shells) #and ~/.bashrc (for interactive shells) : export PYENV_ROOT="$HOME/.pyenv" command -v pyenv >/dev/null || export PATH="$PYENV_ROOT/bin:$PATH" eval "$(pyenv init -)" # Load pyenv-virtualenv automatically by adding # the following to ~/.bashrc: eval "$(pyenv virtualenv-init -)" EOF source ~/.bash_profile #如果是zsh则将方面内容追加至 ~/.zshrc 文件中 #验证 export PYENV_ROOT="${HOME}/.pyenv" "${PYENV_ROOT}/bin/pyenv" init || true "${PYENV_ROOT}/bin/pyenv" virtualenv-init || true
Pyenv的使用
#帮助 pyenv help <command> #pyenv help install #查看现在使用的python版本 pyenv version #查看可供pyenv使用的python版本,和当前版本 pyenv versions #列出所有可用版本 pyenv install --list #在线安装指定版本 pyenv install <python版本> -vvv #这样的安装可能较慢,为了提速,可是选用cache方法。 #卸载 pyenv uninstall <python版本>
使用缓存方式安装
在~/.pyenv/cache目录,放入下载好的待安装版本的文件,默认下xz格式。如 xz 格式的 Python-3.13.1.tar.xz
mkdir ~/.pyenv/cache cd ~/.pyenv/cache wget https://www.python.org/ftp/python/3.13.1/Python-3.13.1.tar.xz pyenv install 3.13.1 -vv #安装 pyenv install 3.10.11 -vvv pyenv versions # 查看所有已安装版本
python3.10 以后需要 OpenSSL 1.1.1 or newer 更新的版本
centos7安装openssl参考:https://computingforgeeks.com/how-to-install-openssl-1-1-on-centos-rhel-7/
#安装python #CentOS 7 with OpenSSL 1.1.1 yum install epel-release yum install readline-devel yum install openssl-devel openssl11 openssl11-devel CPPFLAGS="$(pkg-config --cflags openssl11)" \ LDFLAGS="$(pkg-config --libs openssl11)" \ pyenv install -v 3.10.11
为了方便演示,请用客户端再打开两个会话窗口。 提前安装备用 $ pyenv install 3.13.1
pyenv的python版本控制
1、global 全局设置
pyenv global 3.5.3 #可以看到所有受pyenv控制的窗口中都是3.5.3的python版本了。 #这里用global是作用于非root用户python用户上,如果是root用户安装,请不要使用global,否则影响太大。 #比如,这里使用的CentOS6.5就是Python2.6,使用了global就成了3.x,会带来很不好 #的影响。 pyenv global system #切换回系统版本
2、shell 会话设置
影响只作用于当前会话
pyenv shell 3.5.3
3、local 本地设置
使用pyenv local设置从当前工作目录开始向下递归都继承这个设置。
pyenv local 3.13.1 ; cat .python-version #使用的版本 pyenv local --unset #取消local设置
范例: 设置python版本
$ pyenv versions * system (set by /home/python/.pyenv/version) 3.13.1 3.10.11 $ mkdir -p projs/cmdb $ cd projs/cmdb/ # global 全局 $ pyenv global 3.13.1 $ python -V Python 3.13.1 $ pyenv version 3.13.1 (set by /home/python/.pyenv/version) $ pyenv global system #切换回系统版本 $ python -V Python 3.9.21 # shell 影响当前会话 $ pyenv shell 3.13.1 $ pyenv version 3.13.1 (set by PYENV_VERSION environment variable) $ python -V Python 3.13.1 $ python -V #新打开一个shell窗口 Python 3.9.21 # local本地设置 $ pyenv local 3.13.1 # cmdb 目录设置本地 python 版本 $ python -V Python 3.13.1 $ cd ../ #上层目录是系统版本 $ python -V Python 3.9.21 $ pyenv version system (set by /home/python/.pyenv/version) $ cd cmdb/ $ python -V Python 3.13.1 $ cat .python-version 3.13.1 $ pyenv local 3.10.11 # local 重新设置版本 $ cat .python-version 3.10.11 $ python -V Python 3.10.11
Virtualenv 虚拟环境
为什么要使用虚拟环境? 因为刚才使用的Python环境都是一个公共的空间,如 果多个项目使用不同Python版本开发,或者使用不同的Python版本部署运行,或 者使用同样的版本开发的但不同项目使用了不同版本的库,等等这些问题都会带 来冲突。最好的解决办法就是每一个项目独立运行自己的“独立小环境”中。
使用插件,在plugins/pyenv-virtualenv中
pyenv virtualenv 3.13.1 v3131 # 只拷贝了 setuptools和 pip 包 (v3131) ]$ ls ~/.pyenv/versions/ -l 15:23 3.13.1 v3131 -> /home/python/.pyenv/versions/3.13.1/envs/v3131 # 使用虚拟环境 pyenv local v3131 环境变量: ~/.pyenv/versions/v3131/bin/activate 激活虚拟环境 :pyenv activate <VENV> 读取环境变量文件。 退出虚拟环境 :pyenv deactivate
范例:
[python@c5 ~/projs/cmdb] eth0 = 10.0.4.12 $ pyenv virtualenv 3.10.11 v31011 [python@c5 ~/projs/cmdb] eth0 = 10.0.4.12 $ ll ~/.pyenv/versions/v31011/lib/python3.10/site-packages/ total 28 drwxrwxr-x 3 python python 4096 May 30 10:47 _distutils_hack -rw-rw-r-- 1 python python 151 May 30 10:47 distutils-precedence.pth drwxrwxr-x 5 python python 4096 May 30 10:47 pip drwxrwxr-x 2 python python 4096 May 30 10:47 pip-23.0.1.dist-info drwxrwxr-x 5 python python 4096 May 30 10:47 pkg_resources drwxrwxr-x 8 python python 4096 May 30 10:47 setuptools drwxrwxr-x 2 python python 4096 May 30 10:47 setuptools-65.5.0.dist-info [python@c5 ~/projs/cmdb] eth0 = 10.0.4.12 $ pyenv versions system 3.8.16 * 3.10.11 (set by /home/python/projs/cmdb/.python-version) 3.10.11/envs/v31011 v31011 --> /home/python/.pyenv/versions/3.10.11/envs/v31011 # local重新设置python版本,用虚拟环境 [python@c5 ~/projs/cmdb] eth0 = 10.0.4.12 $ pyenv local v31011 (v31011) [python@c5 ~/projs/cmdb] eth0 = 10.0.4.12 $ python -V Python 3.10.11 (v31011) [python@c5 ~/projs/cmdb] eth0 = 10.0.4.12 $ cat .python-version v31011
查阅帮助
官方文档
1. help() help() #进入交互模式 help(abs) #查看abs函数 2. dir([object]) 获取该对象的大部分相关属性 3. __doc__ 描述性文字信息输出 abs.__doc__
python 基础语法
python解释器
- CPython: 官方,C语言开发,最广泛的Python解释器
- IPython: 一个交互式、功能增强的CPython
- PyPy: Python语言写的Python解释器,JIT技术,动态编译Python代码
- Jython: Python的源代码编译成Java的字节码,跑在JVM上
- IronPython: 与Jython类似,运行在.Net平台上的解释器,Python代码被编译成.Net的字节码
- stackless: Python的增强版本解释器,不使用CPython的C的栈,采用微线程概念编程,并发编程
基础语法
注释
# 井号标注的文本
数字
- 整数int
- Python3开始不再区分long、int,long被重命名为int,所以只有int类型了
- 进制表示:
- 十进制10
- 十六进制0x10
- 八进制0o10
- 二进制0b10
- bool类型,有2个值True、False
- 浮点数float
- 1.2、3.1415、-0.12,1.46e9等价于科学计数法 \(1.46 x 10^9\)
- 本质上使用了C语言的double类型
- 复数complex
- 1+2j或1+2J
字符串
- 使用 ' " 单双引号引用的字符的序列
- ''' 和 """ 单双三引号,可以跨行、可以在其中自由的使用单双引号
- r 前缀 :在字符串前面加上 r 或者 R 前缀,表示该字符串不做特殊的处理
- f 前缀 :3.6版本开始,新增 f 前缀,格式化字符串
r 前缀解决转义问题
d = 'd:\windows\nt' print(d) # 会出现转义
# 解决方法1 d = 'd:\\windows\\nt' #比较麻烦 # 方法2 d = r'd:\windows\nt' # r 前缀将字符串不要转义了
字符串拼接
f 前缀格式化字符串
str(1) + ',' + 'b' # 都转换成字符串拼接到一起 "{}-{}".format(1, 'a') # {}就是填的空,有2个,就使用2个值填充 "{0}-{0}".format('a') # {}就是填的空,用索引对应的值填充 # 在3.6后,可以使用插值 a = 100; b = 'abc' f'{a}-{b}' # 一定要使用f前缀,在大括号中使用变量名
小数点取 2 位
a = 1.22333 print("a = {:.2f}".format(a)) print("a = %.2f" % (a)) #: a = 1.22 #: a = 1.22
#coding: utf-8 #format 对齐 #format处理 ={n:<2}= 冒号是分割符号, < 左对齐,后面的 n 表示变量对应的序号。 print('{0:<2} #'.format(2*3)) #居中对齐 print('{0:^3}'.format(2*3)) #: 6 # #: 6
format 用法: https://docs.python.org/3/library/string.html#formatspec
转义序列
\\ \t \r \n \' \" 上面每一个转义字符只代表一个字符,例如 \t 显示时占了4个字符位置,但是它是一个字符 前缀r,把里面的所有字符当普通字符对待,则转义字符就不转义了
转义:让字符不再是它当前的意义,例如\t,t就不是当前意义字符t了,而是被\转成了tab键
缩进
- 未使用 C 等语言的花括号,而是采用缩进的方式表示层次关系
- 约定使用 4 个空格缩进
续行
- 在行尾使用 \,注意 \ 之后除了紧跟着换行之外不能有其他字符
- 如果使用各种括号,认为括号内是一个整体,其内部跨行不用 \
范例: \ 续行
a = 'abcd'\ 'ef' print(a) # abcdef
标识符
标识符:
- 一个名字,用来指代一个值; 如 a = 'b' 其中 a 就是标识符
- 只能是字母、下划线和数字
- 只能以字母或下划线开头
- 不能是 python 的关键字,例如 def、class 就不能作为标识符
- Python 是大小写敏感的
标识符约定:
- 不允许使用中文,也不建议使用拼音
- 不要使用歧义单词,例如
class_ - 在python中不要随便使用下划线开头的标识符
常量
- 一旦赋值就不能改变值的标识符
python 中无法定义常量
字面常量
一个单独的不可变量,例如 12、"abc" 、'2341356514.03e-9'
如 a = 1 后 a = a + 1 ,其中 1 是字面常量,a 不是字面常量,a 等于 2 是因为 a 的指向变了,1+1 等于新的字面常量 2,a 从指向 1 变为指向 2
变量
- 赋值后,可以改变值的标识符
标识符本质
每一个标识符对应一个具有数据结构的值,但是这个值不方便直接访问,程序员就可以通过其对应的标识符来访问数据,标识符就是一个指代。一句话,标识符是给程序员编程使用的。
语言类型
Python 是动态语言、强类型语言
静态语言
- 事先声明变量类型,之后变量的值可以改变,但值的类型不能再改变
- 编译时检查
动态语言
- 不用事先声明类型,随时可以赋值为其他类型
- 编程时不知道是什么类型,
很难推断
一些争议
静态语言 const int b = 200; int a=100; #定义变量的时候赋值了,要求变量必须是整数类型 a=200 #right a ='abc' # wrong#静态语言有了类型,有了约束。在编译的时候就可以做类型检查,提前发现问题 动态语言 a=100 #不需要指定类型,爱给什么给什么 a='abc' # a指问新的值,可以是新的类型 # 数据的类型没有任何的约束 # 在运行时,才能发现类型不对了,太晚了,
很多人在说 Python 这一语言特性,不做类型检查。 所以从 3.5 开始,增加了很多类型检查
强类型语言
- 不同类型之间操作,必须先强制类型转换为同一类型。如 python 代码
print('a'+1)报错
弱类型语言
- 不同类型间可以操作,自动隐式转换,JavaScript 代码
console.log(1+'a')正常
但是要注意的是,强与弱只是一个相对概念,即使是强类型语言也支持隐式类型转换。
范例:
type(1 + 2) # int type(1 + 2.1 + True) # int + float => float # 悄悄地,隐式的类型转换 #print( 1 + 'a') # 报错,不能做隐式转换 print(str(1) + 'a') # 拼接 # 必须强制类型转换
进制(重要)
常见进制有二进制、八进制、十进制、十六进制。应该重点掌握二进制、十六进制。
十进制逢十进一;十六进制逢十六进一;二进制逢二进一
每8位(bit)为1个字节(byte)
一个字节能够表示的整数的范围:
- 无符号数 0~0xFF,即0到255,256种状态
- 有符号数,依然是256种状态,去掉最高位还剩7位,能够描述的最大正整数为127,那么负数最大就为-128。也就是说负数有128个,整数有127个,加上0,共256种。
十六进制中每 4 位断开转换 1000 0000 二进制 2**7 =128
8 0 十六进制 8 * 16 = 128
八进制每 3 位断开转换
10 000 000
2 0 0 八进制 2*(8**2) + 0 + 0= 128
转为十进制:
按位乘以权累加求和 - 0b1110 二进制转十进制计算为 1*(2**3) + 1*(2**2) + 1*(2**1) + 0*(2**0)= 14 - 0o664 八进制转十进制计算为 6*(8**2) + 6*(8**1) +4*(8**0) = 436 - 0x41 十六进制转十进制计算为 4*16 + 1*1=65
口诀 :
- 2^0=1=1b - 2^1=2=10b - 2^3=8=1000b - 2^4=16=10000b - 2^5=32=100000b - 2^6=64=1000000b - 2^7=128=10000000b - 2^8=256=100000000b - 2^9=512=1000000000b - 2^10=1024=10000000000b - 2^11=2048=100000000000b - 2^12=4096=1000000000000b
8421法则 : 将二进制的每一位数用相对就的 8、4、2、1 来表示,再通过“数字 ”相加就可以得到二进制数的数据
8 1000
4 100
2 10
1 1
1000
100
10
1
--------
1 1 1 1
1 位数:如果是该数本身
2 位数:如果都有值是2+1
3 位数:如果都有值是4+2+1
4 位数:如果有值是8+4+2+1
范例:
# coding: utf-8 a = 10 b = 0xa # 十六进制 c = 0o12 # 八进制 d = 0b1010 # 二进制 print(a, b, c, d) #默认使用十进制展示 #10 10 10 10
范例:转十进制
# 10 --> 10 进制 123 = 1 * (10**2) + 2 * (10 ** 1) + 3 * (10**0) 123 = 1 * (10**2) + 2 * 10 + 3 * 1 # 2 --> 10 进制 ob1010 = 1 * (2 ** 3) + 0 * (2**2) + 1 *(2 ** 1) + 0 * (2**0) ob1010 = 1 * (2**3) + 0 + 1 * (2**1) + 0 = 1 * 8 +1 * 2 8 + 0 + 2 + 0 # 8 --> 10 进制 0o12 = 1 * 8 + 2 * 1 = 10 # 16 --> 10 进制 0x11 = 1 * (16 ** 1) + 1 * (16 ** 0) = 1 * 16 + 1 * 1 = 17
范例:
1 bytes 8bits 00000000 无符号 0 00000011 # 3 1 # 1 ------------ 100 # 4 无符号数 00000000 # 0x00 0 0 11111111 => 0xff => 15 * 16 + 15 * 1 = 255 F f 11111111 + 1 --------- 100000000 # 2 ** 8 = 256 上面 0xff = 256 - 1
特殊二进制数
#计算技巧 2 0b 16 0x 10 1 1 1 11 3 3 111 7 7 1111 f 15 11111 1f 2**5 -1 =31; 16*1 + 15*1=31 111111 3f 63 2*6 - 1; 3f = 3f + 1 - 1 = 0x40 = 4 * 16 + 0 - 1 = 64 -1 01111111 7f 0x80 - 1 = 8 * 16 - 1 = 127 10000000 80 128 11000000 c0 0xc0 = 128 + 64 = 192 11111111 ff 255 100000000 100 256 0~255 有多少种变化? 0x00 ~ 0xFF ,256 种变化状态
常见的十六进制和十进制的对应关系
0x 10进制 0x0 0 0x1 1 0x8 8 0x9 9 0xa 10 0xd 13 0x10 16 0x20 32 0x31 49 0x41 65 0x61 97 0xff 255 11111111 0x7f 127 0xfe 255
转到二进制
十六进制转二进制 0xF8 按位展开即可,得到 0b1111 1000 八进制转二进制 0o664 按位展开即可,得到ob 110 110 100; 16进制 0x1B4; 6*64 + 6 * 8 + 4 = 384 + 48 + 4 = 436
十进制转其他进制
十进制转二进制 127 除以基数 2,直到商为 0 为止,反向提取余数 十进制转为十六进制 127 除以基数 16,直到商为 0 为止,反向提取余数
码制
属于计算机基础原理。
原码
- 5 => 0b101, 1 => 0b1, -1 => -0b1, bin(-1)
是一种自然表达
范例:
# coding: utf-8 # 原码 人喜欢 #进制:2 16 8 print(bin(1), hex(1), oct(1)) #: 0b1 0x1 0o1
原码 1字节整型为例 给人看的, 计算机不是这样存的 short 0b10000000 00000001 0b0000 0001 # 正1 0b1000 0001 # 负1,原码中,最高位置 1, 表示负数
反码
- 正整数的反码与原码相同
- 负数的反码 符号位不变 其余各位按位取反
范例:
0b0000 0001 #正1 0b1000 0001 #原码负1 0b1111 1110 #反码负1
反码运算也不方便,通常用来作为求补码的中间过渡。
补码
在计算机内部,数值一律用补码存储
- 正整数的补码与原码相同
- 负数的补码 符号位不变 其余按位取反后并在最低位+1,即反码加1
- 补码的补码就是原码
范例:
0b0000 0001 #正1 0b1000 0001 #原码负1 0b1111 1110 #反码负1 0b1111 1111 #补码负1,反码+1,0xff 255 如果代表的是有符号数,他其实是-1 0xfe 请问 1 字节的有符号数,请问它的十进制是多少? 1000 0010 # -2 原码 1111 1101 # -2 的反码 1111 1110 # -2 的补码, 0xfe #补码的补码是原码 1111 1110 #-2的补码 1000 0001 + 1 1000 0010 #-2补码的补码
负数表示法
- 早期数字电路的 CPU 中的运算器实现了加法器,但是没有减法器,减法要转换成加法
- 负数在计算机中使用补码存储,-1 的补码为 1111 1111
- 5 -1 => 5 +(-1) 直觉上是 0b101-0b1,其实计算机中是 0b101_0b1111 1111,溢出位舍弃
# 5 - 1 => 5 + (-1) 0000 0101 1111 1111 # 原码为1000 0001 ----------- 0000 0100 0000 0101 是 0000 0001 + 0000 0100, 0000 0001 + 1111 1111 = 1 0000 0000 其中 1 是溢出位舍弃, 得到 0000 0000 再加剩下的 0000 0100 ,最终结果为 0000 0100
在内存中数据都是无差别的,除非赋予它类型,如 a 是正数并指向这个地址。
python中都是有符号类型,没有无符号类型。
False 等价
| 对象/常量 | 值 |
|---|---|
| "" | 假 |
| "string" | 真 |
| 0 | 假 |
| >=1 正整数 | 真 |
| <=-1 负整数 | 真 |
| ()空无组 | 假 |
| []空列表 | 假 |
| {}空字典 | 假 |
| None | 假 |
False等价 布尔值,相当于bool(value)
- 空容器
- 空集合set
- 空字典dict
- 空列表list
- 空元组tuple
- 空字符串
- None
- 0
范例:
# coding: utf-8 print(bool("")) print( bool(0.1),bool(-0.0001), bool(0.00000) ) #: False #: True True False
逻辑运算真值表
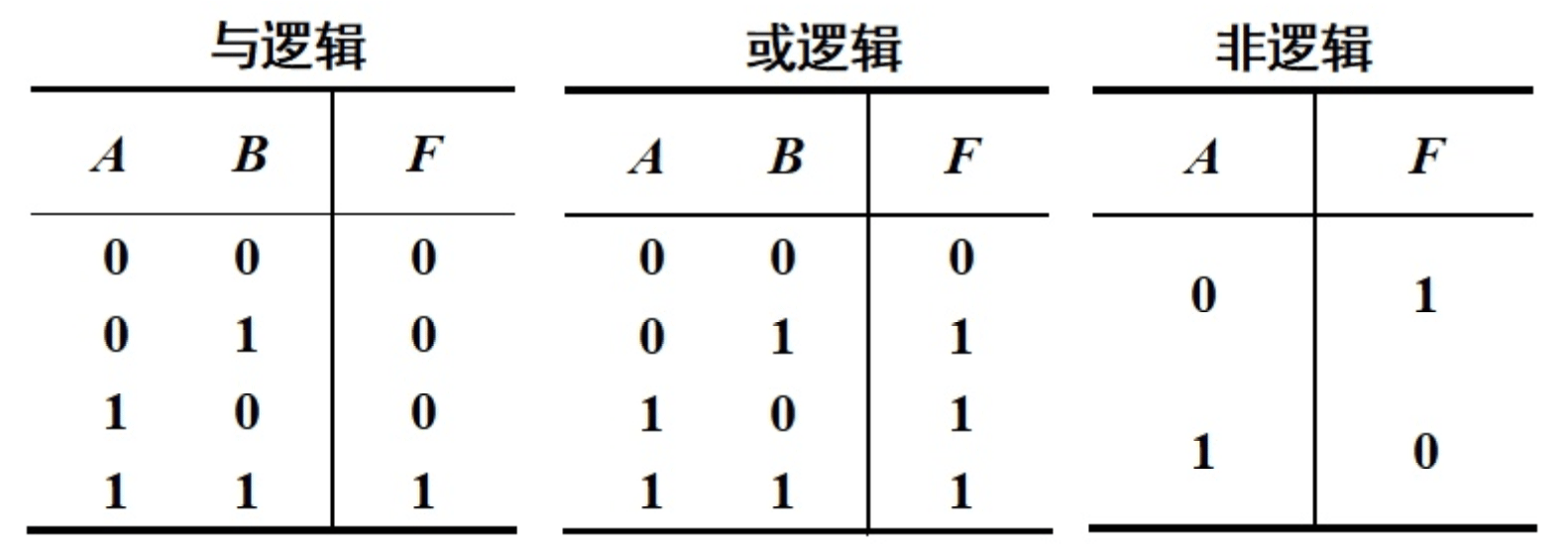
| 与逻辑 | 或逻辑 | 非逻辑 | ||
|---|---|---|---|---|
| A B | F | A B | F | A | F | ||
| 0 0 | 0 | 0 0 | 0 | 0 | 1 | ||
| 0 1 | 0 | 0 1 | 1 | |||
| 1 0 | 0 | 1 0 | 1 | 1 | 0 | ||
| 1 1 | 1 | 1 1 | 1 |
逻辑运算中只有 True 或 False。上面 0 表示假, 1 表示真,A与B,A或B,非A。对应的表达示
与 或 非 & | ~ A&B A|B A~B
为了清楚的计算我们可以把 与看成乘法、或看成加法、非在数学是数字有个横线 \(\overline{A}\)
范例:
- 与: \(0 \times 0|1 = 0 , 1 \times 1 = 1\)
- 或: \(0 + 0 = 0 , 1 + 1 = 1(true)\)
- 非: \(\overline{0} = 1\)
运算符Operator
算数运算符
+、-、*、/、//向下取整整除、%取模(取余)、**幂
注:在Python2中 / 和 // 都是整除。
范例:
# coding: utf-8 print(1/2, "--", 1//2) print(2**4, "--", 2 ** 0.5) # 2的4次幂,2的开方 print(2%3) #: 0.5 -- 0 #: 16 -- 1.4142135623730951 #: 2
位运算符
&位与、|位或、^异或、<<左移、>>右移 ~按位取反,包括符号位 ~12 是多少? 10^9 等于? 10^-9 等于多少?
| 运算符 | 术语 | 说明 | 示例 |
|---|---|---|---|
| & | 按位与 | 参与运算的两数各对应的二进制位相与 | 60&13结果为12 |
| | | 按位或 | 参与运算的两数各对应的二进制位相或 | 60|13结果为61 |
| ^(脱字符) | 异或 | 参与运算的两数各对应的二进制位相异或,当两对应的二进制位相异时,结果为1 | 60^13结果为240 |
| << | 左移 | 左移n位就是乘以2的n次方。左边丢弃,右边补0 | 4<<2结果为16,4*(2**2)=16 |
| >> | 右移 | 右移n位就是除以2的n次方。右边丢弃,左边补位 | 4>>2结果为1,4/(2**2)=1 |
位操作连符号位一起操作,数据在内存中放的是补码,机器内部是按补码操作的,需要再补码一次才是我们能看到的原码。
范例:
# 按拉与 相当于相乘 5 & 3 = 1 0000 0101 0000 0011 & ----------- 0000 0001 1 # 按位或 相当于相加 5 | 3 0000 0101 0000 0011 | ----------- 0000 0111 7 # 异或 5 ^ 3 0000 0101 0000 0011 ^ #相异出1 ----------- 0000 0110 6 # 左移 乘以 2 的位数次幂 1 << 0 #1 * 2**0 0000 0001 1 1 << 1 #1 * 2**1 0000 0010 2 1 << 2 #1 * 2**2 0000 0100 4 1 << 3 #1 * 2**3 0000 1000 8 # 右移 除以 2 的位数次幂 8 >> 1 # 8 / (2**1) 相当于 8//2
# coding: utf-8 print(5 & 3, "--", 5 | 3, "--", 5 ^ 3) print(1 << 0, 1 << 1, 1<<2, 1 << 3) print(8 >> 1, 8//2, '--', 8>> 2, 8//2**2, '--', 8>>3) print(8>>4, 8//2**4) #: 1 -- 7 -- 6 #: 1 2 4 8 #: 4 4 -- 2 2
在 C 语言中, 移位运算 的效率是极高的,比求幂的运算快很多。
~ 按位取反,包括符号位
范例:~12 是多少?
#~12 是多少?
0000 1100 #12补码,存放在计算机内
~ 按位取反,不管符号位
--------------------
1111 0011 # 计算机认为放的是补码,展示出来给人看需要再被码一次,因为补码的补码是原码
#1111 0011 的补码
1000 1100 # 反码
1000 1101 # 补码=反码+1
-----------
-13
# coding: utf-8 print(~12) #: -13
范例: 10^9 等于? 10^-9 等于多少?
# 10 ^ 9 0000 1010 0000 1001 ^ # 相异出1 --------- 0000 0011 3 # 位操作连符号位也一起操作 # 10 ^ -9 # 负数转换为补码做运算 0000 1010 #1000 1001 #原码 -9转换成补码再与10做异或 1000 0111 ^ # 相异出1 ----------- 1000 1101 # 补码,展示出来还需要补码原码 #1000 1101 1000 0011 -3
# coding: utf-8 print(10 ^ 9, 10^-9) #: 3 -3
比较运算符
==、!=、>、>=、<、<=
链式比较: 4 > 3 > 2 比较运算符,返回一个bool值 思考:1 == '1' 吗? 1 > '1' 吗?
