Python: 系统编程
- TAGS: Python
Python 文件系统操作编程
主要内容:
- 文件打开与文件描述符
- 文件的编码与UNICODE
- 二进制文件与文本
- 文本文件的读写
- 二进制文件的读写
- 文件的迭代器读写方式
- 文件读写的异常与 With 语句
- 目录与文件遍历
- 目录创建与删除
- 目录与文件存在判定
- 目录与文件属性查看
- StringIO 和 ByteIO 使用
- 高级文件操作模块 Shutil 使用
- CSV 文件读写与解析
- ini 配置文件的读写与解析
文件操作
冯诺依曼体系架构
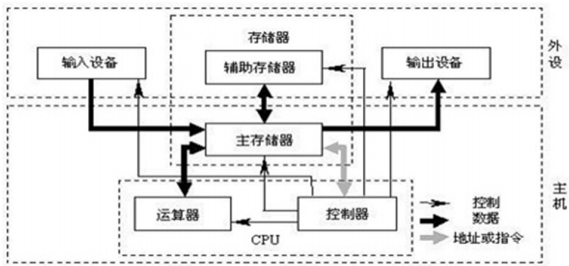
CPU由运算器和控制器组成:
- 运算器,完成各种算数运算、逻辑运算、数据传输等数据加工处理
- 控制器,控制计算机各部件协调运行
- 存储器,用于记忆程序和数据,例如内存
- 输入设备,将数据或程序输入到计算机中,例如键盘、鼠标
- 输出设备,将数据或程序的处理结果展示给用户,例如显示器、打印机等
一般说IO操作,指的是文件IO,如果指的是网络IO,都会直接说网络IO磁盘
目前依然是文件持久化最重要设备。
1956年,IBM发明可以存储5MB的磁盘驱动器。磁盘使用磁性材料记录数据,使用NS极表示0或1。
现代磁盘使用温彻斯特磁盘驱动器,如下
温彻斯特磁盘拥有多个同轴金属盘片,盘片上涂上磁性材料,一组可移动磁头。运行时,磁头摆动从飞速旋转的盘片读取或写入数据。一般常见盘片 转速 为5400转/分钟、7200转/分钟等。磁头摆动定位数据过程称为 寻道 。转速、寻道都影响磁盘读写性能。
磁头不和盘片接触,磁盘内部也不是真空,磁头悬浮在磁盘上方。一组磁头从0编号。
盘片Platter: 涂满磁性材料的盘片,早期是金属的,现在多为玻璃。
磁道Track:盘片划分同心圆,同心圆间距越小,一般来说存储容量越大。磁道编号由外向内从0开始。
扇区Sector:一个磁道上能够存储的0或1信号太多了,所以需要进一步划分成若干弧段,每一个弧段就是一个扇区。通常一个扇区为512字节。每个扇区都有自己的编号。
柱面Cylinder:从垂直方向看,磁道的同心圆就构成了圆柱。编号由外向内从0开始。
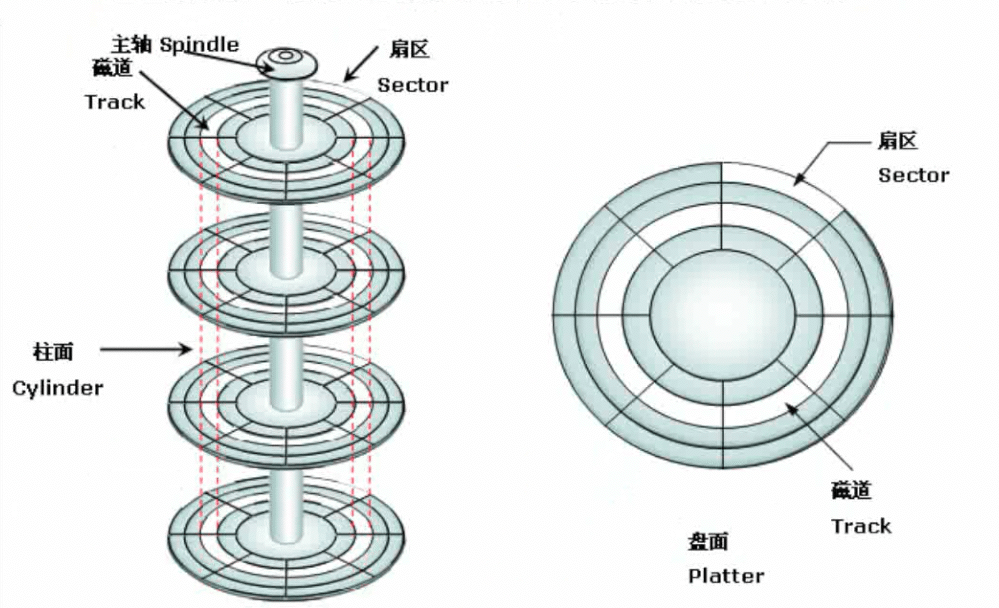
注意:盘片内圈扇区面积小,外圈面积大。但扇区都是512字节。外圈磁密度低,内圈磁密度高。
如今磁盘,可以做到磁密度一致,所以磁盘划分,外圈可以划分更多扇区,这样可以存储更多数据。这种分区弧长一致的分配扇区方法称为ZBR(Zoned-bit recording),按照半径分成不同的磁道组称为Zone。这样,转动同样的角度,外圈读取数据更多。

簇Cluster:操作系统为了优化IO,使用磁盘空间时最小占用的多个扇区。一般簇大小为4-64个扇区(2KB-32KB)。所以,一个文件就有了物理占用空间大小即实际分得的磁盘空间,和逻辑占用大小即文件本身的实际字节数。往往实际占用空间都比文件本身大。越是小文件,越浪费空间。
文件IO常用操作
- open 打开
- read 读取
- write 写稿
- close 关闭
- readline 行读取
- readlines 多行读取
- seek 文件指针操作
- tell 指针位置
打开操作
open 方法
open( file, #文件对象,路径 mode='r', #模式 buffering=-1, #缓冲区 encoding=None, #编码 errors=None, #出错怎么办 newline=None, #遇到换行符怎么办 closefd=True, #是否关闭文件描述符 opener=None, #打开的是谁 )
打开一个文件,返回一个文件对象(流对象)和文件描述符。打开文件失败,则返回异常
基本使用:创建一个文件test,然后打开它,用完 关闭
# coding: utf-8 #open('test') #报错,当前路径不存在,FileNotFoundError: [Errno 2] No such file or directory: 'test' f = open('test') #windows <_io.TextIOWrapper name='test' mode='r' encoding='cp936'> #linux <_io.TextIOWrapper name='test' mode='r' encoding='UTF-8'> print(f.read()) #读取文件 f.close #使用完后关闭 # open成功后,一定可以拿到一个文件对象,就可以对它进行增删改查, 文件操作,读写 #文件对象,默认是文本的打开方式 #encoding='cp936' #windows默认GBK,codepage代码页 936 等价认为是GBK #encoding='UTF-8' #linux系统默认都是用utf-8 中文大多数3字节
文件操作中,最常用的操作就是读和写。
文件访问的模式有两种:文本模式和二进制模式。不同模式下,操作函数不尽相同,表现结果也不一样。
注:windows中使用codepage代码页,可以认为每一个代码页就是一张编码表。cp936等同于GBK。
open的参数
file
打开或要创建的文件。如果不指定路径,默认是当前路径。
mode模式
模式描述字符意义:
- r 缺省模式,只读打开。文件不存在,立即报错。文件存在,从头开始读,文件指针初始在开头即索引0的位置。
- w 只写打开,不支持读取。文件存在,文件内容将被清空,从头写;文件不存在,文件被创建,从头写。白纸一张,从头写,初始位置在0
- x 创建并写入一个新文件,不支持读取。文件存在,抛异常;文件不存在不报错,新文件被创建
- a 只写打开,追加内容,不支持读取。文件存在,追加写入,文件不存在,创建文件,从头写
- b 二进制模式。字节流,将文本按照字节理解,与字符编码无关。二进制模式操作时,字节操作使用bytes类型。不能单独使用,必须和rwax四种之一配合使用,不影响主模式。
- t 缺省模式,文本模式。text,默认可以不写。不能单独使用,必须和wrax配合使用,不影响主模式
- + 读或写打开后,使用+来增加缺失的写或读的能力。必须和主模式(rwax)配合使用,不影响主模式。
- r+ => rt+ 只读文本模式打开,补充写能力。文件指针在开头。
- w+ => wt+ 只写文本模式打开,补充读能力。w能力不变,会清空所有内容
在上面的例子中,可以看到默认是文本打开模式,且是只读的。
# coding: utf-8 #mode rwxabt+ #r 只读模式 f = open('D:/tmp/test') print(f) #: <_io.TextIOWrapper name='D:/tmp/test' mode='r' encoding='cp936'> print(f.readable()) #: True 可读的 r readonly print(f.read()) #文件空的 #f.write('abc') #报错 io.UnsupportedOperation: not writable f.close() f = open('D:/tmp/test', 'r') #只读 #f.write('abc') #报错 io.UnsupportedOperation: not writable f.close() #w写模式 f = open('D:/tmp/test1', 'w') #test1 不存在 print(f.write('abc')) #返回值3,3表示写入的字符数?字节数? #print(f.write('啊')) #返回1,目前返回值是表示字符数 #f.read() #报错,w模式是只写 f.close() f = open('D:/tmp/test1', 'w') #test1存在,w打开,内容没了 f.write('xyz') f.close() #a模式 f = open('D:/tmp/test1', 'a') #test1存在 #f.read() #a模式不支持读取 f.write('123') #追加写入 f.close() f = open('D:/tmp/test2', 'a') #test1不存在,创建文件,从头写 #a模式,不管文件存在与否,都从尾部追加写入 f.write('123\n') f.write('789') f.close() #x模式 #f = open('D:/tmp/test', 'x') #x模式 exsits,文件存在,报错 f = open('D:/tmp/testx', 'x') #x模式 exsits,文件不存在,文件被创建 #f.read() #x模式不支持读取 f.write('testx test') f.close() #t模式 text f = open('D:/tmp/testx', 'r') #字符和编码有关,字符串的世界都是由编码的 #rwax 默认都用文本模式打开 rt wt at xt,不能独立使用 print(f) #: <_io.TextIOWrapper name='D:/tmp/testx' mode='r' encoding='cp936'> f.close() #b模式,binnary, 二进制 f = open('D:/tmp/testx', 'rb') #ab, wb print(f) # encoding 字节的世界都是0和1组成的字节,和编码无关 #: <_io.BufferedReader name='D:/tmp/testx'> print(f.read()) #返回字节 : b'testx test' f.close() f = open('D:/tmp/testx', 'wb') #ab, wb f.write(b'xyz') #返回一个值,写入的字节数 f.write('zhongwen'.encode()) #缺少编码,utf-8,二进制模式,跟字符无关 f.close() #+模式 #+ 附加的能力,必须和主模式(rwax)配合使用,不影响主模式。r+ w+ a+ x+ f = open('D:/tmp/testx', 'r+') f.read() f.write('xyz') #可写 f.read() #写入时,什么都读不到 f.seek(0) #用了seek会立即写入磁盘 f.read() #可以读到 f.close() f = open('D:/tmp/testx', 'w+') f.read() #写入时,什么都读不到 f.write('xyz') #可写 f.close() #注意文件指针
文件指针
文件指针,指向当前字节位置。
- mode=r,指针起始在0
- mode=a,指针起始在EOF
tell()显示指针当前位置
seek(offset[,whence]) 移动文件指针位置。offset偏移多少字节,whence从哪里开始。
文本模式下
- whence 0 缺省值,表示从头开始,offset只能正整数
- whence 1 表示从当前位置,offset只接受0
- whence 2 表示从EOF开始,offset只接受0
二进制模式下
- whence 0 seek(0) seek(0, 0) seek(x) x >=0
- whence 1 表示从当前位置,offset可正可负,不能左超界
- whence 2 表示从EOF开始,offset可正可负,不能左超界
# coding: utf-8 f = open('D:/tmp/test', 'w+') print(f.tell()) #: 0 print(f.write('abc')) #: 3 写入了3个字符 print(f.tell()) #: 3 指针移动了,返回的一直是字节的索引 print(f.write('de')) #: 2 写入了2个字符 print(f.tell()) #: 5 指针移动了,当前位置在5 f.close() #以文本方式打开 f = open('D:/tmp/test') print(f.tell()) #: 0 print(f.read(2)) #: ab print(f.tell()) #: 2 print(f.read(1)) #: c print(f.tell()) #: 3 f.seek(0) #设置指针位置 print(f.read(1)) #: a print(f.tell()) #: 1 print(f.read()) #bcde 从当前位置到结尾 f.close() #seek f = open('D:/tmp/test') f.seek(0, 0) #第一个0 表示偏移,第二个0 表示whence 0表示从头开始,拉回到开头。whence 0 是默认的 print(f.read()) #abcde f.seek(0) print(f.read(2)) #ab f.seek(4, 0) print(f.read()) #e f.seek(0, 2) #跳到EOF #f.seek(-2, 0) # 报错,超出左界,不可以 f.seek(20, 0) #向右超界允许 #二进制模式 seek f = open('D:/tmp/test', 'rb') f.seek(2) #f.seek(-2) #f.seek(-2, 0) 由于左超界,所以报错 f.seek(-2, 1) #当前位置向左走2, 但不能超界,否则报错 print(f.tell()) #0 f.seek(100, 1) print(f.read()) #b'' 二进制世界,没有什么乱码,是字节就读
二进制模式支持任意起点的偏移,从头、从尾、从中间位置开始。
向后seek可以超界,但是向前seek的时候,不能超界,否则抛异常
buffering缓冲区
buffering=-1 使用默认缓冲区大小。如果是二进制模式,使用 io.DEAFAULT_BUFFER_SIZE 值,默认是4096或8192.如果是文本模式,如果是终端设备,是行缓存方式,如果不是,则使用二进制模式的策略。
0 文本模式不支持;二进制模式无缓冲区, 立即写入磁盘,相当于把文件当做一个FIFO队列用。 1,只在文本模式使用,表示使用行缓冲。意思就是见到换行符\n就flush写入磁盘 - 文本模式,如果缓冲区撑破了,被迫写入磁盘 - 二进制模式,1无效,使用的默认缓冲区 - 大于1, 用于指定buffer的大小 - 文本模式,默认缓冲区 - 二进制模式,指定大小字节的缓冲区
buffer 缓冲区
缓冲区一个内存空间,一般来说是一个FIFO队列,到缓冲区满了或者达到阈值,数据才会flush到磁盘。
fush() 将缓冲区数据写入磁盘
close() 关闭前会调用flush()
io.DEAFAULT_BUFFER_SIZE 缺省缓冲区大小,字节
先看二进制模式
# coding: utf-8 # 缓冲区大小为0 f = open('D:/tmp/test', 'w+b', 0) #文本模式不支持,只在二进制模式,立即写入磁盘 f.write(b'a') f.write(b'b') print(f.read()) #返回空,但文本已被写入内容 f.seek(0) print(f.read()) #: b'ab' f.close() # 缓冲区大小为1 f = open('D:/tmp/test', 'w+', 1) #只在文本模式,使用行缓冲。见到换行符 \n 就flush f.write('a') f.write('a') print(f.read()) f.write('\n\t\n') print(f.read()) f.seek(0) print(f.read()) f.close() #如果缓冲区撑破了,被迫写入磁盘 f = open('D:/tmp/test', 'w+', 1) #只在文本模式,使用行缓冲。见到换行符 \n 就flush f.write('a' * 8100) f.write('b' * 100) f.close() import io print(io.DEFAULT_BUFFER_SIZE) #: 8192 f = open('D:/tmp/test', 'wb+', 1) #对二进制来讲,1无效, f.write(b'a') f.close() # 设置缓冲区大小 f = open('D:/tmp/test', 'wb+', 2) #对二进制来讲 f.write(b'a') f.write(b'b') f.close()
buffering=-1 t和b,都是io.DEAFAULT_BUFFER_SIZE buffering=0 b关闭缓冲区 t不支持 bufferin=1 t行缓冲,遇到换行符才flush buffering>1 b模式表示缓冲大小。缓冲区的值可以超过io.DEAFAULT_BUFFER_SIZE,直到设定的值超出后才把缓冲区flush t模式,是io.DEAFAULT_BUFFER_SIZE字节,flush完后把当前的字符串也写入磁盘。
一般来说,只需要记得:
- 文本模式,一般都用默认缓冲区大小
- 二进制模式,是一个个字节的操作,可以指定buffer大小
- 一般来说,默认缓冲区大小是个比较好的选择,除非明确知道,否则不调整它
- 一般编程中,明确知道需要写磁盘了,都会手动调用一次flush,而不是等到自动flush或者close的时候。
encoding
编码,仅文本模式使用
None 表示使用缺省编码,依赖操作系统。windows 下缺省 GBK(0xB0A1), Linux下缺省UTF-8(0xE5 95 8A)
errors
什么样的编码错误将被捕获
None和'strict' 表示有编码错误将抛出ValueError异常;'ignore'表示忽略
newline
文本模式中,换行的转换。取值可以为None、''空串、'\r'、'\n'、'\r\n'
读时
- None,缺省值,表示'\r'、'\n'、'\r\n' 都被转换为 '\n'
- ''表示不会自动转换通用换行符,常见换行符都可以认为是换行
- 其它合法换行字符表示按照该字符分行
写时
- None,缺省值,表示'\n'都会被替换为系统缺省行分隔符os.linesep
- '\n' 或''空串表示'\n' 不替换
- 其它合法换行字符表示文本中的'\n'换行符会被替换为指定的换行字符