# coding: utf-8 print(2>3, 1 == True) #: False True #print(1 > '1') # 不同类型不能比较 print(4 > 3 > 5) # 链式比较 #: False
比较运算符要求同类比较
逻辑运算符
与and、或or、非not
范例:
# coding: utf-8 a = 2 print(a > 200 and a < 300) #: False print(1 and 'abc') # 逻辑运算符是把所操作的数值当做真或假来进行逻辑运算,完了之后返回的是还是原来的值 #: abc
逻辑运算符也是短路运算符
and 如果前面的表达式等价为False,后面就没有必要计算了,这个逻辑表达式最终一定等价为False
1 and '2' and 0 #结果0 0 and 'abc' and 1 #结果0 , and遇到False后面就不用计算了,结果一定为False,短路 #短路的写前面。0写前面后面就不用算了,可以做为优化点
or 如果前面的表达式等价为True,后面没有必要计算了,这个逻辑表达式最终一定等价为True
1 or False or None
- 特别注意,返回值。返回值不一定是bool型
- 把最频繁使用的,做最少计算就可以知道结果的条件放到前面,如果它能短路,将大大减少计算量
范例:
# coding: utf-8 a = 123 print(a or False or None) #: 123
赋值运算符
a = min(3, 5) +=、 -= 、*=、/=、%=、//= 等 x = y = z = 10
赋值语句先计算 等式右边 ,然后再赋值给变量
范例
a = 1 a += 1 # a = a + 1 print(a) #: 2
成员运算符
in、not in,用来判断是否是容器的元素,返回布尔值。后面列表、元组中会讲到
身份运算符
is 、is not,用来判断是否是同一个对象。后面会讲到。
运算符优先级
| 排序 | 运算符 | 描述 |
|---|---|---|
| 1 | 'expr' | 字符串转换 |
| 2 | {key:expr,…} | 字典 |
| 3 | [expr1,expr2…] | 列表 |
| 4 | (expr1,expr2…) | 元组 |
| 5 | function(expr,…) | 函数调用 |
| 6 | x[index:index] | 切片 |
| 7 | x[index] | 下标索引取值 |
| 8 | x.attribute | 属性引用 |
| 9 | ~x | 按拉取反 |
| 10 | +x, -x | 正,负 |
| 11 | x**y | 幂 |
| 12 | x*y, x/y, x%y | 乘,除,取模 |
| 排序 | 运算符 | 描述 |
|---|---|---|
| 13 | x+y, x-y | 加,减 |
| 14 | x ≪ y, x ≫ y | 移位 |
| 15 | x&y | 按位与 |
| 16 | x ^ y | 按位异或 |
| 17 | x | y | 按位或 |
| 18 | x < y, x<=y, x==y | 比较 |
| x!=y, x>=y, | ||
| x>y | ||
| 19 | x is y, x is not y | 等同测试 |
| 20 | x in y, x not in y | 成员判断 |
| 21 | not x | 逻辑否 |
| 22 | x and y | 逻辑与 |
| 23 | x or y | 逻辑或 |
| 24 | lambda arg,…:expr | Lambda匿名函数 |
单目运算符 > 双目运算符
这里的单目即一元运算符,只需要一个操作数。如,-2, +2
双目运算符是指需要两个操作数进行运算的运算符。例如,加法运算符“+”就是一个双目运算符,它需要两个操作数进行加法运算。双目运算符通常是放在两个操作数之间,用来表示两个操作数之间的关系或操作
- 算数运算符 > 位运算符 > 比较运算符 > 逻辑运算符
-3 + 2 > 5 and 'a' > 'b'
搞不清楚就使用括号。长表达式,多用括号,易懂、易读。高级语言的运算符优先级几乎是一样的。
范例:
3 + (-2) # +符号双目 -符号单目 1 > 2, 1 <= 2, 1==2 # 双目 +2 #单目 -2 #单目 ~12 #单目 #优先级 2 * (2**3)
python 中没有三目运算符。
表达式
由数字、符号、括号、变量等的组合。有算数表达式、逻辑表达式、赋值表达式、lambda表达式等等。
Python中, 赋值即定义 。Python是动态语言,只有赋值才会创建一个变量,并决定了变量的类型和值。
如果一个变量已经定义,赋值相当于重新定义。
范例:赋值即定义
#python中赋值即定义,决定了变量的类型和值 a = 100 + 200 a = 'abc'
内建函数
所有内建函数在 python 帮助文档中可以找到,windows 用户在安装目录下找到 Doc/python.chm,搜索 __import__() (built-in function)
| 内建函数 | 函数签名 | 说明 |
|---|---|---|
| print(value,…,sep=' ',end='\n') | 将多个数据输出到控制台,默认使用空格分隔、\n换行 | |
| input | input([prompt]) | 在控制台和用户交互,接收用户输入,并返回字符串 |
| int | int(value) | 将给定的值,转换成整数。int本质是类 |
| bool | bool(value) | 将给定的值,转换成bool值。bool本质是类 |
| str | str(value) | 将给定的值,转换成字符串。str本质是类 |
| type | type(value) | 返回对象的类型。本质是元类 |
| isinstance | isinstance(obj,class_or_tuple) | 比较对象的类型,类型可以是obj的基类 |
int
int(value)将给定的值,转换成整数。int本质是类
范例:
# coding: utf-8 int('1'), int(2.2) # 强制类型转换 #: 1 2 #int('a') 报错。class int(x, base=10) 是基于 10 进制的 print(int('a', base=16)) # 0xa #: 10
str
str(value)将给定的值,转换成字符串。str本质是类,目的是展示给人看。在 python 中所有东西都能转换成字符串。
范例:
# coding: utf-8 # 列表转换成字符串 print(str([])) # 转换成字符串,目的展示给人看 #: [] # 函数转换成字符串 def a(): print('aaa') print(str(a)) # 目的,用一种字符串表达,展示出来; 强制类型转换 #: <function a at 0x000001C3C4BD8A40>
type
type(value)返回对象的类型。本质是元类
范例:
# coding: utf-8 def a(): print('aa') print(type(1),type('abc'),type(a)) # type 返回的是类型 #: <class 'int'> <class 'str'> <class 'function'> #print(type(1) == 'int') # 假,type 返回的是类型 print(type(1) == int) print(type(False) == bool, type(True) == int) # False, True虽然是int 的子类,但不一个类 #: True #: True False #特殊情况, type 返回类型的类型都是 type,了解面向对象之后就明白了。 #type 是元类,是构建所有类型的类 print(type(int), type(list), type(str), type(type)) # : <class 'type'> <class 'type'> <class 'type'> <class 'type'> print(type(1 + True), 1+True) # 发生了隐式类型转换 print(type(1 + True + 2.1), 1 + True + 2.1) #: <class 'int'> 2 #: <class 'float'> 4.1
isinstance
isinstance(obj, class_or_tuple)比较对象的类型,类型可以是obj的基类
范例:
# coding: utf-8 print(isinstance(1, int)) # 是否是后面指定的那个类型的实例, type(1) == int print(isinstance(False, int)) # True, False 是 Int 类型或子类吗? 是 print(isinstance(1, (str, list, tuple, int))) #1是这些中的其中之一吗 #: True #: True #: True
input
input([prompt]) # prompt 命令指示符
在控制台和用户交互,接收用户输入,并返回字符串
范例:
# coding: utf-8 intput("请输入数据")
print
print(*objects, sep=' ', end='\n', file=sys.stdout, flush=False) #sep 分隔符,默认空格 #end 行尾,默认换行
范例:
# coding: utf-8 def a(): print('aa') print(1,2,3,[],[1,2,3],a) #: 1 2 3 [] [1, 2, 3] <function a at 0x00000170CE8A8A40> print(1,2,3,sep='\n', end='***') #print() print(1,2, end=' ') print(3,4, end='\n') #: 1 #: 2 #: 3***1 2 3 4
将多个数据输出到控制台,默认使用空格分隔、\n换行
数值型
- int、float、complex、bool都是class,1、5.0、2+3j都是对象即实例
- int:python3的int就是长整型,且没有大小限制,受限于内存区域的大小
- float:由整数部分和小数部分组成。支持十进制和科学计数法表示。C的双精度型实现
- complex:有实数和虚数部分组成,实数和虚数部分都是浮点数,3+4.2J
- bool:int的子类,仅有2个实例True、False对应1和0,可以和整数直接运算
类型转换
- int、float、complex、bool也可以当做内建函数对数据进行类型转换
- int(x) 返回一个整数
- float(x) 返回一个浮点数
- complex(x)、complex(x,y) 返回一个复数
- bool(x) 返回布尔值,前面讲过False等价的对象
范例:
print( float('1.2'), float(1), float('1e-2') ) #: 1.2 1.0 0.01
整除
math模块的floor()、ceil()函数;内建函数int()、round();运算符 //
# coding: utf-8 # ceil floor print('ceil floor ------------') import math # 导入 match 模块供你使用 print(math.ceil(2.5), math.ceil(-2.5)) # 大一点就向上取整 print(math.floor(2.5), math.floor(-2.5)) # 小一点就向下取整 #3 -2 #2 -3 # 整除 // 向下取整 print('// -----------') print(1//2, 3//2, 5//2, 7//2) print(1//-2, -3//2, 5//-2, -7//2) # 负数部分,向下; // 向下取整。doc 文档 // 解释 x // y floored quotient of x and y #0 1 2 3 #-1 -2 -3 -4 # int 只截取整数部分 print('int ------------') print(int(1.4), int(1.5), int(1.6)) print(int(-1.4), int(-1.5), int(-1.6)) #1 1 1 #-1 -1 -1 # round 正好 .5 的时候找离他最近的偶数,四舍六五入取偶 print('round ------------') print(round(0.1), round(0.6), round(1.2), round(1.7), round(2.3), round(2.8)) print(round(0.50000001), round(1.5000001), round(2.50000001)) print(round(0.5), round(1.5), round(2.5), round(3.5))# 正好 .5 的时候找离他最近的偶数,四舍六入五取偶 print(round(-0.5), round(-1.5), round(-2.5), round(-3.5)) #0 1 1 2 2 3 #1 2 3 #0 2 2 4 #0 -2 -2 -4
- round(),四舍六入五取偶
- math.floor()向下取整
- math.ceil()向上取整
- int() 取整数部分
- // 整除且向下取整
常用数值处理函数
- math模块
- math.pi π
- math.e 自然常数
- math模块中还有对数函数、三角函数等
- math.sqrt() 于 x ** 0.5
- pow(x, y) 等于 x ** y
- min()、max()
- abs()
- 进制函数,返回值是字符串
- bin()、oct()、hex() 对应二进制、8进制、16进制表达
范例:math 中其他常量和函数:
# coding: utf-8 import math print(math.pi) # pi 圆周率 print(math.e) # e 自然常数 print(math.pow(2, 3), pow(2, 3), 2 ** 3) #pow 求次方 print(math.sqrt(2), 2 ** 0.5) # 开方 #: 3.141592653589793 #: 2.718281828459045 #: 8.0 8 8 #: 1.4142135623730951 1.4142135623730951
范例:
# coding: utf-8 #max min 求最大最小值 #max(iterable, *[, default=obj, key=func]) -> value # 可迭代对象。 key 为高阶函数 #max(arg1, arg2, *args, *[, key=func]) -> value print(max([1,2,3,4]), min([1,2,3])) # 可迭代对象 print(max(1,2,3,1,2)) # 当前是同种类型;不同类型就小涉及排序问题,要用到 key 高阶函数 print(min('a','b','c')) #: 4 1 #: 3 #: a
程序控制
- 顺序
- 按照先后顺序一条条执行
- 例如,先洗手,再吃饭,再洗碗
- 分支
- 根据不同的情况判断,条件满足执行某条件下的语句
- 例如,先洗手,如果饭没有做好,玩游戏;如果饭做好了,就吃饭;如果饭都没有做,叫外卖
- 循环
- 条件满足就反复执行,不满足就不执行或不再执行
- 例如,先洗手,看饭好了没有,没有好,一会来看一次是否好了,一会儿来看一次,直到饭好了,才可是吃饭。这里循环的条件是饭没有好,饭没有好,就循环的来看饭好了没有
单分支
if condition: 代码块 if 1<2: # if True: print('1 less than 2') # 代码块
- condition必须是一个bool类型,这个地方有一个隐式转换bool(condition),相当于False等价
- if 语句这行最后,会有一个冒号,冒号之后如果有多条语句的代码块,需要另起一行,并缩进
- if、for、def、class等关键字后面都可以跟代码块
- 这些关键后面,如果有一条语句,也可以跟在这一行后面。例如
if 1>2: pass不建设这样定民,不符合 PEP 规范
多分支
if condition1: 代码块1 elif condition2: 代码块2 elif condition3: 代码块3 ...... else: 代码块
范例: 多分支
# coding: utf-8 a = 5 if a<0: print('negative') elif a==0: # 相当于 a >= 0 print('zero') else: # 相当于 a > 0 print('positive')
- 多分支结构,只要有一个分支被执行,其他分支都不会被执行
前一个条件被测试过,下一个条件相当于隐含着这个条件
范例: 嵌套
score = 80 if score<0: print('wrong') else: if score==0: print('egg') elif score <= 100: print('right') else: print('too big')
if 语言嵌套并不会对性能有太大的影响。for 循环、while 循环都可以互相嵌套,形成多层循环。循环嵌套不易过深。
while循环
while循环多用于死循环,或者不明确知道循环次数的场景。一般用 for 循环比较多。
while cond: block while True: # 死循环 pass
范例:
# coding: utf-8 a = 10 while a: # 条件满足则进入循环,找到边界 print(a) a -= 1
10 9 8 7 6 5 4 3 2 1
会不会打印出0?要注意边界的分析 如果a=-10可以吗?如何改?回忆一下,False等价是什么?
for语句和 range
for element in iteratable: # 可迭代对象中有元素可以迭代,进入循环体 block for i in range(0, 10): print(i)
在 python 可迭代对象非常多,可以说是包罗万象。
遍历: 容器中所有的元素不重复的取一遍。
print(range(3)) #: range(0, 3)
range
内建函数,直接返回一个 range 对象。并不是直接立即返回数据,惰性对象。
惰性对象,必须使用一些方法,去里面拿出数据,你不拿他不给。
range 对象是可迭代对象,它有内容,但是你必须驱动它
for i in range(3): # 默认会一次次驱动它,直到遍布完成 print(i)
语法格式:
range(stop) -> range object #给终点,默认起点就是 0,返回的 [0, stop) 前包后不包 [0, stop - 1] range(start, stop[, step]) -> range object # setp 步长
计数器:
- range(1) # 0 计数 1 次
- range(0) # [0, 0) 计数 0 次
- range(-1) # 进不去循环
范例:
# coding: utf-8 print(range(0, 1)) # [0,1) range(1) 0 1个数据 计数器 print(range(0, 10)) # [0,10) range(10) 0~9 10个数据 计数器
练习: 打印1到10 打印10以内的奇数 打印10以内的偶数 倒着打印10以内的奇数或偶数
范例: 打印 10 以内奇数
# coding: utf-8 # 打印奇数多种方法 for i in range(10): if i % 2 == 1: print(i) for i in range(10): if i % 2: print(i) for i in range(10): if i % 2 != 0: print(i) for i in range(10): if i & 1: #位与 1 相与得 1,说明是奇数。 print(i) for i in range(1, 10, 2): #第3个参数步长 print(i) # 小结 # 上面的需要迭代 10 次,虽然位与挺有效率,但要做 cpu 计算就会消耗时间。 # 最后一个控制步长方式迭代了 5 次,而且只做加法,效率更高。
# coding: utf-8 # 打印偶数 for i in range(0, 10): if i % 2 == 0 : print(i) for i in range(0, 10, 2): print(i) # 倒着打印偶数 for i in range(8, -1 , -2): print(i) # 倒着打印奇数 for i in range(9, 0 , -2): print(i) # 2 ** 0 => 2 ** 10 for i in range(11): print(i, 2 ** i)
continue
跳过当前循环的当次循环,继续下一次循环
for i in range(0, 10): if i % 2 != 0 : continue print(i) for i in range(10): if i % 2 != 0 : continue print(i) for i in range(10): if i & 1: continue print(i)
break
结束当前循环
练习:计算1000以内的,从7开始,被7整除的前15个正整数(for循环)
# coding: utf-8 # 计算1000以内的被7整除的前15个正整数 count = 0 for i in range(7, 1000, 7): print(i) count += 1 if count >= 15: print(count) break
总结
- continue和break是循环的控制语句,只影响当前循环,包括while、for循环
- 如果循环嵌套, continue和break也只影响语句所在的那一层循环
- continue和break 只影响循环 ,所以 if cond: break 不是跳出if,而是终止if外的break所在的循环
- 分支和循环结构可以 嵌套 使用,可以嵌套多层。 2 层循环是极限。
else子句
如果循环正常结束,else子句会被执行,即使是可迭代对象没有什么元素可迭代
for i in range(0): # 可迭代对象没有迭代 pass else: print('ok') for i in range(0,10): break else: print('ok') for i in range(0,10): continue else: print('ok')
有上例可知,一般情况下,循环正常执行,只要当前循环不是被break打断的,就可以执行else子句。哪怕是range(0)也可以执行else子句。
三元表达式
在Python中,也有类似C语言的三目运算符构成的表达式 ?: ,但python中的三元表达式不支持复杂的语句
真值表达式 if 条件表达式 else 假值表达式
范例:
#coding: utf-8 a = 5 if a > 5: print('> 5') else: print('<= 5') #: <= 5 # 三元表达式 a = 5 print('> 5') if a > 5 else print('<= 5') #: <= 5 s = '> 5' if a > 5 else '<= 5' print(s) #: <= 5 print('> 5' if a > 5 else '<= 5') #: <= 5
三元表达式比较适合简化非常简单的if-else语句。
# 判断用户的输入的值,如果为空,输出"empty",否则输出该值 value = input('>>>') if value: print(value) else: print('empty') value = input('>>>') print(value if value else 'empty')
练习1
- 给一个半径,求圆的面积和周长。圆周率3.14
- 输入两个数,比较大小后,从小到大升序打印
- 依次输入若干个整数,打印出最大值。如果输入为空,则退出程序
- 打印位数
- 给定一个不超过5位的正整数(不转换为字符串),判断该数的位数,依次打印出万位、千位、百位、十位、个位的数字
- 给定一个不超过5位的正整数,判断该数是几位数,依次从万位打印到个位的数字
- 输入n个数,求每次输入后的算数平均数
- 打印一个边长为n的正方形,空心的
- 求100内所有奇数的和(2500)
- 成绩问题 判断学生成绩,成绩等级A至E。其中,90分以上为A,80~89分为'B',70~79分为'C,60~69分为'D',60分以下为'E'
- 求1到5阶乘之和
给一个数,判断它是否是素数(质数)
质数:一个大于1的自然数只能被1和它本身整除
给一个半径,求圆的面积和周长。圆周率3.14
圆的周长和面积公式是:
- 圆的周长公式:\(C = 2 \pi r \ 或者\ C = \pi d\) ,其中 r 是圆的半径,d 是圆的直径,\(\pi\) 是圆周率,通常取值为3.14。
- 圆的面积公式:\(S = \pi r^2 \ 或者\ S = \pi (d/2)^2\) ,其中 r 是圆的半径,d 是圆的直径,π 是圆周率,通常取值为3.14。
# coding: utf-8 #radius = int(input('radius = ')) radius = 5 pi = 3.14 C = 2 * pi * radius S = pi * (radius ** 2) print(C, S) print("C = %.2f, S = %.2f" % (C, S)) #: 31.400000000000002 78.5 #: C = 31.40, S = 78.50
输入两个数,比较大小后,从小到大升序打印
#first = int(input("1>>: ")) #second = int(input("2>>: ")) first = float("2.2") second = float("3.2000001000000000010") if first >= second: print(second, first) else: print(first, second)
依次输入若干个整数,打印出最大值。如果输入为空,则退出程序
x = int(input("Plz input your first name : ")) m = x while True: x = input('Plz input a number >>>') # if x == '': # break if x: x = int(x) if x > m: m = x print('Current Max Value = ', m) else: break
打印位数
- 给定一个不超过5位的正整数(不转换为字符串),判断该数的位数,依次打印出万位、千位、百位、十位、个位的数字
打印数字 难点在于如何对一个正整数进行迭代处理。假设有数字 54321, 目标打印出 5、4、3、2、1
第一趟 54321 // 10000 = 5 54321 % 10000 = 4321 第二趟 4321 // 1000 = 4 4321 % 1000 = 321 第三趟 321 // 100 = 3 321 % 100 = 21 第四趟 21 // 10 = 2 21 % 10 = 1 第五趟 1 // 1 = 1 1 % 1 = 0
第一步,找规律
# coding: utf-8 #y = int(input('>>> ')) y = int('54321') w = 10000 # 权位 x = y // w # 取模 5 y = y % w # 取余 4321 print(x, y) w = w // 10 # 1000 x = y // w # 取模 4 y = y % w # 取余 321 print(x, y) w = w // 10 # 100 x = y // w # 取模 3 y = y % w # 取余 21 print(x, y) w = w // 10 # 10 x = y // w # 取模 2 y = y % w # 取余 1 , 最后余数 print(x, y) w = w // 10 # 1 x = y // w # 取模 1 y = y % w # 取余 0 print(x, y) w = w // 10 # 0.1 #: 5 4321 #: 4 321 #: 3 21 #: 2 1 #: 1 0
第二步,加入循环
# coding: utf-8 #y = int(input('>>> ')) y = int('54321') w = 10000 # 权位 for i in range(5): x = y // w y = y % w print(x, y) w = w // 10 #: 5 4321 #: 4 321 #: 3 21 #: 2 1 #: 1 0
第3步, 第 2 步中第 5 次循环无用,最后余数已在第 4 次算出
# coding: utf-8 #y = int(input('>>> ')) y = int('54321') w = 10000 # 权位 for i in range(4): x = y // w y = y % w print(x, y) w = w // 10 else: print(y) # 少计算一次
长度处理
从左到右处理数据,遇到 0 则长度减 1, 遇到第一个非 0 数字才开始打印并不减 1
# coding: utf-8 y = int('00321') w = 10000 length = 5 #假设长度为 5 flag = False # 开关量,打标记,假定没找到第一个非 0 for i in range(5): #while w: x = y // w if not flag: if x: # 找到第一个非 0 数字,从此才开始打印 flag = True else: length -= 1 if flag: print(x) #print(x, y) y = y % w w = w // 10 #print(y) print("The length of the number is ", length)
# coding: utf-8 #num = int(input("Plz input num: ")) num = int('00300') countnum = 0 str1 = "" while True: #print(num%10) str1 = "{} {}".format ((num % 10),str1) num = num//10 countnum +=1 if num == 0: break print("Your countnum:", countnum, "number:", str1) #: Your countnum: 5 number: 5 4 3 2 1
学会拆解,各个击破。
- 给定一个不超过5位的正整数,判断该数是几位数,依次从万位打印到个位的数字
输入n个数,求每次输入后的算数平均数
#coding: utf-8 n = 0 s = 0 while True: x = int(input('>>>')) if x == '': break s += x n +=1 print('avg =', s /n)
打印一个边长为n的正方形
n = 5 print('*'*n) for i in range(n- 2): print('*'+' '*(n-2)+"*") print('*'*n)
或者
#coding: utf-8 char = '*' n = 4 for i in range(n): if i == 0 or i == n-1: # 首尾是特例 print(char * n) else: print(char + ' '*(n-2) + char)
#coding: utf-8 char = '*' n = 4 for i in range(n): if i % (n-1) == 0: # 首尾是特例 print(char * n) else: print(char + ' ' * (n -2 ) + char )
求100内所有奇数的和(2500)
sum = 0 for i in range(1, 100): if i % 2 != 0: sum +=i print(sum)
s = 0 for i in range(100): if i & 1 : s += i print(s)
上面都要计算,99 个数值计算了 99 次,还要做加法,会浪费时间。用如下方法:
sum = 0 for i in range(1, 100, 2): sum += i else: print(sum)
sum 求和函数,对可迭代对象求和
print(sum(range(1,100,2)))
成绩问题
判断学生成绩,成绩等级A至E。其中,90分以上为A,80~89分为'B',70~79分为'C,60~69分为'D',60分以下为'E'
score = '0' score = int(score) if score < 0: print('error input') exit() if score >= 90: print('A') elif score >= 80 print('B') elif score >= 70 print('C') elif score >= 60 print('D') else: print('E')
求1到5的阶乘之和
方法1:
# coding: utf-8 #n = int(input("请输入阶乘之和的数:")) n = 5 multiply = 1 sum = 0 for i in range(1, n+1): for j in range(1, i+1): multiply *= j sum +=multiply multiply = 1 #print(str(n) + "阶乘之和为:", sum) print(str(n) , sum)
方法2: 一层循环,找规律 前一次阶乘的值后一个阶段乘等于后一个阶乘的值
nums = 1 x = 0 for i in range(1, 6): nums *= i x += nums print(x)
给一个数,判断它是否是素数(质数)
质数:一个大于1的自然数只能被1和它自身整除
n=int(input("输入数字>>>: ")) for i in range(2, n): if n % i == 0: #被整除说明是合数 print(n , " is not prime") break else: print(n," is prime")
练习2
- 打印九九乘法表
- 用户登录验证
- 用户依次输入用户名和密码(假设写死的),然后提交验证
- 用户不存在、密码错误,都显示用户名或密码错误提示
- 错误3次,则退出程序
- 验证成功则显示登录信息
- 打印下图菱形
* *** ***** ******* ***** *** *
- 打印闪电
* ** *** ******* *** ** *
- 打印100以内斐波那契数列
- 求斐波那契数第101项
10万以内的素数
质数定义为在大于1的自然数中,除了1和它本身以外不再有其他因数
打印九九乘法表
思路: 九九方阵
for i in range(1, 10): for j in range(1, 10): print(i, j)
print() 每打一行就有一个换行符。想办法凑一行
#coding: utf-8 for i in range(1, 10): line = '' # 重置,重头开始 for j in range(1,10): #凑一行 line += str(i) + '*' + str(j) + '=' + str(i * j) + ' ' print(line) #: 1*1=1 1*2=2 1*3=3 1*4=4 1*5=5 1*6=6 1*7=7 1*8=8 1*9=9 #: 2*1=2 2*2=4 2*3=6 2*4=8 2*5=10 2*6=12 2*7=14 2*8=16 2*9=18 #: 3*1=3 3*2=6 3*3=9 3*4=12 3*5=15 3*6=18 3*7=21 3*8=24 3*9=27 #: 4*1=4 4*2=8 4*3=12 4*4=16 4*5=20 4*6=24 4*7=28 4*8=32 4*9=36 #: 5*1=5 5*2=10 5*3=15 5*4=20 5*5=25 5*6=30 5*7=35 5*8=40 5*9=45 #: 6*1=6 6*2=12 6*3=18 6*4=24 6*5=30 6*6=36 6*7=42 6*8=48 6*9=54 #: 7*1=7 7*2=14 7*3=21 7*4=28 7*5=35 7*6=42 7*7=49 7*8=56 7*9=63 #: 8*1=8 8*2=16 8*3=24 8*4=32 8*5=40 8*6=48 8*7=56 8*8=64 8*9=72 #: 9*1=9 9*2=18 9*3=27 9*4=36 9*5=45 9*6=54 9*7=63 9*8=72 9*9=81
读顺点,i 和 j 互换位置
#coding: utf-8 for i in range(1, 10): line = '' # 重置,重头开始 for j in range(1,10): #凑一行 line += str(j) + '*' + str(i) + '=' + str(i * j) + ' ' print(line)
要的对角线以下的,找规律, 对角线以下 j < i,对角线上 j = i
同时可以用 format 格式化
#coding: utf-8 for i in range(1, 10): line = '' # 重置,重头开始 for j in range(1,10): #凑一行 if j <= i: #line += str(j) + '*' + str(i) + '=' + str(i * j) + ' ' line += "{}*{}={} ".format(j,i,i*j) # format 格式化 print(line) #: 1*1=1 #: 1*2=2 2*2=4 #: 1*3=3 2*3=6 3*3=9 #: 1*4=4 2*4=8 3*4=12 4*4=16 #: 1*5=5 2*5=10 3*5=15 4*5=20 5*5=25 #: 1*6=6 2*6=12 3*6=18 4*6=24 5*6=30 6*6=36 #: 1*7=7 2*7=14 3*7=21 4*7=28 5*7=35 6*7=42 7*7=49 #: 1*8=8 2*8=16 3*8=24 4*8=32 5*8=40 6*8=48 7*8=56 8*8=64 #: 1*9=9 2*9=18 3*9=27 4*9=36 5*9=45 6*9=54 7*9=63 8*9=72 9*9=81
改进1: 找规律 。 j <= i, i 的取值范围是 [1,9],所以第 2 层循环 j 的取值范围 [1,i] 之间
#coding: utf-8 for i in range(1, 10): line = '' for j in range(1, i+1): #凑一行, j [1,i) line += "{}*{}={} ".format(j,i,i*j) print(line)
改进1:对齐有问题 改进 tab 对齐
#coding: utf-8 for i in range(1, 10): line = '' for j in range(1, i+1): line += "{}*{}={}\t".format(j,i,i*j) print(line) #: 1*1=1 #: 1*2=2 2*2=4 #: 1*3=3 2*3=6 3*3=9 #: 1*4=4 2*4=8 3*4=12 4*4=16 #: 1*5=5 2*5=10 3*5=15 4*5=20 5*5=25 #: 1*6=6 2*6=12 3*6=18 4*6=24 5*6=30 6*6=36 #: 1*7=7 2*7=14 3*7=21 4*7=28 5*7=35 6*7=42 7*7=49 #: 1*8=8 2*8=16 3*8=24 4*8=32 5*8=40 6*8=48 7*8=56 8*8=64 #: 1*9=9 2*9=18 3*9=27 4*9=36 5*9=45 6*9=54 7*9=63 8*9=72 9*9=81
j 小于 10,2个空格
#coding: utf-8 for i in range(1, 10): line = '' for j in range(1, i+1): line += "{}*{}={}{}".format( j,i,i*j, ' ' if i*j < 10 else ' ' ) print(line)
方法2:format处理 {n:<2} 冒号是分割符号, < 左对齐,后面的 n 表示变量对应的序号。
for i in range(1, 10): line = '' for j in range(1, i+1): line += '{}*{}={:<{}}'.format( j,i,i*j, 2 if j == i else 3 ) print(line)
{2:<2} 冒号是分割符号, < 左对齐,后面的 2 表示 i*j
for i in range(1, 10): line = '' for j in range(1, i+1): line += '{0}*{1}={2:<2} '.format(j,i,i*j) print(line)
改进2: print 换行优化
#coding: utf-8 for i in range(1, 10): for j in range(1, i+1): line = '{}*{}={}'.format( j,i,i*j ) print(line, end=' ') # 往后打印 print() # 默认行为 end='\n'
精简
#coding: utf-8 for i in range(1, 10): for j in range(1, i+1): print('{}*{}={}'.format(j,i,i*j), end=' ') # 往后打印 print()
#coding: utf-8 for i in range(1, 10): for j in range(1, i+1): print('{}*{}={}'.format(j,i,i*j), end=' ' if j != i else '\n') # 往后打印
对齐
#coding: utf-8 for i in range(1, 10): for j in range(1, i+1): print('{}*{}={:<{}}'.format(j,i,i*j, 2 if j==1 else 3), end='' if j != i else '\n') # 往后打印
倒着打
九九方阵
for i in range (1,10): for j in range(1, 10): print('{}*{}={}'.format(j,i,i*j), end=' ') print()
对角线以上是我们想要的。i <= j 时打印
for i in range (1,10): for j in range(1, 10): if i <= j: print('{}*{}={}'.format(j,i,i*j), end=' ') print() #: 1*1=1 2*1=2 3*1=3 4*1=4 5*1=5 6*1=6 7*1=7 8*1=8 9*1=9 #: 2*2=4 3*2=6 4*2=8 5*2=10 6*2=12 7*2=14 8*2=16 9*2=18 #: 3*3=9 4*3=12 5*3=15 6*3=18 7*3=21 8*3=24 9*3=27 #: 4*4=16 5*4=20 6*4=24 7*4=28 8*4=32 9*4=36 #: 5*5=25 6*5=30 7*5=35 8*5=40 9*5=45 #: 6*6=36 7*6=42 8*6=48 9*6=54 #: 7*7=49 8*7=56 9*7=63 #: 8*8=64 9*8=72 #: 9*9=81
对齐方式不一样,想办法向右挤
1*1=1 2*1=2 3*1=3 4*1=4 5*1=5 6*1=6 7*1=7 8*1=8 9*1=9 2*2=4 3*2=6 4*2=8 5*2=10 6*2=12 7*2=14 8*2=16 9*2=18 3*3=9 4*3=12 5*3=15 6*3=18 7*3=21 8*3=24 9*3=27 4*4=16 5*4=20 6*4=24 7*4=28 8*4=32 9*4=36 5*5=25 6*5=30 7*5=35 8*5=40 9*5=45 6*6=36 7*6=42 8*6=48 9*6=54 7*7=49 8*7=56 9*7=63 8*8=64 9*8=72 9*9=81
前面凑齐空格
for i in range (1,10): print('\t'*(i-1), end='') for j in range(1, 10): if i <= j: print('{}*{}={}\t'.format(j,i,i*j), end='') print()
for i in range(1, 10): print(" "*10*(i-1), end=" ") for j in range(i, 10): print('{0}*{1}={2:<2}'.format(i,j,i*j), end=" ") print()
for i in range (1, 10): for j in range(1,10): if j < i: print(" "*9, end=" ") else: print("{0}*{1} = {2:<2}".format(i, j, i*j), end=" ") print()
向右对齐
for i in range(1,10): line = '' for j in range(1,10): if i <= j: product = i * j line += '{}*{}={}{}'.format(i, j, product, ' ' if product < 10 else ' ') print('{:>66}'.format(line))
for i in range(1,10): line = '' for j in range(i,10): product = i * j line += '{}*{}={}{}'.format(i, j, product, ' ' if product < 10 else ' ') print('{:>66}'.format(line))
for i in range(1,10): line = '' for j in range(i,10): line += '{}*{}={:<{}}'.format(i, j, i*j, 2 if j<4 else 3) print('{:>60}'.format(line))
九九乘法表可以让我们把三元表达练习的比较熟练。2分钟内必须搞定。
用户登录验证
- 用户依次输入用户名和密码(假设写死的),然后提交验证
- 用户不存在、密码错误,都显示用户名或密码错误提示
- 错误3次,则退出程序
- 验证成功则显示登录信息
#coding: utf-8 username = 'tom' password = 'tom' #不可逆算法,单向加密 success = False for i in range(3): u = input('Plz input your username =') p = input('Plz input your password =') if username == u and password == p: success = True pass else: print('Invalid username or password') if success: print('Login successfully') pass # 显示登录页 else: print('Failed') pass # 退出程序
打印菱形
假设 7 个星号的菱形
*
***
*****
*******
*****
***
*
找规律
思路1:
行号 星号 前置空格数 后置空格数 总空格数
1(-3) 1 3 3 6
2(-2) 3 2 2 4
3(-1) 5 1 1 2
4(0) 7 0 0 0
5(1) 5 1 1 2
6(2) 3 2 2 4
7(3) 1 3 3 6
打到中心对称。 每一行中,个数和总空格数相加为7,前后空格321 0 124的规律
范例:
for i in range(-3, 4): if i < 0: prespace = -i else: prespace = i print(' '*prespace + '*'*(7-prespace*2))
for i in range(-3, 4): prespace = abs(i) print(' '*prespace + '*'*(7-prespace*2))
format 居中对齐
n = 7 leadingchar = ' ' char = '*' for i in range(-3, 4): print("{:^7}".format((7-2 * abs(i)) * char))
将变化的全部提出来
n = 7 e = n // 2 # 3 leadingchar = '=' char = '*' for i in range(-e, n-e): print("{:=^{}}".format((n - 2 * abs(i)) * char, n)) #: ====*==== #: ===***=== #: ==*****== #: =*******= #: ********* #: =*******= #: ==*****== #: ===***=== #: ====*====
打印对顶三角形
行 i 星号 前空 后空 总空 1 3 7 0 0 0 2 2 5 1 1 2 3 1 3 2 2 4 4 0 1 3 3 6 5 1 3 2 2 4 6 2 5 1 1 2 7 3 7 0 0 0
方法1: 前置空格
n = 7 e = n // 2 leadinchar = '#' char = '*' for i in range(-e, e+1): spaces = e - abs(i) chars = 2*abs(i)+1 print('{}'.format(leadinchar * spaces + char * chars)) #: ******* #: #***** #: ##*** #: ###* #: ##*** #: #***** #: *******
方法2: 居中对齐
n = 7 e = n // 2 leadinchar = '#' char = '*' for i in range(-e, e+1): chars = 2*abs(i)+1 print('{:^{}}'.format(char * chars,n))
打印闪电
n = 7 e = n // 2 for i in range(-e, e+1): if i == 0 : print( '*' * n) print(' ' * (-i) + '*' * (e+1+i)) if i < 0 else print(' ' * e + '*' * (e+1-i)) #: * #: ** #: *** #: ******* #: **** #: *** #: ** #: *
打印 100 以内斐波那契数列
斐波那契数列由 1和 1 开始,之后的斐波那契数列系数就由之前的两数相加
i = 1 j = 1 while i < 100: print(i) i, j = j, j+i
求斐波那契数第101项
i = 1 j = 1 count = 0 while True: i, j = j, j+i count +=1 if count == 100: break print(i)
10万以内的素数
质数定义为在大于1的自然数中,除了1和它本身以外不再有其他因数 %%timeit #ipython的计算平均时间
print(1) print(2) print(3) for i in range(3, 10000, 2): m = i**0.5 for j in range(3, i, 2): if i % j == 0: break if j> m: print(i) break
count = 0 for x in range(2, 100): for i in range (2, x): if x % i == 0: #print('not a prime number', i) break else: #print(x) count += 1 print(count)
找中点
9 = 3*3 , 16 = 4*4,对于 9 到 16 中间的数字的中间点可以认为是开方点, 3 到 4 之间。对于除法来说开方点前面找到一个数,后面的数就不用测试了
#coding: utf-8 count = 0 for x in range(2, 100): for i in range (2, int(x**0.5)+1): # [2, "中点"],range 只能包含整数,int向下取整,一定会漏掉一个所以 +1 if x % i == 0: #print('not a prime number', i) break else: #print(x) count += 1 print(count)
效率: datetime 包
#coding: utf-8 import datetime start = datetime.datetime.now() count = 0 for x in range(2, 100000): for i in range (2, int(x**0.5)+1): if x % i == 0: #print('not a prime number', i) break else: #print(x) count += 1 delta = (datetime.datetime.now() - start).total_seconds() # 它不是精确的 CPU,它是墙上的时间 print(count, delta) #: 9592 0.351471
偶数问题,除了 2 外,所有的偶数都是和数
#coding: utf-8 import datetime start = datetime.datetime.now() count = 1 # 2 偶数,同时是质数 #算奇数 for x in range(3, 100000, 2): # 只测试奇数,减少一半计算量 for i in range (3, int(x**0.5)+1, 2): if x % i == 0: #print('not a prime number', i) break else: #print(x) count += 1 delta = (datetime.datetime.now() - start).total_seconds() # 它不是精确的 CPU,它是墙上的时间 print(count, delta) #: 9592 0.180551
大于 10 还能被 5 取模就不用算了
#coding: utf-8 import datetime start = datetime.datetime.now() count = 1 # 2 偶数,同时是质数 #算奇数 for x in range(3, 100000, 2): # 只测试奇数,减少一半计算量 if x > 10 and x % 5 == 0: continue for i in range (3, int(x**0.5)+1, 2): if x % i == 0: #print('not a prime number', i) break else: #print(x) count += 1 delta = (datetime.datetime.now() - start).total_seconds() # 它不是精确的 CPU,它是墙上的时间 print(count, delta) #: 9592 0.180551
python 数据结构-线性数据结构
内建常用数据类型
- 数值型
- int、float、complex、bool
- 序列sequence(线性结构有顺序)
- 字符串str、字节序列bytes、bytearray
- 列表list、元组tuple
- 键值对(非线性结构无顺序)
- 集合set、字典dict
线性数据结构
线性表
- 线性表(简称表),是一种抽象的数学概念,是一组元素的序列的抽象,它由有穷个元素组成(0个或任意个)。线性表包含顺序表、链接表。
- 顺序表:使用一大块
连续的内存顺序存储表中的元素,这样实现的表称为顺序表,或称连续表在顺序表中,元素的关系使用顺序表的存储顺序自然地表示
增: - 头部增加insert,引起后面所有元素位置挪动 - 中间插入insert,引起其后所有元素的挪动 - 尾部追加,推荐使用这种方式 删: - 头部删,引起其后元素位置的挪动 - 中间删,引起其后元素位置的挪动 - 尾部删,推荐使用这种 改: - 通过index直接定位元素,覆盖即可,效率很高 查: - 通过index查找,效率很高
链接表:在存储空间中将分散存储的元素链接起来,这种实现称为链接表,简称链表
增: - 头部增加insert, 把头部标记移动到增加的元素上,新元素与跟原来的头部元素拉手。代价很低 - 中间插入insert,断开手,拉新手。效率相对于顺序表稍微差一点点 - 尾部追加,新增的元素跟原来的尾部元素拉手,尾部标记移动到新的尾部元素上面 删: - 头部删,移动头部标记就行了,代价低 - 中间删,被删除元素两边的元素重新拉手,效率高。但是有个找目标元素的过程,相对于顺序表慢一点 - 尾部删,移动尾部标记就行了,效率高 改: - 通过index直接定位元素,覆盖即可,效率很高 查: - 通过index查找,效率很
列表如同地铁站排好的队伍,有序,可以插队、离队,可以索引。
链表如同操场上 手拉手 的小朋友,有序但空间排列随意。或者可以想象成一串带线的珠子,随意盘放在桌上。也可以离队、插队,也可以索引。
链表是线性结构,内存分布上看着不连续,但是内部有指向,前一个元素指向下一个元素,所以它是有明确的顺序。
对比体会一下,这两种数据结构的增删改查效率如何。
接下来讲栈、队列时起码知道它在干什么。在内存中的数据结构组织方式,如果组织错了,那么算法怎么写都不会很优秀。 所有的数据结构几乎都可以用生活中的例子来类比。
列表list
- 一个排列整齐的队伍,Python采用顺序表实现,源码 c 语言数组实现的。其它语言中更多的是链接表。
- 列表内的个体称作元素,由若干元素组成列表
- 元素可以是任意对象(数字、字符串、对象、列表等)
- 列表内元素有顺序,可以使用索引,从 0 开始
- 线性的数据结构
- 使用
[]表示 - 列表是
可变的
列表是非常重要的数据结构,对其内存结构和操作方法必须烂熟于心。
初始化
- list() -> new empty list
- list(iterable) -> new list initialized from iterable's items
- []
- 列表不能一开始就定义大小
范例:
ls1 = [] # 空列表 ls2 = list() #空列表 ls3 = [2, 'ab', [3, 'abc'], (5, 30, 50)] # 列表是一个容器,元素可以是其它类型 ls4 = list(range(5)) # 非常常用的构造方式,将一个可迭代对象转换为一个新的列表 ls5 = list([1, 'a', 100]) # 从[1, 'a', 100] 中遍历所有元素,组建一个新的列表
list A built-in Python sequence. Despite its name it is more akin to an array in other languages than to a linked list since access to elements is O(1). # list 是 sequence class list([iterable]) Lists may be constructed in several ways: •Using a pair of square brackets to denote the empty list: [] •Using square brackets, separating items with commas: [a], [a, b, c] •Using a list comprehension: [x for x in iterable] #解析式 •Using the type constructor: list() or list(iterable) # list 列表 或者 list可迭代对象
索引
- 索引,也叫下标
- 正索引:从左至右,从0开始,为列表中每一个元素编号
- 如果列表有元素,索引范围
[0, 长度-1]
- 如果列表有元素,索引范围
- 负索引:从右至左,从-1开始
- 如果列表有元素,索引范围
[-长度, -1]
- 如果列表有元素,索引范围
- 正、负索引不可以超界,否则引发异常
IndexError - 为了理解方便,可以认为列表是从左至右排列的,左边是头部,右边是尾部,左边是下界,右边是上界
- 列表通过索引访问,list[index] ,index就是索引,使用中括号访问
使用索引定位访问元素的时间复杂度为 O(1),这是最快的方式,是列表最好的使用方式。
范例:
ls3 = [2, 'ab', [3, 'abc'], (5, 30, 50)] print( ls3[0], ls3[2], ls3[-4] ) #: 2 [3, 'abc'] 2
查询
- index(value,[start,[stop]])
- 通过值value,从指定区间查找列表内的元素是否匹配
- 匹配第一个就立即返回索引
- 匹配不到,抛出异常ValueError
- count(value)
- 返回列表中匹配value的次数
- 时间复杂度
- index和count方法都是O(n),遍历元素
- 随着列表数据规模的增大,而效率下降。
性能极差,能不用就不用
- 如何返回列表元素的个数?如何遍历?如何设计高效?
- len() O(1)因为 [1,2,3,4] 列表包装的 C 语言的数组,记录了一个数据当前列表长度
范例:帮助
#python中帮助 >>> help(list.index) Help on method_descriptor: index(self, value, start=0, stop=9223372036854775807, /) unbound builtins.list method Return first index of value. Raises ValueError if the value is not present. #jupyter中帮助 list.index? Signature: list.index(self, value, start=0, stop=9223372036854775807, /) Docstring: Return first index of value. Raises ValueError if the value is not present. Type: method_descriptor
范例:
# -*- coding: utf-8 -*- ls1 = [1, 2, 3,2, 3, 4, 5, 6, 7, 8, 9] print(ls1.index(2)) # Return first index of value print(ls1.index(2,2), ls1[3]) #找到 2 出现的索引中从第 2 个索引地址开始找,返回索引 print(ls1.index(2,2,7)) #找到 2 出现的索引中从第 2 个索引到 第 7 个索引地址开始找,返回索引 #: 1 #: 3 3 #: 3 print(ls1.count(2)) #2 值出现的次数 print(ls1[2]) # 无规模 n 无关,不会随着规模 n 的增加而影响效率 print(len(ls1)) # len效率如何? O(1)。因为 [1,2,3,4] 列表包装的 C 语言的数组,记录了一个数据当前列表长度 #: 2 #: 3 #: 11
修改
- 索引定位元素,然后修改。注意索引不能超界
ls1 = [1,2,3,4] ls1[2] = 200
增加单个元素
- append(object) -> None
- 列表尾部追加元素,返回None
- 返回None就意味着没有新的列表产生,就地修改
- 定位时间复杂度是 O(1)
- insert(index, object) -> None
- 在指定的索引index处插入元素object
- 返回None就意味着没有新的列表产生,就地修改
- 定位时间复杂度是O(1)
- 索引能超上下界吗?
- 超越上界,尾部追加
- 超越下界,头部追加
范例:
# -*- coding: utf-8 -*- #append ls1 = [] ls1.append(1) # append 内部尾部追加,没有返回值。没有返回值往往表示它自己被改变了,就地修改 print(ls1) # append 效率如何?定位尾部是O(1),不需要扩容 ls1[length] = value #虽然说列表是容器,但是有容量, python 中列表可以扩大,自动扩大, #会先给初始大小,不够了扩容,扩增4倍,达到一定限度2倍扩。 #扩容耗时,如果内存连续空间不够,牵扯到了垃圾回收,效率就低了。 #insert ls2 = [10, 20, 30, 50, 20, 40, 60] ls2.insert(-1, 70) # 不是 append,在当前索引前面插入 print(ls2) ls2.insert(10000, 'abc') # None 没有返回值,超界 右边界,相当于 append print(ls2) ls2.insert(0, 80) # 插入到队首 print(ls2) ls2.insert(-1000, 100) # 左边界超界,相当于插入到 队首 print(ls2) #: [10, 20, 30, 50, 20, 40, 70, 60] #: [10, 20, 30, 50, 20, 40, 70, 60, 'abc'] #: [80, 10, 20, 30, 50, 20, 40, 70, 60, 'abc'] #: [100, 80, 10, 20, 30, 50, 20, 40, 70, 60, 'abc'] # insert 方法效率如何? # 超界的情况不要考虑 #insert index 说明定位高效 #插入点之后所有数据向后挪动,效率极低。规模越大,挪动数据越多 #最差情况,插入到队首;最好情况,队尾追加
编程玩的就是内存。算法+数据结构就能写出高效率的代码
增加多个元素
- extend(iteratable) -> None
- 将可迭代对象的元素追加进来,返回None
- 就地修改,本列表自身扩展
- + -> list
- 连接操作,将两个列表连接起来,产生
新的列表,原列表不变 - 本质上调用的是魔术方法
__add__()方法
- 连接操作,将两个列表连接起来,产生
- * -> list
- 重复操作,将本列表元素重复n次,返回新的列表
范例:
#coding: utf-8 # extend ls2 = [10, 20, 30, 50, 20, 40, 60] ls2.extend(range(110,150,10)) # 就地尾部后扩展 ls2.extend([1,2]) print(ls2) #: [10, 20, 30, 50, 20, 40, 60, 110, 120, 130, 140, 1, 2] #效率高吗 还行 ls2.extend([1,2]) ==> for x in [1,2]: ls2.append(x) # + l1 = [1,2] l2 = [11, 22] x = l1 + l2 # 2 个列表组合连接在一起,返回一个全新的列表 #l1 + 3 报错,强类型 print(x) #: [1, 2, 11, 22] #效率,在规模巨大时,要不要创建一个全新的对象也是你要考虑的 # * y = [9] * 3 # 将给的列表的元素重复 3 次,生成全新的列表 print(y) #: [9, 9, 9]
ls1 = [1] * 5 ls2 = [None] * 6 ls3 = [1,2] * 3 ls4 = [[1]] * 3 print(ls4) #: [[1], [1], [1]]
这个重复操作看似好用,如果原理掌握不好,但非常危险
x = [1] * 3 x[0] = 100 print(x) # 结果是什么
#coding: utf-8 y = [[1]] * 3 print(y) # 结果是什么 #: [[1], [1], [1]] y[0] = 100 print(y) # 结果是什么 #: [100, [1], [1]] y[1][0] = 200 #python中一切对象都是引用类型 print(y) # 结果是什么 #: [100, [200], [200]]
在Python中一切皆对象,而对象都是 引用类型 ,可以理解为一个 地址指针 指向这个对象。
但是,字面常量字符串、数值等表现却不像引用类型,暂时可以称为简单类型。
而列表、元组、字典,包括以后学习的类和实例都可以认为是引用类型。
你可以认为简单类型直接存在列表中,而引入类型只是把引用地址存在了列表中。
删除
- remove(value) -> None
- 从左至右查找第一个匹配value的值,找到就移除该元素,并返回none,否则valueerror
- 就地修改,其后所有元素向前移动
- 效率? 低
- pop([index]) -> item
- 不指定索引index,就从列表尾部弹出一个元素
- 指定索引index,就从索引处弹出一个元素,索引超界抛出IndexError错误
- 效率?指定索引的的时间复杂度?不指定索引呢? 从中间移除效率低,从尾部弹出效率可以
- clear() -> None
- 清除列表所有元素,剩下一个空列表
范例:
# -*- coding: utf-8 -*- # remove ls1 = [10, 20, 30, 50, 20, 40, 60] ls1.remove(10) #效率高吗? 遍历, O(n),移除掉中间的元素,其后所有元素向前挪动,效率极差 print(ls1) # 队首移除,效率最低了 # pop x =ls1.pop(0) # index = 0 移除,效率高吗? 效率一样低下,就是用索引找得快,移除元素后,其余元素挪动,效率低 # 以后,遇到了pop 这样的名字,都可以叫做弹出来,弹出返回值 print(x) ls1.pop() # pop 尾部移除最后一个元素,尾部怎么找, lenght起点。效率可以 # clear ls1.clear() # 效率高,标记不用了,lenght 标记为 0。 内存清除操作谨慎,想好再作。 print(ls1)
反转
- reverse() -> None
- 将列表元素反转,返回None
- 就地修改
这个方法最好不用,可以倒着读取,都不要反转。
范例:
# -*- coding: utf-8 -*- # reverse ls1 = [10, 20, 30, 50, 20, 40, 60] ls1.reverse() # 最没用的方法之一。因为列表如果想倒过来读取,使用负索引倒着读就行 print(ls1) #: [60, 40, 20, 50, 30, 20, 10] for i in range(-1, -len(ls1)-1, -1): print(ls1[i])
排序(重要)
- sort(key=None, reverse=False) -> None
- 对列表元素进行排序,就地修改,默认升序
- reverse为True,反转,降序
- key一个函数,指定key如何排序,lst.sort(key=function)
如果排序是必须的,那么排序。排序效率高吗?
范例:
# -*- coding: utf-8 -*- # sort 重要 ls1 = [10, 20, 30, 50, 20, 40, 60] ls1.sort() # None, 就地修改,默认升序排序 print(ls1) ls1.sort(reverse=True) # 降序 print(ls1) #: [10, 20, 20, 30, 40, 50, 60] #: [60, 50, 40, 30, 20, 20, 10] #下面的涉及到高阶函数,暂先了解 ls2 = [1,2,3,'a',11] ls2.sort(key=str) # ? if str(元素0) < str(元素1) str 转换后的值用来进行比较(ascii码比较),决定先后次序,但不影响输出 print(ls2) #: [1, 11, 2, 3, 'a'] ls2 = [1,2,3,'12',11] ls2.sort(key=int) # if int(xx) < int('12') print(ls2) #: [1, 2, 3, 11, '12'] ls2 = [1,2,3,'12',11] ls2.sort(key=str) # if str(xx) < str(yy) print(ls2) #: [1, 11, '12', 2, 3]
in成员操作
在不在其中,返回布尔型
'a' in ['a', 'b', 'c'] [3,4] in [1, 2, 3, [3,4]] for x in [1,2,3,4]: pass
范例:
#coding: utf-8 ls1 = [1,2,3,4,5,6] print(-1 in ls1) #效率不高,遍历。找不到不抛异常,性能低下,规模大的业务少用 print(1 in ls1) if not -1 in ls1: print('-1 not in ls1') #print(1s1.index(-1)) #效率不高,遍历。找不到抛异常 #: False #: True #: -1 not in ls1
列表复制
范例:
#coding: utf-8 # 复制 x = [1,2,3] y = x print(x,y) print(x == y) # y 就是 x ,内容相同,可以不是同一个对象。指向相同的内存地址 print( x is y ) # is 比较在内存中是不是同一个地址,本质问是不量同一个对象 print(id(x), id(y)) #id() 显示内存地址 #: [1, 2, 3] [1, 2, 3] #: True #: True #: 2648564816128 2648564816128 # 复制本质? x = [1,2,3] y = x.copy() # 复制方法,复制一个全新的对象,内容相同 print(x,id(x)) print(x == y) print(x is y, id(x),id(y)) #: [1, 2, 3] 2321011307904 #: True #: False 2321011307904 2321013245440
范例:
#coding: utf-8 a = list(range(4)) b = list(range(4)) print(a == b) c = a #指向同一个内存地址 c[2] = 10 print(a) print(a == b) # 还相等吗? print(a == c) # 相等吗? #: True #: [0, 1, 10, 3] #: False #: True
下面的程序a和b相等吗?