# coding: utf-8 #newline 新行, \n \r\n txt = 'python\rpip\nxx.com\r\nok' print(txt) #写入 txt = 'python\rpip\nxx.com\r\nok' f = open('D:/tmp/test', 'w+') f.write(txt) #做了一些事,newline #txt = 'python\rpip\r\nxx.com\r\r\nok' #None,把\n换成当前操作系统的默认换行符,windows \r\n f.close() #读取 f = open('D:/tmp/test') #newline=None t = f.read() print(t.encode()) #: b'python\npip\nxx.com\n\nok' # None,\r \n \r\n => \n 把常见换行符换成\n f.seek(0) print(f.readlines())#: ['python\n', 'pip\n', 'xx.com\n', '\n', 'ok'] f.close f = open('D:/tmp/test', newline='') #newline='' 什么都不干,按照各系统换行处理 t = f.read() print(t.encode()) #: b'python\rpip\r\nxx.com\r\r\nok' f.seek(0) print(f.readlines()) #: ['python\r', 'pip\r\n', 'xx.com\r', '\r\n', 'ok'] f.close f = open('D:/tmp/test', newline='\n') #newline='\n' 什么都不干,文件处理按\n处理 t = f.read() print(t.encode()) #: b'python\rpip\r\nxx.com\r\r\nok' f.seek(0) print(f.readlines()) #: ['python\rpip\r\n', 'xx.com\r\r\n', 'ok'] f.close f = open('D:/tmp/test', newline='\r') #newline='\r' 什么都不干,文件处理按\r处理 t = f.read() print(t.encode()) #: b'python\rpip\r\nxx.com\r\r\nok' f.seek(0) print(f.readlines()) #: ['python\r', 'pip\r', '\nxx.com\r', '\r', '\nok'] f.close f = open('D:/tmp/test', newline='\r\n') #newline='\r\n' 什么都不干,文件处理按\r\n处理 t = f.read() print(t.encode()) #: b'python\rpip\r\nxx.com\r\r\nok' f.seek(0) print(f.readlines()) #: ['python\rpip\r\n', 'xx.com\r\r\n', 'ok'] f.close
其它
closefd 关闭文件描述符,True表示关闭它。False会在文件关闭后保持这个描述符。fileobj.fileno()查看
# coding: utf-8 #open( # file, #文件对象,路径 # mode='r', #模式 # buffering=-1, #缓冲区 # encoding=None, #编码 # errors=None, #出错怎么办 # newline=None, #遇到换行符怎么办 # closefd=True, #是否关闭文件描述符 # opener=None, #打开的是谁 #) f = open('D:/tmp/test') print(f.fileno()) #文件描述符 f.close() #关闭后,文件描述符关闭 print(f.closed) #是否关闭 #: 3 #: True
read
read(size=-1)
size表示读取的多少字符或字节;负数或者None表示读取到EOF
行读取
readline(size=-1)
一行行读取文件内容。size设置一次能读取行内几个字符或字节
readlines(hint=-1)
读取所有行的列表。指定hint则返回指定的列表。
常用的读取方式
# coding: utf-8 #按行迭代 f = open('D:/tmp/test') #返回可迭代对象,惰性的 for line in f: print(line.strip()) f.close()
write
write(s),把字符串s写入到文件中并返回字符的个数
writelines(lines),将字符串列表写入文件。
# coding: utf-8 f = open('d:/tmp/test', 'w+') lines = ['abc', '123\n', 'cici'] #提供换行符 f.writelines(lines) #writelines 但是不解决换行问题 f.seek(0) print(f.read()) f.close() #: abc123 #: cici
close
flush 并关闭文件对象
文件已经关闭,再次关闭没有任何效果
其他
- seekable() 是否可seek
- readable() 是否可读
- writeable() 是否可写
- closed 是否已经关闭
上下文管理
问题的引出
文件打开会占文件描述符。
在Linux中,执行
# coding: utf-8 #打开2000个文件 lst = [] for _ in range(2000): lst.append(open('test')) # OSError: [Error 24] Too many open files: 'test' print(len(lst))
lsof 列出打开的文件。 yum install lsof 安装
ps aux |grep python lsof -p 9255|grep test| wc -l ulimit -a open file 1024 # 能打开的文件描述符数,默认1024
上下文管理
上下文管理:
- 使用with关键字,上下文管理针对的是with后的对象
- 可以使用as关键字
- 上下文管理的语句块并不会开启新的作用域
文件对象上下文管理
- 进入with时,with后的文件对象是被管理对象
- as子句后的标识符,指向with后的文件对象
- with语句块执行完的时候,会自动关闭文件对象
解决
# coding: utf-8 f = open('d:/tmp/test') try: #尝试捕获try异常 print(f.closed) f.write('abc') print(f.read()) finally: f.close() print(f.closed)
with使用
with 对象 [as 标识符]: pass
# coding: utf-8 with open('d:/tmp/test') as f: #在文件对象with它,as f,f 就是该文件对象 f = open('d:/tmp/test') print(f) print(f.closed) #是不关闭 print(f.read()) #with语句块结束了,自动调用该文件对象的close方法,出错时也会调用close方法 f = open('d:/tmp/test') with f: print(f) print(f.closed) print(f.read()) #哪怕出现异常,离开with时,依然调用with后文件对象的close方法 print(f.closed) #True
- 对象类似于文件对象的IO对象,一般来说都需要在不使用的时候关闭、注销,以释放资源
- IO被打开的时候,会获得一个文件描述符。计算机资源是有限的,所以操作系统都会做限制。就是为了保护计算机的资源不要被完全耗尽,计算资源是很多程序共享的,不是独占的。
- 一般情况下,除非特别明确的知道当前资源情况,否则不要盲目提高资源的限制值解决问题。
StringIO和BytesIO
StringIO
- io模块中的类
- from io import StringIO
- 内存中,开辟的一个 文本模式 的buffer,可以像文件对象一样操作它
- 当close方法被调用的时候,这个buffer会被释放
getvalue()获取全部内容。跟文件指针没有关系。
好处
一般来说,磁盘的操作比内存的操作要慢得多,内存足够的情况下,一般的优化思路是少 落地 ,减少磁盘IO的过程,可以大大提高程序的运行效率。
BytesIO
- io模块中类
- from io import BytesIO
- 内存中,开辟的一个二进制模式的buffer,可以像文件对象一样操作它
- 当close方法被调用的时候,这个buffer会被释放
# coding: utf-8 from io import StringIO, BytesIO s = StringIO() #IO缓冲区,文本 print(s.seekable(), s.readable(), s.writable()) print(s.read()) print(s.write('abc')) print(s.read()) #没读到,文件指针指到最后了 s.seek(0) print(s.readlines()) #['abc'] #print(s.fileno()) #没有文件描述符,没有使用。内存中东西 print(s.read()) #上面读完就读不出东西 print('-' * 30) print(s.getvalue()) #内存中建立类文件对象,无视指针,直接获取全部数据 s.close() #True True True # #3 # #['abc'] # #------------------------------ #abc s = BytesIO() #IO缓冲区,字节 print(s.seekable(), s.readable(), s.writable()) print(s.read()) print(s.write(b'abc')) print(s.read()) #没读到,文件指针指到最后了 s.seek(0) print(s.readlines()) #[b'abc'] #print(s.fileno()) #没有文件描述符,没有使用。内存中东西 print(s.read()) #上面读完就读不出东西 print('-' * 30) print(s.getvalue()) #内存中建立类文件对象,无视指针,直接获取全部数据 s.close() #True True True #b'' #3 #b'' #[b'abc'] #b'' #------------------------------ #b'abc' #支持上下文 s = BytesIO() #IO缓冲区,字节 with s: print(s.seekable(), s.readable(), s.writable()) print(s.read()) print(s.write(b'abc')) print(s.read()) #没读到,文件指针指到最后了 s.seek(0) print(s.readlines()) #[b'abc'] #print(s.fileno()) #没有文件描述符,没有使用。内存中东西 print(s.read()) #上面读完就读不出东西 print('-' * 30) print(s.getvalue()) #内存中建立类文件对象,无视指针,直接获取全部数据 #s.close() print(s.closed)
flie-like对象
- 类文件对象,可以像文件对象一样操作
- socket对象、标准输入输出对象(stdin、stdout) 都是类文件对象
# coding: utf-8 from sys import stderr, stdout #0 stdin; 1 stdout; 2 stderr f = stdout #可写 print(f.seekable(), f.writable(), f.readable()) f.write('abc') print('xzy') #默认调用stdout #: True True False #: abcxzy
# coding: utf-8 from sys import stderr, stdout #0 stdin; 1 stdout; 2 stderr f1 = stderr print(f1.seekable(), f1.writable(), f1.readable()) f1.write('123') print('456', file=stderr) #False True False #123456
>>> help(print) Help on built-in function print in module builtins: print(*args, sep=' ', end='\n', file=None, flush=False) Prints the values to a stream, or to sys.stdout by default. sep string inserted between values, default a space. end string appended after the last value, default a newline. file a file-like object (stream); defaults to the current sys.stdout. flush whether to forcibly flush the stream.
with open('d:/tmp/test', 'w') as f: print('abcdef\n1234', file=f) #写到文件中 #f.close()
正则表达式基础
概述
正则表达式,Regular Expression,缩写为regex、regexp、RE等
正则表达式是文本处理极为重要的技术,用它可以对字符串按照某种规则进行检索、替换。
1970年代,Unix之父Ken Thompson将正则表达式引入到Unix中文本编辑器ed和grep命令中,由此正则表达式普及开来。
1980年后,perl语言对HenrySpencer编写的库,扩展了很多新的特性。1997年开始,Philip Hazel开发出了PCRE (Perl Compatible Regular Expressions),它被PHP和HTTPD等工具采用。
正则表达式应用极其广泛,shell中处理文本的命令、各种高级编程语言都支持正则表达式。
参考
- 正则表达式30分钟入门教程 https://www.w3cschool.cn/regex_rmjc/
- perl文官正则: https://perldoc.perl.org/perlre
- grep 中正则: https://www.gnu.org/software/grep/manual/grep.html#Regular-Expressions
- python re正则表达式: https://docs.python.org/zh-cn/3/library/re.html
- Microsoft
- 基础正则表达式: https://www.cnblogs.com/f-ck-need-u/p/9621130.html
- Perl正则表达式超详细教程: https://www.cnblogs.com/f-ck-need-u/p/9648439.html
测试:
- 正则测试工具RegEx Tester: https://sourceforge.net/projects/regextester/
- 在线测试:https://regextester.github.io/
正则表达式是一个特殊的字符序列,用于判断一个字符串是否与我们所设定的字符序列是否匹配,也就是说检查一个字符串是否与某种模式匹配。
正则表达式可以包含普通或者特殊字符。绝大部分普通字符,比如 'A' , 'a' , 或者 '0' ,都是最简单的正则表达式。它们就匹配自身。你可以拼接普通字符,所以 cici 匹配字符串 'cici' .
一些字符,如 '|' or '(' ,是特殊的。特殊字符要么代表普通字符的类别,要么影响它们周围的正则表达式的解释方式。正则表达式模式字符串可能不包含空字节,但可以使用 \number 符号指定空字节,例如 '\x00' .
重复修饰符 ( * , + , ? , {m,n} , 等) 不能直接嵌套。这样避免了非贪婪后缀 ? 修饰符,和其他实现中的修饰符产生的多义性。要应用一个内层重复嵌套,可以使用括号。 比如,表达式 (?:a{6})* 匹配6个 'a' 字符重复任意次数。
分类
- BRE 基本正则表达式,grep、sed、vi等软件支持。vim有扩展
- ERE 扩展正则表达式,egrep(grep -E) 、sed -r等
- PCRE 几乎所有高级语言都是PCRE的方言或变种。Python从1.6开始使用SRE正则表达式引擎,可以认为是PCRE的子集,见模块re。
基本语法
元字符
metacharacter https://www.cnblogs.com/f-ck-need-u/p/9621130.html#%E5%85%83%E5%AD%97%E7%AC%A6
. 匹配除换行符外的任意一个字符。如. [abc] 字符集合,只能表示一个字符位置。匹配所包含的任意一个字符。如[abc]匹配plain中的'a' [^abc] 字符集合,只能表示一个字符位置。匹配除去集合内字符的任意一个字符。如 [^abc]可以匹配plain中的'p'、'l'、'i' 或者'n' [a-z] 字符范围,也是个集合,表示一个字符位置 ;匹配所有包含的任意字符。常用[A-Z][0-9] [^a-z] 字符范围,也是个集合,表示一个字符位置;匹配除去集合内字符的任意一个字符。 \b 匹配单词的边界。如\bb在文本中找到单词中b开头的b字符 \B 不匹配单词的边界。如t\B 包含t的单词但是不以t结尾的t字符,例如write; \Bb不以b开头的含有b的单词,例如able \d [0-9]匹配1位数字 \D [^0-9]匹配1位数字 \s 匹配1位空白字符,包含换行符、制表符、空格 [\f\r\n\t\v] \S 匹配1位非空白字符 \w 匹配[a-zA-Z0-9_] \W 匹配\w之外的字符
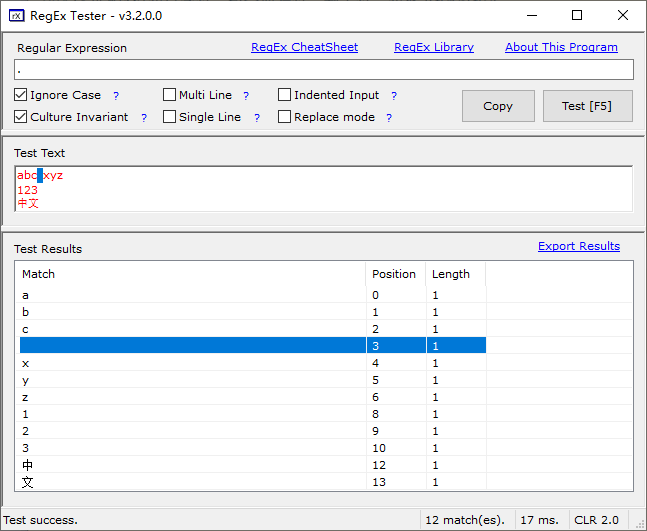
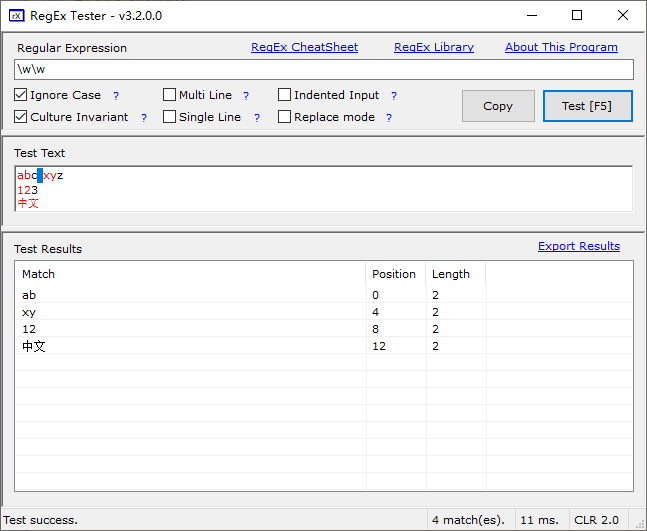
范例:使用正则工具或者在线正则网站测试
abc xyz 123 中文
. #非多行和单行下,默认匹配除换行符之外任意一个字符 \w\w #匹配2个字符 \d #匹配1个数字 [abc ] #匹配abc和空格中任意一个字符 [abc\s] #匹配abc和空格字符中任意一个字符 \w\s\w #匹配c x和z换行1和3换行中 [\d\s\d] #相当于[\d\s] 匹配数字和空白字符中任意字符 \b\w\w\b #即作词首又作词尾,匹配中文
转义
凡是在正则表达式中有特殊意义的符号,如果想使用它的本意,请使用\转义。
反斜杠自身,得使用
\r、\n还是转义后代表回车、换行
重复
https://www.cnblogs.com/f-ck-need-u/p/9621130.html#%E5%85%83%E5%AD%97%E7%AC%A6
* 表示前面的正则表达式会重复0次或多次。如e\w*单词中e后面可以有非空白字符
+ 表示前面的正则表达式重复至少1次。如e\w+单词中e后面至少有一个非空白字符
? 表示前面的正则表达式会重复0次或1次。如e\w?单词中e后面至多有一个非空白字符
{n} 重复固定的n次。如e\w{1} 单词中e后面只能有一个非空白字符
{n,} 重复至少n次。如 e\w{1,} => e\w+ e\w{0,} => e\w* e\w{0,1} => e\w?