#coding: utf-8 a = list(range(4)) b = a.copy() #复制方法,复制一个全新的对象,内容相同 print(a == b) #True 内容相等 a[2] = 10 print(a == b) #False # a = [1, [2, 3, 4], 5] b = a.copy() print(a == b) a[2] = 10 print(a == b,a,b) #: False [1, [2, 3, 4], 10] [1, [2, 3, 4], 5] a[2] = b[2] print(a == b) a[1][1] = 100 print(a == b,a,b) # 还相等吗? : True [1, [2, 100, 4], 5] [1, [2, 100, 4], 5]
列表的内存模型和深浅拷贝
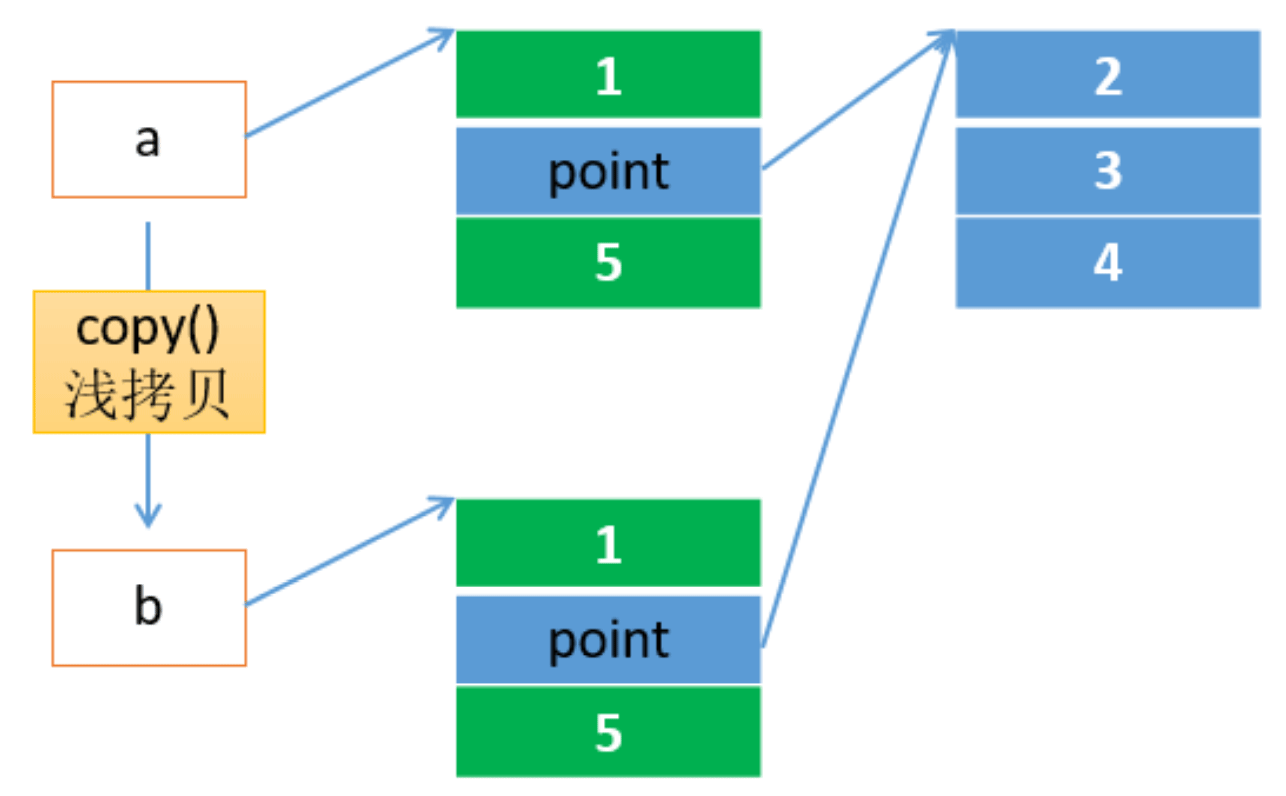
- shadow copy
- 影子拷贝,也叫浅拷贝。遇到引用类型数据,仅仅复制一个引用而已
- deep copy
- 深拷贝,往往会递归复制一定深度
一般情况下,大多数语言提供的默认复制行为都是浅拷贝。
范例: copy.deepcopy(x) 深拷贝
#coding: utf-8 import copy a = [1, [2, 3], 4] b = copy.deepcopy(a) print(a == b) print(a is b, id(a), id(b)) a[1][1] = 100 print(a == b, a, b) # 还相等吗? #: True #: False 1653219121408 1653221736512 #: False [1, [2, 100], 4] [1, [2, 3], 4]
范例: 证明 == 内容比较
a = [1,2] b = [1,2] print(a == b, a is b, id(a), id(b)) #: True False 2329511778560 2329511776640 c = [1, a, 5] d = [1, b, 5] print(c is d, c == d) # == 会展开引用内存地址的内容,比较 #: False True
Python内建数据类型,内部都实现了 == ,它的意思是内容比较
常见线性结构比较
- 列表 List
- 链表 Linked List
- 栈 Stack
- 队列 Queue
线性表
1、顺序表 List
CRUD 效率问题
增加
- 增加元素方法有哪些?效率如何?
append 高。
单个尾部追加,定位尾部快,在尾部增加元素就行了。一般效率很高。如果 有连接空间扩容效率也是很快的,只是标记一下这块内存空间给你了,所以 不会有太大性能问题。只是在扩容时没有空间了会引起垃圾回收,这个时候 效率就低下了。但是对我们来说垃圾回收是个系统性问题,不是简简单单一个方法能解决的,这是整个python 和 java一样都会有垃圾回收。
- insert 不高。中间插入会引起数据挪动,效率低。
- extend 扩展,成批尾部扩展。效率高也是相对而言的。大规模成批追加效率不高
- + 拼接
- * 复制原理,浅拷贝
删除
- remove 按照value来的,遍历,中间移走,后面数据要挪动,最差情况队首走了。效率极差
- pop 弹出来,使用索引只能保证定位快,移除元素后挪动效率不高。一般用pop()尾部移除,这个可以用。
- clear 清除,效率高只是打个标记,但是个危险动作
改:
- list[index] = value 索引定位,效率高
查
- index count 都要遍布,效率不高,都不用
- len 0(1)
遍历:
- 效率高吗? O(n) 效率不高,元素越多遍历时间越长。能少遍历就少遍历。
反转
- reverse 最没效率,不要用
排序:
- sort 后面会加深讲解
链表 Linked List
CRUD 效率问题
增加元素效率高吗?
定位数据是遍历,才能找到索引 index,O(n);找到后,插入数据,就是“手拉手”断开,重新拉新元素。插入本身高效不会引起数据移动。定位消耗时间,跟列表比较,如果列表规模大,列表增这种方式不好,建议使用链接表。
链表头尾操作效率更高,中间操作遍历找到,效率低些。
删除元素
头尾移除效率高,所有数据不需要移动,效率高;中间删除,要遍历找到被删除元素,断开拉手,被删两边元素重新接手就行。效率高。
元素规模较大,增删频繁,请尽量用链接表。
如果是首尾操作,追加,追问删除,顺序表、链接表都行。
改
效率高吗?遍历,才能找到 index,O(n) linkedlist[index] = value
查
查一个值效率高吗? 遍历,效率不高,O(n)
使用索引定位,也不高,遍历
遍历
链表和列表遍历哪个效率高?
O(n) 一样。顺序表来说,就是点完一个再下一个。随着规模增加而增加。
栈 Stack
后进先出LIFO(Last in First Out),像罗盘子一样。
队列 Queue
- 先进先出队列FIFO(First In First Out),用列表还是链表? 用链表
- 用列表队首离开,后补,挪动
- 用链表,队首,手断开,不挪动,性能很高,队列不进行内部操作。
- 后进先出队列LIFO(Last In First Out),用列表还是链表?都行。看到更多的是链表。
队列更像是有栏杆的,不能插队,只能首尾操作。
练习
- 求 100 内的素数
- 从 2 开始到自身的数 -1 中找到一个能整除的 => 从 2 开始到自身开平方的数中找到一个能整除的
- 一个合数一定可以分解成几个素数的乘积,也就是说,一个数如果能被一个素数整除就是合数
- 计算杨辉三角前6行
- 第 n 行有 n 项,n 是正整数
- 第 n 行数字之和为 2**(n-1)
- 打印出杨辉三角的每一行数字即可
求 100 内的素数
质数定义为在大于1的自然数中,除了1和它本身以外不再有其他因数
- 从 2 开始到自身的数 -1 中找到一个能整除的 => 从 2 开始到自身开平方的数中找到一个能整除的
- 一个合数一定可以分解成几个素数的乘积,也就是说,一个数如果能被一个素数整除就是合数
回顾:
# coding: utf-8 #算法1 #求 100 内的素数 #1. >2 之后都是奇数 #2. 测试奇数是不是质数,就没有必要拿偶数来整除取模 #3. 找到开方点 import datetime start = datetime.datetime.now() n = 100000 count = 1 # 2 for x in range(3, n, 2): for i in range(3, int(x**0.5)+1 , 2): # 这里面包含了大量的合数,9,14,27, if x % i == 0: break else: count += 1 delta = (datetime.datetime.now() - start).total_seconds() print(count, delta) #: 9592 0.173527
- 一个合数一定可以分解成几个素数的乘积,也就是说,一个数如果能被一个素数整除就是合数
# coding: utf-8 #算法2 # 原来代码的问题:x % 奇数,包括合数,计算量大了。 # 改进 x % 素数,但素数是谁? 是否能用上以前算出的素数? # 把已经算出的素数放进一个列表供自己使用 import datetime start = datetime.datetime.now() n = 100000 count = 1 # 2 primenumbers = [2] # 质数列表 for x in range(3, n, 2): # 只测试大于 2 的奇数 # x % odd => x % prime for i in primenumbers: #全质数表遍历,没有考虑开方点 ,对比 range(3, int(x**0.5)+1, 2) if x % i == 0: break else: count +=1 primenumbers.append(x) delta = (datetime.datetime.now() - start).total_seconds() print(count, delta) #: 9592 5.266468 反而时间更长了
改进
# coding: utf-8 # 算法3.1 # 原来代码的问题:x % 奇数,包括合数,计算量大了。 # 改进 x % 素数,但素数是谁? 是否能用上以前算出的素数? # 把已经算出的素数放进一个列表供自己使用 import datetime start = datetime.datetime.now() n = 100000 count = 1 # 2 primenumbers = [2] # 质数列表 for x in range(3, n, 2): # 只测试大于 2 的奇数 # x % odd => x % prime edge = int(x ** 0.5) for i in primenumbers: #全质数表遍历,没有考虑开方点 ,对比 range(3, int(x**0.5)+1, 2) # int(x ** 0.5) #if i <= int(x ** 0.5) and x % i == 0: # 计算量加大 if i <= edge and x % i == 0: break else: count +=1 primenumbers.append(x) delta = (datetime.datetime.now() - start).total_seconds() print(count, delta) #: 9592 3.676972 反而时间更长了
改进2
# coding: utf-8 # 算法3.2 import datetime start = datetime.datetime.now() n = 100000 count = 2 # 2 3 primenumbers = [3] # 质数列表 for x in range(5, n, 2): # 只测试大于 2 的奇数 # x % odd => x % prime edge = int(x ** 0.5) flag = False #假设这一趟的当前的 x,不是质数 for i in primenumbers: #全质数表遍历,没有考虑开方点 ,对比 range(3, int(x**0.5)+1, 2) if i > edge: #质数 i 大于开方点,说明不用往后走了,当前 x 已经是质数了。 flag = True # 找到质数了 break # 含义? 是质数 if x % i == 0: # 隐含了 i <= edge break # 是合数 if flag: # 找到质数 count +=1 primenumbers.append(x) delta = (datetime.datetime.now() - start).total_seconds() print(count, delta) #: 9592 0.152628
改进
# coding: utf-8 # 算法4 # 大于 5 之后,个位数是 5 就是合数 import datetime start = datetime.datetime.now() n = 100000 count = 2 # 2 3 primenumbers = [3] # 质数列表 for x in range(5, n, 2): # 只测试大于 2 的奇数 if x > 5 and x % 5 == 0: continue # x % odd => x % prime edge = int(x ** 0.5) flag = False #假设这一趟的当前的 x,不是质数 for i in primenumbers: #全质数表遍历,没有考虑开方点 ,对比 range(3, int(x**0.5)+1, 2) if i > edge: #质数 i 大于开方点,说明不用往后走了,当前 x 已经是质数了。 flag = True # 找到质数了 break # 含义? 是质数 if x % i == 0: # 隐含了 i <= edge break # 是合数 if flag: # 找到质数 count +=1 primenumbers.append(x) delta = (datetime.datetime.now() - start).total_seconds() print(count, delta) #: 9592 0.136901
# coding: utf-8 # 算法4.1 # 大于 5 之后,个位数是 5 就是合数 import datetime start = datetime.datetime.now() n = 100000 count = 3 # 2 3 5 primenumbers = [5] # 质数列表 for x in range(7, n, 2): # 只测试大于 2 的奇数 if x > 5 and x % 5 == 0: continue # x % odd => x % prime edge = int(x ** 0.5) flag = False #假设这一趟的当前的 x,不是质数 for i in primenumbers: #全质数表遍历,没有考虑开方点 ,对比 range(3, int(x**0.5)+1, 2) if i > edge: #质数 i 大于开方点,说明不用往后走了,当前 x 已经是质数了。 flag = True # 找到质数了 break # 含义? 是质数 if x % i == 0: # 隐含了 i <= edge break # 是合数 if flag: # 找到质数 count +=1 primenumbers.append(x) delta = (datetime.datetime.now() - start).total_seconds() print(count, delta) #: 9592 0.136901
- 孪生素数性质
大于 3 的素数只有 6N-1 和 6N+1 两种形式,如果 6N-1 和 6N+1 都是素数称为孪生素数
如何得到 6N-1 和 6N+1?
# coding: utf-8 # 孪生素数性质 >3 之后,素数只可能是 6 的倍数的前后值 # 5 7 11 13 17 19 规律是什么 ? # 5 +2 7 +4 11 +2 13 +4 17 +2 19 n = 20 x = 5 # 被测数x step = 2 while x < n: print(x) x += step step = 4 if step == 2 else 2 #: 5 #: 7 #: 11 #: 13 #: 17 #: 19
# coding: utf-8 # 算法5 孪生素数 import datetime start = datetime.datetime.now() n = 100000 x = 5 step = 2 primenumbers = [3] # >3 之后, 6 的倍数前后的数一定是奇数 count = 2 # 2,3 while x < n: edge = int(x ** 0.5) flag = False for i in primenumbers: if i > edge: flag = True break if x % i == 0: break if flag: count += 1 primenumbers.append(x) x += step step = 4 if step == 2 else 2 delta = (datetime.datetime.now() - start).total_seconds() print(count, delta)
改进
# coding: utf-8 # 算法5.1 孪生素数 import datetime start = datetime.datetime.now() n = 100000 x = 7 step = 4 primenumbers = [3,5] # >3 之后, 6 的倍数前后的数一定是奇数 count = 3 # 2,3,5 while x < n: if x % 5 != 0: edge = int(x ** 0.5) flag = False for i in primenumbers: if i > edge: flag = True break if x % i == 0: break if flag: count += 1 primenumbers.append(x) x += step step = 4 if step == 2 else 2 delta = (datetime.datetime.now() - start).total_seconds() print(count, delta) #: 9592 0.115729
计算杨辉三角前6行
- 第 n 行有 n 项,n 是正整数
- 第 n 行数字之和为 2**(n-1)
- 打印出杨辉三角的每一行数字即可
解法1:逐行计算
# coding: utf-8 # 算法1 # 直接推出,从第三行开始,后一行与前一行有关 # 容器,里面放各行 n = 6 triangle = [[1],[1,1]] # 每一行用列表实现,它是引用类型 for i in range(2, n): # 计数器 cur = [1] pre = triangle[i-1] # [1,2,1] for j in range(i-1): # 计数器,控制每一行计算的个数 # i=2 1次 j=0 # i=3 2次 j=0 1 #计算几项,如何完成计算 j=0 cur.append(pre[j]+pre[j+1]) cur.append(1) print(cur) triangle.append(cur) # 加入到大三角里面,引用类型 print('~~~~~~~~') print(triangle) #: [1, 2, 1] #: [1, 3, 3, 1] #: [1, 4, 6, 4, 1] #: [1, 5, 10, 10, 5, 1] #: ~~~~~~~~ #: [[1], [1, 1], [1, 2, 1], [1, 3, 3, 1], [1, 4, 6, 4, 1], [1, 5, 10, 10, 5, 1]]
# coding: utf-8 # 算法1.1 # 直接推出,从第三行开始,后一行与前一行有关 # 容器,里面放各行 n = 6 triangle = [[1],[1,1]] # 每一行用列表实现,它是引用类型 for i in range(2, n): # 计数器 cur = [1] triangle.append(cur) # 加入到大三角里面,引用类型 pre = triangle[i-1] # [1,2,1] for j in range(i-1): # 计数器,控制每一行计算的个数 # i=2 1次 j=0 # i=3 2次 j=0 1 #计算几项,如何完成计算 j=0 cur.append(pre[j]+pre[j+1]) cur.append(1) print(cur) #triangle.append(cur) # 加入到大三角里面,引用类型 print('~~~~~~~~') print(triangle) #: [1, 2, 1] #: [1, 3, 3, 1] #: [1, 4, 6, 4, 1] #: [1, 5, 10, 10, 5, 1] #: ~~~~~~~~ #: [[1], [1, 1], [1, 2, 1], [1, 3, 3, 1], [1, 4, 6, 4, 1], [1, 5, 10, 10, 5, 1]]
# coding: utf-8 # 算法1.2 # 直接推出,从第三行开始,后一行与前一行有关 # 容器,里面放各行 n = 6 triangle = [] # 每一行用列表实现,它是引用类型 for i in range(n): # 计数器 cur = [1] triangle.append(cur) # 加入到大三角里面,引用类型 if i == 0: continue for j in range(i-1): # 计数器,控制每一行计算的个数 # i=2 1次 j=0 # i=3 2次 j=0 1 #计算几项,如何完成计算 j=0 cur.append(triangle[i-1][j] + triangle[i-1][j+1]) cur.append(1) print(cur) #triangle.append(cur) # 加入到大三角里面,引用类型 print('~~~~~~~~') print(triangle) # 空间复杂度高 #: [1, 1] #: [1, 2, 1] #: [1, 3, 3, 1] #: [1, 4, 6, 4, 1] #: [1, 5, 10, 10, 5, 1] #: ~~~~~~~~ #: [[1], [1, 1], [1, 2, 1], [1, 3, 3, 1], [1, 4, 6, 4, 1], [1, 5, 10, 10, 5, 1]]
改进:题目要求打印每一行,没有必要保存所有行,只需保存 2 行就够了
# coding: utf-8 # 算法1.3 # 直接推出,从第三行开始,后一行与前一行有关 # 只需要 2 行,向后递推 # 相对算法1 降低了内存使用 n = 3 pre = [] for i in range(n): # 计数器 cur = [1] if i == 0: print(cur) pre = cur # [1] continue for j in range(i-1): # 计数器,控制每一行计算的个数 # i=2 1次 j=0 # i=3 2次 j=0 1 #计算几项,如何完成计算 j=0 cur.append(pre[j] + pre[j+1]) #[1,2] cur.append(1) #[1,2,1] print(cur) pre = cur # [1,2,1] print('~~~~~~~~') #: [1] #: [1, 1] #: [1, 2, 1] #: ~~~~~~~~
# coding: utf-8 # 算法1.4 # 直接推出,从第三行开始,后一行与前一行有关 # 只需要 2 行,向后递推 # 相对算法1 降低了内存使用 n = 3 pre = [] for i in range(n): # 计数器 cur = [1] if i != 0: for j in range(i-1): # 计数器,控制每一行计算的个数 cur.append(pre[j] + pre[j+1]) #[1,2] cur.append(1) #[1,2,1] print(cur) pre = cur # [1,2,1] print('~~~~~~~~') #: [1] #: [1, 1] #: [1, 2, 1] #: ~~~~~~~~
解法2: 补零
# coding: utf-8 #算法2 补零。每行两边补零 n = 6 pre = [1] # 前一行 print(pre) for i in range(1,n): # 计数器 cur = [] # 新建一个列表 cur 引用类型 pre.append(0) # [1,0] for j in range(i+1): # 计数器, cur.append(pre[j-1] + pre[j]) # -1,0 0,1 print(cur) pre = cur # [1,2,1] #: [1] #: [1, 1] #: [1, 2, 1] #: [1, 3, 3, 1] #: [1, 4, 6, 4, 1] #: [1, 5, 10, 10, 5, 1]
# coding: utf-8 #算法2.1 补零。每行两边补零 # cur 一次性开辟内存空间。一般来说,频繁 append 效率没有一次性扩展一定大小好 n = 6 pre = [1] # 前一行 print(pre) for i in range(1,n): # 计数器 cur = [None] * (i+1) # 新建一个列表,直接开辟够 pre.append(0) # [1,0] for j in range(i+1): # 计数器, cur[j] = pre[j-1] + pre[j] #cur.append(pre[j-1] + pre[j]) # -1,0 0,1 print(cur) pre = cur # [1,2,1] #: [1] #: [1, 1] #: [1, 2, 1] #: [1, 3, 3, 1] #: [1, 4, 6, 4, 1] #: [1, 5, 10, 10, 5, 1]
解法3:对称
- 行索引奇数,左右数字个数相同,只需计算左边所有数字
- 行索引为偶数,只需计算左边所有数字,最中心数字只需计算一次
- 为每一行直接开辟够空间,两端 1 不要计算了
# coding: utf-8 #算法3 对称 n = 6 for i in range(n): # 计数器 cur = [1] * (i+1) # 新建一个列表,直接开辟够 for j in range(i//2): # 计数器, value = pre[j] + pre[j+1] cur[j+1] = value #对称点 cur[-(j+1)-1] = value print(cur) pre = cur # [1,2,1]
# coding: utf-8 #算法3.1 对称,range 平移 n = 6 for i in range(n): # 计数器 cur = [1] * (i+1) # 新建一个列表,直接开辟够 for j in range(1, i//2+1): # 计数器, # i=2, j=1, m=1 重复了 # i=3, j=1, m=1 不重复赋值 # i=4, j=1, m=2 重复了 value = pre[j-1] + pre[j] cur[j] = value #对称点 if i != 2*j: cur[-j-1] = value print(cur) pre = cur # [1,2,1]
python 内存管理
面试题。
- 变量无须事先声明,也不需要指定类型,这是动态语言的特性
- 变量只是一个标识符,指向一个对象,而这个对象被创建在内存“堆”中
- Python 编程中一般无须关心变量的存亡,也不用关心内存的管理
- Python 使用引用计数记录所有对象的引用数。当对象引用数变为0,它就可以被垃圾回收GC,从源头上减少垃圾排放
计数增加:
- 赋值给其它变量就增加引用计数,例如
x=3;y=x;z=[x,1]x 所指向的内存地址被引用了 3 次 - 实参传参,如 foo(y)
计数减少:
- 函数运行结束时,局部变量就会被自动销毁,对象引用计数减少
- 变量被赋值给其它对象。例如
x=3;y=x;x=4
有关性能的时候,就需要考虑变量的引用问题,但是,到底该释放内存还是尽量不释放内存,看需求。
内存是宝贵的,因为它快。但再好的硬件资源,再多的机器,在高并发面前都嫌少。内存一定要合理利用。
但是,数据搬到内存中不易,不要把大量数据好不容易搬到内存中,立刻就不要了。这非常没有效率
1 2 3 4 5 6 7
[1][ ][ ][4][5][6][ ]
7 8 9 10
引用计数的问题
引用计数是简单实现垃圾标记的办法
引用计数可能出现循环引用,Python 提供了 gc 模块,解决了这个问题。
查看引用计数
#coding: utf-8 #列表 x = [] # 新建的空列表 [],地址交给了 x,引用计数为1 import sys print(sys.getrefcount(x)) # 函数调用自动加 1, 用完减 1 #: 2 y = x print(sys.getrefcount(x)) print(sys.getrefcount([])) #实际 [] 引用计数 0 ,调用完后,适当的时候,GC 清理它 #: 3 #: 1 a = 1 # 字面常量,数值或字符串等,他们是常量,常量处理不同,一旦创建不允许改动,因此没有必要在内存保存很多份 print(sys.getrefcount(a)) b = a print(sys.getrefcount(a)) #: 4294967295 #: 4294967296
随机数(重要)
random模块常用方法
- randint(a, b) 返回[a, b]之间的整数
- randrange ([start,] stop [,step]) 从指定范围内,按指定基数递增的集合中获取一个随机数,基数缺省值为1。 random.randrange(1,7,2)
- choice(seq) 从非空序列的元素中随机挑选一个元素,比如random.choice(range(10)),从0到9中随机挑选一个整数。random.choice([1,3,5,7])
- 3.6开始提供choices,一次从样本中随机选择几个,可重复选择,可以指定权重
- random.shuffle(list) ->None 就地打乱列表元素
- sample(population, k) 从样本空间或总体(序列或者集合类型)中随机取出k个不同的元素,返回一个新的列表
- random.sample(['a', 'b', 'c', 'd'], 2)
- random.sample(['a', 'a'], 2) 会返回什么结果
- 每次从样本空间采样,在这一次中不可以重复抽取同一个元素
范例:
#coding: utf-8 import random for i in range(5): print(random.randint(0,1), end=' ') #[0,1] 全闭区间 #1 0 1 0 1 print() for i in range(5): print(random.randrange(0,1), end=' ') #和 range 一样 [0,1) 前包后不包 #0 0 0 0 0 print() x = list(range(5)) print(x) random.shuffle(x) # 就地打乱 print(x) #[0, 1, 2, 3, 4] #[3, 0, 2, 1, 4] x = list(range(5)) for i in range(3): print(random.choice(x)) # 参数为 sequence 序列,序列中随机抽取一个 #0 #1 #0 # choices #population, weights=None, *, cum_weights=None, k=1 for i in range(3): print(random.choices(x, k=6)) # 每一次拿都可以重复, 6 次 choice #[4, 4, 4, 4, 4, 4] #[4, 3, 4, 2, 0, 3] #[2, 4, 1, 4, 1, 4] for i in range(3): print(random.choices([0,1], [100,1],k=4)) # 有权重,0和1比例为 100:1 #[0, 0, 0, 0] #[0, 0, 0, 0] #[0, 0, 0, 0] for i in range(5): print(random.sample([0,1],k=2)) #从样本中,不同索引位置上挑,不重复挑选,每一次都没重复 #[1, 0] #[0, 1] #[1, 0] #[1, 0] #[1, 0]
元组tuple
- 一个有序的元素组成的集合
- 使用小括号 ( ) 表示
- 元组是
不可变对象
初始化
- tuple() -> empty tuple
- tuple(iterable) -> tuple initialized from iterable's items
t1 = () # 空元组 t2 = (1,) # 必须有这个逗号 t3 = (1,) * 5 t4 = (1, 2, 3) t5 = 1, 'a' t6 = (1, 2, 3, 1, 2, 3) t7 = tuple() # 空元组 t8 = tuple(range(5)) t9 = tuple([1,2,3])
范例:
#coding: utf-8 t1 = () # 解释器对不可变 tuple 类型做了优化,空元组 t2 = tuple() print(t1 == t2, t1 is t2) #: True True t3 = (1,) t4 = tuple((1,)) print(t3 is t4, t3, t4) #: True (1,) (1,)
索引
索引和列表规则一样,不可以超界
查询
方法和列表一样,时间复杂度也一样。index、count、len等
增删改
元组元素的个数在初始化的时候已经定义好了,所以不能为元组增加元素、也不能从中删除元素、也不能修改元素的内容。
但是要注意下面这个例子
# coding: utf-8 t1 = ([1]) * 3 t1[1] = 100 # 可以,因为上面定义的是列表 print(t1) #: [1, 100, 1] # 注意下面的例子 t2 = ([1],) * 3 print(t2) #: ([1], [1], [1]) #t2[1] = 100 #不能修改元素内容 t2[0][0] = 100 print(t2) #: ([100], [100], [100])
上例说明t2是可变的吗?不是说元组不可变吗?到底什么不可变?对于元组来讲只要里面的内容不变就行。
练习
依次接收用户输入的 3 个数,排序打印
- 转换 int 后,判断大小排序。使用分支结构完成
- 使用 max 函数
- 使用列表的 sort 方法
- 冒泡法
分支结构
#coding: utf-8 nums = [] while True: nums.append(int(input('>>>'))) if len(nums) >=3: break if nums[0] > nums[1]: if nums[0] > nums[2]: if nums[1] > nums[2]: orders = (2,1,0) else: # 1 <= 2 orders = (1,2,0) else: # 0 < 2 and 0 > 1 orders = (1,0,2) else: # 0 < 1 if nums[0] > nums[2]: orders = (2,0,1) else:# 0 <= 2 if nums[1] > nums[2]: orders = (0,2,1) else: # 1 <= 2 orders = (0,1,2) print(nums) for i in orders: print(nums[i])
使用 max 函数
#coding: utf-8 #nums = [] #while True: # nums.append(int(input('>>>'))) # if len(nums) >=3: break # 使用 max 函数 # 不推荐。因为 max 每一次都对全体剩余元素进行从头到尾的遍历 nums = [4, 6, 5] newlist = [None] * len(nums) # 必须要有,一般来说 append 效率也不错 # 但是,如果需要大空间列表,那么一次次 append 从原理来说不如一次性开辟够 index = -1 while nums: m = max(nums) nums.remove(m) newlist[index] = m # 通过索引覆盖是高效的方法 if len(nums) == 1: newlist[0] = nums[0] break index -= 1 print(nums) print(newlist)
使用列表的 sort 方法
#coding: utf-8 nums = [4,6,5] print(nums) nums.sort() # 就地修改 print(nums) # sorted 函数 nums = [4, 6 , 5] x = sorted(nums) # 立即返回一个新的列表 print(x) #都用了排序算法,效率很高。 推荐
排序算法-冒泡排序 Bubble Sort

- 交换排序
- 相邻元素两两比较大小,有必要则交换
- 元素越小或越大,就会在数列中慢慢的交换并“浮”向顶端,如同水泡咕嘟咕嘟往上冒
- 依次类推,每一轮都会减少最右侧的不参与比较,直至剩下最后2个数比较。
核心算法
- 排序算法,一般都实现为就地排序,输出为升序
- 扩大有序区,减少无序区。
- 每一趟比较中,将无序区中所有元素依次两两比较,升序排序将大数调整到两数中的右侧
- 每趟比较完成,都会把这一趟最大数推到当前无序区的最右侧
基本实现
分析过程:将问题规模减小,一般 2 次不一定能找到规律, 3 次基本上可以看出规律。所以,我们思考时认为列表里就只有 4 个元素。
[9,1,8,5] 第一趟 len -1 - 0 依次比较相邻的两个元素,使较大的那个向后移 0,1; [1,9,8,5] 1,2;[1,8,9,5] 2,3; [1,8,5,9] 第二趟 len - 1 -1 依次比较相邻的两个元素,使较大的那个向后移 0,1; [1,8,5|,9] 1,2;[1,5,8|,9] 第三趟 len - 1 -2 依次比较相邻的两个元素,使较大的那个向后移 0,1; [1,5|,8,9]
#coding: utf-8 #排序算法,所有程序员的基础,大厂 一定考算法 nums = [9,1,8,5] length = len(nums) for i in range(length - 1): for j in range(length - 1 - i): if nums[j] > nums[j+1]: # 相邻比较,交换 temp = nums[j] nums[j] = nums[j+1] nums[j+1] = temp print(nums) # 每一趟走完的当前情况 print('----------------') print(nums) # 最终结果 #: [1, 8, 5, 9] #: [1, 5, 8, 9] #: [1, 5, 8, 9] #无用功 #: ---------------- #: [1, 5, 8, 9]
检查比较的次数、交换的次数
#coding: utf-8 #排序算法,所有程序员的基础,大厂 一定考算法 nums = [1,9,8,5,6,7,4,3,2] length = len(nums) count = 0 swap_count = 0 print(nums) print('~~~~~~~~~~~~~~') for i in range(length - 1): for j in range(length - 1 - i): count += 1 if nums[j] > nums[j+1]: # 相邻比较,交换 temp = nums[j] nums[j] = nums[j+1] nums[j+1] = temp swap_count += 1 print(nums) # 每一趟走完的当前情况 print('----------------') print(nums) # 最终结果 print(count, swap_count) # 比较次数、交换次数
优化
思考:如果某一趟两两比较没有发生任何交换,说明什么?
1 + 2 + ... + (n -2) + (n -1) # 比较次数 => n(n-1)/2 (n-1) + (n -2) + ... + 2 + 1
nums = list(range(1, 10)) # 升序, count = 9(9-1)/2=36; swap = 0
测试
#coding: utf-8 #排序算法,所有程序员的基础,大厂 一定考算法 #nums = list(range(1, 10)) # 升序, count = 9(9-1)/2=36; swap = 0 nums = list(range(9,0, -1)) # 最差情况 #nums = [9,8,1,2,3,4,5,6,7] length = len(nums) count = 0 swap_count = 0 print(nums) print('~~~~~~~~~~~~~~') for i in range(length - 1): flag = False # 假设这一趟没有交换过 for j in range(length - 1 - i): count += 1 if nums[j] > nums[j+1]: # 相邻比较,交换 temp = nums[j] nums[j] = nums[j+1] nums[j+1] = temp swap_count += 1 flag = True print(nums) # 每一趟走完的当前情况 if not flag: break print('----------------') print(nums) # 最终结果 print(count, swap_count) # 比较次数、交换次数
总结
- 冒泡法需要数据一趟趟比较
- 可以设定一个标记判断此轮是否有数据交换发生,如果没有发生交换,可以结束排序,如果发生交换,继续下一轮排序。
- 最差的排序情况是,初始排序与目标顺序完全相反,遍历次数 1,…,n-1之和 n(n-1)/2
- 最好的排序情况是,初始排序与目标顺序完全相同,遍历次数 n-1
- 时间复杂度 \(O(n^2)\)
字符串str
- 一个个字符组成的有序的序列,是字符的集合
- 使用单引号、双引号、三引号引住的字符序列
- 字符串是
不可变对象,是字面常量
Python3 起,字符串都是 Unicode 类型
初始化
#coding: utf-8 s1 = 'string' s2 = "string2" s3 = '''this's a "String" ''' # 有单引号、双引号,用三绰号包裹 s4 = 'hello \n xxx.com' # 转义字符 \n 用 print 才能看到 s5 = r"hello \n xxx.com" # r 前缀阻止 \n 转义 #s6 = 'c:\windows\nt' #3.12+之后,\后必须是有效转义,如\n \t s7 = R"c:\windows\nt" # 方法1 加 r 前缀不转义 s8 = 'c:\windows\\nt' # 方法2 \ 用 \\ 转义表示 name = 'tom'; age = 20 # python代码写在一行,使用分号隔开,不推荐 s9 = f'{name}, {age}' # 3.6支持 f 前缀,使用变量插值 sql = """select * from user where name='tom' """ # 长语句用三引号比较方便 print(sql) #: select * from user where name='tom'
r前缀:所有字符都是本来的意思,没有转义
f前缀:3.6开始,使用变量插值
索引
字符串是序列,支持下标访问。但不可变,不可以修改元素。
sql = "select * from user where name='tom'" print(sql[4]) # 字符串'c' sql[4] = 'o' # 不可以
字符串遍历
s = 'hello' for i in s: print(type(i), i) # python 中没有其他语言的 char 类型 #: <class 'str'> h #: <class 'str'> e #: <class 'str'> l #: <class 'str'> l #: <class 'str'> o
连接
- 加号
- 将2个字符串连接起来
- 返回一个
新的字符串
join 方法
- sep.join(iterable)
- 使用指定字符串作为
分隔符,将可迭代对象中字符串使用这个分隔符拼接起来 - 可迭代对象必须是字符串
- 返回一个新的字符串
范例:
x = 'ab' x = x + 'cd' print(','.join(x)) print('\t'.join(x)) print('\n'.join(x)) print('-'.join(range(5))) # 可以吗, 不可以
范例
#coding: utf-8 s = 'a' + 'b' s2 = 'cde' print(s, s2) print(','.join(s2)) print(list(s2), tuple(s2)) print(''.join(['a','b','cd'])) # join 可迭代对象必须是字符串 print('\n'.join(map(str,range(5)))) # \n 代表一个字符 #: ab cde #: c,d,e #: ['c', 'd', 'e'] ('c', 'd', 'e') #: abcd #: 0 #: 1 #: 2 #: 3 #: 4
字符查找
- find(sub[, start[, end]]) -> int
- 在指定的区间[start, end),从左至右,查找子串sub
- 找到返回正索引,没找到
返回-1
- rfind(sub[, start[, end]]) -> int
- 在指定的区间[start, end),从右至左,查找子串sub
- 找到返回正索引,没找到
返回-1
s = 'xxx.edu' print(s.find('edu')) print(s.find('edu', 3)) print(s.find('edu', 4)) print(s.find('edu', 6, 9)) print(s.find('edu', 7, 20)) print(s.find('edu', 200)) s = 'xxx.edu' print(s.rfind('edu')) print(s.rfind('edu', 3)) print(s.rfind('edu', 4)) print(s.rfind('edu', 6, 9)) print(s.rfind('edu', 7, 20)) print(s.rfind('edu', 200))
这两个方法只是找字符串的方向不同,返回值一样。找到第一个满足要求的子串立即返回。特别注意返回值,找不到返回的是负数-1。
这两个方法效率高吗?要不要用?
这两个方法效率真不高,都是在字符串中遍历搜索,但是如果找子串工作必不可少,那么必须这么做,但是能少做就少做。
- index(sub[, start[, end]]) -> int
- 在指定的区间[start, end),从左至右,查找子串sub
- 找到返回正索引,没找到抛出异常ValueError
- rindex(sub[, start[, end]]) -> int
- 在指定的区间[start, end),从右至左,查找子串sub
- 找到返回正索引,没找到抛出异常ValueError
index方法和find方法很像,不好的地方在于找不到抛异常。推荐使用find方法。
#coding: utf-8 s = 'xxx.edu' print(s.index('edu')) print(s.index('edu', 3)) print(s.index('edu', 4)) #print(s.index('edu', 6, 9)) # 抛异常 #print(s.index('edu', 7, 20)) # 抛异常 #print(s.index('edu', 200)) # 抛异常
范例
#coding: utf-8 x = '\n'.join('1234') #print(x.index(1)) #抛异常,找的必须是字符串 y = '1234' print(y.index('123')) #: 0
- count(sub[, start[, end]]) -> int
- 在指定的区间[start, end),从左至右,统计子串sub出现的次数
- 能不用就不用,字符串的子串问题,是相当难的算法题
#coding: utf-8 s = 'xxx.edu' print(s.count('edu')) print(s.count('edu', 4)) #: 1 #: 1
- 时间复杂度
- find、index和count方法都是O(n)
- 随着字符串数据规模的增大,而效率下降
- len(string)
- 返回字符串的长度,即字符的个数。字符串是字面常量,长度已经定义好了,可以直接取到。
分割
- split(sep=None, maxsplit=-1) -> list of strings
- 从左至右
- sep 指定分割字符串,缺省的情况下空白字符串作为分隔符
- maxsplit 指定分割的次数,-1 表示遍历整个字符串
- 立即返回列表
- rsplit(sep=None, maxsplit=-1) -> list of strings
- 从右向左开始切,但是输出的字符串字符不会反
- sep 指定分割字符串,缺省的情况下空白字符串作为分隔符
- maxsplit 指定分割的次数,-1 表示遍历整个字符串
- 立即返回列表
- splitlines([keepends]) -> list of strings
- 按照行来切分字符串
- keepends 指的是是否保留行分隔符
- 行分隔符包括\n、\r\n、\r等
#coding: utf-8 s = ','.join('abcd') print(s.split(',')) print(s.split()) print(s.split(',', 2)) # 指定切割次数 #: ['a', 'b', 'c', 'd'] #: ['a,b,c,d'] #: ['a', 'b', 'c,d'] s1 = '\na b \tc\nd\n' # 注意下面3个切割的区别 print(s1.split()) # 空白、换行符、tab,统称为空白字符 space。切割行为是:尽可能长的空白字符 print(s1.split(' ')) print(s1.split('\n')) print(s1.split('b')) #: ['\na', 'b', '\tc\nd\n'] #: ['', 'a b \tc', 'd', ''] #: ['\na ', ' \tc\nd\n'] # rsplit 从右向左切割 print(s1.rsplit()) print(s1.rsplit('\n')) #: ['a', 'b', 'c', 'd'] #['', 'a b \tc', 'd', ''] print(s1.splitlines()) # 按行切割。 print(s1.splitlines(True)) # 是否保留切掉的换行符 #['', 'a b \tc', 'd'] #['\n', 'a b \tc\n', 'd\n']
- partition(sep) -> (head, sep, tail)
- 从左至右,遇到分隔符就把字符串分割成两部分,返回头、分隔符、尾三部分的三元组
- 如果没有找到分隔符,就返回头、2个空元素的三元组
- sep 分割字符串,必须指定
- rpartition(sep) -> (head, sep, tail)
- 从右至左,遇到分隔符就把字符串分割成两部分,返回头、分隔符、尾三部分的三元组
- 如果没有找到分隔符,就返回2个空元素和尾的三元组
s = ','.join('abcd') print(s.partition(',')) #立即返回元组(part1, sep, part2) #: ('a', ',', 'b,c,d') print(s.partition('.')) # 没有切入点时,后两个元素是空串 print(s.rpartition(',')) print(s.rpartition('.')) #: ('a', ',', 'b,c,d') #: ('a,b,c,d', '', '') #: ('a,b,c', ',', 'd') #: ('', '', 'a,b,c,d')
替换
- replace(old, new[, count]) -> str
- 字符串中找到匹配替换为新子串,返回新字符串。不支持模式匹配,以后使用 re 模块
- count表示替换几次,不指定就是全部替换
#coding: utf-8 s = ','.join('abcd') print(s.replace(',', ' ')) print(s.replace(',', ' ', 2)) s1 = 'www.xxx.edu' print(s1.replace('w', 'a')) print(s1.replace('ww', 'a')) print(s1.replace('ww', 'w')) # 返回什么? print(s1.replace('www', 'a')) #: aaa.xxx.edu #: aw.xxx.edu #: ww.xxx.edu #: a.xxx.edu
移除
- strip([chars]) -> str
- 在字符串两端去除指定的字符集chars中的所有字符。其它语言一般叫 trim
- 如果 chars 没有指定,去除两端的空白字符
- lstrip([chars]) -> str ,从左开始
- rstrip([chars]) -> str,从右开始
#coding: utf-8 s = '\t\r\na b c,d\ne\n\t' print(s.strip()) # 拿掉两端的空白字符 print('-' * 30) print(s.strip('\t\n')) print('-' * 30) print(s.strip('\t\ne\r')) # 两端字符在这个字符集就拿掉
首尾判断
- endswith(suffix[, start[, end]]) -> bool
- 在指定的区间[start, end),字符串是否是suffix结尾
- startswith(prefix[, start[, end]]) -> bool
- 在指定的区间[start, end),字符串是否是prefix开头
效率还是很高的,因为它锚死了开头或结尾
s = "www.xxx.edu" print(s.startswith('ww')) print(s.startswith('e', 7)) #从索引 7 位置开始找 print(s.startswith('e', 10)) print(s.startswith('edu', 11)) print(s.endswith('edu'))
其它函数
upper()大写- lower()小写
- swapcase() 交换大小写
isalnum()-> bool 是否是字母和数字组成- isalpha() 是否是字母
- isdecimal() 是否只包含十进制数字
- isdigit() 是否全部数字(0~9)
- isidentifier() 是不是字母和下划线开头,其他都是字母、数字、下划线
- islower() 是否都是小写
isupper()是否全部大写- isspace() 是否只包含空白字符
其他格式打印函数中文几乎不用,大家自行查看帮助。以后用正则表达式,这些都不在话下。
范例:
#coding: utf-8 f = 'abcdef' print(f.upper()) print(f.lower()) print('Abc'.istitle()) # 对于英文,title 首字母要大写,是大写返回True print(" \t\r\n\f".isspace()) print('012'.isnumeric()) # 是数字吗,不认小数点 print('012'.isdigit()) # 是数字吗,不认小数点 print('abc_123'.isidentifier()) # 是标识符吗。不以数字开始,字母、数字、下划线吗 print('abc_123'.isalnum()) #是字母和数字的集合吗 #: ABCDEF #: abcdef #: True #: True #: True #: True #: True #: False
格式化
简单的使用+或者join也可以拼接字符串,但是需要先转换数据到字符串后才能拼接。
C风格printf-style
参考:printf-style String Formatting
- 占位符:使用 % 和格式字符,例如%s、%d
- 修饰符:在占位符中还可以插入修饰符,例如%03d
- format % values
- format是格式字符串,values是被格式的值
- 格式字符串和被格式的值之间使用%
- values只能是一个对象,可以是一个值,可以是一个元素个数和占位符数目相等的元组,也可以是一个字典
#coding: utf-8 print("I am %03d" % (20,)) #默认右对齐。I am 020 。 左对齐的话 %-03d print("%3.2f%%" % (89.7654,)) # 宽度为3,小数点后2位。 print('I like %s.' % 'Python') print("I am %-5d y" % (20,)) # 左对齐 print("I am %05d y" % (20,)) # 充填等长的0 print("%(host)s.%(domain)s" % {'domain':'xxx.com', 'host':'www'}) # 靠名字对应 #: I am 020 #: 89.77% #: I like Python. #: I am 20 y #: I am 00020 y #: www.xxx.com print("0x%x %X %o %d" % (10,16,8,2)) # %x 十六进制, %X 十六进制大写 %o 八进制 print("%#x %#X %#o %d" % (10,16,8,2)) #%#X 其中 # 在前面加 0X #: 0xa 10 10 2 #: 0xa 0X10 0o10 2
python3.6后,f 插入字符串
age = 20; name = 'Tome' print(f'{age} {name}') #: 20 Tome
format函数
Python2.5之后,字符串类型提供了format函数, 功能更加强大,鼓励使用 。
"{} {xxx}".format(*args, **kwargs) -> str
- args是可变的位置参数
- kwargs是可变关键字参数,写作a=100
- 使用花括号作为占位符
- {}表示按照顺序匹配位置参数,{n}表示取位置参数索引为n的值
- {xxx}表示在关键字参数中搜索名称一致的
- {{}} 表示打印花括号
# 位置对应 "{}:{}".format('127.0.0.1', 8080) # 位置或关键字对应 "{server} {1}:{0}".format(8080, '127.0.0.1', server='Web Server Info: ') # 访问元素 "{0[0]}.{0[1]}".format(('xxx', 'com')) # 很少这样写 "{}+++{}".format(*('xxx', 'com')) # 拆开,相当于 format('xxx','com') # 进制,# 在前面加上对应进制标记 "{0:d} {0:b} {0:o} {0:x} {0:#X}".format(31)
# 浮点数 print("{}".format(3**0.5)) # 1.7320508075688772 print("{:f}".format(3**0.5)) # 1.732051,精度默认6 print("{:10f}".format(3**0.5)) # 右对齐,宽度10 print("{:2}".format(102.231)) # 宽度为2数字 print("{:2}".format(1)) # 宽度为2数字 print("{:.2}".format(3**0.5)) # 1.7 2个数字 print("{:.2f}".format(3**0.5)) # 1.73 小数点后2位 print("{:3.2f}".format(3**0.5)) # 1.73 宽度为3,小数点后2位 print("{:20.3f}".format(0.2745)) # 0.275 print("{:3.3%}".format(1/3)) # 33.333% # 注意宽度可以被撑破
#coding: utf-8 # 对齐 print("{}*{}={}".format(5, 6, 5*6)) print("{}*{}={:2}".format(5, 6, 5*6)) print("{1}*{0}={2:3}".format(5, 6, 5*6)) # 索引2对应用数字右对齐3个字符 print("{1}*{0}={2:0>3}".format(5, 6, 5*6)) # 6*5=030 右对齐3个字符,前面补0。场景:商品、设备编号 print("{}*{}={:#<3}".format(4, 5, 20)) # 4*5=20# 左对齐3个字符,后面补#号 print("{:#^7}".format('*' * 3)) #: ##***## 居中对齐两边加#号
范例:
#coding: utf-8 #format 对齐 #format处理 ={n:<2}= 冒号是分割符号, < 左对齐,后面的 n 表示变量对应的序号。 print('{0:<2} #'.format(2*3)) #居中对齐 print('{0:^3}'.format(2*3)) #: 6 # #: 6
范例:时间字符串格式化
#coding: utf-8 import datetime d1 = datetime.datetime.now() #datetime.datetime(2024, 3, 18, 15, 59, 23, 999524) print("{}".format(d1)) print("{:%Y %y %m %d %H %M %S }".format(d1)) print("{:%Y/%m/%d %H:%M:%S }".format(d1)) #年月日 时分秒 #: 2024-03-18 16:02:40.556765 #: 2024 24 03 18 16 02 40 #: 2024/03/18 16:02:40
练习
判断数字并打印。
用户输入一个十进制正整数数字。1.判断是几位数; 2.打印每一位数字及重复的次数;3.依次打印每一位数字,顺序个、十、百、千、万位
判断数字位数并打印
输入 5 个十进制正整数数字,判断输入的这些数字分别是几位数,将这些数字排序打印,要求升序。
判断数字并打印。
用户输入一个十进制正整数数字。1.判断是几位数; 2.打印每一位数字及重复的次数;3.依次打印每一位数字,顺序个、十、百、千、万位
# coding: utf-8 num = '' while not num: x = input('Plz input your positive number >> ').strip().lstrip('0') if x.isdigit(): num = x #以上就是简单判断 print(num, len(num)) # 几位数
倒着打印
# coding: utf-8 num = '12345' for i in range(len(num)-1, -1, -1): print(num[i]) for i in range(1, len(num)+1): print(num[-i]) for x in reversed(num): print(x) for i in range(-1, -len(num)-1, -1): print(num[i]) print(num[::-1])
打印每一位数字及重复的次数
# coding: utf-8 num = '1112333' count = [0] * 10 # 十进制 0 ~ 9 # 解法1,count 时间复杂度 0(n) for i in range(10): # 10 * n O(10n) count[i] = num.count(str(i)) # O(n) if count[i]: print('The count of {} is {}'.format(i, count[i])) print('~~~~~~~~~~~~~') for i in '0123456789': # 10*n x = num.count(i) if x: print('The count of {} is {}'.format(i, x))
# coding: utf-8 num = '12222333' counter = [0] * 10 # 十进制,0~9 #解法2 遍历num count for x in num: i = int(x) if counter[i] == 0: counter[i] = num.count(x) print(counter)
# coding: utf-8 num = '12222333' counter = [0] * 10 # 十进制,0~9 #解法3 不用count,遍历自己 for x in num: # O(n) counter[int(x)] +=1 print(counter) for i in range(len(counter)): if counter[i]: print('The count of {} is {}'.format(i, counter[i])) #: [0, 1, 4, 3, 0, 0, 0, 0, 0, 0] #: The count of 1 is 1 #: The count of 2 is 4 #: The count of 3 is 3
判断数字位数并打印
输入 5 个十进制正整数数字,判断输入的这些数字分别是几位数,将这些数字排序打印,要求升序。
# coding: utf-8 nums = [] while len(nums) <5: num = input('Plz input a number: ').strip().lstrip('0') if not num.isdigit(): continue print('The length of {} is {}'.format(num, len(num))) nums.append(int(num)) print(nums) # sort 方法排序 lst = nums.copy() lst.sort() # 就地修改 print(lst) # 冒泡法 for i in range(len(nums)): flag = False for j in range(len(nums)-i-1): if nums[j] > nums[j+1]: tmp = nums[j] nums[j] = nums[j+1] nums[j+1] = tmp flag = true if not flag: break print(nums)
编码与解码
bytes 叫字节序列。bytearray 叫字节序列,但它可变。bytearray 把当字节数组一样使用,可进行增删改查。bytes 更像 string 一样不允许修改。
使用场景,主要用在编码和解码中。
- 编码:str => bytes,将字符串这个字符序列使用指定字符集encode编码为一个个字节组成的序列bytes
- 解码:bytes或bytearray => str,将一个个字节按照某种指定的字符集解码为一个个字符串组成的字符串
范例:
# coding: utf-8 #编码 print("abc".encode()) # 缺省为utf-8编码 str => bytes 类型不可变。一个字符一个字节 print("啊".encode('utf-8')) # utf-8 str => bytes 一个汉字 3 个字节 print("啊".encode('gbk')) # gbk str => bytes 一个汉字 2 个字节 #b'abc' #b'\xe5\x95\x8a' #b'\xb0\xa1' #解码 #bytes btearry 字节序列 => str print(b'abc'.decode('utf8')) print(b'\xb0\xa1'.decode('gbk')) #abc #啊
python 3 中字符串使用的都是 unicode
ASCII
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套单字节编码系统
https://en.wikipedia.org/wiki/ASCII
范例:查看 ascii 表
dnf -y install man-pages man ascii
熟记:
- \x00是ASCII表中第一项,C语言中的字符串结束符
- \t、\x09,表示tab字符
- \r\n是\x0d\x0a
- \x30~\x39 字符0~9,\x31是字符1
- \x41对应十进制65,表示A
- \x61对应十进制97,表示a
注意:这里的1指定是字符1,不是数字1
# coding: utf-8 a = '\x00' print(a,type(a),len(a)) #C 语言中,字符串尾部都有结束符,就是 null 字符,长度多个 1 c = '\t' # '\x09' 1 个字符 d = '\r\n' # 回车换行 '\x0d0a' \r \x0d \n \x0a e = '\x20' # 空格 #\x31 49 字符1 , \x41 65 A, \x61 97 a print('aAa' > 'aA') # true,使用相同的编码逐字节比较
UTF-8、GBK都兼容了ASCII
# coding: utf-8 print('a\x09b\x0d\x0ac \x31\x41\x61') # 表示什么? print('A' > 'a') # 谁大? #a\tb\r\nc 1Aa #False
兼容 ascii gb2312 -> gbk 双字节 unicode iso 兼容 ascii,完成双字节把世界已知字符装进去 str 在字符的世界中,是有编码的,要查编码表 bytes 在字节的世界中,只有一个个字节,没有编码。 latin-1 isolate859-1 互联网时代来了 传输数据,字节,utf-8,变字长的编码1~6字节表示 ascii 单字节;中文字符绝大多数落在 3 个字节上,一些特殊符号需要 4 个字节,mysql utf8mb4 就是包含了特殊字节。 在网络传输中可以做压缩,字符的压缩比非常大。
字节序列
Python3 引入两个新的类型bytes、bytearray。
bytes 不可变 字节序列;bytearray是 可变 字节数组。
bytes
bytes初始化
- bytes() 空bytes
- bytes(int) 指定字节的bytes,被0填充
- bytes(iterable_of_ints) -> bytes [0,255]的int组成的可迭代对象
- bytes(string, encoding[, errors]) -> bytes 等价于string.encode()
- bytes(bytes_or_buffer) -> immutable copy of bytes_or_buffer 从一个字节序列或者buffer复制出一个新的不可变的bytes对象
- 使用b前缀定义
- 只允许基本ASCII使用字符形式
b'abc9' - 使用16进制表示
b"\x41\x61"
- 只允许基本ASCII使用字符形式
bytes类型和str类型类似,都是不可变类型,操作方法类似。
print(b'abcd'[2]) # 返回int,指定是本字节对应的十进制数 x = b'\t\x09' print(x, len(x)) y = br'\t\x09' print(y, len(y))
范例:
# coding: utf-8 b1 = bytes() # b'' 空字节,不可变类型,不可修改 b2 = b'' #bytes(int) 指定字节的bytes,被0填充 b3 = bytes(5) # 一旦定义不可变 print(b3) #: b'\x00\x00\x00\x00\x00' b3 = b'\x00\x00\x00\x00\x00' #bytes(string, encoding[, errors]) -> bytes 等价于string.encode() b4 = bytes('abc', 'utf-8') b4 = b'abc' b4 = 'abc'.encode() # utf-8 print(b4) #: b'abc' #bytes(iterable_of_ints) -> bytes [0,255]的int组成的可迭代对象 b6 = bytes(range(10)) print(b6) b6 = bytes(range(0x30, 0x3a)) print(b6) print(bytes(range(65, 91))) print(bytes(range(65+0x20, 91+32))) #: b'\x00\x01\x02\x03\x04\x05\x06\x07\x08\t' #: b'0123456789' #: b'ABCDEFGHIJKLMNOPQRSTUVWXYZ' #: b'abcdefghijklmnopqrstuvwxyz' b8 = bytes(range(65, 69)) print(b8[0]) for i in b8: print(type(i), 8) #: 65 #<class 'int'> 8 #<class 'int'> 8 #<class 'int'> 8 #<class 'int'> 8 #bytes(bytes_or_buffer) -> immutable copy of bytes_or_buffer 从一个字节序列或者buffer复制出一个新的不可变的bytes对象 #包装,包装bytes创建出新bytes print(bytes(b'\x41')) #b'A'
索引
print(b'abcd'[2]) #返回 int,指定是本字节对应的十进制数
bytes 操作方法
bytes 和 str 类似,它们都是不可变类型,操作方法几乎一样。只不过要注意的是, str 的方法操作的是 str 类型数据,而 bytes 的方法操作的是 bytes 类型数据。
范例:
print(b'a' + b'bc') print(b'a' in b'abc') print(b'abc'.index(b'a')) print(b'abcddabc'.replace(b'abc', b'***')) #: b'abc' #: True #: 0 #: b'***dd***'