{n,m} 重复n到m次。如e\w{1,10}单词中e后面至少1个,至多10个非空白字符
范例:使用正则工具或者在线正则网站测试
abc xyz 123 中文
\w\w? #匹配一个字符,后面可有可无一个字符 \w\w+ #匹配一个字符,后面至少有一个字符的字符串。可匹配abc, xyz, 123, 中文
或
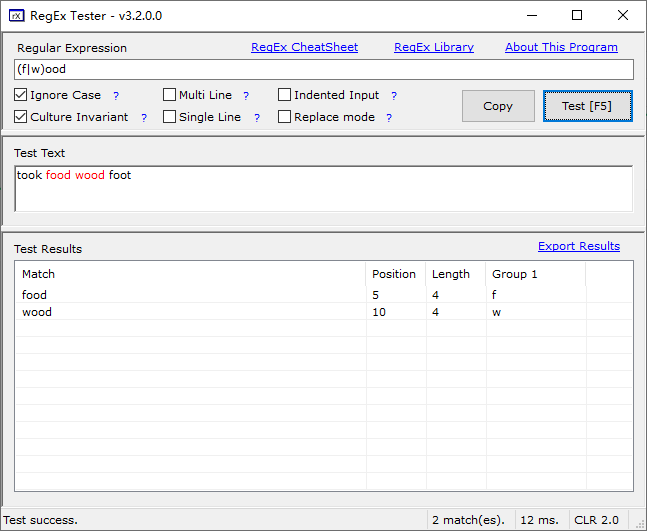
x|y 匹配x或者y
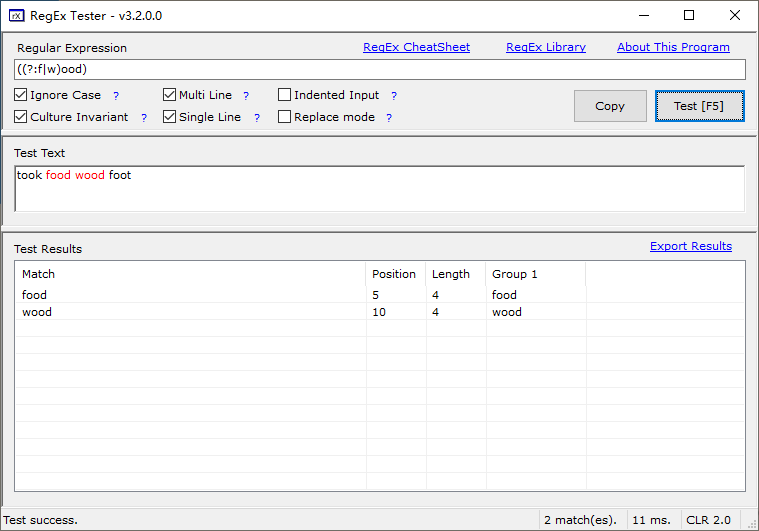
took food wood foot 使用 w|food 或者 (w|f)ood
捕获
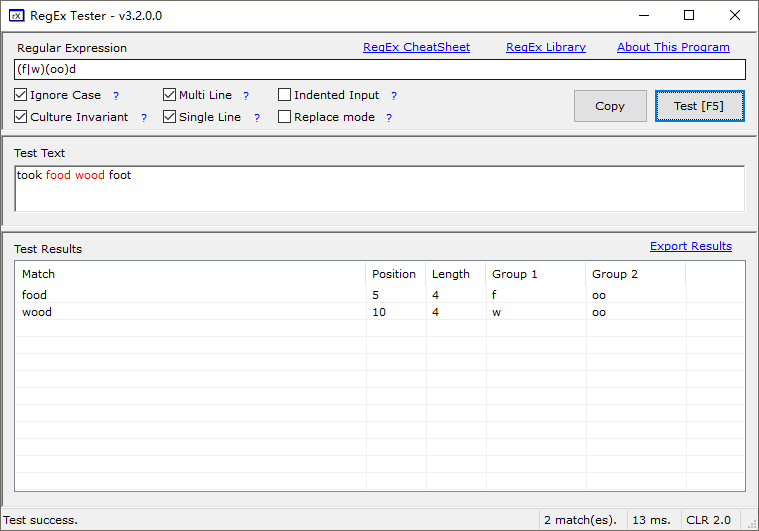
(pattern)
使用小括号指定一个子表达式,也叫分组;
捕获后会自动分配组号 从1开始 可以改变优先级
\数字
匹配对应的分组
例: (very) \1 匹配very very,但捕获的组group是very
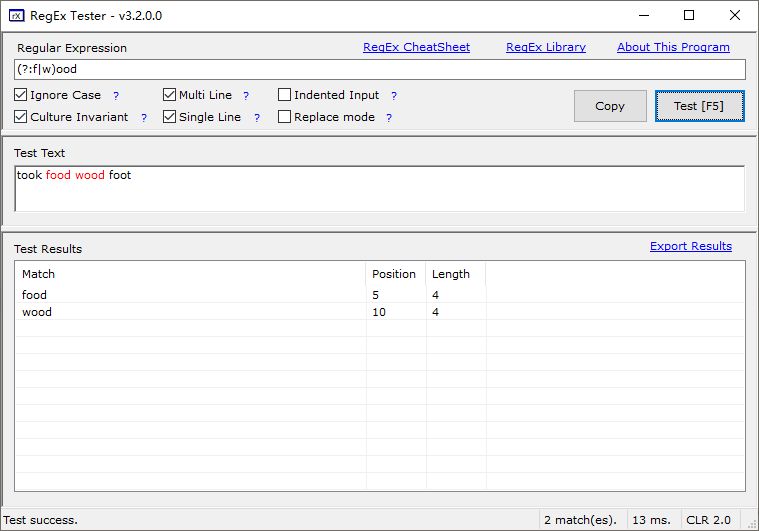
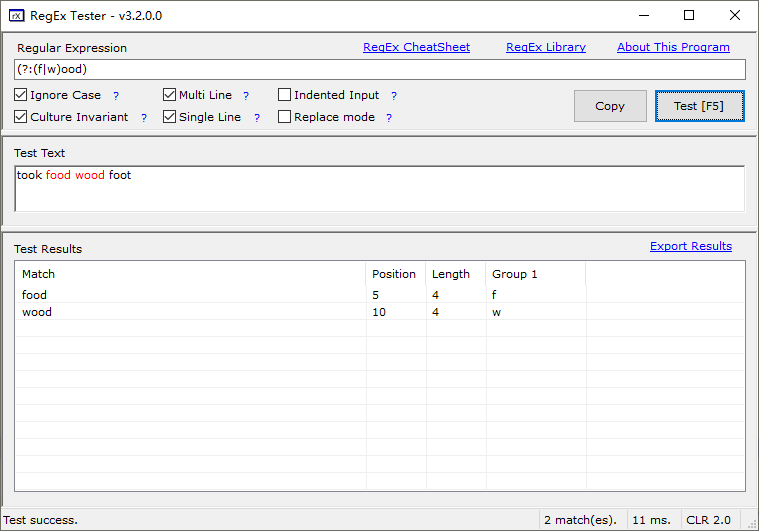
(?:pattern)
如果仅仅为了改变优先级,就不需要捕获分组
例: (?:w|f)ood
'industr(?:y|ies)等价 'industry|industries'
(?<name>exp) 或者 (?'name'exp)
命名分组捕获,但是可以通过name访问分组。 如果不命名的话是从1开始编号的。
Python语法必须是(?P<name>exp)
断言
"环视"锚定,即lookaround anchor,也称为”零宽断言”,它表示匹配的是位置,不是字符。
#零宽断言 - (?=exp) 从左向右的顺序环视,又叫零宽度正预测先行断言。断言exp一定在匹配的右边出现,也就是说断言后面一定跟个exp - (?<=exp) 从右向左的逆序环视,又叫零宽度正回顾后发断言。断言exp一定出现在匹配的左边出现,也就是说前面一定有个exp前缀 #负向零宽断言 - (?!exp) 顺序环视的取反,又叫零宽度负预测先行断言。断言exp一定不会出现在右侧,也就是说断言后面一定不是exp - (?<!exp) 逆序环视的取反,又叫零宽度负回顾后发断言。断言exp一定不能出现在左侧,也就是说断言前面一定不能是exp - (?#comment) 注释
关于”环视”锚定,最需要注意的一点是匹配的结果不占用任何字符,它仅仅只是锚定位置。所以断言只是个条件。
另外,无论是哪种锚定,都是从左向右匹配再做回溯的(假设允许回溯),即使是逆序环视。
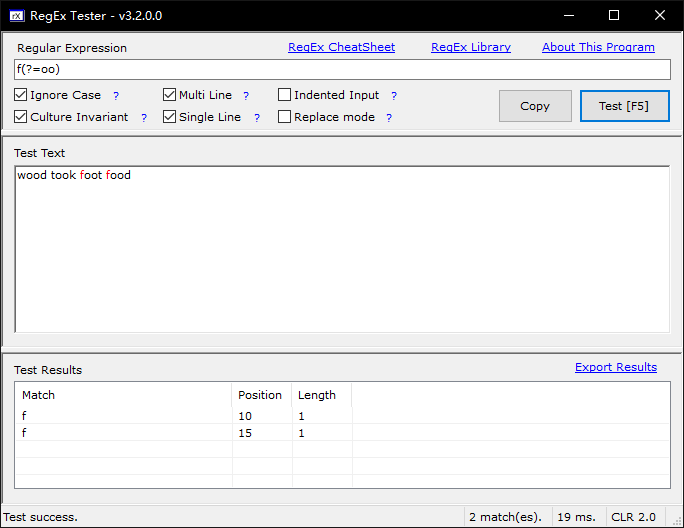
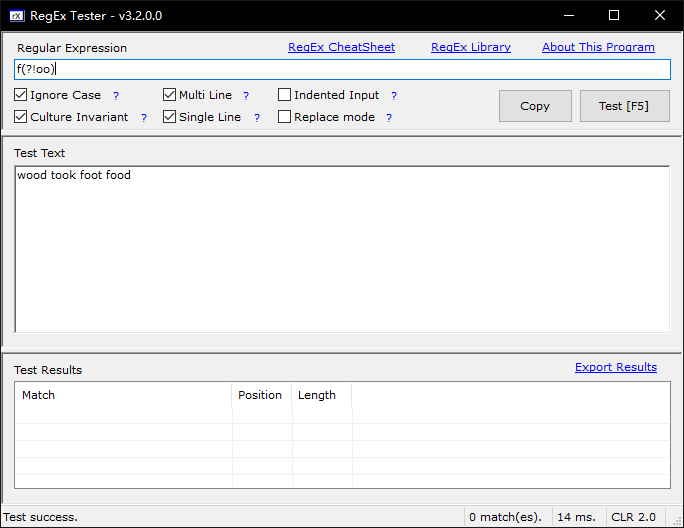
范例:测试字符串为wood took foot food
# 顺序环视 f(?=oo) #匹配f,但f后面一定有oo出现 # 逆序环视,这里能逆序匹配成功,靠的是锚定括号后面的ood\ook (?<=f)ood #匹配ood,ook前一定有t出现 (?<=t)ook #匹配ook,ook前一定有t出现 # 顺序否定环视 foo(?!d) #匹配foo,但foo后面一定不是d \d{3}(?!\d) #匹配3位数字,断言3位数字后面一定不能是数字 # 逆序否定环视 (?<!f)ood #匹配ood,但ood的左边一定不是f #注释 f(?=oo)(?#这个后断言不捕获)
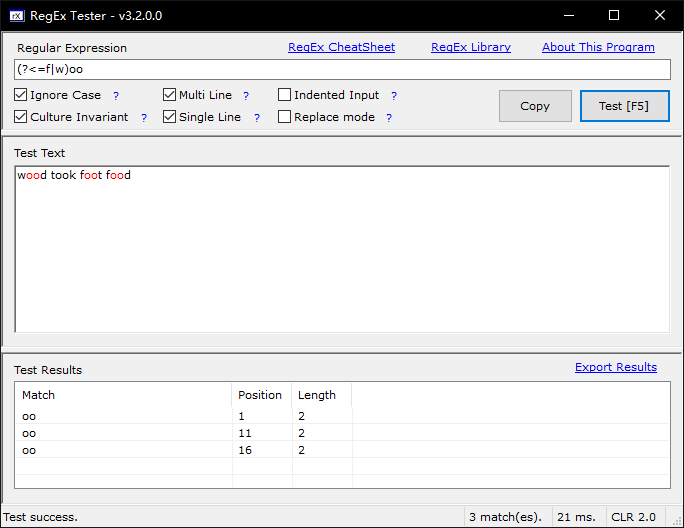
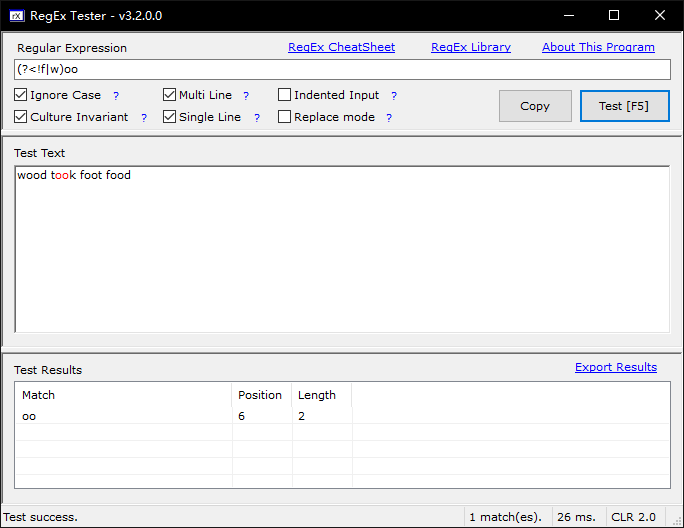
注意: 断言会不会捕获呢?也就是断言占不占分组号呢?
断言不占分组号。断言如同条件,只是要求匹配必须满⾜断言的条件。
分组和捕获是同一个意思。
使用正则表达式时,能用简单表达式,就不要复杂的表达式。
范例:
import re a = 'wood took foot food' findall = re.findall('f(?=oo)', a) print(findall) # ['f', 'f']
贪婪与非贪婪
默认是贪婪模式,也就是说尽量多匹配更长的字符串。
非贪婪很简单,在重复的符号后面加上一个?问号,就尽量的少匹配了。
代码 说明 举例
*? 匹配任意次,但尽可能少重复
+? 匹配至少1次,,但尽可能少重复
?? 匹配0次或1次,,但尽可能少重复
{n,}? 匹配至少n次,但尽可能少重复
{n,m}? 匹配至少n次,至多m次,但尽可能少重复
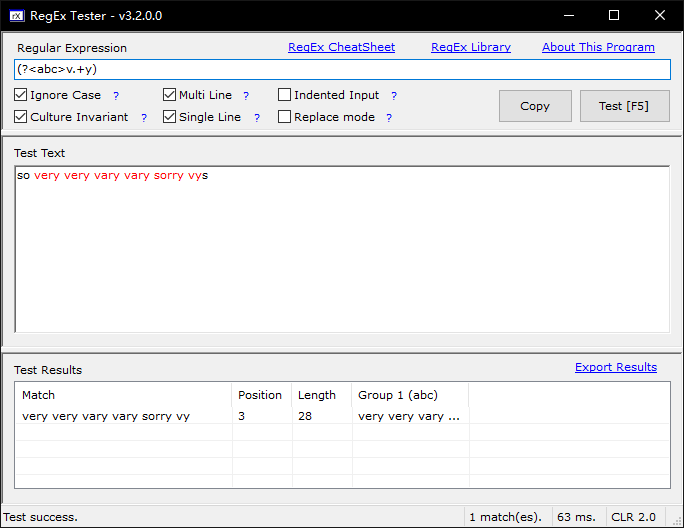
very very happy 使用v.*y和v.*?y #so very very vary vary sorry vys v.*y #贪婪,尽可能多匹配。匹配very very vary vary sorry vy v.*?y #非贪婪, 尽可能短。匹配very、 very、 vary、 vary、vy v.+?y #非贪婪,尽可能短。匹配very、 very 、vary、vary v.??y #非贪婪,匹配0次或1次。匹配vy v.{2,}?y #非贪婪,匹配2次。匹配very、 very 、vary、vary
如果要使用非贪婪,则加一个 ? ,上面的例子修改如下:
import re a = 'java*&39android##@@python' # 贪婪与非贪婪 re_findall = re.findall('[a-z]{4,7}?', a) print(re_findall)
输出结果如下:
['java', 'andr', 'pyth']
引擎选项
IgnoreCase 匹配时忽略大小写。如re.I re.IGNORECASE Singleline 单行模式,即整个测试文本被认为是单行。可以匹配所有字符,包括\n。如re.S re.DOTALL Multiline 多行模式,^行首、$行尾。如re.M re.MULTLINE IgnorePatternWhitespace 忽略表达式中的空白字符,如果要使用空白字符用转义,#可以用来做注释。 如re.X re.VERBOSE
- 默认模式:将整个测试字符串看做一个一行的大字符串,.不能代表\n
- 单行模式:将整个测试字符串看做一个一行的大字符串,.可以匹配\n
- 多行模式:终于可以把一行大字符串用\n分割成多行,^指的是行首,$行尾,.行为不变
单行模式: . 可以匹配所有字符,包括换行符 ^ 表示整个字符串的开头,$整个字符串的结尾 多行模式 . 可以匹配除了换行符之外的字符,多行不影响.点号 ^ 表示行首,$行尾,只不过这里的行是每一行 默认模式:可以看做待匹配的文本是一行,不能看做多行,.点号不能匹配换行符,^和$表示行首和行尾,而行首行尾就是整个字符的开头和结尾 单行模式:基本和默认模式一样,只是.点号终于可以匹配任意一个字符包括换行符,这时所有文本就是一个长长的只有一行的字符串。^就是这一行字符串的行首,$就是这一行的行尾。 多行模式:重新定义了行的概念,但不影响.点号的行为,^和$还是行首行尾的意思,只不过因为多行模式可以识别换行符了。“开始”指的是\n后紧接着下一个字符;“结束”指的是\n前的字符,注意最后一行结尾可以没有\n 简单讲,单行模式只影响.点号行为,多行模式重新定义行影响了^和$ 注意:字符串看不见的换行符,\r\n会影响e$的测试,e$只能匹配e\n
范例
so very very sorry vys ray v.*y 匹配,整个看做一行,从very 到sorry,遇到\n不能突破,后面再匹配vys ray so =very very sorry= =vys ray= v.*y 单行模式匹配,可以突破\n =very very sooryvys ray= ^v.*y 单行模式匹配。 空 ^v.*y 默认匹配。 空 v.*y 多行模式匹配 so =very very sorry= =vys ray= ^v.*y 多行模式匹配 =vys ray= ^v.*y 单行和多行模式匹配 =vys ray= ^v.*y$ 单行模式匹配。 空
正则习题
匹配1个0~999之间的任意数字
1 12 885 9999 102 02 003 4d
\d 1位数 [1-9]?\d 1-2位数 ^[1-9]?\d\d? 1-3位数 ^([1-9]\d\d?|\d) 1-3位数 ^([1-9]\d\d?|\d)$ 1-3位数的行 ^([1-9]\d\d?|\d)\r?$ ^([1-9]\d\d?|\d)(?!\d) 数字开头1-3位数且之后不能是数字,注意9999
IP地址
匹配合法的IP地址
192.168.1.150 0.0.0.0 255.255.255.255 17.16.52.100 172.16.0.100 400.400.999.888 001.022.003.000 257.257.255.256
IPV4
(\d{1,3}\.){3}\d{1,3}
([0-2]?\d\d?\.){3}
((25[0-5]|2[0-4]\d|[01]?\d\d?)\.){3}
((25[0-5]|2[0-4]\d|[01]?\d\d?)\.){3}(25[0-5]|2[0-4]\d|[01]?\d\d?)