类方法构造
bytes 就是字节序列,最好书写的方式就是 16 进制的字符串表达,例如 '6162 61 6b',这个字符串中的空格将被忽略。
# coding: utf-8 bytes(range(5)) # 类来构建一个 bytes 对象 print(bytes.fromhex('09 0d 0a41 42')) # 没有 bytes 对象,用类型.方法,构建一个 bytes 对象,写字符串 16 进制表达 #: b'\t\r\nAB'
十六进制表达
一个 bytes 对象,就是一个个字节的序列,完全可以把每个字节用 16 进制表示
# coding: utf-8 print('abcde'.encode().hex()) #返回字符串 #: 6162636465
bytearray
bytearray初始化
- bytearray() 空bytearray
- bytearray(int) 指定字节的bytearray,被0填充
- bytearray(iterable_of_ints) -> bytearray [0,255]的int组成的可迭代对象
- bytearray(string, encoding[, errors]) -> bytearray 近似string.encode(),不过返回可变对象
- bytearray(bytes_or_buffer) 从一个字节序列或者buffer复制出一个新的可变的bytearray对象
范例:
# coding: utf-8 print(bytearray()) # 可变的,像数组, list print(bytearray(b'')) #: bytearray(b'') #: bytearray(b'') print(bytearray('abc'.encode())) print(bytearray('abc', 'gbk')) #: bytearray(b'abc') #: bytearray(b'abc') print(bytearray(5)) print(bytearray(range(65,70))) #: bytearray(b'\x00\x00\x00\x00\x00') #: bytearray(b'ABCDE')
b前缀表示的是bytes,不是bytearray类型
索引
# coding: utf-8 a = bytearray(range(65, 70)) print(a[2]) # 返回 int,指定是本字节对应的十进制数中 #: 67 a[0] = 0x63 for i in a: print(type(i), i) #: <class 'int'> 99 #: <class 'int'> 66 #: <class 'int'> 67 #: <class 'int'> 68 #: <class 'int'> 69 print(a) #: bytearray(b'cBCDE')
bytearray 操作方法
由于bytearray类型是可变数组,所以,类似列表。
- append(int) 尾部追加一个元素
- insert(index, int) 在指定索引位置插入元素
- extend(iterable_of_ints) 将一个可迭代的整数集合追加到当前bytearray
- pop(index=-1) 从指定索引上移除元素,默认从尾部移除
- remove(value) 找到第一个value移除,找不到抛ValueError异常
- 注意:上述方法若需要使用int类型,值在[0, 255]
- clear() 清空bytearray
- reverse() 翻转bytearray,就地修改
# coding: utf-8 b = bytearray() b.append(97) b.append(99) b.insert(1,98) b.extend([65,66,67]) print(b) #: bytearray(b'abcABC') b.remove(66) b.pop() b.reverse() print(b) # 输出什么 b.clear() #: bytearray(b'Acba')
类方法构造
bytearray 就是字节数组,最好书写的方式就是 16 进制的字符串表达,例如 '6162 6a 6b',这个字符串中的空格将被忽略。
# coding: utf-8 x = bytearray.fromhex('09 0d 0a41 42') print(x) #: bytearray(b'\t\r\nAB') x.append(49) print(x) #: bytearray(b'\t\r\nAB1')
十六进制表达
一个 bytearray 对象,就是一个个字节的序列,完全可以把每个字节用 16 进制表示
# coding: utf-8 x = bytearray.fromhex('616263 6a 6b') x.append(49) print(x.hex()) #返回字符串 #: 6162636a6b31
字节序
字符串采用了大端模式 Big endian,尾巴字符往高地址放。
int 类型,C 语言
- 1 字节,无所谓大小端
- 2 字节,0x61 62 63 整数类型,还需要知道大小端问题,也就是字节序。
内存中对于一个超过一个字节数据的分布方式
int i = 450 = 2^8 + 2^7 + 2^6 +2 = 0x000001C2 C2 认为是尾巴 LSB Little endian 11000010|00000001|00000000|00000000| 尾巴放在低地址端,就是小端模式 C2 01 00 00 LSB: Least Significant Bit,最低有效位 lower --> address highter MSB Big endian 00000000|00000000|00000001|11000010| 尾巴放在大地址端,就是大端模式 00 00 01 C2 MSB: Most Significant Bit,最高有效位
内存地址向右越大
- 大端模式,big-endian;小端模式, little-endian
- Intel X86 CPU 使用小端模式
- 网络传输更多使用大端模式
- windows、linux 使用小端模式
- Mac OS 使用大端模式
- Java 虚拟机是大端模式
int 和 byte 互转
int.from_bytes(bytes, byteorder)
- 按照指定字节序,将一个字节序列表示成整数
int.to_bytes(length, byteorder)
- 按照指定字节序,将一个整数表达成一个指定长度的字节序列
范例:
# coding: utf-8 a = 0x616263 print(type(a),hex(a),a) #: <class 'int'> 0x616263 6382179 # int 转 bytes print(a.to_bytes(3, 'big')) # int --> bytes big大端模式 #: b'abc' #解码 print(a.to_bytes(3,'big').decode()) # int --> bytes -->decode() str #: abc # bytes 转 int print(int.from_bytes(b'abc', 'big')) #bytes --> int print(hex(int.from_bytes(b'abc', 'big'))) #bytes --> int #: 6382179 #: 0x616263 b = bytearray() b.append(0x61) b.extend(b'bc') print(b) print(hex(int.from_bytes(b, 'big'))) #: bytearray(b'abc') #: 0x616263
线性结构
线性结构特征:
- 可迭代 for … in
- 有长度,通过len(x)获取,容器
- 通过整数下标可以访问元素。正索引、负索引
- 可以切片
已经学习过的线性结构:list、tuple、str、bytes、bytearray
切片
把索引范围的描述叫切片。
sequence[start:stop] # 前包后不包 sequence[start:stop:step]
- 通过给定的索引区间获得线性结构的一部分数据
- start、stop、step为整数,可以是正整数、负整数、零
- start为0时,可以省略
- stop为末尾时,可以省略
- step为1时,可以省略
- 切片时,索引超过上界(右边界),就取到末尾;超过下界(左边界),取到开头
# coding: utf-8 x = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] print(x[0:], x[:]) #全部 print(x[1:]) # 掐头 print(x[:-1], x[0:-1]) # 去尾 print(x[1:-1]) # 掐头去尾 print(x[3:]) print(x[3:-1]) # print(x[9:]) print(x[:9]) print(x[9:-1]) print(x[:100]) # 可以超界 print(x[-100:], x[-1000::1]) # 默认步长为1 print(x[4:-2]) print(x[-4:-2]) print('0123456789'[-4:8]) print(b'0123456789'[-4:8]) print(bytearray(b'0123456789')[-10:5]) # 步长 x = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] print(x[::], x[:], x[::1]) # 等价,默认步长为 1 print(x[::-1]) # 真的逆序了,但 x 不变,返回全新的 print(x[::2]) print(x[2:8:3]) print(x[:9:3]) print(x[1::3]) print(x[-10:8:2]) # 起止和方向 x = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] print(x[-10:]) print(x[-5:6]) print(x[-5:-6]) print(x[6:5]) print(x[5:5]) print(x[1:9:-2]) print(x[::-2]) print(x[8::-2]) print(x[8:2:-2]) print(x[8:-10:2]) print(x[8:-10:-2]) print(x[-5:4:-1]) print(x[-5:5:-1])
在序列上使用切片[start:stop],子区间索引范围[start, stop),相当于从start开始指向stop的方向上获取数据
默认step为1,表示向右;步长为负数,表示向左
如果子区间方向和步长方向不一致,直接返回当前类型的"空对象"
如果子区间方向和步长方向一致,则从起点间隔步长取值
| 内建函数 | 函数签名 | 说明 |
| id | id(object) | CPython中返回对象的内存地址,可以用来判断是不是同一个对象 |
# 使用id看地址,要注意地址回收复用问题 print(id([1,2,3])) print(id([4,5,6,7])) # 上下两句可能内存地址一样,但是上面那个[1,2,3]没有意义,因为它用完之后,引用计数为0了,没人能再次访问到,释放了内存 # 如果2个存在在内存中的对象,地址一样一定是同一个对象
本质
# coding: utf-8 x = [0, 1, 2] y = x[:] print(x, y) print(id(x), id(y)) x[0] = 100 print(x ==y, x, y) #[0, 1, 2] [0, 1, 2] #1548029799232 1548029797120 #False [100, 1, 2] [0, 1, 2] #切片是浅拷贝 x = [[1]] * 5 y = x print(x == y, x is y) z = y[:] print(z) x[0][0] = 300 print(z) print(id(x), id(y), id(z)) #True True #[[1], [1], [1], [1], [1]] #[[300], [300], [300], [300], [300]] #2049030455872 2049030455872 2049030038272 x = [[1]] y = x[:] print(x, y) print(x == y) print(id(x), id(y), x is y) x[0][0] = 100 print(x, y) print(x == y) print(x is y) x[0] = 200 print(x == y) # ? print(x, y) #[[1]] [[1]] #True #2049030455936 2049030456000 False #[[100]] [[100]] #True #False #False #[200] [[100]]
上例可知,实际上切片后得到一个全新的对象。 [:] 或 [::] 相当于copy方法。
切片赋值
范例:切片赋值,只能用可迭代对象赋值
# coding: utf-8 a = list(range(5)) t = list() t[:] = a print(t ==a, t is a,t) #: True False [0, 1, 2, 3, 4] t[1:2] = (50,) print(t) t[1:] = range(10,20) # 覆盖加扩展 print(t) #: [0, 50, 2, 3, 4] #: [0, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19] t[1:8] = [20] #覆盖 print(t) #: [0, 20, 17, 18, 19]
切片贬值用作初始化相当于 copy。
切片赋值好吗? 为什么?
确实方便,对于顺序表list,挪动,效率比较低。
练习
解决猴子吃桃问题
猴子第一天摘下若干个桃子,当即吃了一半,还不过瘾,又多吃了一个。第二天早上又将剩下的桃子吃掉一半,又多吃了一个。以后每天早上都吃了前一天剩下的一半零一个。到第 10 天早上想吃时,只剩下一个桃子了。
求第一天共摘多个个桃子?
- 求杨辉三角第 n 行第 k 列的值
数字统计。
要求: 每个数字取值范围[1,20];统计重要的数字有几个?分别是什么?;统计不重复的数字有几个?分别是什么?;举例: 11,7,5,11,6,7,4,其中 2 个数字 7 和 11 重复了,3 个数字4、5、6没有重复。
解决猴子吃桃问题
猴子第一天摘下若干个桃子,当即吃了一半,还不过瘾,又多吃了一个。第二天早上又将剩下的桃子吃掉一半,又多吃了一个。以后每天早上都吃了前一天剩下的一半零一个。到第 10 天早上想吃时,只剩下一个桃子了。
求第一天共摘多个个桃子?
假设猴子摘了 x 个桃子 d1 x/2 -1 d2 d1/2 -1 d3 d2/2 -1 ... d9 d8/2 -1 d10 1
# coding: utf-8 peach = 1 for i in range(9): #第 9 天吃完只剩下一个 peach = 2 * (peach+1) print(peach) #: 1534
求杨辉三角第 n 行第 k 列的值
# coding: utf-8 # 杨辉三角 n 行的 k 列是什么 m = 5 k = 2 pre = None for i in range(5): row = [1] * (i+1) print(row) print('-' * 30) #: [1] #: [1, 1] #: [1, 1, 1] #: [1, 1, 1, 1] #: [1, 1, 1, 1, 1] #: ------------------------------
# coding: utf-8 # 杨辉三角 n 行的 k 列是什么 m = 5 k = 2 pre = None for i in range(5): row = [1] * (i+1) for j in range(i-1): row[j+1] = pre[j] + pre[j+1] print(row) pre = row print('-' * 30) print(pre[k-1]) #: [1] #: [1, 1] #: [1, 2, 1] #: [1, 3, 3, 1] #: [1, 4, 6, 4, 1] #: ------------------------------ #: 4
# coding: utf-8 # 杨辉三角 n 行的 k 列是什么 # 解法1:比较笨,要第几行,就计算第几行 m = 5 k = 2 pre = None for i in range(5): row = [1] * (i+1) for j in range(i//2): row[j+1] = pre[j] + pre[j+1] print(row) pre = row print('-' * 30) #[1] #[1, 1] #[1, 2, 1] #[1, 3, 1, 1] #[1, 4, 4, 1, 1] #------------------------------ for i in range(5): row = [1] * (i+1) for j in range(1, i//2+1): value= pre[j] + pre[j-1] row[j] = value if i != 2*j: row[-j-1] = value print(row) pre = row print('-' * 30) print(pre[k-1]) #: [1] #: [1, 1] #: [1, 2, 1] #: [1, 3, 3, 1] #: [1, 4, 6, 4, 1] #: ------------------------------ #: 4
# coding: utf-8 # 第 n 行的m个数可表示为 C(n-1, m-1),即为从n-1个不同元素中取m-1个元素的组合数 # 第 n 行的m个数可表示为 C(m-1, k-1),即为从m-1个不同元素中取k-1个元素的组合数 # m 个不同元素中取出k个元素的组合数。用符号c(m,k)表示 # c(m, k) = m!/(k! * (m-k)!) m = 9 k = 3 n = m - 1 r = k - 1 # d = n- r = m - 1 - (k -1) = m -k d = m - k # c(n, r) = c(8, 2) # ?如何计算 28 = 8! / (2! * 6!) # 2! = 1 * 2 # 6! = 2! * 3 * 4 * 5 * 6 # 8! = 6! * 7 * 8 # r 和 d 有可能相等, r 或 d 可以和n相等 # 也就是说算8的阶乘的时候,就可以捎带着把2和6阶乘计算了 factorial = 1 targets = [] for i in range(1, n+1): factorial *= i #print(factorial, i) if i == d: targets.append(factorial) if i == r: targets.append(factorial) if i == n: targets.append(factorial) value = targets[2] // (targets[0] * targets[1]) print(value) print(targets) #: 28 #: [2, 720, 40320]
数字统计
要求: 每个数字取值范围[1,20];统计重要的数字有几个?分别是什么?;统计不重复的数字有几个?分别是什么?;举例: 11,7,5,11,6,7,4,其中 2 个数字 7 和 11 重复了,3 个数字4、5、6没有重复。
# coding: utf-8 nums = [5,14,18,17,16,16,13,16,5] # 9 #1 counter = [0] * 21 # 值域 [1, 20] #2 先排序,[5,5,13,14,16,16,17,18] 时间复杂度高 #3 字典,目前大多数人可以掌握的方法,简单 #4 今天要用列表的技巧 print(nums) length = len(nums) counter = [0] * length samenums = [] diffnums = [] for i in range(length): if counter[i] == 1: continue flag = False # 没有相同值 for j in range(i+1, length): if counter[j] == 1: continue if nums[i] == nums[j]: flag = True counter[j] = 1 if flag: counter[i] = 1 samenums.append(nums[i]) else: diffnums.append(nums[i]) print(counter) print(samenums) print(diffnums) #: [5, 14, 18, 17, 16, 16, 13, 16, 5] #: [1, 0, 0, 0, 1, 1, 0, 1, 1] #: [5, 16] #: [14, 18, 17, 13]
# coding: utf-8 nums = [5,14,18,17,16,16,13,16,5] # 9 #1 counter = [0] * 21 # 值域 [1, 20] #2 先排序,[5,5,13,14,16,16,17,18] 时间复杂度高 #3 字典,目前大多数人可以掌握的方法,简单 #4 今天要用列表的技巧,效率并不高 print(nums) length = len(nums) counter = [0] * length samenums = [] diffnums = [] for i in range(length): if counter[i] !=0: continue count = 0 # 假设没有和它重复的 for j in range(i+1, length): if counter[j]: continue if nums[i] == nums[j]: count += 1 counter[j] = count if count: # != 0 count += 1 counter[i] = count samenums.append((nums[i], count)) else: diffnums.append(nums[i]) print(counter) print(samenums) print(diffnums) #: [5, 14, 18, 17, 16, 16, 13, 16, 5] #: [2, 0, 0, 0, 3, 1, 0, 2, 1] #: [(5, 2), (16, 3)] #: [14, 18, 17, 13]
Ipython 使用
Ipython 是增强的CPython,尤其是交互体验。该项目还提供了 Jupyter Notebook。
官方网站: https://ipython.org/
帮助
- ?:Ipython 概述和简介
- help(name):查询指定名称的帮助
- obj?:列出对象的详细帮助
- obj??:如果可以,则列出更加详细的帮助
范例:
help(int)
int?
int??
特殊变量
Ipython 内部提供了非常多的内建变量,或许能用到的如下
_ :上一次的 out 值 __ :倒数第 2 次的 out 值 ___ :倒数第 3 次的 out 值 _oh :输出的历史 _dh :目录的历史,切换过多少。 ~cd~ 回到家目录
shell 命令
提前安装 cygwin 环境
- !COMAND:调用当前 shell 环境命令
!ls -l !touch a.txt file = !ls -l |grep py
魔术方法
IPython内置的特殊方法,使用%百分号开头的
- % 开头是 line magic
- %% 开头是 cell magic,notebook的cell
行魔术方法
cd 是 %cd 的快捷方法 ls 是 %ls 的快捷方法 pwd 是 %pwd 的快捷方法 #定义别名 %alias ll ls -l # 定义 ll 为 ls -l 别名
cell magic
%%js 或者 %%javascript 在当前 cell 中运行 js 脚本
%%js
alert('a'+1)
%timeit statement -n 一个循环loop执行语句多少次 -r 循环执行多少次loop,取最好的结果 %%timeit setup_code code..... # 下面写一行,列表每次都要创建,这样写不好 %timeit (-1 in list(range(100))) # 下面写在一个cell中,写在setup中,列表创建一次 %%timeit l=list(range(1000000)) -1 in l
def prime():
x = 12577
count = 0
for i in range(2, int(x ** 0.5) +1:
if x % i == 0:
break
else:
count = 1
# 可以写成下面 2 种之一
%timeit prime()
%%timeit
prime()
python 数据结构-非线性数据结构
集合set,字典都是哈希表实现。
集合Set
集合,简称集。由任意个元素构成的集体。高级语言都实现了这个非常重要的数据结构类型。
Python中,它是 可变的、无序的、不重复 的元素的集合。
初始化
- set() -> new empty set object
- set(iterable) -> new set object
s1 = set() s2 = set(range(5)) s3 = set([1, 2, 3]) s4 = set('abcdabcd') s5 = {} # 这是什么? 字典 s6 = {1, 2, 3} # 集合 set s7 = {1, (1,)} #s8 = {1, (1,), [1]} # ? #报错,元素,不可以是不可 hash 类型
元素性质
- 去重:在集合中,所有元素必须相异
- 无序:因为无序,所以
不可索引 - 可哈希:Python集合中的元素必须可以hash,即元素都可以使用内建函数hash
- 目前学过不可hash的类型有:list、set、bytearray
- 可迭代:set中虽然元素不一样,但元素都可以迭代出来
范例
# coding: utf-8 print({'a', 'b', 'c', 'd', 'a', 'a', 'b', 'b'}) # 去重 #: {'c', 'd', 'b', 'a'} print({'a', 1, 1.2, True, None, b'12', range(5), (1,)}) #元素,不可以是不可 hash 类型 #: {1, 1.2, None, 'a', range(0, 5), (1,), b'12'} for i in {'a', 'b', 'e', 'a'}: print(i, hash(i)) #: a -1845824050094026799 #: b 8156587031893591034 #: e -1292561222035631597
增加
- add(elem)
- 增加一个元素到set中
- 如果元素存在,什么都不做
- update(*others)
- 合并其他元素到set集合中来
- 参数others必须是可迭代对象
- 就地修改
s = set() s.add(1) s.update((1,2,3), [2,3,4])
删除
- remove(elem)
- 从set中移除一个元素
- 元素不存在,抛出KeyError异常。为什么是KeyError?
- discard(elem)
- 从set中移除一个元素
- 元素不存在,什么都不做
- pop() -> item
- 移除并返回任意的元素。为什么是任意元素?
- 空集返回KeyError异常
- clear()
- 移除所有元素
# coding: utf-8 s = set(range(10)) s.remove(0) # 非常好, set 非线性, remove 效率极高 O(1),原理是 hash 值对应。 #s.remove(11) # KeyError 给的 key 找不到,key 唯一不重复的值 O(1) #[].remove('a') # ValueError 给的值找不到,遍历 s.discard(11) # 有就移除,没有不报错 s.pop() # 无序的集合,弹任意元素 s.clear() #清空,标记。相应使用的对象引用计数为0
修改
集合类型没有修改。因为元素唯一。如果元素能够加入到集合中,说明它和别的元素不一样。
所谓修改,其实就是把当前元素改成一个完全不同的元素,就是删除加入新元素。
索引
非线性结构,不可索引。
遍历
只要是容器,都可以遍历元素。但是效率都是O(n)
范例:
# coding: utf-8 s = set(range(5)) for x in s: print(type(x), x)
成员运算符in
print(10 in [1, 2, 3]) print(10 in {1, 2, 3})
上面2句代码,分别在列表和集合中搜索元素。如果列表和集合的元素都有100万个,谁的效率高?
in 在列表中使用效率不高,列表是顺序表结构,in 相当于在做 index 或者 find,从前向后找找到才能返回 true 或 false,时间复杂度 O(n)
in 在集合中使用效率高,时间复杂度是 O(1)。
set和线性结构比较
结果说明,集合性能很好。为什么?
- 线性数据结构,搜索元素的时间复杂度是O(n),即随着数据规模增加耗时增大
- set、dict使用hash表实现,内部使用hash值作为key,时间复杂度为O(1),查询时间和数据规模无关,不会随着数据规模增大而搜索性能下降。
ipython 中提前初始化列表或集合,再比较效率
%%timeit a = list(range(100)) -1 in a # O(n)
%%timeit a = set(range(100)) -1 in a # O(n)
如果内存中有线程列表,需要的操作里面用到了遍历,O(n),n 规模越大,效率越低下。微秒–>毫秒。index, count
如果内存中有集合,不管数据规模多大,它的检索元素时间,不随着规模变化,O(1),效率极高。ns。
可哈希
- 数值型int、float、complex
- 布尔型True、False
- 字符串string、bytes
- tuple
- None
- 以上都是不可变类型,称为可哈希类型,hashable
set元素必须是可hash的。目前学过不可hash的类型有:list、set、bytearray
集合概念
- 全集
- 所有元素的集合。例如实数集,所有实数组成的集合就是全集
- 子集subset和超集superset
- 一个集合A所有元素都在另一个集合B内,A是B的子集,B是A的超集
- 真子集和真超集
- A是B的子集,且A不等于B,A就是B的真子集,B是A的真超集
- 并集:多个集合合并的结果
- 交集:多个集合的公共部分
- 差集:集合中除去和其他集合公共部分
并集
将两个集合A和B的所有的元素合并到一起,组成的集合称作集合A与集合B的并集
union(*others)返回和多个集合合并后的新的集合|运算符重载,等同unionupdate(*others)和多个集合合并,就地修改|=等同update
# coding: utf-8 a = {1,2,3} b = {2,3,4,5} print(a|b) # a.union(b) #: {1, 2, 3, 4, 5} a.update({1,2,3}, [range(10,11)]) print(a) #: {1, 2, 3, range(10, 11)} a |= {10,11} print(a) #: {1, 2, 3, 10, 11, range(10, 11)}
交集
集合A和B,由所有属于A且属于B的元素组成的集合
intersection(*others)返回和多个集合的交集&等同intersectionintersection_update(*others)获取和多个集合的交集,并就地修改&=等同intersection_update
# coding: utf-8 a = {1,2,3} b = {2,3,4,5} print(a&b) # #: {2, 3} c = {'a', 'b'} print(a & c) #: set() c &= a print(c) #: set()
差集
集合A和B,由所有属于A且不属于B的元素组成的集合
difference(*others)返回和多个集合的差集-等同differencedifference_update(*others)获取和多个集合的差集并就地修改-=等同difference_update
# coding: utf-8 a = {1,2,3} b = {2,3,4,5} print(a-b, b-a) # #: {1} {4, 5}
对称差集
集合A和B,由所有不属于A和B的交集元素组成的集合,记作(A-B)∪(B-A)
- symmetric_differece(other) 返回和另一个集合的对称差集
- ^ 等同symmetric_differece
- symmetric_differece_update(other) 获取和另一个集合的对称差集并就地修改
- ^= 等同symmetric_differece_update
其它集合运算
- issubset(other)、<= 判断当前集合是否是另一个集合的子集
- set1 < set2 判断set1是否是set2的真子集
- issuperset(other)、>= 判断当前集合是否是other的超集
- set1 > set2 判断set1是否是set2的真超集
- isdisjoint(other) 当前集合和另一个集合没有交集,没有交集,返回True
练习
- 共同好友
- 你的好友A\B\C,他的好友C、B、D,求共同好友
- 微信群提醒
- XXX与群里其他人都不是微信朋友关系
- 权限判断
- 有一个API,要求权限同时具备A、B、C才能访问,用户权限是B、C、D,判断用户是否能够访问该API
- 一个总任务列表,存储所有任务。一个已完成的任务列表。找出为未完成的任务
- 随机产生2组各10个数字的列表,如下要求:
- 每个数字取值范围[10,20]
- 统计20个数字中,一共有多少个不同的数字?