(?<![0-9])(?:(?:25[0-5]|2[0-4][0-9]|[0-1]?[0-9]{1,2})[.](?:25[0-5]|2[0-4][0-9]|[0-1]?[0-9]{1,2})[.](?:25[0-5]|2[0-4][0-9]|[0-1]?[0-9]{1,2})[.](?:25[0-5]|2[0-4][0-9]|[0-1]?[0-9]{1,2}))(?![0-9])
提取文件名
选出含有ftp的链接,且文件类型是gz或者xz的文件名
ftp://ftp.astron.com/pub/file/file-5.14.tar.gz ftp://ftp.gmplib.org/pub/gmp-5.1.2/gmp-5.1.2.tar.xz ftp://ftp.vim.org/pub/vim/unix/vim-7.3.tar.bz2 http://anduin.linuxfromscratch.org/sources/LFS/lfs-packages/conglomeration//iana-etc/iana-etc-2.30.tar.bz2 http://anduin.linuxfromscratch.org/sources/other/udev-lfs-205-1.tar.bz2 http://download.savannah.gnu.org/releases/libpipeline/libpipeline-1.2.4.tar.gz http://download.savannah.gnu.org/releases/man-db/man-db-2.6.5.tar.xz http://download.savannah.gnu.org/releases/sysvinit/sysvinit-2.88dsf.tar.bz2 http://ftp.altlinux.org/pub/people/legion/kbd/kbd-1.15.5.tar.gz http://mirror.hust.edu.cn/gnu/autoconf/autoconf-2.69.tar.xz http://mirror.hust.edu.cn/gnu/automake/automake-1.14.tar.xz
ftp.*\.(xz|gz)$ ftp.*/.+\.(xz|gz)$ (?<=.*ftp.*/)[^/\s]+\.(?:xz|gz)$
匹配邮箱地址
test@hot-mail.com [email protected] [email protected] [email protected] a@w-a-com
\w[\w-.]+@[\w-.]+ \w[\w-.]+@\w[\w-]*(\.[a-zA-z0-9]+)+ \w[\w-.]+@\w[\w-]*(\.\w+)+
匹配html标记
提取href中的链接url,提取文字“CiCi”
<a href='http://www.cici.com/index.html' target='_blank'>CiCi</a>
>(\w+)< 拿分组 拿href中内容 (?<=href\s*=\s*['"]?)[^\s'"<>]+ 断言复杂 href\s*=\s*['"]?([^\s'"<>]+) 拿分组
匹配URL
http://www.cici.com/index.html https://login.cici.com file:///ect/sysconfig/network
(\w+)://[^\s'"]+
匹配二代中国身份证ID
321105700101003 321105197001010030 11210020170101054X 17位数字+1位校验码组成 前6位地址码,8位出生年月,3位数字,1位校验位(0-9或X) 地址码+出生日期码+顺序码+校验码 # 格式說明 # ┌──省份(第1-2位) # │ ┌──城市(第3-4位) # │ │ ┌──区县(第5-6位) # │ │ │ ┌─出生年 月 日(第7-14位) # │ │ │ │ ┌─顺序码(第15-17位,第17位代表性别,奇数为男性偶数为女性) # │ │ │ │ │ ┌─校验码(第18位,校验正确性。第18位如果计算出来是10,身份号就变成19位号了,用X代替10,罗马数字X表示10) # │ │ │ │ │ │ # xxxxxx xxxxxxxx xxx x
\d{17}[\dXx]|\d{15}
路径操作
路径操作模块
https://docs.python.org/3/library/os.path.html
# coding: utf-8 #os 模块常用函数 os.path模块 from os import path #拼接 p1 = path.join('d:/tmp', 'conf', 'a/b') #拼接 print(p1, type(p1)) #b basename基名, d:/tmp/conf/a 路径名dirname print(p1.split('/')) #str.split print(path.split(p1)) #p1:str 一刀, replit, sep \ / #: d:/tmp\conf\a/b <class 'str'> #: ['d:', 'tmp\\conf\\a', 'b'] #: ('d:/tmp\\conf\\a', 'b') #分隔 d, b = path.split(p1) #切成路径名和基名 print(d, b) #: d:/tmp\conf\a b print(path.split(d)) #: ('d:/tmp\\conf', 'a') print(d, path.dirname(d), path.basename(d)) #: d:/tmp\conf\a d:/tmp\conf a print(path.exists('d:/tmp')) #存在 print(path.exists('d:/tmp/test')) print(path.splitdrive('d:/tmp/test')) #仅windows,区分驱动器 print(path.abspath('d:/tmp/test')) #对应的绝对路径 print(__file__) #当前文件自己的路径 print(path.isdir('d:/')) # d盘的/是目录吗 print(path.isfile('d:/tmp/test')) # 是文件吗 #: True #: True #: ('d:', '/tmp/test') #d:\tmp\test #<stdin> #True #True #遍历,打印父目录 p = 'd:/tmp/test' while p != path.dirname(p): p = path.dirname(p) print(p) #d:/tmp #d:/
3.4版本开始,建议使用pathlib模块,提供Path对象来操作。包括目录和文件。
Path类
从3.4开始python提供了pathlib模块,使用path类操作目录更加方便。
https://docs.python.org/3/library/pathlib.html
# coding: utf-8 from pathlib import Path #内部调用的os.path #获取当前路径对象 print(Path(), Path(''), Path('.')) #会检查当前操作系统,并返回当前系统支持的操作对象 WindowsPath('.') print(Path().absolute()) #绝对路径 WindowsPath('D:/project/pyprojs') import os print(os.path.abspath(''), os.path.abspath('.')) #绝对路径,相比Path类使用复杂些 #字符串显现方法,路径拼接 p = Path('/etc/', 'sysconfig', 'c/d') print(p) #自动调整。windows 下: \etc\sysconfig\c\d print(str(p), repr(p), bytes(p)) #p 内部调用的是repr : \etc\sysconfig\c\d WindowsPath('/etc/sysconfig/c/d') b'\\etc\\sysconfig\\c\\d' #bytes(p) == str(p).encode() print(Path('.', 'a', 'b/c', '', Path(''), Path('e/f'))) #WindowsPath('a/b/c/e/f') print(Path('a') / 'b/c') # / 运算符重载 #: a\b\c print(Path('a') / 'b/c' / '' / Path('d')) #: a\b\c\d print('a/b' / Path('c', 'd', Path('e/f'))) #: a\b\c\d\e\f #print('a/b' / 'c/d' / Path('e/f')) # 报错,字符不能相除 print('a/b' / ('c/d' / Path('e/f'))) #a\b\c\d\e\f #str / Path => Path #Path / Path => Path #Path / str => Path #str / str 错的 # 由哪些部分组成 p = ('a/b' / ('c/d' / Path('e/f'))) print(p.parts) #('a', 'b', 'c', 'd', 'e', 'f') p1 = ('/a/b' / ('c/d' / Path('e/f'))) print(p1.parts) #绝对路径,多了根 ('\\', 'a', 'b', 'c', 'd', 'e', 'f') print(p1.parent) #取父路径 \a\b\c\d\e print(p1.parent.parent.parent.parent.parent.parent) #取父路径 \ print(p1.parent.joinpath('d1', 'd2/d3', Path('d4', 'd5'))) #路径拼接 \a\b\c\d\e\d1\d2\d3\d4\d5 l = p1.parents #惰性对象 print(list(l), p1) #父路径,是由近及远 #[WindowsPath('/a/b/c/d/e'), WindowsPath('/a/b/c/d'), WindowsPath('/a/b/c'), WindowsPath('/a/b'), WindowsPath('/a'), WindowsPath('/')] \a\b\c\d\e\f
初始化
# coding: utf-8 from pathlib import Path p = Path() #当前目录,Path() Path('.') Path('') p = Path('a', 'b', 'c/d') #当前目录下的 a/b/c/d p = Path('/etc', Path('sysconfig'), 'network/ifcfg') #根下的etc目录
路径拼接
操作符 /
- Path对象 / Path对象
- Path对象 / Path对象
- 字符串 / Path对象
joinpath
- joinpath(*other) 在当前Path路径上连接多个字符串返回新路径对象
# coding: utf-8 from pathlib import Path p1 = ('/a/b' / ('c/d' / Path('e/f'))) print(p1.parent) #取父路径 \a\b\c\d\e print(p1.parent.joinpath('d1', 'd2/d3', Path('d4', 'd5'))) #路径拼接 \a\b\c\d\e\d1\d2\d3\d4\d5
分解
parts 属性,会返回目录各部分的元组
# coding: utf-8 from pathlib import Path p = Path('/a/b/c/d') print(p.parts) #最左边的是/是根目录 #: ('\\', 'a', 'b', 'c', 'd')
获取路径
str 获取路径字符串
bytes 获取路径字符串的 bytes
from pathlib import Path p = Path('/etc') print(str(p), bytes(p)) #: \etc b'\\etc'
父目录
parent 目录的逻辑父目录
parents 父目录惰性可迭代对象,索引0是直接的父
# coding: utf-8 from pathlib import Path p = Path('/data/mysql/install/my.tar.gz') print(p.parent) #: \data\mysql\install for x in p.parents: #可迭代对象 print(x) #: \data\mysql\install #: \data\mysql #: \data #: \ #相对路径 p = Path('data/mysql/install/my.tar.gz') #路径系统当中,2特殊的目录 # . 引用,对当前目录自身的引用 # .. 对当前目录的父目录的引用 print(p.parent) #data\mysql\install for x in p.parents: #可迭代对象 print(x) #data\mysql\install #data\mysql #data #. print(list(p.parents)) #[WindowsPath('data/mysql/install'), WindowsPath('data/mysql'), WindowsPath('data'), WindowsPath('.')]
目录组成部分
name、stem、suffix、suffixes、with_suffix(suffix)、with_name(name)
- name 目录的最后一个部分
- stem 目录最后一个部分,没有后缀
- suffix 目录最后一个部分的扩展名
- name = stem + suffix
suffixes 返回多个扩展名列表
- with_suffix(suffix) 有扩展名则替换,无则补充扩展名
- with_name(name)替换目录最后一个部分并返回一个新的路径
# coding: utf-8 from pathlib import Path p = Path('/data/mysql/my.tar.gz') print(p.exists()) #: False print(p.name, p.parent) #路径成分 基名 父目录 : my.tar.gz \data\mysql print(p.suffix, p.suffixes, p.stem) #文件扩展名 : .gz ['.tar', '.gz'] my.tar print(p.with_name('config')) #换基名 : \data\mysql\config print(p.parent.with_name('config')) #换基名 : \data\config print(p.parent.parent / 'redis') #换基名: \data\redis print(p.with_suffix('.xz')) #换扩展名 : \data\mysql\my.tar.xz
全局方法
- cwd() 返回当前工作目录
- home() 返回当前家目录
# coding: utf-8 from pathlib import Path p = 'd:/tmp' print(Path(p).cwd(), Path.cwd()) # 当前工作路径不会随着你路径的变化而变化,相当于常量,通过任何路径都可以方便调用到当前工作路径 #家目录也是一样,相当于常量 print(Path('abc').home(), Path.home())
判断方法
- exists() 目录或文件是否存在
- is_dir() 是否是目录,目录存在返回True
- is_file() 是否是普通文件,文件存在返回True
- is_symlink() 是否是软链接
- is_socket() 是否是socket文件
- is_block_device() 是否是块设备
- is_char_device() 是否是字符设备
- is_absolute() 是否是绝对路径
注意: 文件只有存在 ,才能知道它是什么类型文件
范例:
# coding: utf-8 from pathlib import Path p1 = Path('/dev') print((p1 / 'bus').is_dir()) print((p1 / 'console').is_char_device()) print((p1 / 'cdrom').is_symlink()) print((p1 / 'cdrom').is_file()) print((p1 / 'abcdea').is_file()) #不知道是谁,False. 内部调用了exits()目录或文件是否存在 print(p1.is_absolute())
绝对路径
- resolve() 非windows,返回一个新的路径,这个新路径就是当前Path对象的绝对路径。如果是软链接则直接被解析
- absolute() 获取绝对路径
范例
# coding: utf-8 from pathlib import Path p1 = Path('/dev') print((p1 / 'cdrom').is_symlink()) print((p1 / 'cdrom').absolute()) print((p1 / 'cdrom').resolve()) #如果是软链接返回真实路径 #True #/dev/cdrom #/dev/sr0
其它操作
- rmdir() 删除空目录。没有提供判断目录为的方法
- touch(mode=0o666, exist_ok=True) 创建一个文件
- as_uri() 将路径返回成URI,例如'file:///etc/passwd'
mkdir(mode=0o777, parents=False, exist_ok=False)
parents 是否创建父目录,True等同于mkdir -p。False时,父目录不存在,则抛出FileExistsError被忽略
exist_ok 在3.5版本加入。False时,路径存在,抛出FileExistsError; True时 FileExistsError被忽略
- iterdir() 迭代当前目录,不递归
# coding: utf-8 from pathlib import Path p = Path('d:/tmp/mydir') p.mkdir(parents=True, exist_ok=True) print(p.is_file()) #返回False print(p.exists()) #返回True print(list(p.absolute().iterdir())) #返回[] 遍历目录,iterdir方法遍历,返回生成器对象,遍历目录不递归 (p / 'd1').mkdir(exist_ok=True) #创建目录 (p / 'c1/c2/c3').mkdir(parents=True, exist_ok=True) #创建目录,mkdir -p (p / 'c1/a.py').touch() #创建文件 (p / '../a.py').touch() #创建文件 #遍历父路径 for x in (p / 'd1').parent.iterdir(): print(x) #: d:\tmp\mydir\c1 #: d:\tmp\mydir\d1
范例:d:/tmp下的所有文件,不递归,判断是否为空目录,判断文件类型
# coding: utf-8 from pathlib import Path p = Path('d:/tmp/c1/c2') #可以用parents操作,也可以用parent操作 #print(list(p.parents)) #for x in p.parents[len(p.parents)-2].iterdir(): #不支持负索引 for x in p.parent.parent.iterdir(): print(x, type(x)) if x.is_dir(): print('dir', x) # flag = False #不为空 # for z in x.iterdir(): # flag = True # break # print('Not empty' if flag else 'Empty') print('Not empty' if next(x.iterdir(), False) else 'Empty') #next(迭代对象, False) 如果没有返回False elif x.is_file(): print('file', x) else: print('other', x)
- stat 相当于stat -L命令,跟踪软链接
- lstat 使用方法同stat(),但如果是符号链接,则显示符号链接本身的文件信息。
# coding: utf-8 from pathlib import Path p1 = Path('/dev/') print((p1 / 'cdrom').is_symlink()) print((p1 / 'cdrom')) print((p1 / 'cdrom').stat()) #会跟踪软链接,是真实路径的状态 print((p1 / 'cdrom').resolve()) print((p1 / 'cdrom').resolve().stat()) #True #/dev/cdrom #os.stat_result(st_mode=25008, st_ino=160, st_dev=5, st_nlink=1, st_uid=0, st_gid=24, st_size=0, st_atime=1735647858, st_mtime=1735647858, st_ctime=1735647858) #/dev/sr0 #os.stat_result(st_mode=25008, st_ino=160, st_dev=5, st_nlink=1, st_uid=0, st_gid=24, st_size=0, st_atime=1735647858, st_mtime=1735647858, st_ctime=1735647858)
通配符
- glob(pattern) 通配给定的模式,返回生成器对象
- rglob(pattern) 通配给定的模式,递归目录,返回生成器对象
- ? 代表一个字符
- * 表示任意个字符
- [abc]或[a-z]表示一个字符
# coding: utf-8 from pathlib import Path #通配符,不是正则表达式 p1 = Path('d:/tmp') print(p1.glob('*')) #当前目录下所有文件,返回可迭代对象: <generator object Path.glob at 0x0000027452864120> print(p1.glob('*.py')) #当前目录下所有.py文件 print(p1.glob('*/*/*.py')) #当前目录下子目录下所有.py文件 print(p1.glob('**/*.py')) #当前目录下任意目录下所有.py文件 #? 一个 p1.glob('**/[a-z]*.??') #[a-z]*.?? 代表a到z任意一个字符后面跟任何字符,再接个.?? p1.rglob('**/[a-z]*.??') #递归glob,层级就不用写了
文件操作
Path.open(mode='r', buffering=-1, encoding=None, errors=None, newline=None)
使用方法类似内建函数open。返回一个文件对象
3.5增加了新函数
Path.read_bytes() 以 'rb' 读取路径对应文件,并返回二进制流。看源码
Path.read_text(encoding=None, errors=None) 以'rt'方式读取路径对应文件,返回文本
Path.write_bytes(date) 以'wb'方式写入数据到路径对应文本
Path.write_text(date, encoding=None, errors=None) 以'wt'方式写入字符串到路径对应文件
open()函数文件操作
# coding: utf-8 from pathlib import Path p = Path('d:/tmp/a.py') with open(p, 'w+') as f: #open文件参数可以是 Path对象、字符串、文件对象 f.write('abc') f.seek(0) print(f.read())
Path类中的文件操作
# coding: utf-8 from pathlib import Path p = Path('d:/tmp/a.py') p.write_text('abc') #内部用了open(mode='w') p.write_bytes(b'abc') #内部用了open(mode='wb') print(p.read_text()) #open(mode='rt') print(p.read_bytes()) #open(mode='rb') #: abc #: b'abc' with p.open() as f: #self.open(mode, ...) open(file, mode) print(f.read())
os模块
操作系统平台
os.namewindows是nt,linux是posixos.uname()*nix支持sys.platformwindows显示win32, linux显示linux
os.listdir('d:/tmp') 返回指定目录内容列表,不递归
os也有open、read、write等方法,但是太底层,建议使用内建函数open、read、write,使用方式相似
os.stat(path, *, dir_fd=None, follow_symlinks=True) 本质上调用linux系统的stat
# coding: utf-8 import os import sys print(os.name, sys.platform) #: nt win32 print(os.listdir('d:/tmp')) #返回字符串列表,就不递归 print(os.path.isdir('d:/tmp')) print(os.stat('d:/tmp/test')) #mode=33188 print(os.lstat('d:/tmp/test')) print(oct(31888)) #八进制 0o76220 权限为rwww
os.chmod(path, mode, *, dir_fd=None, follow_symlinks=True)
os.chmod('test', 0o777)
os.chown(path, uid, git) 改变文件的属性、属组,但需要足够的权限
shutil模块
文件拷贝:使用打开2文件对象,源文件读取内容,写入目标文件中来完成拷贝过程。但是这样丢失stat数据信息(权限等),因为根本没有复制这些信息过去。
目录复制又怎么办呢?