- 2组之间进行比较,不重复的数字有几个?分别是什么?
- 2组之间进行比较,重复的数字有几个?分别是什么?
业务中,任务ID一般不可以重复 所有任务ID放到一个set中,假设为ALL 所有已完成的任务ID放到一个set中,假设为COMPLETED,它是ALL的子集 ALL - COMPLETED => UNCOMPLETED
集合运算,用好了妙用无穷。
共同好友
- 你的好友A\B\C,他的好友C、B、D,求共同好友
# coding: utf-8 yours = {'B', 'C', 'A'} his = {'B', 'C', 'D'} print(yours & his, yours.intersection(his))
微信群提醒
- XXX与群里其他人都不是微信朋友关系
# coding: utf-8 # X与群里其他人都不是微信朋友关系,什么原理? # a, b, c, x a A; b B; c C; x 在A、B、C中找了个遍没有它 x-userid in A or x-userid in B or x-userid in C # 短路,快吗?集合的in操作本身O(1) x-userid in (A|B|C) # 这个并集有可能成为一个超大的集合,非常的耗费内容?快吗,快,但是内存占用可能大 有,反过来思考 a、b、c用户id,有没有在x的好友列表中 a in X or b in X or c in X a、b、c,把它们的id合成一个集合IDs IDs & X != set() IDs - X < IDs IDs.isdisjoint(X) == False
权限判断
- 有一个API,要求权限同时具备A、B、C才能访问,用户权限是B、C、D,判断用户是否能够访问该API
T = {A, B, C}
P = {B, C, D}
T - P == set()
T & P == T
T <= P
任务处理
- 一个总任务列表,存储所有任务。一个已完成的任务列表。找出为未完成的任务
- 任务ID不重复
# coding: utf-8 ALL = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10} print(ALL) COMPLETED = {2, 4, 6, 8, 10} UNCOMPLETED = ALL - COMPLETED print(UNCOMPLETED) #: {1, 2, 3, 4, 5, 6, 7, 8, 9, 10} #: {1, 3, 5, 7, 9}
数字统计
- 随机产生2组各10个数字的列表,如下要求:
- 每个数字取值范围[10,20]
- 统计20个数字中,一共有多少个不同的数字?
- 2组之间进行比较,不重复的数字有几个?分别是什么?
- 2组之间进行比较,重复的数字有几个?分别是什么?
# coding: utf-8 import random g1 = [] g2 = [] for i in range(10,20): g1.append(random.randint(10,20)) g2.append(random.randint(10,20)) print(g1, g2) #total = set() #total.update(g1, g2) #print(total) s1 = set(g1) s2 = set(g2) print(s1 | s2) print(s1 & s2) #相同的 print(s1 ^ s2) #对称差集
字典Dict
Dict即Dictionary,也称为 mapping 映射。
Python中,字典由任意个元素构成的集合,每一个元素称为Item,也称为Entry。这个Item是由(key,value)组成的二元组。
字典是 可变的、无序的、key不重复 的key-value 键值对 集合。
初始化
- dict(**kwargs) 使用name=value对初始化一个字典
- dict(iterable, kwarg) 使用可迭代对象和name=value对构造字典,不过可迭代对象的元素必须是一个二元结构
- dict(mapping, **kwarg) 使用一个字典构建另一个字典
字典的初始化方法都非常常用,都需要会用
# coding: utf-8 d1 = {} d11 = {'a':1, 'b': 2} d2 = dict() d3 = dict(a=100, b=200) d4 = dict(d3) # 构造另外一个字典 d5 = dict(d4, a=300, c=400) d6 = dict([('a', 100), ['b', 200], (1, 'abc')], b=300, c=400) print(d6) #: {'a': 100, 'b': 300, 1: 'abc', 'c': 400}
#coding: utf-8 # 类方法dict.fromkeys(iterable, value) d1 = dict.fromkeys(range(5)) d2 = dict.fromkeys(range(5), 0) print(d1, d2) #: {0: None, 1: None, 2: None, 3: None, 4: None} {0: 0, 1: 0, 2: 0, 3: 0, 4: 0}
元素访问
- d[key]
- 返回key对应的值value
- key不存在抛出KeyError异常
- get(key[, default])
- 返回key对应的值value
- key不存在返回缺省值,如果没有设置缺省值就返回None
- setdefault(key[, default])
- 返回key对应的值value
- key不存在,添加kv对,value设置为default,并返回default,如果default没有设置,缺省为None
#coding: utf-8 d = {'a':111, 'b': 200, 'c': 333, 'd':444, 'e': None} if d.get('e'): # 如果知道字典中有 None,就不能用这个方法 print('++++', d['e']) d.setdefault('f', 1234) print(d) d.setdefault('f', 222) #key 不存在,使用缺省值凑成 kv 对,写入字典;key 存在,相当于 get print(d) #: {'a': 111, 'b': 200, 'c': 333, 'd': 444, 'e': None, 'f': 1234} del d['f'] # 删除 kv 对 print(d) #: {'a': 111, 'b': 200, 'c': 333, 'd': 444, 'e': None}
新增和修改
- d[key] = value
- 将key对应的值修改为value
- key不存在添加新的kv对
- update([other]) -> None
- 使用另一个字典的kv对更新本字典
- key不存在,就添加
- key存在,覆盖已经存在的key对应的值
- 就地修改
d = {} d['a'] = 1 # {'a': 1} d.update(red=1) #{'a': 1, 'red': 1} d.update({'c': 3}) #{'a': 1, 'red': 1, 'c': 3} d.update([('red', 2)]) #{'a': 1, 'red': 2, 'c': 3} d.update({'red':3}, a=333,c=444,h=555) #{'a': 333, 'red': 3, 'c': 444, 'h': 555} #后面更新的占优 d.update([(1, 110), (2, 220), ('h', 556)], a=333,c=444,h=555) #{'a': 333, 'red': 3, 'c': 444, 'h': 555, 1: 110, 2: 220}
范例
d = {'x': 4, 'y': 5} d2 = {'c': 3} print(d.keys()) print(dict(zip(d.keys(), (1, 2)))) d2.update(zip(d.keys(), (1, 2))) print(d2) #输出 #: dict_keys(['x', 'y']) #: {'x': 1, 'y': 2} #: {'c': 3, 'x': 1, 'y': 2}
删除
- pop(key[, default])
- key存在,移除它,并返回它的value
- key不存在,返回给定的default
- default未设置,key不存在则抛出KeyError异常
- popitem()
- 移除并返回一个任意的键值对
- 字典为empty,抛出KeyError异常
- clear()
- 清空字典
# coding: utf-8 d = {'a': 11, 'b': 222, 'c': 333} del d # 标识符取消了,d 指向的对象引用计数减 1 。如果引用计数为 0, gc 清理 # del 引用计数 del d['a'] d.pop('b') #按 key 弹出 d.pop('h', 200) # key 不存在,返回给定的 default d.popitem() #随机弹出
遍历
1、遍历Key
for k in d: print(k) for k in d.keys(): print(k)
2、遍历Value
for v in d.values(): print(v) for k in d.keys(): print(d[k]) print(d.get(k))
3、遍历Item
for item in d.items(): print(item) print(item[0], item[1]) for k,v in d.items(): print(k, v) for k,_ in d.items(): print(k) for _,v in d.items(): print(v)
Python3中,keys、values、items方法返回一个类似一个生成器的可迭代对象
- Dictionary view对象,可以使用len()、iter()、in操作
- 字典的entry的动态的视图,字典变化,视图将反映出这些变化
- keys返回一个类set对象,也就是可以看做一个set集合。如果values都可以hash,那么items也可以看做是类set对象
Python2中,上面的方法会返回一个新的列表,立即占据新的内存空间。所以Python2建议使用iterkeys、itervalues、iteritems版本,返回一个迭代器,而不是返回一个copy
# coding: utf-8 d1 = {'a': 11, 'b': 222, 'c': 333} d2 = {'a': 2, 'b': 2, 'c': 3, 'd': 4} print( 'a' in d1.keys()) print(d1.keys() | d2.keys()) # keys 返回一个类 set 对象。可做集合运算。 #: True #: {'c', 'd', 'b', 'a'}
遍历与删除
# 错误的做法 d = dict(a=1, b=2, c=3) for k,v in d.items(): # 字典大小变化 print(d.pop(k)) # 报运行时错误
在使用keys、values、items方法遍历的时候,不可以改变字典的size
while len(d): print(d.popitem()) while d: print(d.popitem())
上面的while循环虽然可以移除字典元素,但是很少使用,不如直接clear。
# coding: utf-8 # for 循环正确删除 d = dict([('d', [4,3,2])], a=1, b=2, c=3 ) keys = [] for k,v in d.items(): if isinstance(v, list): print(k,v) v.append(1) keys.append(k) print(d) for k in keys: d.pop(k) print(d) #: d [4, 3, 2] #: {'d': [4, 3, 2, 1], 'a': 1, 'b': 2, 'c': 3} #: {'a': 1, 'b': 2, 'c': 3}
key
字典的key和set的元素要求一致
- set的元素可以就是看做key,set可以看做dict的简化版
- hashable 可哈希才可以作为key,可以使用hash()测试
- 使用key访问,就如同列表使用index访问一样,时间复杂度都是O(1),这也是最好的访问元素的方式
d = { 1 : 0, 2.0 : 3, "abc" : None, ('hello', 'world', 'python') : "string", b'abc' : '135' }
有序性
字典元素是按照key的hash值无序存储的 。
但是,有时候我们却需要一个有序的元素顺序,Python 3.6之前,使用OrderedDict类可以做到,3.6开始dict自身支持。到底Python对一个无序数据结构记录了什么顺序?
# 3.5如下 C:\Python\Python353>python Python 3.5.3 (v3.5.3:1880cb95a742, Jan 16 2017, 16:02:32) [MSC v.1900 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> d = {'a':300, 'b':200, 'c':100, 'd':50} >>> d {'c': 100, 'a': 300, 'b': 200, 'd': 50} >>> d {'c': 100, 'a': 300, 'b': 200, 'd': 50} >>> list(d.keys()) ['c', 'a', 'b', 'd'] >>> exit() C:\Python\Python353>python Python 3.5.3 (v3.5.3:1880cb95a742, Jan 16 2017, 16:02:32) [MSC v.1900 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> d = {'a':300, 'b':200, 'c':100, 'd':50} >>> d {'b': 200, 'c': 100, 'd': 50, 'a': 300}
Python 3.6之前,在不同的机器上,甚至同一个程序分别运行2次,都不能确定不同的key的先后顺序。
# 3.6+表现如下 C:\Python\python366>python Python 3.6.6 (v3.6.6:4cf1f54eb7, Jun 27 2018, 03:37:03) [MSC v.1900 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> d = {'c': 100, 'a': 300, 'b': 200, 'd': 50} >>> d {'c': 100, 'a': 300, 'b': 200, 'd': 50} >>> exit() C:\Python\python366>python Python 3.6.6 (v3.6.6:4cf1f54eb7, Jun 27 2018, 03:37:03) [MSC v.1900 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> d = {'c': 100, 'a': 300, 'b': 200, 'd': 50} >>> d {'c': 100, 'a': 300, 'b': 200, 'd': 50} >>> d.keys() dict_keys(['c', 'a', 'b', 'd'])
Python 3.6+,记录了字典key的录入顺序,遍历的时候,就是按照这个顺序 。但不表示是 key 是排序。
如果使用 d = {'a':300, 'b':200, 'c':100, 'd':50} ,就会造成以为字典按照key排序的错觉。
3.6提供的这种字典特性,还是以为字典返回的是无序的,可以在Python不同版本中考虑使用OrderedDict类来保证这种录入序。
defaultdict
# coding: utf-8 d = {} d['a'] = [] d['a'].extend(range(4)) print(d) #: {'a': [0, 1, 2, 3]}
# coding: utf-8 d = {} #d['a'] = [] d.setdefault('a', []).extend(range(4)) print(d) #: {'a': [0, 1, 2, 3]}
还有一种实现方式
Python 提供了 defaultdict类, defaultdict(default_factory) 构造一个
特殊字典,初始化是可以传入一个工厂函数,当访问一个存在的 key时,就会调
用这个工厂函数获得返回值,和 key 凑成键值对。
# coding: utf-8 from collections import defaultdict d = defaultdict(list) #{} list 函数名 d['a'].extend(range(4)) # d['a'] => KeyError => 'a':list() -> 'a': [] print(d) #defaultdict(<class 'list'>, {'a': [0, 1, 2, 3]}) d = defaultdict(set) d['b'].update(range(10, 15)) #KeyError => 'b': set() print(d) #defaultdict(<class 'set'>, {'b': {10, 11, 12, 13, 14}})
# coding: utf-8 d = {} for k in 'abcd': for v in range(3): if k not in d.keys(): d[k] = [] d[k].append(v) print(d) from collections import defaultdict d = defaultdict(list) for k in 'abcd': for v in range(3): d[k].append(v) print(d) #: {'a': [0, 1, 2], 'b': [0, 1, 2], 'c': [0, 1, 2], 'd': [0, 1, 2]} #: defaultdict(<class 'list'>, {'a': [0, 1, 2], 'b': [0, 1, 2], 'c': [0, 1, 2], 'd': [0, 1, 2]})
练习
- 用户输入一个数字
- 打印每一位数字及其重复的次数
- 数字重复统计
- 随机产生 100 个整数
- 数字范围 [-1000, 1000]
- 升序输出这个数字并打印其重复的次数
- 字符串重复统计
- 字符表 'abcdefghigklmnopqrstuvwxyz'
- 随挑选 2 个字母组成字符串,共挑选 100 个
- 降序输出所有不同的字符串及重复的次数
重复统计
- 用户输入一个数字
- 打印每一位数字及其重复的次数
# coding: utf-8 #num = input('>>>').strip().lstrip('0+-') # 1223330 num = '1223330' #统计的,优先想到使用字典 counter = {} for x in num: if x not in counter.keys(): counter[x] = 0 counter[x] += 1 print(counter) counter = {} for x in num: counter[x] = counter.get(x, 0) + 1 print(counter) counter = {} for x in num: counter[x] = counter.setdefault(x, 0) + 1 print(counter) from collections import defaultdict counter = defaultdict(lambda :0) # list list() for x in num: counter[x] += 1 #kv不存在时 x:fn() => x:0 print(counter)
数字重复统计
- 随机产生 100 个整数
- 数字范围 [-1000, 1000]
- 升序输出这个数字并打印其重复的次数
# coding: utf-8 import random n = 10 nums = [None] * n for i in range(n): nums[i] = random.randint(-1000, 1000) #统计 counter = {} for x in nums: counter[x] = counter.get(x, 0) + 1 #升序打印数字及其重复次数 print(sorted(counter.items()))
字符串重复统计
- 字符表 'abcdefghigklmnopqrstuvwxyz'
- 随挑选 2 个字母组成字符串,共挑选 100 个
- 降序输出所有不同的字符串及重复的次数
生成字符表
# coding: utf-8 alphabet = 'abcdefghijklmnopqrstuvwxyz' print(alphabet) import string alphabet = string.ascii_lowercase print(alphabet) alphabet = bytes(range(0x61, 123)).decode() print(alphabet) #: abcdefghijklmnopqrstuvwxyz #: abcdefghijklmnopqrstuvwxyz #: abcdefghijklmnopqrstuvwxyz
取字符
# coding: utf-8 import random alphabet = 'abcdefhijklmnopqrstuvwxyz' print("".join(random.sample(alphabet, k=2))) print("".join(random.choices(alphabet, k=2))) # >=3.6 print(random.choice(alphabet) + random.choice(alphabet)) print(chr(random.randint(97,122)) + chr(random.randint(97,122))) #: ok #: bx #: ox #: nz
# coding: utf-8 import random alphabet = 'abcdefghijklmnopqrstuvwxyz' print(alphabet) words = [] for i in range(100): #words.append(random.choice(alphabet) + random.choice(alphabet)) words.append(chr(random.randint(97,122)) + chr(random.randint(97,122))) #words.append("".join(random.sample(alphabet, k=2))) #words.append("".join(random.choices(alphabet, k=2))) # >=3.6 print(words) counter = {} for word in words: counter[word] = counter.get(word, 0) + 1 print(sorted(counter.items(), reverse=True))
封装和解构
基本概念
# coding: utf-8 t1 = 1, 2 # 封装 print(type(t1)) # 什么类型 print(t1) #: <class 'tuple'> #: (1, 2) x, y = t1 #解构 print(x, y) #: 1 2 t2 = (1, 2) print(type(t2))
Python等式右侧出现逗号分隔的多值的时候,就会将这几个值封装到元组中。这种操作称为封装packing。
x, y = 1, 2 # 右边先封装成元组(1,2),然后为了赋值 x 和 y,解构后,依次对应标识符 print(x) # 1 print(y) # 2
Python中等式右侧是一个容器类型,左侧是逗号分隔的多个标识符,将右侧容器中数据的一个个和左侧标识符一一对应。这种操作称为解构unpacking。
从Python3开始,对解构做了很大的改进,现在用起来已经非常的方便快捷。
封装和解构是非常方便的提取数据的方法,在Python、JavaScript等语言中应用极广。
# 交换数据 x = 4 y = 5 temp = x #中间变量 x = y y = temp # 封装和解构,交换 x = 10 y = 11 x, y = y, x
简单解构
# 左右个数相同 a,b = 1,2 a,b = (1,2) a,b = [1,2] a,b = [10,20] a,b = b'xy' a,b = {10,20} # 非线性结构,但没有顺序 a,b = {'a':10,'b':20} # 非线性结构也可以解构,3.6 后 a='a' b='b' [a,b] = (1,2) [a,b] = 10,20 (a,b) = {30,40}
那么,左右个数不一致可以吗?
a, b = (10, 20, 30) # 不可以,左右两边要一一对就应
剩余变量解构
在Python3.0中增加了剩余变量解构(rest)。
a, *rest, b = [1, 2, 3, 4, 5] print(a, b) print(type(rest), rest) # <class 'list'> [2, 3, 4]
标识符rest将尽可能收集剩余的数据组成一个列表。
# coding: utf-8 a, *rest = [1, 2, 3, 4, 5] # rest有*,尽可能收集数字到一个列表中 print(a, rest) #: 1 [2, 3, 4, 5] *rest, b = [1, 2, 3, 4, 5] print(rest, b) #: [1, 2, 3, 4] 5 #,*rest = [1, 2, 3, 4, 5] #报错,就一个标识符没必要这么定 #print(rest) # 内容是什么? #a, *r1, *r2, b = [1, 2, 3, 4, 5] # 报错,剩余变量只能用一次
丢弃变量
# coding: utf-8 a, *_, b = [1, 2, 3, 4, 5] print(_) # 在IPython中实验,_是最后一个输出值,这里将把它覆盖 #: [2, 3, 4] _, *b, _ = [1, 2, 3] print(_) # 第一个_是什么 print(b) # 是什么 print(_) # 第二个_是什么 #: 3 #: [2] #: 3
_ 是合法的标识符,这里它没有什么可读性,它在这里的作用就是表示不关心这个变量的值,我不想要。
有人把它称作 丢弃(Throwaway)变量。
其它结构
x = [range(5)] y = [*range(5)] z = list(range(5)) print(x, y, z) #: [range(0, 5)] [0, 1, 2, 3, 4] [0, 1, 2, 3, 4]
练习
- 从nums = [1, (2, 3, 4), 5]中,提取其中4出来
- 从list(range(10))中,提取第二个、第四个、倒数第二个元素
- 环境变量JAVA_HOME=/usr/bin,返回环境变量名和路径
# coding: utf-8 #- 从nums = [1, (2, 3, 4), 5]中,提取其中4出来 nums = [1, (2,3,4), 5] _, (*_, num), _ = nums print(num) #- 从list(range(10))中,提取第二个、第四个、倒数第二个元素 _, a, _, b, *_, c, _ =list(range(10)) print(a, b, c) #- 环境变量JAVA_HOME=/usr/bin,返回环境变量名和路径 name, path = "JAVA_HOME=/usr/bin".split('=', maxsplit=1) print(name, path) name, sep, path = "JAVA_HOME=/usr/bin".partition('=') print(name, path)
排序算法-选择排序
简单选择排序
- 选择排序
- 每一趟两两比较大小,找出极值(极大值或极小值)并放置到有序区的位置
初始 1 9 8 5 6 7 4 3 2 第一趟 9 1 8 5 6 7 4 3 2 选择出此轮最大数9,和索引0数交换 第二趟 9 8 1 5 6 7 4 3 2 选择出此轮最大数8,和索引1数交换 第三趟 9 8 7 5 6 1 4 3 2 以此类推 第四趟 9 8 7 6 5 1 4 3 2 第五趟 9 8 7 6 5 1 4 3 2 第六趟 9 8 7 6 5 4 1 3 2 第七趟 9 8 7 6 5 4 3 1 2 第八趟 9 8 7 6 5 4 3 2 1
核心算法
- 结果可为升序或降序排列,默认升序排列
- 扩大有序区,减小无序区。
- 以降序为例
- 相邻元素依次两两比较,获得每一次比较后的最大值,并记住此值的索引。
- 每一趟都从无序中选择出最大值,然后交换到当前无序区最左端
算法实现
# coding: utf-8 #简单选择排序 nums = [1, 9, 8, 5] print(nums) length = len(nums) count_iter = 0 count_swap = 0 for i in range(length - 1): maxindex = i # i = 0 for j in range(i+1,length): count_iter += 1 if nums[j] > nums[maxindex]: maxindex = j if i != maxindex: count_swap += 1 nums[i], nums[maxindex] = nums[maxindex], nums[i] print(nums, i, maxindex) print('-' * 30) print(nums, count_iter, count_swap) #: [1, 9, 8, 5] #: [9, 1, 8, 5] 0 1 #: [9, 8, 1, 5] 1 2 #: [9, 8, 5, 1] 2 3 #: ------------------------------ #: [9, 8, 5, 1] 6 3
问题:该问题选择排序算法,是否能像冒泡排序一样,提前结束的可能? 不可以,每一趟只关心极值数的索引
变种:选择排序
# coding: utf-8 #变种:选择排序 nums = [1, 9, 8, 5] print(nums) length = len(nums) count_iter = 0 count_swap = 0 for i in range(length//2): # 2 个数需要1次;3 个数需要1次;4个数需要2次;5个数需要2次 maxindex = i # 假设最大索引就是当前索引 minindex = -i - 1 # 最小索引 minorigin = minindex # j 循环作用:记住极大值索引和极小值索引 for j in range(i+1,length): # range(2,4) 2, 3 count_iter += 1 if nums[j] > nums[maxindex]: maxindex = j if nums[minindex] > nums[-j-1]: minindex = -j-1 # 负索引 print(maxindex, minindex, '+++') if i != maxindex: count_swap += 1 nums[i], nums[maxindex] = nums[maxindex], nums[i] # 克服交换对最小值索引的干扰 if i == minindex or i == length + minindex: minindex = maxindex - length if minorigin != minindex: nums[minorigin], nums[minindex] = nums[minindex], nums[minorigin] count_swap += 1 print(nums, i, maxindex) print('-' * 30) print(nums, count_iter, count_swap) #: [1, 9, 8, 5] #: 1 -4 +++ #: [9, 5, 8, 1] 0 1 #: 2 -3 +++ #: [9, 8, 5, 1] 1 2 #: ------------------------------ #: [9, 8, 5, 1] 5 3
# coding: utf-8 #变种:选择排序 nums = [1, 9, 8, 5] print(nums) length = len(nums) count_iter = 0 count_swap = 0 for i in range(length//2): # 2 个数需要1次;3 个数需要1次;4个数需要2次;5个数需要2次 maxindex = i # 假设最大索引就是当前索引 minindex = -i - 1 # 最小索引 minorigin = minindex # j 循环作用:记住极大值索引和极小值索引 for j in range(i+1,length - i): # range(2,3) 2 count_iter += 1 if nums[j] > nums[maxindex]: maxindex = j if nums[minindex] > nums[-j-1]: minindex = -j-1 # 负索引 print(maxindex, minindex, '+++') if i != maxindex: count_swap += 1 nums[i], nums[maxindex] = nums[maxindex], nums[i] # 克服交换对最小值索引的干扰 if i == minindex or i == length + minindex: minindex = maxindex - length if minorigin != minindex: nums[minorigin], nums[minindex] = nums[minindex], nums[minorigin] count_swap += 1 print(nums, i, maxindex) print('-' * 30) print(nums, count_iter, count_swap)
二元选择排序
# coding: utf-8 #变种:选择排序 #nums = [1, 9, 8, 5] nums = [1, 1, 1, 1] print(nums) length = len(nums) count_iter = 0 count_swap = 0 for i in range(length//2): # 2 个数需要1次;3 个数需要1次;4个数需要2次;5个数需要2次 maxindex = i # 假设最大索引就是当前索引 minindex = -i - 1 # 最小索引 minorigin = minindex # j 循环作用:记住极大值索引和极小值索引 for j in range(i+1,length - i): # range(2,3) 2 count_iter += 1 if nums[j] > nums[maxindex]: maxindex = j if nums[minindex] > nums[-j-1]: minindex = -j-1 # 负索引 print(maxindex, minindex, '+++') if nums[maxindex] == nums[minindex]: break if i != maxindex: count_swap += 1 nums[i], nums[maxindex] = nums[maxindex], nums[i] # 克服交换对最小值索引的干扰 if i == minindex or i == length + minindex: minindex = maxindex - length if minorigin != minindex: nums[minorigin], nums[minindex] = nums[minindex], nums[minorigin] count_swap += 1 print(nums, i, maxindex) print('-' * 30) print(nums, count_iter, count_swap) #: [1, 1, 1, 1] #: 0 -1 +++ #: ------------------------------ #: [1, 1, 1, 1] 3 0
# coding: utf-8 #变种:选择排序 #nums = [1, 9, 8, 5] nums = [1, 1, 1, 2] print(nums) length = len(nums) count_iter = 0 count_swap = 0 for i in range(length//2): # 2 个数需要1次;3 个数需要1次;4个数需要2次;5个数需要2次 maxindex = i # 假设最大索引就是当前索引 minindex = -i - 1 # 最小索引 minorigin = minindex # j 循环作用:记住极大值索引和极小值索引 for j in range(i+1,length - i): # range(2,3) 2 count_iter += 1 if nums[j] > nums[maxindex]: maxindex = j if nums[minindex] > nums[-j-1]: minindex = -j-1 # 负索引 print(maxindex, minindex, '+++') if nums[maxindex] == nums[minindex]: break if i != maxindex: count_swap += 1 nums[i], nums[maxindex] = nums[maxindex], nums[i] # 克服交换对最小值索引的干扰 if i == minindex or i == length + minindex: minindex = maxindex - length if minorigin != minindex and nums[minindex] != nums[minorigin]: nums[minorigin], nums[minindex] = nums[minindex], nums[minorigin] count_swap += 1 print(nums, i, maxindex) print('-' * 30) print(nums, count_iter, count_swap) #: [1, 1, 1, 2] #: 3 -2 +++ #: [2, 1, 1, 1] 0 3 #: 1 -2 +++ #: ------------------------------ #: [2, 1, 1, 1] 4 1
总结
- 简单选择排序需要数据一趟趟比较,并在每一趟中发现极值
- 没有办法知道当前这一趟是否已经达到排序要求,但是可以知道极值是否在目标索引位置
- 遍历次数1,…,n-1之和n(n-1)/2
- 时间复杂度 \(O(n^2)\)
- 减少了交换次数,提高了效率,性能略好于冒泡法
解析式和生成器表达式
列表解析式
列表解析式List Comprehension,也叫列表推导式。
# 生成一个列表,元素0~9,将每一个元素加1后的平方值组成新的列表 x = [] for i in range(10): x.append((i+1)**2) print(x)
# 列表解析式,推导式 --- 表达式 print([(i+1)**2 for i in range(10)]) # 立即生成一个新列表,填充内容
语法
- [返回值 for 元素 in 可迭代对象 if 条件]
- 使用中括号[],内部是for循环,if条件语句可选
- 返回一个新的列表
列表解析式是一种语法糖
- 编译器会优化,不会因为简写而影响效率,反而因优化提高了效率
- 减少程序员工作量,减少出错
- 简化了代码,增强了可读性
范例
# coding: utf-8 # 10 以内的奇数 print([i for i in range(10) if i % 2]) print([i for i in range(10) if i % 2 == 1]) print([i for i in range(10) if i & 1]) print([i for i in range(1, 10, 2)])
复杂语法如下
[expr for item in iterable if cond1 if cond2] 等价于 ret = [] for item in iterable: if cond1: if cond2: ret.append(expr) # [expr for i in iterable1 for j in iterable2 ] 等价于 ret = [] for i in iterable1: for j in iterable2: ret.append(expr)
范例:20以内即能被2整除又能被3整除
nums = [] for i in range(20): if i % 2 == 0: if i % 3 == 0: nums.append(i) print(nums) print([i for i in range(20) if i % 2 == 0 if i % 3 ==0]) nums = [] for i in range(20): if i % 2 == 0 and i % 3 == 0: nums.append(i) print(nums) print([i for i in range(20) if i % 2 == 0 and i % 3 ==0])
范例:20以内即能被2整除或能被3整除
print([i for i in range(20) if i % 2 ==0 or i % 3 == 0]) #print([i for i in range(20) if i % 2 ==0 elif i % 3 == 0]) # 解析式中不允许出现else elif
请问下面3种输出各是什么?为什么
# coding: utf-8 # 请问下面3种输出各是什么?为什么 [(i,j) for i in range(7) if i>4 for j in range(20,25) if j>23] [(i,j) for i in range(7) for j in range(20,25) if i>4 if j>23] [(i,j) for i in range(7) for j in range(20,25) if i>4 and j>23] nums = [] for i in range(7): if i >4: for j in range(20, 25): if j > 23: nums.append((i,j)) print([(i,j) for i in range(7) if i>4 for j in range(20,25) if j>23]) print([(i,j) for i in range(7) for j in range(20,25) if i>4 if j>23]) print([(i,j) for i in range(7) for j in range(20,25) if i>4 and j>23]) #: [(5, 24), (6, 24)] #: [(5, 24), (6, 24)] #: [(5, 24), (6, 24)] #: [(5, 24), (6, 24)]
练习
- 返回1-10平方的列表
- 有一个列表lst=[1, 4, 9, 16, 2, 5, 10, 15],生成一个新列表,要求新列表元素是lst相邻2项的和
- 打印九九乘法表
- "0001.abadicddws" 是ID格式,要求ID格式是以点号分割,左边是4位从1开始的整数,右边是10位随机小写英文字母。依次生成前100个ID的列表
- 返回1-10平方的列表
print([i**2 for i in range(1,11)]) #: [1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
- 有一个列表lst=[1, 4, 9, 16, 2, 5, 10, 15],生成一个新列表,要求新列表元素是lst相邻2项的和
# coding: utf-8 lst = [1, 4, 9, 16,2, 5,10, 15] l1 = [] for i in range( len(lst)-1): # 控制边界 l1.append(lst[i] + lst[i+1]) print(l1) print([lst[i]+lst[i+1] for i in range(len(lst)-1)]) #: [5, 13, 25, 18, 7, 15, 25] #: [5, 13, 25, 18, 7, 15, 25]
- 打印九九乘法表
# coding: utf-8 for i in range(1,10): for j in range(1, i+1): print("{}*{}={:<{}}".format(j,i,j*i, 2 if j == 1 else 3), end='\n' if i == j else '') lst = [print("{}*{}={:<{}}".format(j,i,j*i, 2 if j == 1 else 3), end='\n' if i == j else '') for i in range(1,10) for j in range(1, i+1)] print(lst)
1*1=1 1*2=2 2*2=4 1*3=3 2*3=6 3*3=9 1*4=4 2*4=8 3*4=12 4*4=16 1*5=5 2*5=10 3*5=15 4*5=20 5*5=25 1*6=6 2*6=12 3*6=18 4*6=24 5*6=30 6*6=36 1*7=7 2*7=14 3*7=21 4*7=28 5*7=35 6*7=42 7*7=49 1*8=8 2*8=16 3*8=24 4*8=32 5*8=40 6*8=48 7*8=56 8*8=64 1*9=9 2*9=18 3*9=27 4*9=36 5*9=45 6*9=54 7*9=63 8*9=72 9*9=81 1*1=1 1*2=2 2*2=4 1*3=3 2*3=6 3*3=9 1*4=4 2*4=8 3*4=12 4*4=16 1*5=5 2*5=10 3*5=15 4*5=20 5*5=25 1*6=6 2*6=12 3*6=18 4*6=24 5*6=30 6*6=36 1*7=7 2*7=14 3*7=21 4*7=28 5*7=35 6*7=42 7*7=49 1*8=8 2*8=16 3*8=24 4*8=32 5*8=40 6*8=48 7*8=56 8*8=64 1*9=9 2*9=18 3*9=27 4*9=36 5*9=45 6*9=54 7*9=63 8*9=72 9*9=81 [None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None]
1*1=1 1*2=2 2*2=4 1*3=3 2*3=6 3*3=9 1*4=4 2*4=8 3*4=12 4*4=16 1*5=5 2*5=10 3*5=15 4*5=20 5*5=25 1*6=6 2*6=12 3*6=18 4*6=24 5*6=30 6*6=36 1*7=7 2*7=14 3*7=21 4*7=28 5*7=35 6*7=42 7*7=49 1*8=8 2*8=16 3*8=24 4*8=32 5*8=40 6*8=48 7*8=56 8*8=64 1*9=9 2*9=18 3*9=27 4*9=36 5*9=45 6*9=54 7*9=63 8*9=72 9*9=81 1*1=1 1*2=2 2*2=4 1*3=3 2*3=6 3*3=9 1*4=4 2*4=8 3*4=12 4*4=16 1*5=5 2*5=10 3*5=15 4*5=20 5*5=25 1*6=6 2*6=12 3*6=18 4*6=24 5*6=30 6*6=36 1*7=7 2*7=14 3*7=21 4*7=28 5*7=35 6*7=42 7*7=49 1*8=8 2*8=16 3*8=24 4*8=32 5*8=40 6*8=48 7*8=56 8*8=64 1*9=9 2*9=18 3*9=27 4*9=36 5*9=45 6*9=54 7*9=63 8*9=72 9*9=81 [None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None]
- "0001.abadicddws" 是ID格式,要求ID格式是以点号分割,左边是4位从1开始的整数,右边是10位随机小写英文字母。依次生成前100个ID的列表
# coding: utf-8 print(["{:04}.{}".format( i, 'abcd') for i in range(1, 3)]) #: ['0001.abcd', '0002.abcd'] import random l1 = ["{:04}.{}".format( i, "".join( [chr(random.randint(97,123)) for i in range(10)] ) ) for i in range(1, 3)] print(l1) #: ['0001.pwjbrfpaer', '0002.ozlemkflgl'] import random l1 = ["{:04}.{}".format( i, "".join( # 在某一个函数中,如果只需要一个参数,可迭代对象,如果要用生成器表达式 # 可以去除两边的小括号 #(chr(random.randint(97,123)) for i in range(10)) #生成器表达式 chr(random.randint(97,123)) for i in range(10) #生成器表达式 ) ) for i in range(1, 3)] print(l1) import random import string l2 = ["{:04}.{}".format( i, "".join( random.choice(string.ascii_lowercase) for i in range(10) #生成器表达式 ) ) for i in range(1, 3)] print(l2) #: ['0001.kfotfrtaks', '0002.iuiryhdzvq'] import random import string l2 = ["{:04}.{}".format( i, "".join( random.choices(string.ascii_lowercase, k=10) #生成器表达式 ) ) for i in range(1, 3)] print(l2)
生成器表达式
中括号换成小括号就可以了
语法
- (返回值 for 元素 in 可迭代对象 if 条件)
- 列表解析式的中括号换成小括号就行了
- 返回一个生成器对象
和列表解析式的区别
- 生成器表达式是 按需计算 (或称 惰性求值 、 延迟计算 ),需要的时候才计算值
- 列表解析式是立即返回值
生成器对象
可迭代对象迭代器
| 生成器表达式 | 列表解析式 |
| 延迟计算 | 立即计算 |
| 返回可迭代对象迭代器,可以迭代 | 返回可迭代对象列表,不是迭代器 |
| 只能迭代一次 | 可反复迭代 |
范例
# coding: utf-8 a = [i+1 for i in range(5)] #生成列表 for x in a: #多次从头到尾遍历 print(x, end=' ') print('-' * 20) for x in a: print(x, end=' ') #: 1 2 3 4 5 -------------------- #: 1 2 3 4 5
# coding: utf-8 a = (i+1 for i in range(5)) #生成器表达式,得到一个生成器对象,这个对象是懒惰的 print(type(a), a) # 只能从头到尾遍历一次 for x in a: print(x, end=' ') print('-' * 20) for x in a: print(x, end=' ') #: <class 'generator'> <generator object <genexpr> at 0x000001D519ED5E40> #: 1 2 3 4 5 -------------------- b = range(5) #print(next(b)) # range 不是迭代器,是惰性求值,是可迭代对象 c = list(range(5)) #print(next(c)) # c 是列表,可迭代对象,不是惰性求值,也不是迭代器,更不是生成器对象 a = (i+1 for i in range(5)) print('*', next(a)) # next 内建函数,作用拨一下迭代器。next 还可以判断是否是迭代器 print('*', next(a)) #生成器对象内部,有指针,指向当前位置 for x in a: # for 替你拨转它 print(x, end=' ') #: * 1 #: * 2 #: 3 4 5 #print(next(a)) #StopIteration 如果迭代器已经遍历完,如果使用for就不遍历了 #如果使用 next,将抛出StopIteration异常
生成器表达式和列表解析式对比
- 计算方式
- 生成器表达式延迟计算,列表解析式立即计算
- 内存占用
- 单从返回值本身来说,生成器表达式省内存,列表解析式返回新的列表
- 生成器没有数据,内存占用极少,使用的时候,一次返回一个数据,只会占用一个数据的空间
- 列表解析式构造新的列表需要为所有元素立即占用掉内存
- 计算速度
- 单看计算时间看,生成器表达式耗时非常短,列表解析式耗时长
- 但生成器本身并没有返回任何值,只返回了一个生成器对象
- 列表解析式构造并返回了一个新的列表
集合解析式
换成大括号
语法
- {返回值 for 元素 in 可迭代对象 if 条件}
- 列表解析式的中括号换成大括号{}就变成了集合解析式
- 立即返回一个集合
{(x, x+1) for x in range(10)}
{[x] for x in range(10)} # 可以吗? 不可以,列表、集合、bytearray不可哈希
s = {(x,) for x in 'abcabc'} # 集合解析式要去重 print(s) #: {('b',), ('c',), ('a',)}
字典解析式
语法
- {key:value for 元素 in 可迭代对象 if 条件}
- 列表解析式的中括号换成大括号{},元素的构造使用key:value形式
- 立即返回一个字典
{x:y for x in 'abc' for y in range(3)}
{x:(x,x+1) for x in range(10)}
{x:[x,x+1] for x in range(10)}
{(x,):[x,x+1] for x in range(10)}
{[x]:[x,x+1] for x in range(10)} # 不可以
{str(x):y for x in range(3) for y in range(4)} # 输出多少个元素?
s = {str(0x61 + x):x**2 for x in range(1,4)} print(s) #: {'98': 1, '99': 4, '100': 9} s = {chr(0x61 + x):x**2 for x in range(1,4)} print(s) #: {'b': 1, 'c': 4, 'd': 9}
总结
- Python2 引入列表解析式
- Python2.4 引入生成器表达式
- Python3 引入集合、字典解析式,并迁移到了2.7
一般来说,应该多应用解析式,简短、高效。如果一个解析式非常复杂,难以读懂,要考虑拆解成for循环。
生成器和迭代器是不同的对象,但都是可迭代对象。
如果不需要立即获得所有可迭代对象的元素,在Python 3中,推荐使用惰性求值的迭代器。
| 内建函数 | 函数签名 | 说明 |
|---|---|---|
| sorted | sorted(iterable[,key][,reverse]) | 默认升序,对可迭代对象排序,立即返回列表 |
# 排序一定是容器内全体参与 print(sorted([1,2,3,4,5])) print(sorted(range(10, 20), reverse=True)) print(sorted({'a':100, 'b':'abc'})) print(sorted({'a':100, 'b':'abc'}.items())) print(sorted({'a':'ABC', 'b':'abc'}.values(), key=str, reverse=True)) print(sorted({'a':2000, 'b':'201'}.values(), key=str)) print(sorted({'a':2000, 'b':'201'}.values(), key=int))
时间模块和内建函数
时间模块
datetime模块
datetime类
- 时间高级类
- 类方法,用类调用的方法,由类方法获得一个时间对象
- now(tz=None)返回当前时间的datetime对象,时间到微秒,如果tz为None,返回当前时区的不带时区信息的时间
- utcnow() 不带时区的0时区时间
- fromtimestamp(timestamp,tz=None)从一个时间戳返回一个datetime对象
- 时间对象方法
- timestamp()返回一个到微秒的时间戳
- 时间戳:格林威治时间1970年1月1日0点到现在的秒数
- 构造方法 datetime.datetime(2016, 12, 6, 16, 29, 43, 79043)
- year、month、day、hour、minute、second、microsecond,取datetime对象的年月日时分秒及微秒
- weekday() 返回星期天,周一0,周日6
- isoweekday()返回星期天,周一1,周日7
- date() 返回日期date对象
- time() 返回时间time对象
- timestamp()返回一个到微秒的时间戳
范例:时区时间
# coding: utf-8 import datetime datetime.datetime # 类,抽象的概念,具体 #具体的时间,时间对象 #不带时区的时间 d1 = datetime.datetime.now() #datetime类的now方法,从类的方法上获取一个具体的时间对象 print(d1) #缺省print打印的是时间对象的一种字符串表达,给人看的 d2 = datetime.datetime.utcnow() #utc 近似认为 0 时区时间 print(d2) #8hours d3 = datetime.datetime(2018, 8, 10, 20, 30) print(d3) print(type(d1), type(d2), type(d3)) #带时区的时间 #timezone类,时区类 #timedelta类,时间差类 print(datetime.datetime.now(datetime.timezone(datetime.timedelta(hours=8)))) #: 2024-04-07 18:35:13.951021 #: 2024-04-07 10:35:13.952018 #: 2018-08-10 20:30:00 #: <class 'datetime.datetime'> <class 'datetime.datetime'> <class 'datetime.datetime'> #: 2024-04-07 18:35:13.952018+08:00
范例:时间戳
# coding: utf-8 # Unix 元年 1970年1月1日0点开始到现在的秒数 import datetime # 类的now方法构建时间对象 #时间对象.timestamp() stamp = datetime.datetime.now().timestamp() #float print(type(stamp), stamp) #: <class 'float'> 1712487038.292848 d4 = datetime.datetime.fromtimestamp(1712487038.292848) #使用时间戳 print(type(d4), d4) #: <class 'datetime.datetime'> 2024-04-07 18:50:38.292848
时期与格式化
- 类方法 strptime(date_string, format) ,返回datetime对象(时间字符串+格式化字符串=>时间对象)
- 对象方法 strftime(format) ,返回字符串(时间对象通过格式字符串=>时间字符串)
- 字符串format函数格式化(时间对象通过格式字符串=>时间字符串)
# coding: utf-8 import datetime datestr = '2018-01-10 17:16:08' dt = datetime.datetime.strptime(datestr, '%Y-%m-%d %H:%M:%S') #由字符串到时间对象 print(type(dt), dt) print(dt.strftime('%Y/%m/%d-%H:%M:%S')) #输出为字符串 print("{:%Y/%m/%d %H:%M:%S}".format(dt)) #输出为字符串 #: <class 'datetime.datetime'> 2018-01-10 17:16:08 #: 2018/01/10-17:16:08 #: 2018/01/10 17:16:08
范例:
# coding: utf-8 import datetime d4 = datetime.datetime.fromtimestamp(1712487038.292848) #使用时间戳,返回时间对象 print("{}".format(d4)) #: 2024-04-07 18:50:38.292848 print(d4.strftime('%y-%m-%d!!%H:%M:%S')) #str format time 时间对象格式化输出,字符串 #: 24-04-07!!18:50:38 #%d 日子 #%b %B 月份名称 #%m 月份 #%y 年,2位数表达; %Y 年,4位数表达 #%H 24小时表达,%I 12小时表达 #%M 分钟 #%S 秒 #%z 时区 #strptime() #str parse time 时间字符串 => parse 时间对象 d5 = datetime.datetime.strptime('24-04-07!!18:50:38', '%y-%m-%d!!%H:%M:%S') #时间类.strptime print(d5) #: 2024-04-07 18:50:38 print(d5.year, d5.month, d5.day, d5.hour) #: 2024 4 7 18 print(d5.date(), d5.time(), d5.weekday(), d5.isoweekday()) #: 2024-04-07 18:50:38 6 7 print("{:%Y/%m/%d %H:%M:%S}".format(d5)) #: 2024/04/07 18:50:38
timedelta类
- datetime2 = datetime1 + timedelta
- datetime2 = datetime1 - timedelta
- timedelta = datetime1 - datetime2
- 构造方法
- datetime.timedelta(days=0, seconds=0, microseconds=0, milliseconds=0, minutes=0, hours=0, weeks=0)
- year = datetime.timedelta(days=365)
- total_seconds() 返回时间差的总秒数
# coding: utf-8 import datetime #datetime.timedelta? #timedelta(days=0, seconds=0, microseconds=0, milliseconds=0, minutes=0, hours=0, weeks=0) #时间对象 - 时间对象 => 时间差 #时间对象 + 时间差 => 新时间对象 #时间对象 - 时间差 => 新时间对象 d1 = datetime.datetime.now() d2 = datetime.datetime.strptime('2024-04-07 18:50:38', '%Y-%m-%d %H:%M:%S') print(d1, d2) timedelta = d1 - d2 print(timedelta) t1 = d2 + datetime.timedelta(1,10,hours=8) t2 = d2 - datetime.timedelta(1,10,hours=8) print(t1, t2) #: 2024-04-08 14:47:09.190344 2024-04-07 18:50:38 #: 19:56:31.190344 #: 2024-04-09 02:50:48 2024-04-06 10:50:28 total_s = (d1 - d2).total_seconds() #时间差对象才有total_seconds print(total_s) #: 72261.922858
time模块
time 模块相对更加原始。
- time.sleep(secs) 将调用线程挂起指定的秒数
范例:
# coding: utf-8 import time print(1111) time.sleep(5) #卡住了,阻塞了5秒 print(2222)
内建函数
常见内建函数
1
- 标识id
- 返回对象的唯一标识,CPython返回内存地址
- 哈希hash()
- 返回一个对象的哈希值
- 类型type()
- 返回对象的类型
- 类型轮换
- float() int() bin() hex() oct() bool() list() tuple() dict() set() complex() bytes() bytearray()
- 输入input([prompt])
- 接收用户输入,返回一个字符串
- 打印print(value, …, sep=' ', end='\n', file=sys.stdout, flush=False)
- 打印输出,默认使用空格分割、换行结尾,输出到控制台
2
- 对象长度 len(s)
- 返回一个集合类型的元素个数
- isinstance(obj, class_or_tuple)
- 判断对象obj是否属于某种类型或者元组中列出的某个类型
- isinstance(True, int)
- issubclass(cls, class_or_tuple)
- 判断类型cls是否是某种类型的子类或元组中列出的某个类型的子类
- issubclass(bool, int)
3
- 绝对值abs(x) x为数值
- 最大值max() 最小值min()
- 返回可迭代对象中最大或最小值
- 返回多个参数中最大或最小值
- round(x) 四舍六入五取偶,round(-0.5)
- pow(x, y) 等价于x**y
- range(stop) 从0开始到stop-1的可迭代对象;range(start, stop[,step])从start开始到stop-1结束步长为step的可迭代对象
- divmod(x, y) 等价于 tuple(x//y, x%y)
- sum(iterable[,start])对可迭代对象的所有数值元素求和
- sum(range(1, 100, 2))
#min(iterable, *[, default=obj, key=func]) -> value #min(arg1, arg2, *args, *[, key=func]) -> value print(min(1, 2, 3, 4), min([2, 3, 1])) #: 1 1 print(sum(range(10)), sum(range(10), 100)) #: 45 145
4
- chr(i) 给一个一定范围的整数返回对应的字符
- chr(97) chr(20013)
- ord(c) 返回字符对应的整数
- ord('a') ord('中') 对应unicode编号
- str()、repr()、ascii() 后面讲解
# coding: utf-8 print(ord('a'), ord('中')) #97 21834
sort排序
- sorted(iterable[,key][,reverse])排序
- 返回一个新的
列表,默认升序 - reverse 是反转
- 返回一个新的
sorted([1, 3, 5]) sorted([1, 3, 5], reverse=True) sorted({'a':100, 'b':'abc'}) sorted({'a':100, 'b':'abc'}.items()) sorted({'a':30, 'b':200}.values(), reverse=True, key=str) sorted({'a':30, 'b':200}.values(), reverse=True)
范例:
# coding: utf-8 print(sorted(range(5))) #立即返回列表,排序是全员参与,一般来说都不高效 print(sorted('edcba')) #: [0, 1, 2, 3, 4] #: ['a', 'b', 'c', 'd', 'e'] print(sorted([1, '100'], key=str)) #key 只是把转换后的结果用来进行大小比较,并不影响结果 #: [1, '100'] print(sorted({'c':1, 'b':2, 'a':1})) #? for k in dict.keys() 按key排序 #: ['a', 'b', 'c'] print(sorted({'c':1, 'b':2, 'a':1}.values())) # 按value排序 print(sorted({'c':1, 'b':2, 'a':1}.items())) # 按items排序 #: [1, 1, 2] #: [('a', 1), ('b', 2), ('c', 1)]
翻转 reversed(seq)
- 翻转 reversed(seq)
- 返回一个翻转元素的迭代器
# coding: utf-8 r = reversed(range(10)) print(r) print(next(r)) print(next(r)) l1 = list(reversed("13579")) print(l1) {reversed((2, 4))} #返回什么 ? for x in reversed(['c', 'b', 'a']): #reversed 高效? 为什么?高效,一定是倒着读取 print(x) reversed(sorted({1, 5, 9})
范例:
# coding: utf-8 lst = list(range(5)) for i in reversed(lst): #reversed 高效? 为什么?高效,一定是倒着读取,什么都不做,立即返回一个迭代器 print(i) print(reversed(lst)) #返回一个迭代器,惰性 #: 4 #: 3 #: 2 #: 1 #: 0 #: <list_reverseiterator object at 0x00000139EC4A0FD0> l1 = list(reversed("13579")) print(l1) #: ['9', '7', '5', '3', '1'] print({reversed('ababab')}) # 集合构造方式:{元素}、set(iterable)。 list(iterable) tuple(interable) #: {<reversed object at 0x00000139663CC580>}
枚举 enumerate(seq, start=0)
- 枚举 enumerate(seq, start=0)
- 迭代一个序列,返回索引数字和元素构成的二元组
- start表示索引开始的数字,默认是0
for x in enumerate([2, 4, 8]): print(x) for x in enumerate("abcde"): print(x, end=' ')
只要是遍历,只跟规模有关,规模越大越耗时
范例:
# coding: utf-8 g = enumerate([1, 2, 3]) print(g) print(next(g)) #: <enumerate object at 0x0000014526718280> #: (0, 1) l2 = list(range(15, 10, -1)) for index, element in enumerate(l2, 10): #(数据, 列表的元素) print(index, element) #: 10 15 #: 11 14 #: 12 13 #: 13 12 #: 14 11 for i, (k,v) in enumerate({'a':1, 'b':2}.items()): print(i,k,v) #: 0 a 1 #: 1 b 2
迭代器和取元素 iter(iterable)、next()
- 迭代器和取元素 iter(iterable)、next(iterator[, default])
- iter将一个可迭代对象封装成一个迭代器
- next对一个迭代器取下一个元素。如果全部元素都取过了,再次next会抛StopIteration异常
it = iter(range(5)) # 生成一个全新的迭代器对象 next(it) it = reversed([1,3,5]) next(it)
拉链函数zip(*iterables)
- 拉链函数zip(*iterables)
- 像拉链一样,把多个可迭代对象合并在一起,返回一个迭代器
- 将每次从不同对象中取到的元素合并成一个元组
# coding: utf-8 l1 = list(zip(range(5), range(5))) l2 = list(zip(range(5), range(5), range(2), range(5))) # 木桶原理,谁短用谁 #: [(0, 0), (1, 1), (2, 2), (3, 3), (4, 4)] #: [(0, 0, 0, 0), (1, 1, 1, 1)] d1 = dict(zip('abcde', range(3))) d2 = {k:v for k, v in zip('abcde', range(3))} #: {'a': 0, 'b': 1, 'c': 2} #: {'a': 0, 'b': 1, 'c': 2} d3 = {str(x):y for x,y in zip(range(10), range(10))} #: {'0': 0, '1': 1, '2': 2, '3': 3, '4': 4, '5': 5, '6': 6, '7': 7, '8': 8, '9': 9}
d = {'x': 4, 'y': 5} print(d.keys()) print(dict(zip(d.keys(), (1, 2)))) #输出 #: dict_keys(['x', 'y']) #: {'x': 1, 'y': 2}
可迭代对象
- 能够通过迭代一次次返回
不同的元素的对象- 所谓相同,不是指值是否相同,而是元素在容器中是否是同一个,例如列表中值可以重复的,['a', 'a'],虽然这个列表有2个元素,值一样,但是两个'a'是不同的元素
- 可以迭代,但是未必有序,未必可索引
- 可迭代对象有: list、tuple、string、bytes、bytearray、range、set、dict、生成器等
- 可以使用成员操作符in、not in
- in本质上对于线性数据结构就是在遍历对象,O(n)
- in对于字典和集合是遍历吗? 不是遍历,对key做in操作,O(1)
3 in range(10) 3 in (x for x in range(10)) 3 in {x:y for x,y in zip(range(4), range(4,10))}
迭代器
- 特殊的对象,一定是可迭代对象,具备可迭代对象的特征
- 通过iter方法把一个可迭代对象封装成迭代器
- 通过next方法,迭代迭代器对象
- 迭代器对象只能从头到尾迭代一遍
- 生成器对象 ,就是迭代器对象,它是特殊的迭代器对象
for x in iter(range(10)): print(x) g = (x for x in range(10)) print(type(g)) print(next(g)) print(next(g))