Python提供了一个方便的库shutil(高级文件操作)
copy 复制
copyfileobj(fsrc, fdst[, length])
- 文件对象的复制,fsrc和fdst是open打开的文件对象,复制内容。fdst要求可写。
- length指定了表示buffer的大小
- 阅读copyfileobj函数。
copyfile(src, dst, *, follow_symlinks=True)
- 复制文件内容,不含元数据。src、dst为文件的路径字符串。
- 本质上调用的就是copyfileobj,所以不带元数据二进制内容复制。
copymode(src, dst, *, follow_symlinks=True)
- 仅复制权限
copystat(src, dst, *, follow_symlinks=True)
- 复制文件权限和元数据
copy(src, dst, *, follow_symlinks=True)
- 内部用了copyfile() 和 copymode()
copy2(src, dst, *, follow_symlinks=True)
- 内部用了copyfile() 和 copystat()
# coding: utf-8 from pathlib import Path import shutil src = Path('d:/tmp/test') dst = Path('d:/tmp/t.txt') with open(src, 'rb') as fsrc: with open(dst, 'wb') as fdst: #从src读取,写入dst shutil.copyfileobj(fsrc, fdst) shutil.copyfile(src,dst) #实际上是上面的实现。 shutil.copymode(src,dst) #复制权限 shutil.copystat(src,dst) #stat 全面元数据,包括mode shutil.copy(src,dst) #copyfile copymode shutil.copy2(src,dst) #copyfile copystat
copytree(src, dst, symlinks=False, ignore=None, copy_function=copy2, ignore_dangling_symlinks=False)
- 递归复制目录。默认使用copy2,也就是带更多的元数据复制。
- src, dst必须是目录,src必须存在,dst必须不存在。
- ignore = func ,提供一个callable(src, names) -> ignored_names。 提供一个函数,它会被调用。 src是源目录,names是os.listdir(src)的结果,就是列出src中的文件名,返回值是要被过滤的文件的set类型数据。
# coding: utf-8 from pathlib import Path import shutil src = Path('d:/tmp/d1') #递归copy d1 子文件 dst = Path('d:/tmp/dx') #shutil.copytree(src, dst) #源目录递归copy到dst,要求目标路径不能存在 def fn(src, files): #src, name表示src所有直接的文件 # print(src, files) #d:/tmp/d1 ['b.txt', 'd2'] # ignore_names = set() #集合解析式 # for name in names: #不要copy .py文件 #文件名字符串列表 # print(name, type(name)) # if name.endswith('.py') or name.endswith('.txt'): # ignore_names.add(name) # return ignore_names #返回可迭代对象 #return { name for name in names if name.endswith('.py') or name.endswith('.txt')} return set(filter(lambda name: name.endswith('.py') or name.endswith('.txt'), names)) #可迭代对象。filter返回一个迭代器,用完就没了。所以这里用set() 变为可迭代对象。 shutil.rmtree('d:/tmp/dx', ignore_errors=True) #删除目录 shutil.copytree(src, dst, ignore=fn) #源目录递归copy到dst,要求目标路径不能存在
rm 删除
shutil.rmtree(path, ignore_errors=False, onerror=None)
递归删除。如同rm -fr一样危险,慎用。
shutil.rmtree('d:/tmp') #类似rm -fr
move 移动
move(src, dst, copy_function=copy)
递归移动文件、目录到目标,返回目标。
本身使用的是 os.rename 方法。
如果不支持rename,如果是目录则copytree再删除源目录
默认使用copy2方法
shutil.move('d:/a', 'd:/aaa') os.rename('d:/t.txt', 'd:/tmp/t') os.rename('test3', 'd:/tmp/taa')
shutil还有打包功能。生成tar并压缩。支持zip, gz, bz, xz。
练习
指定一个源文件,实现copy到目标目录
例如把/tmp/test.txt拷贝到/tmp/test1.txt
单词统计
有一个文件(https://docs.python.org/zh-cn/3.13/library/os.path.html),对其进行单词统计,不区分大小写,并显示单词重复最多的10个单词
单词统计进阶
在上一题的基础上,要求用户可以排除一些单词的统计,例如a, the, of等不应该出现在具有实际意义的统计中,应当忽略。要求全部代码使用函数封装,并调用完成
配置文件转换
有一个配置文件test.ini内容如下,将其转换成json格式文件
[DEFAULT] a = test [mysql] default-character-set=utf8 a = 100 [mysqld] datadir =/dbserver/data port = 33060 character-set-server=utf8 sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES
复制目录
选择一个已存在的目录作为当前工作目录,在其下创建a/b/c/d这样的子目录结构并在这些子目录的不同层级生成50个普通文件,要求文件名由随机4个小写字母构成。
将a目录下所有内容复制到当前工作目录dst目录下,要求复制的普通文件的文件名必须是x, y, z开头。
举例,假设工作目录/tmp,构建的目录结构是/tmp/a/b/c/d。在a, b, c, d目录中放入随机生成的文件,这些文件的名称也是随机生成的。最终把a目录下所有的目录也就是b, c, d目录,和文件名开头是x, y, z开头的文件。
指定一个源文件,实现copy到目标目录
例如把/tmp/test.txt拷贝到/tmp/test1.txt
# coding: utf-8 from os import path import shutil base = 'd:/tmp' src = 'test.txt' dst = 'test1.txt' src = path.join(base, src) dst = path.join(base,dst) with open(src, 'w', encoding='utf-8') as f: f.write('\n'.join(['123','abc', '你好'])) def copy(src, dst): length = 16 * 1024 with open(src, 'rb', ) as f1: with open(dst, 'wb') as f2: while True: buffer = f1.read(length) if not buffer: break f2.write(buffer) copy(src, dst) #shutil.copyfile(src,dst) #shutil.copyfileobj(fsrc,fdst) #shutil.copy(src,dst) #shutil.copy2(src,dst)
复制目录
选择一个已存在的目录作为当前工作目录,在其下创建a/b/c/d这样的子目录结构并在这些子目录的不同层级生成50个普通文件,要求文件名由随机4个小写字母构成。
将a目录下所有内容复制到当前工作目录dst目录下,要求复制的普通文件的文件名必须是x, y, z开头。
举例,假设工作目录/tmp,构建的目录结构是/tmp/a/b/c/d。在a, b, c, d目录中放入随机生成的文件,这些文件的名称也是随机生成的。最终把a目录下所有的目录也就是b, c, d目录,和文件名开头是x, y, z开头的文件。
# coding: utf-8 #准备要用的目录 import shutil from pathlib import Path base = Path('d:/tmp') sub = Path('a/b/c/d') #(base / sub).mkdir(parents=True, exist_ok=True) #路径,需要父路径。 #解一下parentes #print(*sub.parents) #: a\b\c a\b a . 相对路径有个点,要去掉 print(list(sub.parents)[:-1]) #: [WindowsPath('a/b/c'), WindowsPath('a/b'), WindowsPath('a')] dirs = [sub] + list(sub.parents)[:-1] print(dirs) #: [WindowsPath('a/b/c/d'), WindowsPath('a/b/c'), WindowsPath('a/b'), WindowsPath('a')]
# coding: utf-8 #随机文件 import shutil from pathlib import Path from string import ascii_lowercase import random base = Path('d:/tmp/mydir') sub = Path('a/b/c/d') dirs = [sub] + list(sub.parents)[:-1] #: [WindowsPath('a/b/c/d'), WindowsPath('a/b/c'), WindowsPath('a/b'), WindowsPath('a')] #删除目录 if base.exists(): shutil.rmtree(str(base)) #创建目录 (base / sub).mkdir(parents=True, exist_ok=True) #路径,需要父路径。 for i in range(20): name = "".join(random.choices(ascii_lowercase, k=4)) #print(name) (base / random.choice(dirs) / name).touch() #遍历所有文件 print(*list(base.rglob('*')), sep='\n')
# coding: utf-8 #复制目录 import shutil from pathlib import Path from string import ascii_lowercase import random base = Path('d:/tmp/mydir') sub = Path('a/b/c/d') dirs = [sub] + list(sub.parents)[:-1] #: [WindowsPath('a/b/c/d'), WindowsPath('a/b/c'), WindowsPath('a/b'), WindowsPath('a')] #删除目录 if base.exists(): shutil.rmtree(str(base)) #创建目录 (base / sub).mkdir(parents=True, exist_ok=True) #路径,需要父路径。 for i in range(20): name = "".join(random.choices(ascii_lowercase, k=4)) #print(name) (base / random.choice(dirs) / name).touch() #copy headers = set('xyz') def ignore_files(src, names): # return {name for name in names # if name[0] not in headers and Path(src, name).is_file()} return set(filter(lambda name: name[0] not in headers and Path(src, name).is_file(), names)) shutil.copytree(str(base / 'a'), str(base / 'dst'), ignore=ignore_files) #遍历所有文件 print(*(base / 'dst').rglob('*'), sep='\n')
密码强度
要求密码必须由10-15位,指定字符组成:
十进制数字
大写字母
小写字母
下划线
要求四种类型的字符都要出现才算合法的强密码
例如:Aatb32_67mnq,其中包含大写字母、小写字母、数字和下划线,是合格的强密码
^[a-zA-Z0-9_]{10,15}$
但是还是没有解决类似于11111111112这种密码问题,如果解决?
较好的思路:
1. 给一个列表,打标记[0,0,0,0]
2. 首先长度判断
3. 遍历密码原文字符串的字符,判断这个字符是哪一个分类,如果不是上面4类,直接返回非常密码。
如果每一个字符都合格,属于哪个分类就在该分类上标记为1
4. 如果4类都有,则列表为[1,1,1,1],哪一种字符没出现过,就是0
这样既可以判断密码强弱,还知道了密码的强度等级。
配置文件转换
有一个配置文件test.ini内容如下,将其转换成json格式文件
[DEFAULT] a = test [mysql] default-character-set=utf8 a = 100 [mysqld] datadir =/dbserver/data port = 33060 character-set-server=utf8 sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES
代码
import json from configparser import ConfigParser src = 'test.ini' dst = 'test.json' cfg = ConfigParser() cfg.read(src) d = {} for section in cfg.sections(): #不带缺省值 print(section, type(section)) print(cfg.items(section)) # ['mysql', 'mysqld'] # mysql <class 'str'> # [('a', '100'), ('default-character-set', 'utf8')] # mysqld <class 'str'> # [('a', 'test'), ('datadir', '/dbserver/data'), ('port', '33060'), ('character-set-server', 'utf8'), ('sql_mode', 'NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES')] d[section] = dict(cfg.items(section)) print(d) with open(dst, 'w', encoding='utf-8') as f: json.dump(d, f)
查看新文件内容
(.venv) PS D:\project\pyproj> python -m json.tool .\test.json
{
"mysql": {
"a": "100",
"default-character-set": "utf8"
},
"mysqld": {
"a": "test",
"datadir": "/dbserver/data",
"port": "33060",
"character-set-server": "utf8",
"sql_mode": "NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES"
}
}
单词统计
有一个文件(https://docs.python.org/zh-cn/3.13/library/os.path.html),对其进行单词统计,不区分大小写,并显示单词重复最多的10个单词
from collections import defaultdict import re filename = 'sample.txt' d = {} #d = defaultdict(lambda :0) #处理os.path.commonpath(['/usr/lib' #line = "os.path.commonpath(['/usr/lib'" def make_key1(line:str): #line = line.lower() pattern = r"""[~`!@#$%^&*()-_=+|\{}\[\]:;"'<>?/,.\s]+""" ret = re.split(pattern, line) return ret def make_key2(line:str): #line = line.lower() chars = set(r"""~`!@#$%^&*()-_=+|\{}[]:;"'<>?/,.""") ret = [] for c in line: if c in chars: ret.append(' ') else: ret.append(c) return ''.join(ret).split() with open(filename, encoding='utf-8') as f: for line in f: #逐行处理 #不区分大小写 # line = line.lower() # words = line.split() # for word in words: # for word in map(lambda x:x.lower(), make_key1(line)): for word in map(str.lower, make_key1(line)): # print(word) #d[word] += 1 d[word] = d.get(word, 0) + 1 print(sorted(d.items(), key=lambda item:item[1], reverse=True) ) # for k in d.keys(): # if k.find('path') > -1: # print(k) print(*filter(lambda k: k.find('path') > -1, d.keys()), sep='\n') def make_key3(line:str): #line = line.lower() chars = set("""~`!@#$%^&*()-_=+|\{}[]:;"'<>?/,.\n\r\t""") ret = [] start = 0 length = len(line) for i,c in enumerate(line): if c in chars: if start == i: start = i + 1 continue ret.append(line[start:i]) start = i + 1 #假定下一个字符是OK的 else: if start < length: ret.append(line[start:]) return ret line = "os.path.commonpath(['/usr/lib'" print(make_key3(line)) def make_key4(line:str): #line = line.lower() chars = set("""~`!@#$%^&*()-_=+|\{}[]:;"'<>?/,.\n\r\t""") # ret = [] start = 0 length = len(line) for i,c in enumerate(line): if c in chars: if start == i: start = i + 1 continue # ret.append(line[start:i]) yield line[start:i] start = i + 1 #假定下一个字符 else: if start < length: # ret.append(line[start:]) yield line[start:] line = "os.path.commonpath(['/usr/lib'" print(*make_key4(line))
from collections import defaultdict import re filename = 'sample.txt' #d = defaultdict(lambda :0) #处理os.path.commonpath(['/usr/lib' #line = "os.path.commonpath(['/usr/lib'" regex = re.compile(r"""[~`!@#$%^&*() -_=+|\{}\[\]:;"'<>?/,.\s]+""") def make_key1(line:str): #line = line.lower() ret = regex.split(line) return ret chars = set("""~`!@#$%^&*()-_=+|\{}[]:;"'<>?/,. \n\r\t""") def make_key2(line:str): #line = line.lower() ret = [] for c in line: if c in chars: ret.append(' ') else: ret.append(c) return ''.join(ret).split() def make_key3(line:str): #line = line.lower() ret = [] start = 0 length = len(line) for i,c in enumerate(line): if c in chars: if start == i: start = i + 1 continue ret.append(line[start:i]) start = i + 1 #假定下一个字符是OK的 else: if start < length: ret.append(line[start:]) return ret def make_key4(line:str): start = 0 length = len(line) for i,c in enumerate(line): if c in chars: if start == i: start = i + 1 continue yield line[start:i] start = i + 1 #假定下一个字符 else: if start < length: yield line[start:] def wordcount(filename, enconding='utf-8', ignore=None): d = {} with open(filename, encoding='utf-8') as f: for line in f: #逐行处理 for word in map(str.lower, make_key4(line)): d[word] = d.get(word, 0) + 1 return d def topN(d:dict, n:int=10): return sorted(d.items(), key=lambda item:item[1], reverse=True)[:n] t = topN(wordcount(filename)) print(t)
单词统计进阶
在上一题的基础上,要求用户可以排除一些单词的统计,例如a, the, of等不应该出现在具有实际意义的统计中,应当忽略。要求全部代码使用函数封装,并调用完成
import re filename = 'sample.txt' #处理os.path.commonpath(['/usr/lib' #line = "os.path.commonpath(['/usr/lib'" regex = re.compile(r"""[~`!@#$%^&*()-_=+|\{}\[\]:;"'<>?/,.\s]+""") def make_key1(line:str): #line = line.lower() ret = regex.split(line) return ret chars = set("""~`!@#$%^&*()-_=+|\{}[]:;"'<>?/,. \n\r\t""") def make_key2(line:str): #line = line.lower() ret = [] for c in line: if c in chars: ret.append(' ') else: ret.append(c) return ''.join(ret).split() def make_key3(line:str): #line = line.lower() ret = [] start = 0 length = len(line) for i,c in enumerate(line): if c in chars: if start == i: start = i + 1 continue ret.append(line[start:i]) start = i + 1 #假定下一个字符是OK的 else: if start < length: ret.append(line[start:]) return ret def make_key4(line:str): start = 0 length = len(line) for i,c in enumerate(line): if c in chars: if start == i: start = i + 1 continue yield line[start:i] start = i + 1 #假定下一个字符 else: if start < length: yield line[start:] def wordcount(filename, enconding='utf-8', ignore=None): d = {} if ignore is None: #stopwords ignore = set() with open(filename, encoding='utf-8') as f: for line in f: #逐行处理 for word in map(str.lower, make_key4(line)): if word not in ignore: d[word] = d.get(word, 0) + 1 return d def topN(d:dict, n:int=10): # return sorted(d.items(), key=lambda item:item[1], reverse=True)[:n] yield from sorted(d.items(), key=lambda item:item[1], reverse=True)[:n] t = topN(wordcount(filename, ignore={'the', 'is', 'a'})) print(*t)
Python的正则表达式
Python使用re模块提供了正则表达式处理的能力
常量
多行模式 - re.M - re.MULTILINE 单行模式 - re.S - re.DOTALL 忽略大小写 - re.I - re.IGNORECASE 忽略表达式中空白字符 - re.X - re.VERBOSE
方法
编译
re.compile(pattern, flags=0)
- 设定flags,编译模式,返回正则表达式对象regex
- pattern就是正则表达式字符串,flags是选项,指代当前工作模式。正则表达式需要被编译,为了提高效率,这些编译后的结果被保存,下次使用同样的pattern的时候,就不需要再次编译
- re的其他方法为了提高效率都调用了编译方法,就是为了提速
范例
import re #预编译 re.compile('\s', re.S | re.M) #预编译,单行或者多行模式,得到一个正则表达式对象
单次匹配
match
re.match(pattern, string, flags=0) regex.match(string[, pos[, endpos]])
- match匹配从字符串的开头匹配,索引为0的位置,regex对象match方法可以重设定开始位置和结束位置,返回match对象
search
re.search(pattern, string, flags=0) regex.search(string[, pos[, endpos]])
- search匹配从头搜索直到第一个匹配,regex对象search方法可以重设定开始位置和结束位置,返回match对象
fullmatch
re.fullmatch(pattern, string, flags=0) regex.fullmatch(string[, pos[, endpos]])
- 全长完全匹配,整个字符串和正则表达式匹配
范例:加强对match的理解
import re s = """bottle\nbag\nbig\napple""" for i,c in enumerate(s, 1): #查看字符串索引对应关系 print((i-1,c), end='\n' if i%10==0 else '') # (0, 'b')(1, 'o')(2, 't')(3, 't')(4, 'l')(5, 'e')(6, '\n')(7, 'b')(8, 'a')(9, 'g') # (10, '\n')(11, 'b')(12, 'i')(13, 'g')(14, '\n')(15, 'a')(16, 'p')(17, 'p')(18, 'l')(19, 'e') #预编译 #re.compile('\s', re.S | re.M) #预编译,单行或者多行模式,得到一个正则表达式对象 #match 单次匹配, 并不做全文搜索,而且要求必须是从头匹配 索引0 r = re.match('a', s) print(r) #None r = re.match('^a', s) print(r) #None 默认模式,一整行,没有a开头的 r = re.match('^a', s, re.M) print(r) #None 从索引0开始匹配,所以匹配不上 r = re.match('a', s, re.M) print(r) #None #即便是 MULTILINE 多行模式, re.match() 也只匹配字符串的开始位置,而不匹配每行开始 r = re.match('b.+', s, re.S) #匹配不上返回None; #匹配上,得到match类型实例,span (start, end), math=xxx 匹配 print(type(r), r) #<class 're.Match'> <re.Match object; span=[0, 20), match='bottle\nbag\nbig\napple'> print(r.start(), r.end()) #0 20 。匹配从头至尾 print(s[r.start():r.end()].encode()) #b'bottle\nbag\nbig\napple' print(r.string.encode()) #原字符串内容,即s本身内容 b'bottle\nbag\nbig\napple' r = re.match('b.+', s, re.M) #多行模式匹配,但match只做单次匹配,所以只拿到bottle print(type(r), r) #<class 're.Match'> <re.Match object; span=(0, 6), match='bottle'> #match内部用了编译,不需要反复做编译,那么我们可以先编译再match #如果需要多次使用这个正则表达式的话,使用 re.compile() 和保存这个正则对象以便复用,可以让程序更加高效。 regex = re.compile('b.+', re.M) print(regex.match(s)) # 单次匹配 <re.Match object; span=(0, 6), match='bottle'> print(regex.match(s, pos=1)) #pos指定字符串索引位置。 从s的索引1位置即o开始匹配,没匹配到,返回None print(regex.match(s, 7)) #从索引7位置开始匹配,能匹配到 <re.Match object; span=(7, 10), match='bag'> regex = re.compile('b') m = regex.match(s) print(m) #默认模式,从索引0开始匹配,<re.Match object; span=(0, 1), match='b'> regex = re.compile('^b') print(regex.match(s)) #默认模式,从索引0开始匹配,<re.Match object; span=(0, 1), match='b'> regex = re.compile('^a') print(regex.match(s)) #默认模式,从索引0开始匹配,None regex = re.compile('^a', re.M) print(regex.match(s)) #多行模式,从索引0开始匹配,None regex = re.compile('^a', re.M) print(regex.match(s, 8)) #多行模式,从索引8开始匹配,但要求是行首,None regex = re.compile('^a', re.M) print(regex.match(s, 15)) #多行模式,从索引15开始匹配,是行首,<re.Match object; span=(15, 16), match='a'> regex = re.compile('a', re.M) print(regex.match(s, 8)) #多行模式,从索引8开始匹配,<re.Match object; span=(8, 9), match='a'> regex = re.compile('^a',) print(regex.match(s, 15)) #默认模式,从索引15开始匹配,但a不是行首,None
范例:search匹配
import re s = """bottle\nbag\nbig\napple""" for i,c in enumerate(s, 1): #查看字符串索引对应关系 print((i-1,c), end='\n' if i%10==0 else '') # (0, 'b')(1, 'o')(2, 't')(3, 't')(4, 'l')(5, 'e')(6, '\n')(7, 'b')(8, 'a')(9, 'g') # (10, '\n')(11, 'b')(12, 'i')(13, 'g')(14, '\n')(15, 'a')(16, 'p')(17, 'p')(18, 'l')(19, 'e') #预编译 #re.compile('\s', re.S | re.M) #预编译,单行或者多行模式,得到一个正则表达式对象 #match 单次匹配, 并不做全文搜索,而且要求必须是从头匹配 索引0 #search 是单次匹配,但是从index为0开始向后找,找到一次就算匹配到,找不到返回None。 r = re.search('b', s) print(type(r), r) #<class 're.Match'> <re.Match object; span=(0, 1), match='b'> r = re.search('a', s) print(type(r), r) #<class 're.Match'> <re.Match object; span=(8, 9), match='a'> r = re.search('a', s, re.M) print(type(r), r) #<class 're.Match'> <re.Match object; span=(8, 9), match='a'> r = re.search('^a', s, re.M) print(type(r), r) #<class 're.Match'> <re.Match object; span=(15, 16), match='a'> r = re.search('^a', s) print(type(r), r) #默认模式,整个算一整行。<class 'NoneType'> None #如果需要多次使用这个正则表达式的话,使用 re.compile() 和保存这个正则对象以便复用,可以让程序更加高效。 regex = re.compile('^a') r = regex.search(s) print(r) #None print(regex.search(s, 15)) #默认模式,整个算一整行。不是a开头。并不是多行模式 regex = re.compile('^a', re.M) print(regex.search(s, 15)) #多行模式,a是这一行的行首 <re.Match object; span=(15, 16), match='a'>
范例:fullmatch匹配
import re s = """bottle\nbag\nbig\napple""" for i,c in enumerate(s, 1): #查看字符串索引对应关系 print((i-1,c), end='\n' if i%10==0 else '') # (0, 'b')(1, 'o')(2, 't')(3, 't')(4, 'l')(5, 'e')(6, '\n')(7, 'b')(8, 'a')(9, 'g') # (10, '\n')(11, 'b')(12, 'i')(13, 'g')(14, '\n')(15, 'a')(16, 'p')(17, 'p')(18, 'l')(19, 'e') #预编译 #re.compile('\s', re.S | re.M) #预编译,单行或者多行模式,得到一个正则表达式对象 #match 单次匹配, 并不做全文搜索,而且要求必须是从头匹配 索引0 #search 是单次匹配,但是从index为0开始向后找,找到一次就算匹配到,找不到返回None。 #fullmatch 是单次匹配,要求指定区间全部匹配 r = re.fullmatch('b.+', s) print(type(r), r) #<class 'NoneType'> None r = re.fullmatch('bag', s) print(type(r), r) #<class 'NoneType'> None r = re.fullmatch('b.+', s, re.S) print(type(r), r) #<class 're.Match'> <re.Match object; span=(0, 20), match='bottle\nbag\nbig\napple'> #如果需要多次使用这个正则表达式的话,使用 re.compile() 和保存这个正则对象以便复用,可以让程序更加高效。 r = re.compile('bag') print(r.fullmatch(s, 7)) #None print(r.fullmatch(s, 7, 11)) #None 区间前包后不包 [7, 11) print(r.fullmatch(s, 7, 10)) #<re.Match object; span=(7, 10), match='bag'> print(r.fullmatch(s, 7, 9)) #None r = re.compile('^bag') print(r.fullmatch(s, 7, 10)) #默认模式,bag不是首行。None r = re.compile('^bag', re.M) print(r.fullmatch(s, 7, 10)) #多行模式,bag是行首,并且在指定区间内匹配<re.Match object; span=(7, 10), match='bag'>
全文搜索
findall
re.findall(pattern,string,flags=0) regex.findall(string[, pos[, endpos]])
- 对整个字符串,从左至右匹配,返回所有匹配项的列表,里面是str
finditer
re.finditer(pattern,string,flags=0) regex.finditer(string[, pos[, endpos]])
- 对整个字符串,从左至右匹配,返回所有匹配项,返回迭代器
- 注意每次迭代返回的是match对象
范例:findall匹配
import re s = """bottle\nbag\nbig\napple""" for i,c in enumerate(s, 1): #查看字符串索引对应关系 print((i-1,c), end='\n' if i%10==0 else '') # (0, 'b')(1, 'o')(2, 't')(3, 't')(4, 'l')(5, 'e')(6, '\n')(7, 'b')(8, 'a')(9, 'g') # (10, '\n')(11, 'b')(12, 'i')(13, 'g')(14, '\n')(15, 'a')(16, 'p')(17, 'p')(18, 'l')(19, 'e') #预编译 #re.compile('\s', re.S | re.M) #预编译,单行或者多行模式,得到一个正则表达式对象 #findall 返回列表,返回匹配的字符串。跟平常理解的正则是一样的 r = re.findall('b', s) print(type(r), r) #<class 'list'> ['b', 'b', 'b'] r = re.findall(r'b\w+', s) print(type(r), r) #<class 'list'> ['bottle', 'bag', 'big'] #如果需要多次使用这个正则表达式的话,使用 re.compile() 和保存这个正则对象以便复用,可以让程序更加高效。 regex = re.compile(r'b\w+') print(regex.findall(s, 1)) #['bag', 'big'] regex = re.compile(r'^b\w+') print(regex.findall(s, 0)) #['bottle'] #match 单次匹配, 并不做全文搜索,而且要求必须是从头匹配 索引0 #search 是单次匹配,但是从index为0开始向后找,找到一次就算匹配到,找不到返回None。 #fullmatch 是单次匹配,要求指定区间全部匹配
范例:finditer匹配
import re s = """bottle\nbag\nbig\napple""" for i,c in enumerate(s, 1): #查看字符串索引对应关系 print((i-1,c), end='\n' if i%10==0 else '') # (0, 'b')(1, 'o')(2, 't')(3, 't')(4, 'l')(5, 'e')(6, '\n')(7, 'b')(8, 'a')(9, 'g') # (10, '\n')(11, 'b')(12, 'i')(13, 'g')(14, '\n')(15, 'a')(16, 'p')(17, 'p')(18, 'l')(19, 'e') #预编译 #re.compile('\s', re.S | re.M) #预编译,单行或者多行模式,得到一个正则表达式对象 #findall 返回列表,返回匹配的字符串。跟平常理解的正则是一样的 #finditer 返回一个迭代器,每一个元素都是match实例 r = re.finditer(r'b\w+', s) print(type(r), r) #<class 'callable_iterator'> <callable_iterator object at 0x00000249B4052B30> for x in r: print(type(x), x) #<class 're.Match'> <re.Match object; span=(0, 6), match='bottle'> #<class 're.Match'> <re.Match object; span=(7, 10), match='bag'> #<class 're.Match'> <re.Match object; span=(11, 14), match='big'> r = re.finditer(r'^b', s) print(type(r), r) #<class 'callable_iterator'> <callable_iterator object at 0x00000179427D27A0> for x in r: print(type(x), x) #<class 're.Match'> <re.Match object; span=(0, 1), match='b'> r = re.finditer(r'^b', s, re.M) print(type(r), r) #<class 'callable_iterator'> <callable_iterator object at 0x0000024685441FF0> for x in r: print(type(x), x) #<class 're.Match'> <re.Match object; span=(0, 1), match='b'> #<class 're.Match'> <re.Match object; span=(7, 8), match='b'> #<class 're.Match'> <re.Match object; span=(11, 12), match='b'> #如果需要多次使用这个正则表达式的话,使用 re.compile() 和保存这个正则对象以便复用,可以让程序更加高效。 #match 单次匹配, 并不做全文搜索,而且要求必须是从头匹配 索引0 #search 是单次匹配,但是从index为0开始向后找,找到一次就算匹配到,找不到返回None。 #fullmatch 是单次匹配,要求指定区间全部匹配
匹配替换
sub
re.sub(pattern, replacement, string, count=0, flags=0) regex.sub(replacement, string, count=0)
- 使用pattern对字符串string进行匹配,对匹配项使用replacement替换,返回的是str
- replacement可是是string、bytes、function
subn
re.subn(pattern, replacement, string, count=0, flags=0) regex.subn(replacement, string, count=0)
- 同sub返回一个元祖(new_string, number_of_subs_made)
范例:sub和subn匹配替换
简单的用str.replace替换, "123".replace('12', 'ab')
import re s = """bottle\nbag\nbig\napple""" for i,c in enumerate(s, 1): #查看字符串索引对应关系 print((i-1,c), end='\n' if i%10==0 else '') # (0, 'b')(1, 'o')(2, 't')(3, 't')(4, 'l')(5, 'e')(6, '\n')(7, 'b')(8, 'a')(9, 'g') # (10, '\n')(11, 'b')(12, 'i')(13, 'g')(14, '\n')(15, 'a')(16, 'p')(17, 'p')(18, 'l')(19, 'e') #预编译 #re.compile('\s', re.S | re.M) #预编译,单行或者多行模式,得到一个正则表达式对象 #sub 模式替换,可以指定至多替换的次数,返回替换结果 r = re.sub(r'b\w+', 'abc', s) print(type(r), r.encode()) #<class 'str'> b'abc\nabc\nabc\napple' r = re.sub(r'b\w+', 'abc', s, count=1) #最多替换1次 print(type(r), r.encode()) #<class 'str'> b'abc\nbag\nbig\napple' r = re.sub(r'b\w+', 'abc', s, count=10) #最多替换10次 print(type(r), r.encode()) #<class 'str'> b'abc\nabc\nabc\napple' regex = re.compile(r'b\w+') print(regex.sub('abc',s, 2).encode()) #b'abc\nabc\nbig\napple' #subn 模式替换,可以指定至多替换的次数,返回元组(替换的结果, 替换的次数) r = re.subn(r'b\w+', 'abc', s, count=10) #最多替换10次 print(type(r), r) #<class 'tuple'> ('abc\nabc\nabc\napple', 3) 返回元组,后面数字是替换的次数 r = re.subn(r'b\w+', 'abc', s, count=1) #最多替换1次 print(type(r), r) #<class 'tuple'> ('abc\nbag\nbig\napple', 1) 返回元组,后面数字是替换的次数 #findall 返回列表,返回匹配的字符串。跟平常理解的正则是一样的 #finditer 返回一个迭代器,每一个元素都是match实例 #match 单次匹配, 并不做全文搜索,而且要求必须是从头匹配 索引0 #search 是单次匹配,但是从index为0开始向后找,找到一次就算匹配到,找不到返回None。 #fullmatch 是单次匹配,要求指定区间全部匹配
分割字符串
re.split(pattern, string, maxsplit=0, flags=0)
范例:split分割匹配
import re s = """bottle\n\t\t\t\t \nbag\nbig\napple""" for i,c in enumerate(s, 1): #查看字符串索引对应关系 print((i-1,c), end='\n' if i%10==0 else '') #(0, 'b')(1, 'o')(2, 't')(3, 't')(4, 'l')(5, 'e')(6, '\n')(7, '\t')(8, '\t')(9, '\t') #(10, '\t')(11, ' ')(12, '\n')(13, 'b')(14, 'a')(15, 'g')(16, '\n')(17, 'b')(18, 'i')(19, 'g') #(20, '\n')(21, 'a')(22, 'p')(23, 'p')(24, 'l')(25, 'e') #预编译 #re.compile('\s', re.S | re.M) #预编译,单行或者多行模式,得到一个正则表达式对象 #split 分割,指定分割符 print(s.split()) #默认使用 \s+ 分割 ['bottle', 'bag', 'big', 'apple'] print(re.split(r'\s+', s, maxsplit=1)) #['bottle', 'bag\nbig\napple'] print(re.split(r'\s+', s)) #['bottle', 'bag', 'big', 'apple'] s = """ os.path.abspath(path) path. ([path)] """ print(re.split(r'\s', s)) #['', 'os.path.abspath(path)', 'path.', '([path)]', ''] print(re.split(r'[\s().\[\]{}]', s)) #['', 'os', 'path', 'abspath', 'path', '', 'path', '', '', '[path', ']', ''] print(re.split(r'[\s().\[\]{}]+', s)) #['', 'os', 'path', 'abspath', 'path', 'path', 'path', ''] #sub 模式替换,可以指定至多替换的次数,返回替换结果 #subn 模式替换,可以指定至多替换的次数,返回元组(替换的结果, 替换的次数) #findall 返回列表,返回匹配的字符串。跟平常理解的正则是一样的 #finditer 返回一个迭代器,每一个元素都是match实例 #match 单次匹配, 并不做全文搜索,而且要求必须是从头匹配 索引0 #search 是单次匹配,但是从index为0开始向后找,找到一次就算匹配到,找不到返回None。 #fullmatch 是单次匹配,要求指定区间全部匹配
分组
- 使用小括号的pattern捕获的数据被放到了组group中
- match、search函数可以返回match对象
- findall返回字符穿列表;finditer返回一个个match对象
如果pattern中使用了分组,如果有匹配的结果,会在match对象中:
- 使用group(N)方式返回对应分组,1到N是对应的分组,0返回整个匹配的字符串,N不写缺省为0
- 如果使用了命名分组,可以使用group(‘name’)的方式取分组
- 也可以使用groups()返回所有组
- 使用groupdict()返回所有命名的分组
范例:分组
import re s = """bottle\n\t\t\t\t \nbag\nbig\napple""" for i,c in enumerate(s, 1): #查看字符串索引对应关系 print((i-1,c), end='\n' if i%10==0 else '') #(0, 'b')(1, 'o')(2, 't')(3, 't')(4, 'l')(5, 'e')(6, '\n')(7, '\t')(8, '\t')(9, '\t') #(10, '\t')(11, ' ')(12, '\n')(13, 'b')(14, 'a')(15, 'g')(16, '\n')(17, 'b')(18, 'i')(19, 'g') #(20, '\n')(21, 'a')(22, 'p')(23, 'p')(24, 'l')(25, 'e') print() #预编译 #re.compile('\s', re.S | re.M) #预编译,单行或者多行模式,得到一个正则表达式对象 #split 分割,指定分割符 #sub 模式替换,可以指定至多替换的次数,返回替换结果 #subn 模式替换,可以指定至多替换的次数,返回元组(替换的结果, 替换的次数) #findall 返回列表,返回匹配的字符串。跟平常理解的正则是一样的 #finditer 返回一个迭代器,每一个元素都是match实例 #match 单次匹配, 并不做全文搜索,而且要求必须是从头匹配 索引0 #search 是单次匹配,但是从index为0开始向后找,找到一次就算匹配到,找不到返回None。 #fullmatch 是单次匹配,要求指定区间全部匹配 #分组 group m = re.match(r'b\w+', s) #分不分组要看正则表达式中有没有括号 print(m) #<re.Match object; span=(0, 6), match='bottle'> print(m.groups()) #() 取分组 m = re.match(r'(b)(\w+)', s) #分不分组要看正则表达式中有没有括号 print(m) #<re.Match object; span=(0, 6), match='bottle'> print(m.groups()) #('b', 'ottle') 取分组 #m = re.search(r'^(a)(\w+)', s) #匹配不到,报错 m = re.search(r'^(a)(\w+)', s, re.M) #分不分组要看正则表达式中有没有括号 print(m) #<re.Match object; span=(21, 26), match='apple'> print(m.groups()) #('a', 'pple') 取分组 m = re.search(r'(a)(\w+)', s, re.M) #分不分组要看正则表达式中有没有括号 print(m) #<re.Match object; span=(14, 16), match='ag'> print(m.groups()) #('a', 'g') 取分组 print(m.group()) #ag 组,组号,从1开始 print(m.group(0)) #m.group() 等价,组0表示<re.Match object; span=(14, 16), match='ag'>中match m = re.search(r'a(\w+)', s, re.M) #分不分组要看正则表达式中有没有括号 print(m) #<re.Match object; span=(14, 16), match='ag'> print(m.groups()) #('g',) 取分组 print(m.group()) #ag 组,组号,从1开始 print(m.group(0)) #m.group() 等价,组0表示<re.Match object; span=(14, 16), match='ag'>中match print(m.group(1)) #g 组,组号,从1开始 m = re.search(r'a\w+', s, re.M) #分不分组要看正则表达式中有没有括号 if m: #如果匹配成功 print(m) #<re.Match object; span=(14, 16), match='ag'> print(m.groups()) #() 取分组 print(m.group()) #ag 组,组号,从1开始 print(m.group(0)) #m.group() 等价,组0表示<re.Match object; span=(14, 16), match='ag'>中match
范例:命名分组
findall用法
import re s = """bottle\n\t\t\t\t \nbag\nbig\napple""" for i,c in enumerate(s, 1): #查看字符串索引对应关系 print((i-1,c), end='\n' if i%10==0 else '') #(0, 'b')(1, 'o')(2, 't')(3, 't')(4, 'l')(5, 'e')(6, '\n')(7, '\t')(8, '\t')(9, '\t') #(10, '\t')(11, ' ')(12, '\n')(13, 'b')(14, 'a')(15, 'g')(16, '\n')(17, 'b')(18, 'i')(19, 'g') #(20, '\n')(21, 'a')(22, 'p')(23, 'p')(24, 'l')(25, 'e') print() #预编译 #re.compile('\s', re.S | re.M) #预编译,单行或者多行模式,得到一个正则表达式对象 #split 分割,指定分割符 #sub 模式替换,可以指定至多替换的次数,返回替换结果 #subn 模式替换,可以指定至多替换的次数,返回元组(替换的结果, 替换的次数) #findall 返回列表,返回匹配的字符串。跟平常理解的正则是一样的 #finditer 返回一个迭代器,每一个元素都是match实例 #match 单次匹配, 并不做全文搜索,而且要求必须是从头匹配 索引0 #search 是单次匹配,但是从index为0开始向后找,找到一次就算匹配到,找不到返回None。 #fullmatch 是单次匹配,要求指定区间全部匹配 #分组 group m = re.search(r'a(?P<tail>\w+)', s, re.M) #分不分组要看正则表达式中有没有括号 if m: #如果匹配成功 print(m) #<re.Match object; span=(14, 16), match='ag'> print(m.groups()) #('g',) 取分组 print(m.group()) #ag 组,组号,从1开始 print(m.group(0)) #m.group() 等价,组0表示<re.Match object; span=(14, 16), match='ag'>中match print() print(m.group(1)) # g 命名分组也有组号 print(m.groupdict()) #{'tail': 'g'} #分组 findall用法 m = re.findall(r'(b\w+)\s+(?P<name2>b\w+)\s+(?P<name3>b\w+)', s) print(type(m), m) #m是什么类型 <class 'list'> [('bottle', 'bag', 'big')] for x in m: #m有几项,能迭代几下?匹配了1下。 print(type(x), x) #<class 'tuple'> ('bottle', 'bag', 'big') m = re.findall(r'(b\w+)\s+\w+\s+b\w+', s) print(type(m), m) #m是什么类型 <class 'list'> ['bottle'] for x in m: #m有几项,能迭代几下?匹配了1下。 print(type(x), x) #<class 'str'> bottle m = re.findall(r'(b\w+)\s+\w+\s+b(\w+)', s) print(type(m), m) #m是什么类型<class 'list'> [('bottle', 'ig')] for x in m: #m有几项,能迭代几下?匹配了1下。 print(type(x), x) #<class 'tuple'> ('bottle', 'ig') #取消分组看看 m = re.findall(r'b\w+\s+b\w+\s+b\w+', s) print(type(m), m) #m是什么类型 <class 'list'> ['bottle\n\t\t\t\t \nbag\nbig'] for x in m: #m有几项,能迭代几下?匹配了1下。 print(type(x), x.encode()) #<class 'str'> b'bottle\n\t\t\t\t \nbag\nbig'
finditer用法
import re s = """bottle\n\t\t\t\t \nbag\nbig\napple""" for i,c in enumerate(s, 1): #查看字符串索引对应关系 print((i-1,c), end='\n' if i%10==0 else '') #(0, 'b')(1, 'o')(2, 't')(3, 't')(4, 'l')(5, 'e')(6, '\n')(7, '\t')(8, '\t')(9, '\t') #(10, '\t')(11, ' ')(12, '\n')(13, 'b')(14, 'a')(15, 'g')(16, '\n')(17, 'b')(18, 'i')(19, 'g') #(20, '\n')(21, 'a')(22, 'p')(23, 'p')(24, 'l')(25, 'e') print() #预编译 #re.compile('\s', re.S | re.M) #预编译,单行或者多行模式,得到一个正则表达式对象 #split 分割,指定分割符 #sub 模式替换,可以指定至多替换的次数,返回替换结果 #subn 模式替换,可以指定至多替换的次数,返回元组(替换的结果, 替换的次数) #findall 返回列表,返回匹配的字符串。跟平常理解的正则是一样的 #finditer 返回一个迭代器,每一个元素都是match实例 #match 单次匹配, 并不做全文搜索,而且要求必须是从头匹配 索引0 #search 是单次匹配,但是从index为0开始向后找,找到一次就算匹配到,找不到返回None。 #fullmatch 是单次匹配,要求指定区间全部匹配 #分组 group #分组 findall用法 #分组 finditer用法 m = re.finditer(r'(b\w+)\s+(?P<name2>b\w+)\s+(?P<name3>b\w+)', s) print(type(m), m) #m是什么类型 <class 'callable_iterator'> <callable_iterator object at 0x00000199F139DF90> for x in m: #m有几项,能迭代几下?匹配了1下。 print(type(x), x) #<class 're.Match'> <re.Match object; span=(0, 20), match='bottle\n\t\t\t\t \nbag\nbig'> print(x.group().encode()) #b'bottle\n\t\t\t\t \nbag\nbig' print(x.groups()) #('bottle', 'bag', 'big') print(x.groupdict()) #以命名方式提取分组 {'name2': 'bag', 'name3': 'big'} m = re.match(r'(b\w+)\s+(?P<name2>b\w+)\s+(?P<name3>b\w+)', s) print(type(m), m) #m是什么类型 <class 're.Match'> <re.Match object; span=(0, 20), match='bottle\n\t\t\t\t \nbag\nbig'> print(m.group().encode()) #b'bottle\n\t\t\t\t \nbag\nbig' print(m.groups()) #('bottle', 'bag', 'big') print(m.groupdict()) #以命名方式提取分组 {'name2': 'bag', 'name3': 'big'}
csv与ini文件
csv文件
csv文件简介
- 参看 RFC 4180 http://www.ietf.org/rfc/rfc4180.txt
- 逗号分隔值Comma-Separated Values
- CSV 是一个被行分隔符、列分隔符划分成行和列的文本文件
- CSV不指定字符编码
- 行分隔符为\r\n,最后一行可以没有换行符
- 列分隔符常为逗号或者制表符
- 每一行成为一条记录record
- 字段可以使用双引号括起来,也可以不使用。如果字段中出现了双引号、逗号、换行符必须使用双引号括起来。如果字段的值是双引号,使用两个双引号表示一个转义
- 表头可选,和字段列对齐就行
手动生成csv文件
为了理解csv格式
from pathlib import Path p1 = Path('d:/tmp/mydir/my.csv') p1.parent.mkdir(parents=True, exist_ok=True) # """\ 中\斜杠表示续行符,近接着后面字符 # ""双双引号代表一个双引号 csv_body = """\ id,name,age,comment 1,zs,20, I'm 20 2,ls,18,"test string""1223." 3,ww,30," python 你好 " """ # with p1.open('w', encoding='utf-8') as f: # newline = None \n 转换成 OS对应的换行符 # f.write(csv_body) print(csv_body.encode()) #b'id,name,age,comment\n1,zs,20, I\'m 20\n2,ls,18,"test string""1223."\n3,ww,30,"\npython\n\n\xe4\xbd\xa0\xe5\xa5\xbd\n"\n' p1.write_text(csv_body, encoding='utf-8')
csv模块
csv.reader(iterable, dialect='excel', *args, **kwargs)
- 返回reader 对象,是一个行迭代器
- 默认使用excel方言,如下:
- delimiter 列分隔符,逗号
- lineterminator 行分隔符\r\n
- quotechar 字段的引用符号,缺省为 " 双引号
- 双引号的处理
- doublequote 双引号的处理,默认为True。如果碰到数据中有双引号,而quotechar也是双引号,True则使用2个双引号表示,False表示使用转义字符将作为双引号的前缀
- escapechar 一个转义字符,默认为None
- writer = csv.writer(f, doublequote=False, escapechar=’@’)遇到双引号,则必须提供转义字符
- quoting 指定双引号的规则
- QUOTE_ALL 所有字段
- QUOTE_MINIMAL 特殊字符字段,Excel方言使用该规则
- QUOTE_NONNUMERIC 非数字字段
- QUOTE_NONE 都不使用引号
csv.writer(fileobj, dialect='excel', *args, **kwargs)
- 返回DictWriter的实例
- 主要方法有writerow、writerows
writerow(iterable)
- 说明row行,需要一个可迭代就可以,可迭代的每一个元素,将作为csv行的每一个元素
- windows下回再每行末尾多出一个/r,解决办法 open(‘test.csv’, ‘w’, newline=’’)
范例:读取csv文件
from pathlib import Path import csv p1 = Path('d:/tmp/mydir/my.csv') p1.parent.mkdir(parents=True, exist_ok=True) # """\ 中\斜杠表示续行符,近接着后面字符 # ""双双引号代表一个双引号 csv_body = """\ id,name,age,comment 1,zs,20, I'm 20 2,ls,18,"test string""1223." 3,ww,30," python 你好 " """ with p1.open(encoding='utf-8') as f: #在windows下默认使用gbk编码读取 reader = csv.reader(f) print(next(reader)) #字段分开,返回列表,每一个字段项 print(next(reader)) print('-' * 30) for line in reader: print(line) # ['id', 'name', 'age', 'comment'] # ['1', 'zs', '20', " I'm 20"] # ------------------------------ # ['2', 'ls', '18', 'test string"1223.'] # ['3', 'ww', '30', '\npython\n\n你好\n']
范例:写csv文件
from pathlib import Path import csv p1 = Path('d:/tmp/mydir/my.csv') p1.parent.mkdir(parents=True, exist_ok=True) # """\ 中\斜杠表示续行符,近接着后面字符 # ""双双引号代表一个双引号 csv_body = """\ id,name,age,comment 1,zs,20, I'm 20 2,ls,18,"test string""1223." 3,ww,30," python 你好 " """ #写csv文件 p2 = Path('d:/tmp/mydir/test.csv') rows = [ ['id', 'name', "age"], range(3), #数字 -> 文本文件 -> 0 字符串 'abcdefg', (1, 'tom', '20'), ((1,), (2,)), ([1], [2]) ] with p2.open('w', encoding='utf-8', newline='') as f: #写时,- '\n' 或''空串表示'\n' 不替换 writer = csv.writer(f) writer.writerow(rows[0]) #写第一行 writer.writerows(rows[1:]) #写多行 # id,name,age # 0,1,2 # a,b,c,d,e,f,g # 1,tom,20 # "(1,)","(2,)" # [1],[2] #读文件 with p2.open(encoding='utf-8', newline='') as f: #在windows下默认使用gbk编码读取. # newline='' 表示不会自动转换通用换行符,常见换行符都可以认为是换行 reader = csv.reader(f) first = next(reader) #字段分开,返回列表,每一个字段项 print(first) second = next(reader) print(second) print('-' * 30) for line in reader: print(line) #读回来的都是字符串,类型没有 # ['id', 'name', 'age'] # ['0', '1', '2'] # ------------------------------ # ['a', 'b', 'c', 'd', 'e', 'f', 'g'] # ['1', 'tom', '20'] # ['(1,)', '(2,)'] # ['[1]', '[2]']
ini文件处理
作为配置文件,ini文件的格式很流畅
[DEFAULT] a = test [mysql] default-character-set=utf8 [mysqld] datadir =/dbserver/data port = 33060 character-set-server=utf8 sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES
- 中括号里面的部分称为section,译作节、区、段
- 每一个section内,都是key=value形成的键值对,key称为option选项
- 注意这里的DEFAULT是缺省section的名字,必须大写
configparser
- configparser模块的ConfigParser类就是用来操作
- 可以将section当做key,section存储着键值对组成的字典,可以把ini配置文件当做一个嵌套的字典。默认使用的是有序字典
read(filenames, encoding=None) - 读取ini文件,可以是单个文件,也可以是文件列表。可以指定文件编码 sections() - 返回section列表。缺省section不包括在内 add_section(section_name) - 增加一个section has_section(section, option) - 判断seciton是否存在 options(section) - 返回section的所有option,会追加缺省section的option has_option(section, option) - 判断section是否存在这个option get(section, option, *, raw=False, vars=None[, fallback]) - 从指定的段的选项上取值,如果找到返回,如果没有找到就去找DEFAULT段有没有 getint(section, option, *, raw=False, vars=None[, fallback]) getfloat(section, option, *, raw=False,vars=None[, fallback]) getboolean(section, option, *, raw=False,vars=None[, fallback]) 上面3个方法和get一样,返回指定类型数据 items(raw=False, vars=None) items(section, raw=Fale, vars=None) - 没有section,则返回所有section名字及其对象;如果指定section,则返回这个指定的seciton的键值对组成而元组 set(section, option, value) - section存在的情况下,写入option=value,要求option、value必须是字符串 remove_section(section) - 移除seciton及其所有option remove_option(section, option) - 移除section下的option write(fileobject, space_aroud_delimiters=True) - 将当前config的所有内容写入fileobject中,一般open函数使用w模式
范例:读取
import configparser #配置文件解析器 ini cfg = configparser.ConfigParser() # 配置文件解析器对象 print(cfg) #<configparser.ConfigParser object at 0x0000014E8B2056A0> r = cfg.read('mysql.ini') #r = cfg.read(('mysql.ini', 'mysql.ini')) print(r) #['mysql.ini'] #读取section for x in cfg.sections(): #返回的是所有section,但不包含特殊的缺省section print(type(x), x) # <class 'str'> mysql # <class 'str'> mysqld print(cfg.options(x)) #每个section下的options,包含缺省 # ['default-character-set', 'a'] # ['datadir', 'port', 'character-set-server', 'sql_mode', 'a'] print(cfg.items()) #ItemsView(<configparser.ConfigParser object at 0x000002D346FE56A0>) for y in cfg.items(): #items() 迭代时,包含了DEFAULT print(type(y), y) # <class 'tuple'> ('DEFAULT', <Section: DEFAULT>) # <class 'tuple'> ('mysql', <Section: mysql>) # <class 'tuple'> ('mysqld', <Section: mysqld>) print('-' * 30) for k,v in cfg.items(): #items() 迭代时,包含了DEFAULT print(type(k), k) #k str print(type(v), v) #v section对象 print(cfg.items(k)) #二元组可迭代对象, print('+' * 30) # <class 'str'> DEFAULT # <class 'configparser.SectionProxy'> <Section: DEFAULT> # [('a', 'test')] # ++++++++++++++++++++++++++++++ # <class 'str'> mysql # <class 'configparser.SectionProxy'> <Section: mysql> # [('a', 'test'), ('default-character-set', 'utf8')] # ++++++++++++++++++++++++++++++ # <class 'str'> mysqld # <class 'configparser.SectionProxy'> <Section: mysqld> # [('a', 'test'), ('datadir', '/dbserver/data'), ('port', '33060'), ('character-set-server', 'utf8'), ('sql_mode', 'NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES')] # ++++++++++++++++++++++++++++++ print(cfg.has_option('mysqld', 'a')) #mysql下有没有a? 有 返回True #取值 t = cfg.get('mysqld', 'a') print(type(t), t) #<class 'str'> test t = cfg.get('mysqld', 'port', fallback=[]) #如果没有值,返回fallback的值 print(type(t), t) #<class 'str'> 33060 t = cfg.getint('mysqld', 'port', fallback=3306) #类型转换, int(get()) 如果没有值,返回fallback的值. print(type(t), t) #<class 'int'> 33060
范例:写入
import configparser #配置文件解析器 ini cfg = configparser.ConfigParser() # 配置文件解析器对象 print(cfg) #<configparser.ConfigParser object at 0x0000014E8B2056A0> r = cfg.read('mysql.ini') #r = cfg.read(('mysql.ini', 'mysql.ini')) print(r) #['mysql.ini'] #写入 cfg.set('mysqld', 'a', '100') #在内存中操作。 设置mysqld上a的值为100 with open('t.ini', 'w', encoding='utf-8') as f: cfg.write(f) if cfg.has_section('test'): cfg.remove_section('test') #本section所有options全部删除 cfg.add_section('test') print(cfg['mysql']) #<Section: mysql> #字典操作更简单 cfg['test']['t1'] = '1000' cfg['test']['t2'] = str([1,2,3]) t = cfg['test']['t2'] print(type(t), t) #<class 'str'> [1, 2, 3] print(cfg.get('test', 't2')) #[1, 2, 3] cfg['test'] = {'t3': 'abc'} #section存在,直接覆盖test中的内容 print(cfg.options('test')) #['t3', 'a'] cfg['test2'] = {'y': '1000'} #section不存在 print(cfg.options('test2')) #['y', 'a'] with open('t.ini', 'w', encoding='utf-8') as f: cfg.write(f) #其他 print(cfg._sections) #{'mysql': {'default-character-set': 'utf8'}, 'mysqld': {'datadir': '/dbserver/data', 'port': '33060', 'character-set-server': 'utf8', 'sql_mode': 'NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES', 'a': '100'}, 'test': {'t3': 'abc'}} for k,v in cfg._sections.items(): print(k,v) # mysql {'default-character-set': 'utf8'} # mysqld {'datadir': '/dbserver/data', 'port': '33060', 'character-set-server': 'utf8', 'sql_mode': 'NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES', 'a': '100'} # test {'t3': 'abc'}
序列化和反序列化
主要内容:
- 序列化、反序列化重要性
- Python 序列化库 Pickle
- 文本序列化方案 Json
- 高效二进制序列化库 Msgpack
- 常用序列化方案比较和适用场景
为什么要序列化
- 内存中的字典、列表、集合以及各种对象,如何保存到一个文件中?
- 如果是自己定义的类的实例,如何保存到一个文件中?
- 如何从文件中读取数据,并让他们在内存中再次恢复成自己对应的类的实例?
要设一套 协议 ,就按照某种规则,把内存中数据保存到文件中。文件是一个字节序列,所以必须把数据转换成字节序列,输出到文件。这就是 序列化 。
反之,把文件的字节序列恢复到内存并且还是原来的类型,就是 反序列化
定义
serialization 序列化
- 将内存中对象存储下来,把它变成一个个字节 ->二进制
deserialization 反序列化
- 将文件的一个个字节恢复成内存中对象 -> 二进制
序列化保存到文件就是持久化
- 可以将数据序列化后持久化,或者网络传输;也可以将文件中或者网络接收到的字节序列反序列化
Python提供了pickle库
pickle库
Python中的序列化、反序列化模块
对应函数
dumps 对象序列化为bytes对象 dump 对象序列化到文件对象,就是存入文件 loads 从bytes对象反序列化 load 对象反序列化,从文件读取数据
范例:序列化、反序列化
#理解二进制 import pickle from pathlib import Path filename = 'd:/tmp/mydir/ser.bin' Path(filename).parent.mkdir(parents=True,exist_ok=True) i = 99 #int c = 'c' #str l = list(range(1,4)) d = {'a': 1, 'b': 'abc', 'c':[1,2,3]} #写入,序列化 with open(filename, 'wb') as f: pickle.dump(i, f) #序列化 99的16进制 0x63 , 二进制文件的表现,80 04 int 63 边界2e # # hexdump.exe -C ser.bin # 00000000 80 04 4b 63 2e |..Kc.| # 00000005 pickle.dump(c, f) #c 0x8004 str 0x63 边界\x2e # # hexdump.exe -C ser.bin # 00000000 80 04 4b 63 2e 80 04 95 05 00 00 00 00 00 00 00 |..Kc............| # 00000010 8c 01 63 94 2e |..c..| pickle.dump(l, f) #l 0x8004 list 0x4b01 0x4b02 0x4b03 边界\x2e # # hexdump.exe -C ser.bin # 00000000 80 04 4b 63 2e 80 04 95 05 00 00 00 00 00 00 00 |..Kc............| # 00000010 8c 01 63 94 2e 80 04 95 0b 00 00 00 00 00 00 00 |..c.............| # 00000020 5d 94 28 4b 01 4b 02 4b 03 65 2e |].(K.K.K.e.| pickle.dump(d, f) #d 0x8004 dict xx 边界\x2e # # hexdump.exe -C ser.bin # 00000000 80 04 4b 63 2e 80 04 95 05 00 00 00 00 00 00 00 |..Kc............| # 00000010 8c 01 63 94 2e 80 04 95 0b 00 00 00 00 00 00 00 |..c.............| # 00000020 5d 94 28 4b 01 4b 02 4b 03 65 2e 80 04 95 23 00 |].(K.K.K.e....#.| # 00000030 00 00 00 00 00 00 7d 94 28 8c 01 61 94 4b 01 8c |......}.(..a.K..| # 00000040 01 62 94 8c 03 61 62 63 94 8c 01 63 94 5d 94 28 |.b...abc...c.].(| # 00000050 4b 01 4b 02 4b 03 65 75 2e |K.K.K.eu.| #读取,反序列化 with open(filename, 'rb') as f: for i in range(4): t = pickle.load(f) print(i+1, type(t), t) # 1 <class 'int'> 99 # 2 <class 'str'> c # 3 <class 'list'> [1, 2, 3] # 4 <class 'dict'> {'a': 1, 'b': 'abc', 'c': [1, 2, 3]}
可以看到二进制的序列化文件中,每一个数据最重要的,为了保存数据并在以后可以还原它,至少需要保存数据的 类型 数据 边界 。
对象序列化
import pickle #类 class AAA: tttt = 'ABC' #类属性 def __init__(self): #初始化方法 print('init~~~~~') self.cccc = 'AABBCC' #实例的属性,每一个实例都不同 def show(self): #def 方法 print('aabbcc') a1 = AAA() #实例化,会调用__init__ #序列化 ser = pickle.dumps(a1) print('ser={}'.format(ser)) # ser=b'\x80\x04\x95+\x00\x00\x00\x00\x00\x00\x00\x8c\x08__main__\x94\x8c\x03AAA\x94\x93\x94)\x81\x94}\x94\x8c\x04cccc\x94\x8c\x06AABBCC\x94sb.' with open('d:/tmp/mydir/ser', 'wb') as f: f.write(ser) # # hexdump.exe -C ser # 00000000 80 04 95 2b 00 00 00 00 00 00 00 8c 08 5f 5f 6d |...+.........__m| # 00000010 61 69 6e 5f 5f 94 8c 03 41 41 41 94 93 94 29 81 |ain__...AAA...).| # 00000020 94 7d 94 8c 04 63 63 63 63 94 8c 06 41 41 42 42 |.}...cccc...AABB| # 00000030 43 43 94 73 62 2e |CC.sb.| #反序列化 obj = pickle.loads(ser) print(type(obj)) #返回的是类型名 AAA <class '__main__.AAA'> print(obj) #AAA object对象实例,在内存中的位置 <__main__.AAA object at 0x0000019E2D687D90> print(obj.tttt) #ABC obj.show() #aabbcc print(obj.cccc) #AABBCC #序列化之后,反序列化的时候使用同样的定义 #list实例,反序列化时不会有这样的现象, #因为你根本不会使用自定义的list,用的还是python的list
上面的例子中,故意使用了连续的AAA、ABC、abc等字符串,就是为了在二进制文件中能容易的发现它们 上例中,其实就保存了一个类名,因为所有的其他东西都是类定义的东西,是不变的,所以只序列化一个AAA类名。反序列化的时候找到类就可以恢复一个对象
可以看出这回除了必须保存的AAA,还序列化了aaaa和abc,因为这是每一个对象自己的属性,每一个对象不一样的,所以这些数据需要序列化
序列化、反序列化实验
序列化的类定义和反序列化的类定义可能是不一致的。
因为反序列化时会找当前代码中的类名。有则使用当前类。
因此,序列化、反序列化必须保证使用同一套类的定义,否则会带来不可预料的结果
序列化应用
一般来说,本地序列化的情况,应用较少。大多数场景都应用在网络传输中。
将数据序列化后通过网络传输到远程节点,远程服务器上的服务将接受到的数据反序列化后,就可以使用了
但是需要注意,远程接受端,反序列化时必须有对应的数据类型,否则就会报错。尤其是自定义类,必须远程得有一致的定义
现在,大多数项目,都不是单机的,也不是单服务的,需要多个程序之间配合。需要通过网络将数据传送到其他节点上去,这就需要大量的序列化、反序列化过程
但是,问题是,Python程序之间还可以都用pickle解决序列化、反序列化,如果是跨平台、跨语言、跨协议。pickle就不太适合,需要公共的协议。例如XML、Json、Protocol Buffer等
不同的协议,效率不同,适用不同的场景,根据不同的情况分析选型
Json
Json(JavaScript Object Notation,JS 对象标记)是一种轻量级的数据交换格式。它基于 ECMAScript(w3c组织制定的JS规范)的一个子集,采用完全独立于变成语言的文本格式来存储和表示数据
Json官网:http://json.org/
Json是数据类型
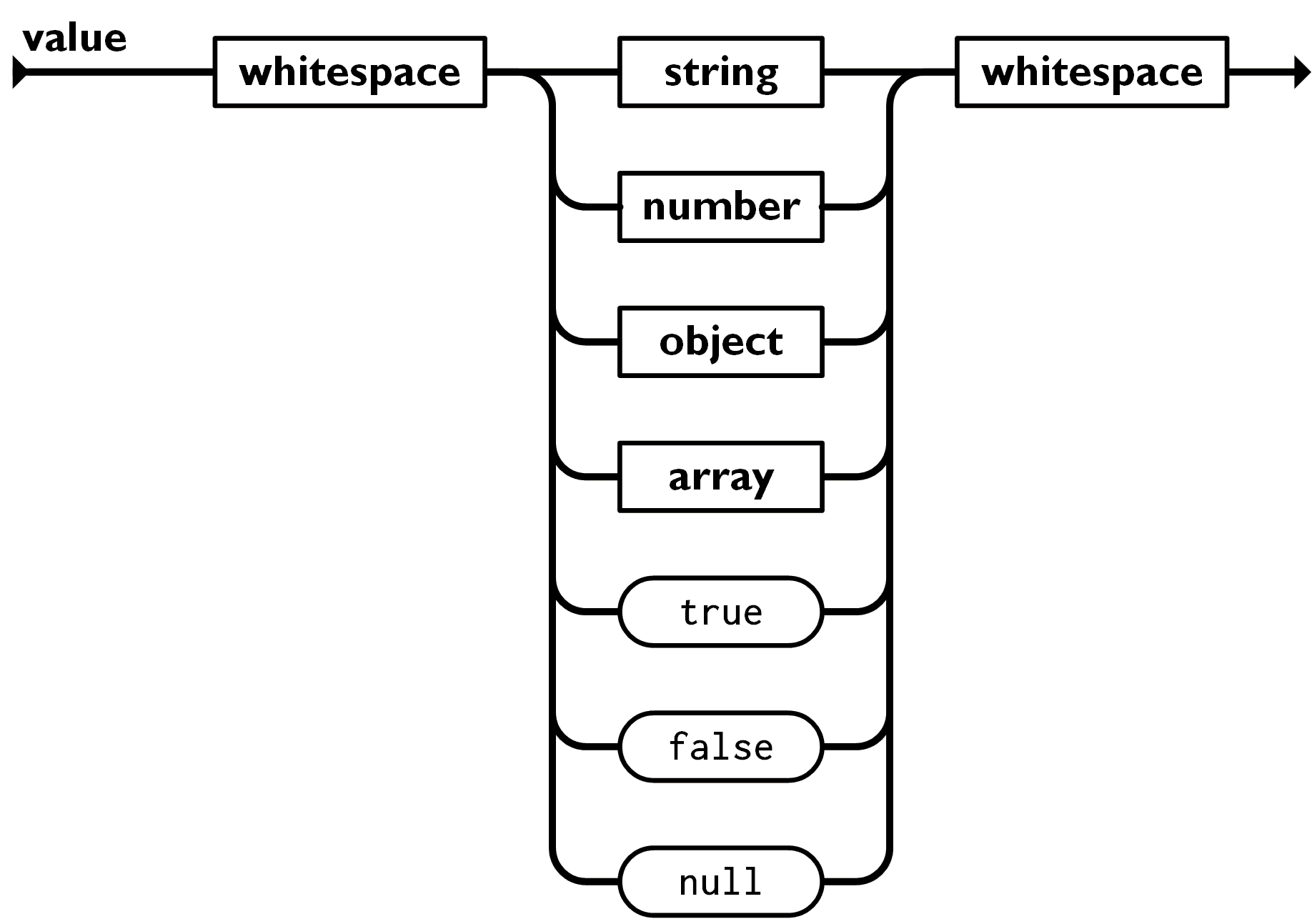
值
双引号引起来的字符串,数值,true和false,null,对象,数组。这些都是值
字符串
由双引号包围起来的任意字符的组合,可以有转义字符
数值
有正负,有整数、浮点数
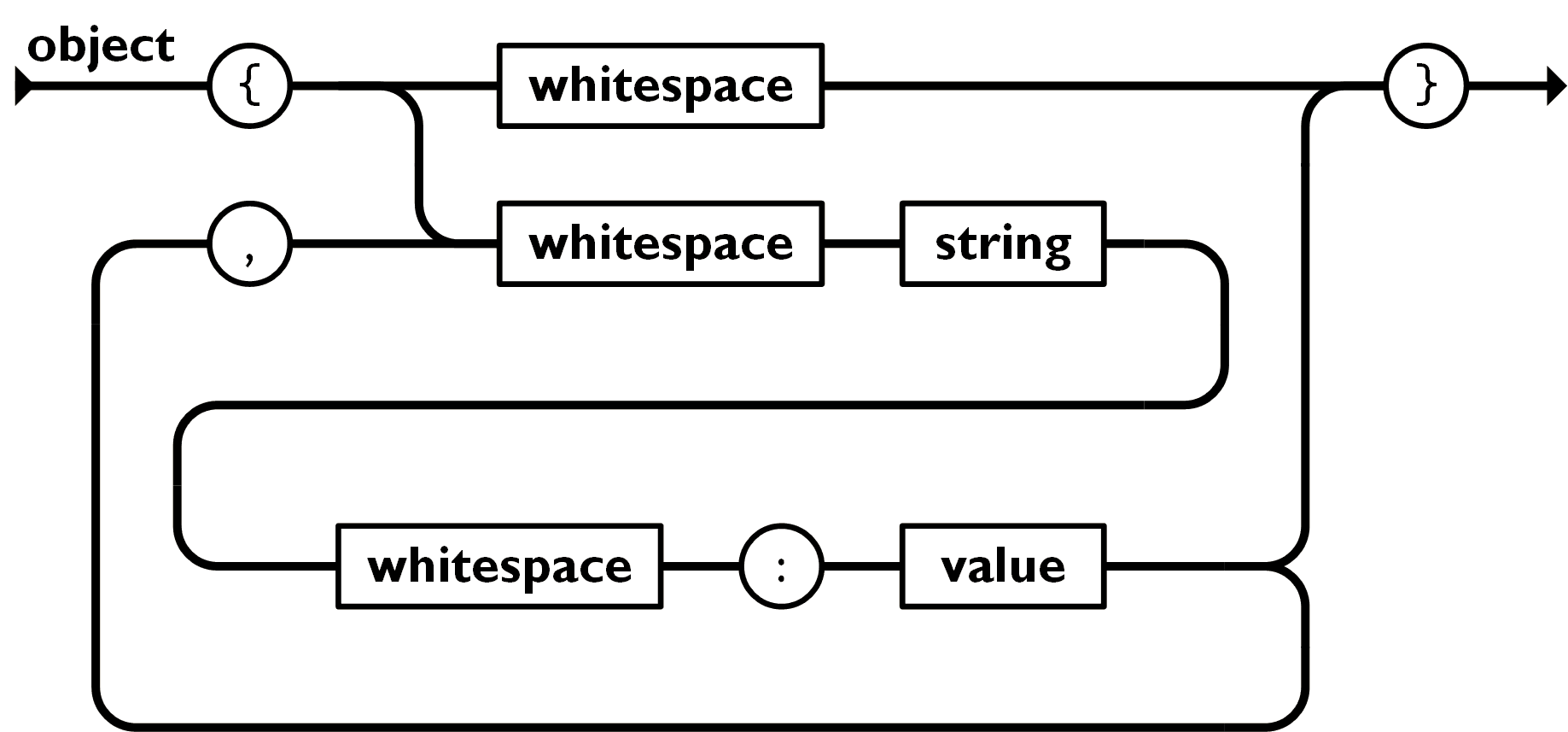
对象
无序的键值对的集合
格式:{key1:value1,…,keyn:valuen}
key必须是一个字符串,需要双引号包围这个字符串
value可以是任意合法的值
数组
有序的值的集合
格式:[val1,…,valn]
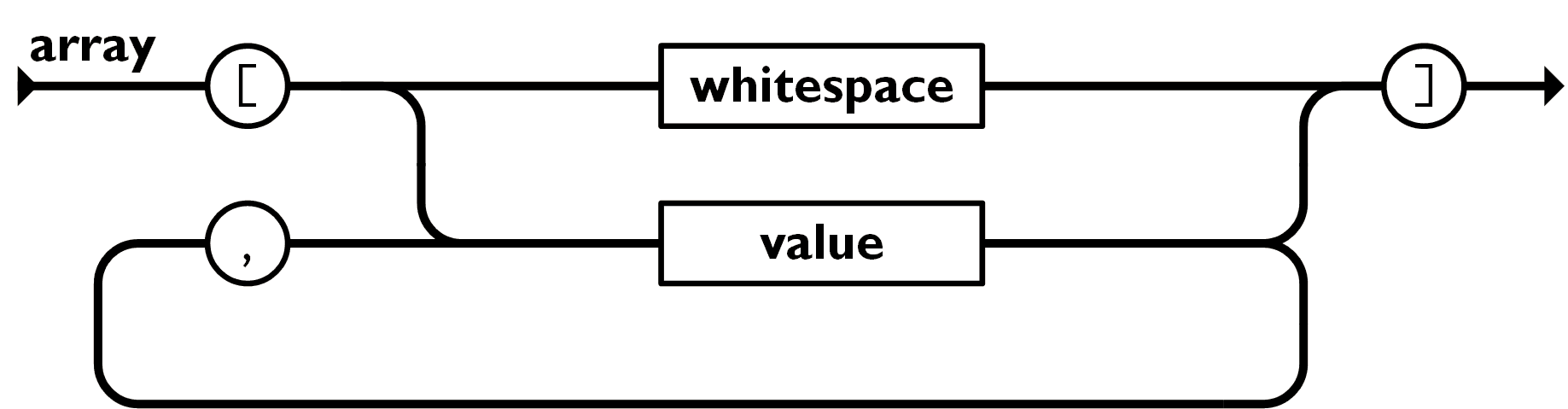
范例
{
"person":[
{
"name": "tom",
"age": 18
},
{
"name": "jerry",
"age": 16
}
],
"total": 2
}
Json 模块
Python 与 Json
Python支持少量内建数据类型到Json类型的转换
| Python类型 | Json类型 |
|---|---|
| True | true |
| False | false |
| None | null |
| str | string |
| int | integer |
| float | float |
| list | array |
| dict | object |
常用方法
| Python类型 | Json类型 |
|---|---|
| dumps | json编码 |
| dump | json编码并存入文件 |
| loads | json编码 |
| load | json编码,从文件读取数据 |
范例:
import json d = { 'name':'Tom', 'age':20, 'insterest':('movie', 'music'), # ? 'class':['python'] #array } #dict => object #序列化json s = json.dumps(d) # 转成字符序列 print(type(s), len(s)) #<class 'str'> 80 print(s) #{"name": "Tom", "age": 20, "insterest": ["movie", "music"], "class": ["python"]} #反序列化json new = json.loads(s) # str => dict 实际上是 js:object => dict print(type(new)) #<class 'dict'> print(new) #{'name': 'Tom', 'age': 20, 'insterest': ['movie', 'music'], 'class': ['python']} #尽量写成js支持的类型 d = { 'name':'Tom', 'age':20, 'insterest':['movie', 'music'], 'class':['python'] #array } #dict => object #序列化json s = json.dumps(d) # 转成字符序列 print(type(s), len(s)) #<class 'str'> 80 print(s) #{"name": "Tom", "age": 20, "insterest": ["movie", "music"], "class": ["python"]} #反序列化json new = json.loads(s) # str => dict 实际上是 js:object => dict print(type(new)) #<class 'dict'> print(new) #{'name': 'Tom', 'age': 20, 'insterest': ['movie', 'music'], 'class': ['python']} print(d == new) # ? True 等号代表内容是否相同 print(d is new) # ? False is代表内存位置是否相同 print(id(d), id(new)) #2713103083392 2713101598528
一般json编码的数据很少落地,数据都是通过网络传输。传输的时候,要考虑压缩它
本质上来说它就是个文本,就是个字符串
json很简单,几乎编程语言都支持json,所以应用范围十分广泛
MessagePack
MessagePack是一个基于 二进制 高效的对象序列化类库,可用于跨语言通信
它可以像Json那样,在许多语言之间交换结构对象
但是它比Json更快速也更轻巧
支持Python、Ruby、Java、C/C++等众多语言。
兼容json和pickle
可以看出,大大的节约了空间
# Json:27 bytes
{"person":[{"name":"tom","age":18},{"name":"jerry",."age":16}],"total":2}
# MessagePack:18 bytes
# 82 a7 63 6f 6d 70 61 63 74 c3 a6 73 63 68 65 6d 61 00
#流量就是金钱,在流量很大时就能体现出来了
安装
pip install msgpack
常用方法
- packb 序列化对象。提供了dumps来兼容pickle和json
- unpackb 反序列化对象。提供了loads来兼容
- pack 序列化对象保存到文件对象。提供了dump来兼容
- unpack 反序列化对象保存到文件对象。提供了load来兼容
MessagePack简单易用,高效压缩,支持语言丰富 所以,用它序列化也是一种很好的选择。Python很多大名鼎鼎的库都是用了msgpack
范例:对比
import json import pickle import msgpack d = { 'Persons':[ {'name':'tom', 'age':20}, #dict => object {'name':'jerry', 'age':18} ], #list => array 'test':'aaaaaa', 'total': 2 } # dict => object #序列化 for i,module in enumerate((pickle, json, msgpack)): #元组, 三个元素 # pickle.dumps(d) #99 bytes # json.dumps(d) #101 bytes 会有一些无效的空格 # msgpack.dumps(d) #61 bytes data = module.dumps(d) print(module.__name__, "len={}".format(len(data)), type(data)) print(i, data) # pickle len=99 <class 'bytes'> # 0 b'\x80\x04\x95X\x00\x00\x00\x00\x00\x00\x00}\x94(\x8c\x07Persons\x94]\x94(}\x94(\x8c\x04name\x94\x8c\x03tom\x94\x8c\x03age\x94K\x14u}\x94(h\x04\x8c\x05jerry\x94h\x06K\x12ue\x8c\x04test\x94\x8c\x06aaaaaa\x94\x8c\x05total\x94K\x02u.' # json len=101 <class 'str'> # 1 {"Persons": [{"name": "tom", "age": 20}, {"name": "jerry", "age": 18}], "test": "aaaaaa", "total": 2} # msgpack len=61 <class 'bytes'> # 2 b'\x83\xa7Persons\x92\x82\xa4name\xa3tom\xa3age\x14\x82\xa4name\xa5jerry\xa3age\x12\xa4test\xa6aaaaaa\xa5total\x02' #反序列化 u = msgpack.loads(data) #utf-8 print(type(u), u) u2 = msgpack.loads(data, raw=True) #新版 raw=True 用原始的,不转字符串了 print(type(u2), u2) # <class 'dict'> {'Persons': [{'name': 'tom', 'age': 20}, {'name': 'jerry', 'age': 18}], 'test': 'aaaaaa', 'total': 2} # <class 'dict'> {b'Persons': [{b'name': b'tom', b'age': 20}, {b'name': b'jerry', b'age': 18}], b'test': b'aaaaaa', b'total': 2}